Om du använder tabellpartitionering med en eller flera partitioner lagrade i en skrivskyddad filgrupp, kan SQL-uppdaterings- och raderingssatser misslyckas med ett fel. Naturligtvis är detta det förväntade beteendet om någon av ändringarna skulle kräva skrivning till en skrivskyddad filgrupp; men det är också möjligt att stöta på detta feltillstånd där ändringarna är begränsade till filgrupper markerade som läs-skriv.
Exempeldatabas
För att demonstrera problemet kommer vi att skapa en enkel databas med en enda anpassad filgrupp som vi senare kommer att markera som skrivskyddad. Observera att du måste lägga till sökvägen till filnamnet för att passa din testinstans.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Partitionsfunktion och schema
Vi kommer nu att skapa en grundläggande partitioneringsfunktion och -schema som styr rader med data före 1 januari 2000 till den skrivskyddade partitionen. Senare data kommer att lagras i den primära läs-skriva filgruppen:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); Range right-specifikationen innebär att rader med gränsvärdet 1 januari 2000 kommer att finnas i läs-skriv-partitionen.
Partitionerad tabell och index
Vi kan nu skapa vår testtabell:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); Tabellen har en klustrad primärnyckel i datetime-kolumnen och är också partitionerad i den kolumnen. Det finns icke-klustrade index på de andra två heltalskolumnerna, som är uppdelade på samma sätt (indexen är justerade med bastabellen).
Exempel på data
Slutligen lägger vi till ett par rader med exempeldata och gör datapartitionen före 2000 skrivskyddad:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
Du kan använda följande testuppdateringssatser för att bekräfta att data i den skrivskyddade partitionen inte kan ändras, medan data med en dt värde den 1 januari 2000 eller senare kan skrivas till:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Ett oväntat misslyckande
Vi har två rader:en skrivskyddad (1999-12-31); och en läs-skriv (2000-01-01):

Prova nu följande fråga. Den identifierar samma skrivbara "2000-01-01"-rad som vi just har uppdaterat, men använder ett annat where-satspredikat:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
Den beräknade (förutförande) planen är:

De fyra (!) Compute Scalarerna är inte viktiga för denna diskussion. De används för att avgöra om det icke-klustrade indexet behöver underhållas för varje rad som kommer till Clustered Index Update-operatorn.
Det mer intressanta är att denna uppdateringssats misslyckas med ett fel som liknar:
Msg 652, Level 16, State 1Indexet "PK_dbo_Test__c1_dt" för tabellen "dbo.Test" (RowsetId 72057594039042048) finns i en skrivskyddad filgrupp ("ReadOnlyFileGroup"), som inte kan modifieras.
Inte eliminering av partition
Om du har arbetat med partitionering tidigare, kanske du tror att "partitioneliminering" kan vara orsaken. Logiken skulle se ut ungefär så här:
I de tidigare satserna angavs ett bokstavligt värde för partitioneringskolumnen i where-satsen, så att SQL Server omedelbart skulle kunna avgöra vilken eller vilka partitioner som ska komma åt. Genom att ändra where-satsen så att den inte längre refererar till partitioneringskolumnen, har vi tvingat SQL Server att komma åt varje partition med en Clustered Index Scan.
Det är sant i allmänhet, men det är inte anledningen till att uppdateringssatsen misslyckas här.
Det förväntade beteendet är att SQL Server ska kunna läsa från alla partitioner under exekveringen av en fråga. En dataändringsoperation bör bara misslyckas om exekveringsmotorn faktiskt försöker modifiera en rad lagrad i en skrivskyddad filgrupp.
För att illustrera, låt oss göra en liten ändring av föregående fråga:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; Where-satsen är exakt densamma som tidigare. Den enda skillnaden är att vi nu (medvetet) sätter partitioneringskolumnen lika med sig själv. Detta kommer inte att ändra värdet som lagras i den kolumnen, men det påverkar resultatet. Uppdateringen lyckas nu (om än med en mer komplex genomförandeplan):

Optimizern har introducerat nya Split-, Sorter- och Collapse-operatorer och lagt till det maskineri som krävs för att underhålla varje potentiellt påverkat icke-klustrat index separat (med en bred strategi eller per-index-strategi).
Egenskaperna för Clustered Index Scan visar att båda partitionerna i tabellen var åtkomst när du läste:
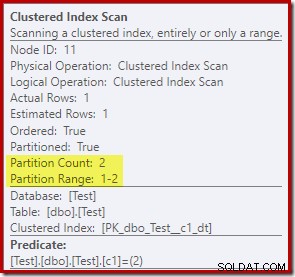
Däremot visar Clustered Index Update att endast läs-skrivpartitionen var åtkomst för skrivning:
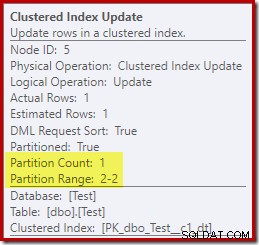
Var och en av de icke-klustrade indexuppdateringsoperatorerna visar liknande information:endast den skrivbara partitionen (#2) modifierades under körningen, så inget fel inträffade.
Anledningen avslöjad
Den nya planen lyckas inte eftersom de icke-klustrade indexen upprätthålls separat; eller beror det (direkt) på kombinationen Split-Sort-Collapse som är nödvändig för att undvika tillfälliga dubbletter av nyckelfel i det unika indexet.
Den verkliga anledningen är något som jag nämnde kort i min tidigare artikel, "Optimera uppdateringsfrågor" – en intern optimering känd som Rowset Sharing . När detta används delar Clustered Index Update samma underliggande lagringsmotorraduppsättning som en Clustered Index Scan, Seek eller Key Lookup på lässidan av planen.
Med Rowset Sharing-optimeringen söker SQL Server efter offline- eller skrivskyddade filgrupper vid läsning. I planer där Clustered Index Update använder en separat raduppsättning, utförs kontrollen offline/skrivskyddad endast för varje rad vid uppdaterings- (eller raderings-) iteratorn.
Odokumenterade lösningar
Låt oss först få bort det roliga, nördiga men opraktiska grejen.
Optimeringen av delad raduppsättning kan endast tillämpas när rutten från den klustrade indexsökningen, skanningen eller nyckelsökningen är en pipeline . Inga blockerande eller halvblockerande operatörer är tillåtna. Med andra ord måste varje rad kunna ta sig från läskälla till skrivdestination innan nästa rad läses.
Som en påminnelse, här är exempeldata, uttalande och genomförandeplan för den misslyckade uppdatera igen:
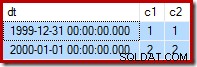
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Halloween-skydd
Ett sätt att introducera en blockerande operatör till planen är att kräva explicit Halloween Protection (HP) för den här uppdateringen. Att separera läsningen från skrivningen med en blockerande operatör kommer att förhindra att raduppsättningsdelningsoptimeringen används (ingen pipeline). Odokumenterad och ostödd (endast testsystem!) spårningsflagga 8692 lägger till en Eager Table Spool för explicit HP:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
Den faktiska exekveringsplanen (tillgänglig eftersom felet inte längre visas) är:

Kombinationen Sortera i Split-Sort-Collapse som sågs i den tidigare framgångsrika uppdateringen tillhandahåller den blockering som krävs för att inaktivera raduppsättningsdelning i det fallet.
Anti-Rowset Sharing Trace Flag
Det finns en annan odokumenterad spårningsflagga som inaktiverar optimeringen av raduppsättningsdelning. Detta har fördelen av att inte introducera en potentiellt dyr spärroperatör. Det kan naturligtvis inte användas i praktiken (såvida du inte kontaktar Microsoft Support och får något skriftligt som rekommenderar att du aktiverar det, antar jag). Icke desto mindre, för underhållningsändamål, här är spårflaggan 8746 i aktion:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
Den faktiska genomförandeplanen för det uttalandet är:

Experimentera gärna med olika värden (de som faktiskt ändrar de lagrade värdena om du vill) för att övertyga dig själv om skillnaden här. Som nämnts i mitt tidigare inlägg kan du också använda odokumenterad spårningsflagga 8666 för att exponera raduppsättningsdelningsegenskapen i exekveringsplanen.
Om du vill se raduppsättningsdelningsfelet med en delete-sats, ersätt helt enkelt uppdateringen och set-klausuler med en delete, samtidigt som du använder samma where-sats.
Lösningar som stöds
Det finns hur många möjliga sätt som helst att säkerställa att raduppsättningsdelning inte tillämpas i verkliga frågor utan att använda spårningsflaggor. Nu när du vet att kärnfrågan kräver en delad och pipelined klustrad läs- och skrivplan för index, kan du förmodligen komma på en egen. Trots det finns det ett par exempel som är särskilt värda att titta på här.
Tvingat index / täckande index
En naturlig idé är att tvinga lässidan av planen att använda ett icke-klustrat index istället för det klustrade indexet. Vi kan inte lägga till ett indextips direkt till testfrågan som skriven, men alias för tabellen tillåter detta:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Detta kan tyckas vara den lösning som frågeoptimeraren borde ha valt i första hand, eftersom vi har ett icke-klustrat index på where-satspredikatets kolumn c1. Utförandeplanen visar varför optimeraren valde som den gjorde:
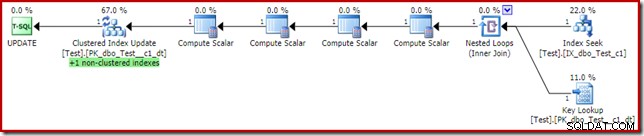
Kostnaden för nyckelsökningen är tillräcklig för att övertyga optimeraren att använda det klustrade indexet för läsning. Uppslagningen behövs för att hämta det aktuella värdet för kolumn c2, så att Compute Scalars kan avgöra om det icke-klustrade indexet behöver underhållas.
Att lägga till kolumn c2 till det icke-klustrade indexet (nyckel eller inkludera) skulle undvika problemet. Optimeraren skulle välja det nu täckande indexet istället för det klustrade indexet.
Som sagt, det är inte alltid möjligt att förutse vilka kolumner som kommer att behövas, eller att inkludera alla även om uppsättningen är känd. Kom ihåg att kolumnen behövs eftersom c2 finns i set-satsen av uppdateringsförklaringen. Om frågorna är ad-hoc (t.ex. skickade av användare eller genererade av ett verktyg), skulle varje icke-klustrat index behöva inkludera alla kolumner för att göra detta till ett robust alternativ.
En intressant sak med planen med Key Lookup ovan är att den inte gör det generera ett fel. Detta trots att Key Lookup och Clustered Index Update använder en delad raduppsättning. Anledningen är att den icke-klustrade Indexsökningen lokaliserar raden med c1 =2 före Key Lookup berör det klustrade indexet. Den delade raduppsättningskontrollen för offline-/skrivskyddade filgrupper utförs fortfarande vid sökningen, men den berör inte den skrivskyddade partitionen, så inget fel uppstår. Som en sista (relaterad) punkt av intresse, notera att Indexsökningen rör båda partitionerna, men nyckelsökningen träffar bara en.
Utesluter den skrivskyddade partitionen
En trivial lösning är att förlita sig på partitionseliminering så att lässidan av planen aldrig rör den skrivskyddade partitionen. Detta kan göras med ett explicit predikat, till exempel någon av dessa:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Där det är omöjligt eller obekvämt att ändra varje fråga för att lägga till ett partitionselimineringspredikat, kan andra lösningar som uppdatering via en vy vara lämpliga. Till exempel:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; En nackdel med att använda en vy är att en uppdatering eller borttagning som riktar sig till den skrivskyddade delen av bastabellen kommer att lyckas utan att raderna påverkas, snarare än att misslyckas med ett fel. En i stället för trigger på bordet eller vy kan vara en lösning för det i vissa situationer, men kan också skapa fler problem...men jag avviker.
Som nämnts tidigare finns det många potentiella lösningar som stöds. Poängen med den här artikeln är att visa hur raduppsättningsdelning orsakade det oväntade uppdateringsfelet.