Med Disaster Recovery strävar vi efter att sätta upp system för att hantera allt som kan gå fel med vår databas. Vad händer om databasen kraschar? Vad händer om en utvecklare av misstag trunkerar en tabell? Vad händer om vi får reda på att vissa uppgifter raderades förra veckan men vi märkte det inte förrän idag? Dessa saker händer, och att ha en stabil plan och ett system på plats kommer att få DBA att se ut som en hjälte när alla andras hjärtan redan har stannat när en katastrof reser upp sitt fula huvud.
Varje databas som har någon form av värde bör ha ett sätt att implementera ett eller flera alternativ för återställning av katastrofer. PostgreSQL har ett mycket solidt replikeringssystem inbyggt, och är tillräckligt flexibelt för att kunna ställas in i många konfigurationer för att hjälpa till med Disaster Recovery, om något skulle gå fel. Vi kommer att fokusera på scenarier som ifrågasatts ovan, hur vi ställer in våra alternativ för katastrofåterställning och fördelarna med varje lösning.
Hög tillgänglighet
Med strömmande replikering i PostgreSQL är High Availability enkel att ställa in och underhålla. Målet är att tillhandahålla en failover-webbplats som kan befordras till master om huvuddatabasen går ner av någon anledning, som hårdvarufel, mjukvarufel eller till och med nätverksavbrott. Att vara värd för en replik på en annan värd är bra, men att vara värd för den i ett annat datacenter är ännu bättre.
Severalnines har en detaljerad djupdykning tillgänglig här för detaljer om hur du ställer in streamingreplikering. Den officiella PostgreSQL Streaming Replication Documentation har detaljerad information om streaming-replikeringsprotokollet och hur det hela fungerar.
En standardinställning kommer att se ut så här, en huvuddatabas som accepterar läs-/skrivanslutningar, med en replikdatabas som tar emot all WAL-aktivitet i nästan realtid och spelar upp all dataändringsaktivitet lokalt.
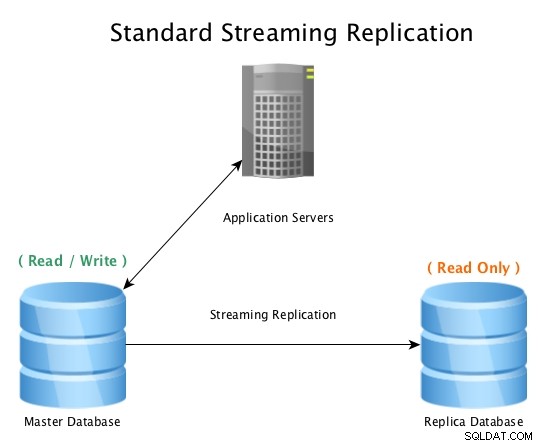 Standard strömmande replikering med PostgreSQL
Standard strömmande replikering med PostgreSQL När huvuddatabasen blir oanvändbar, initieras en failover-procedur för att koppla den offline, och främja replikdatabasen till master, och sedan peka alla anslutningar till den nyligen befordrade värden. Detta kan göras genom att antingen konfigurera om en lastbalanserare, applikationskonfiguration, IP-alias eller andra smarta sätt att omdirigera trafiken.
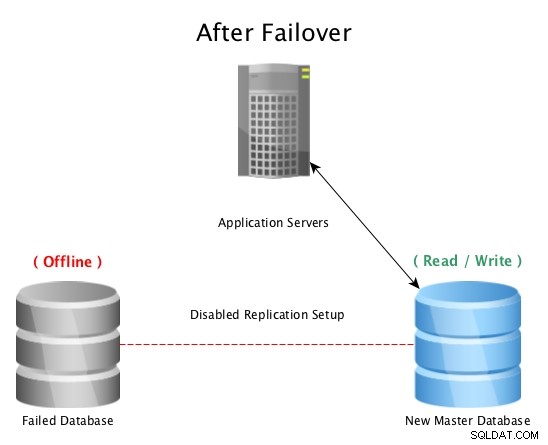 Efter en failover med PostgreSQL Streaming Replication
Efter en failover med PostgreSQL Streaming Replication När en katastrof drabbar en huvuddatabas (som ett hårddiskfel, strömavbrott eller något som hindrar mastern från att fungera som avsett) är det snabbaste sättet att vara online och betjäna frågor till applikationer eller kunder att misslyckas med ett hot standbyläge. driftstopp. Tävlingen är sedan igång för att antingen fixa den misslyckade databasvärden, eller ta en ny kopia online för att upprätthålla skyddsnätet att ha en standby redo att gå. Att ha flera standby-lägen säkerställer att fönstret efter ett katastrofalt fel också är redo för ett sekundärt fel, hur osannolikt det än kan verka.
Obs:När du misslyckas med en strömmande replik kommer den att fortsätta där den tidigare mastern slutade, så detta hjälper till att hålla databasen online, men inte återställa oavsiktligt förlorad data.
Time-återställning
Ett annat alternativ för katastrofåterställning är Point in TIME Recovery (PITR). Med PITR kan en kopia av databasen hämtas tillbaka när som helst vi vill, så länge vi har en basbackup från före den tiden, och alla WAL-segment som behövdes fram till dess.
Ett Point In Time Recovery-alternativ kommer inte lika snabbt online som ett Hot Standby, men den största fördelen är att kunna återställa en databas ögonblicksbild före en stor händelse som en raderad tabell, dålig data som infogas eller till och med oförklarlig datakorruption . Allt som skulle förstöra data på ett sådant sätt att vi skulle vilja få en kopia innan den förstörelsen, PITR räddar dagen.
Point in Time Recovery fungerar genom att skapa periodiska ögonblicksbilder av databasen, vanligtvis med hjälp av programmet pg_basebackup, och bevara arkiverade kopior av alla WAL-filer som genererats av mastern
Inställning för punktinställning
Installationen kräver några konfigurationsalternativ inställda på mastern, av vilka några är bra att gå med standardvärden på den aktuella senaste versionen, PostgreSQL 11. I det här exemplet kommer vi att kopiera 16MB-filen direkt till vår fjärranslutna PITR-värd med rsync , och komprimera dem på andra sidan med ett cron-jobb.
WAL-arkivering
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'OBS: Inställningen archive_command kan vara många saker, det övergripande målet är att skicka bort alla arkiverade WAL-filer till en annan värd av säkerhetsskäl. Om vi förlorar några WAL-filer blir PITR förbi den förlorade WAL-filen omöjlig. Låt din programmeringskreativitet bli galen, men se till att den är pålitlig.
[Valfritt] Komprimera de arkiverade WAL-filerna:
Varje konfiguration kommer att variera något, men om inte databasen i fråga är mycket lätt i datauppdateringar, kommer uppbyggnaden av 16 MB filer att fylla upp diskutrymme ganska snabbt. Ett enkelt komprimeringsskript, konfigurerat via cron, kan se ut som nedan.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]OBS: Under en återställningsmetod måste alla komprimerade filer dekomprimeras senare. Vissa administratörer väljer att bara komprimera filer efter att de är X antal dagar gamla, vilket håller det totala utrymmet lågt, men håller också nyare WAL-filer redo för återställning utan extra arbete. Välj det bästa alternativet för databaserna i fråga för att maximera din återställningshastighet.
Basbackuper
En av nyckelkomponenterna i en PITR-säkerhetskopiering är bassäkerhetskopieringen och frekvensen av bassäkerhetskopieringar. Dessa kan vara varje timme, dagligen, veckovis, månadsvis, men valde det bästa alternativet baserat på återställningsbehov såväl som trafiken i databasdatachurnen. Om vi har veckovisa säkerhetskopior varje söndag, och vi behöver återställa ända till lördag eftermiddag, tar vi föregående söndags bassäkerhetskopiering online med alla WAL-filer mellan den säkerhetskopian och lördag eftermiddag. Om denna återställningsprocess tar 10 timmar att bearbeta, är detta sannolikt oönskat för lång tid, dagliga basbackuper kommer att minska återställningstiden, eftersom basbackupen skulle vara från den morgonen, men också öka mängden arbete på värden för basbackupen sig själv.
Om en veckas återställning av WAL-filer tar bara några minuter, eftersom databasen ser låg churn, är veckosäkerhetskopiering bra. Samma data kommer att finnas till slut, men hur snabbt du kan komma åt det är nyckeln.
I vårt exempel kommer vi att ställa in en veckovis bassäkerhetskopiering, och eftersom vi använder Streaming Replication för hög tillgänglighet, samt minskar belastningen på mastern, kommer vi att skapa bassäkerhetskopian från replikdatabasen.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zOBS: Kommandot pg_basebackup förutsätter att denna värd är inställd för lösenordslös åtkomst för användarens 'replikering' på mastern, vilket kan göras antingen genom att 'trusta' på pg_hba för denna PITR backup-värd, lösenord i .pgpass-filen eller andra säkrare sätt . Tänk på säkerheten när du ställer in säkerhetskopior.
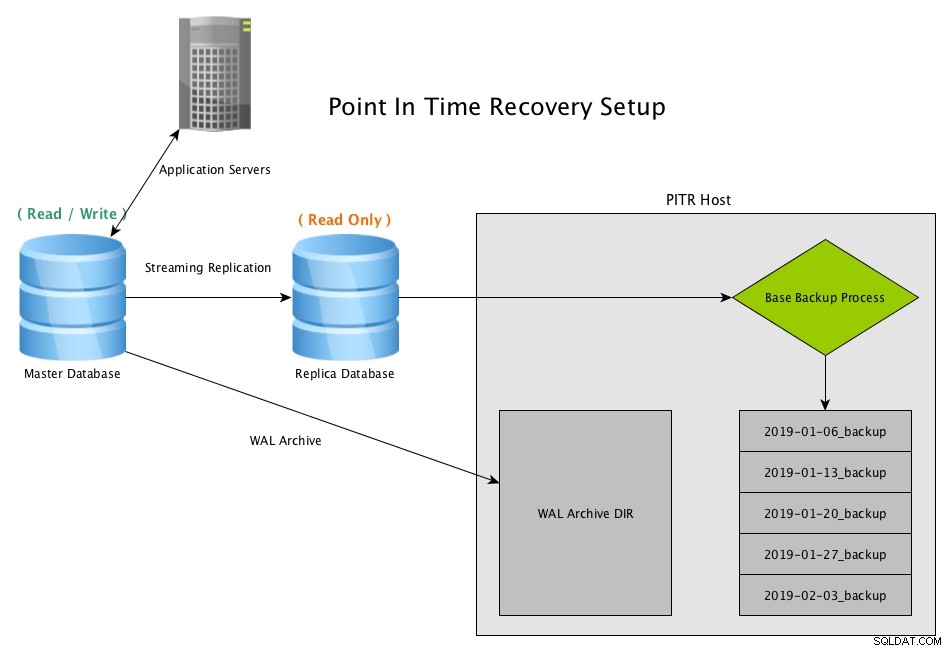 Point In Time Recovery (PITR) från en strömmande replika med PostgreSQLDladda ned Whitepaper Today PostgreSQL Management &Control med Cluster Automation vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda Whitepaper
Point In Time Recovery (PITR) från en strömmande replika med PostgreSQLDladda ned Whitepaper Today PostgreSQL Management &Control med Cluster Automation vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda Whitepaper PITR-återställningsscenario
Att ställa in Point In Time Recovery är bara en del av jobbet, att behöva återställa data är den andra delen. Med lycka till, detta kanske aldrig behöver hända, men det rekommenderas starkt att regelbundet göra en återställning av en PITR-säkerhetskopia för att verifiera att systemet fungerar och för att se till att processen är känd/skriptad korrekt.
I vårt testscenario väljer vi en tidpunkt att återställa till och initiera återställningsprocessen. Till exempel:Fredag morgon driver en utvecklare en ny kodändring till produktion utan att gå igenom en kodgranskning, och det förstör en massa viktig kunddata. Eftersom vår Hot Standby alltid är synkroniserad med mastern, skulle det inte fixa någonting att misslyckas med det, eftersom det skulle vara samma data. PITR-säkerhetskopior är det som kommer att rädda oss.
Kodpushen gick in klockan 11, så vi måste återställa databasen till strax före den tiden, 10:59 bestämmer vi, och som tur är gör vi dagliga backuper så vi har en backup från midnatt i morse. Eftersom vi inte vet vad som förstördes, bestämmer vi oss också för att göra en fullständig återställning av denna databas på vår PITR-värd och föra den online som master, eftersom den har samma hårdvaruspecifikationer som mastern, ifall detta scenario inträffade.
Stäng av Master
Eftersom vi bestämde oss för att återställa helt från en säkerhetskopia och marknadsföra den för att behärska, finns det ingen anledning att hålla detta online. Vi stänger av den, men behåller den ifall vi skulle behöva ta något från den senare, för säkerhets skull.
Konfigurera Base Backup för återställning
Därefter hämtar vi på vår PITR-värd vår senaste basbackup från före evenemanget, vilket är backup '2018-12-21_backup'.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Med detta är bassäkerhetskopieringen, såväl som WAL-filerna som tillhandahålls av pg_basebackup, redo att användas, om vi tar den online nu kommer den att återställas till den punkt då säkerhetskopieringen ägde rum, men vi vill återställa alla WAL-transaktioner mellan midnatt och 11:59, så vi konfigurerade vår recovery.conf-fil.
Skapa recovery.conf
Eftersom denna säkerhetskopia faktiskt kom från en strömmande replik, finns det troligen redan en recovery.conf-fil med replikainställningar. Vi kommer att skriva över det med nya inställningar. En detaljerad informationslista för alla olika alternativ finns i PostgreSQL:s dokumentation här.
Genom att vara försiktig med WAL-filerna, kommer återställningskommandot att kopiera de komprimerade filerna som det behöver till återställningskatalogen, dekomprimera dem och sedan flytta till där PostgreSQL behöver dem för återställning. De ursprungliga WAL-filerna kommer att finnas kvar om de behövs av andra skäl.
Ny recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Starta återställningsprocessen
Nu när allt är konfigurerat kommer vi att starta processen för återställning. När detta inträffar är det en bra idé att ta hand om databasloggen för att se till att den återställs som avsett.
Starta databasen:
pg_ctl -D /var/lib/pgsql/11/data startTa efter loggarna:
Det kommer att finnas många loggposter som visar att databasen återställs från arkivfiler, och vid en viss tidpunkt kommer den att visa en rad som säger "återställningen stoppas innan transaktionen utförs ..."
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07Vid det här laget har återställningsprocessen tagit in alla WAL-filer, men är också i behov av granskning innan den kommer online som en master. I det här exemplet noterar loggen att nästa transaktion efter återställningsmåltiden 11:59:00 var 11:59:01 och den återställdes inte. För att verifiera, logga in på databasen och ta en titt, den körande databasen bör vara en ögonblicksbild från 11:59 exakt.
När allt ser bra ut, dags att främja återhämtningen som en mästare.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Nu är databasen online, återställd till den punkt vi bestämt, och accepterar läs/skriv-anslutningar som en masternod. Se till att alla konfigurationsparametrar är korrekta och redo för produktion.
Databasen är online, men återställningsprocessen är inte klar än! Nu när den här PITR-backupen är online som master, bör en ny standby- och PITR-inställning ställas in, tills dess kan den här nya mastern vara online och betjäna applikationer, men den är inte säker från en annan katastrof förrän allt är konfigurerat igen.
Andra scenarier för återställning vid tidpunkt
Att ta tillbaka en PITR-säkerhetskopia för en hel databas är ett extremfall, men det finns andra scenarier där endast en delmängd av data saknas, är korrupt eller dålig. I dessa fall kan vi vara kreativa med våra återställningsalternativ. Utan att ta mastern offline och ersätta den med en säkerhetskopia kan vi ta en PITR-säkerhetskopia online till den exakta tidpunkt vi vill ha på en annan värd (eller en annan port om utrymme inte är ett problem), och exportera den återställda data från säkerhetskopian direkt in i huvuddatabasen. Detta kan användas för att återställa en handfull rader, en handfull tabeller eller någon konfiguration av data som behövs.
Med strömmande replikering och Point In Time Recovery ger PostgreSQL oss stor flexibilitet när det gäller att se till att vi kan återställa all data vi behöver, så länge vi har standby-värdar redo att gå som master, eller säkerhetskopior redo att återställa. Ett bra alternativ för katastrofåterställning kan utökas ytterligare med andra säkerhetskopieringsalternativ, fler replikanoder, flera säkerhetskopieringsplatser över olika datacenter och kontinenter, periodiska pg_dumps på en annan replik, etc.
Dessa alternativ kan läggas ihop, men den verkliga frågan är "hur värdefull är data, och hur mycket är du villig att spendera för att få tillbaka den?". Många fall är förlusten av data slutet på ett företag, så bra katastrofåterställningsalternativ bör finnas på plats för att förhindra att det värsta händer.