Jag har tidigare skrivit om fördelarna med att använda NOEXPAND tips, även i Enterprise Edition. Detaljerna finns i den länkade artikeln, men för att sammanfatta kort:
- SQL Server kommer endast att skapas automatiskt statistik på en indexerad vy när en
NOEXPANDtabelltips används. Om du utelämnar denna ledtråd kan det leda till exekveringsplansvarningar om saknad statistik som inte kan lösas genom att skapa statistik manuellt. - SQL Server kommer endast att använda automatiskt eller manuellt skapad vystatistik i kardinalitetsuppskattningsberäkningar när frågan refererar till vyn direkt och en
NOEXPANDledtråd används. För alla utom de mest triviala vydefinitionerna betyder detta att kvaliteten på kardinalitetsuppskattningar sannolikt är lägre när denna ledtråd inte används, vilket ofta resulterar i mindre optimala utförandeplaner. - Avsaknaden av, eller oförmågan att använda, visningsstatistik kan göra att optimeraren gissar på kardinalitetsuppskattningar, även där bastabellstatistik är tillgänglig. Detta kan hända när en del av frågeplanen ersätts med en indexerad vyreferens av den automatiska vymatchningsfunktionen, men vystatistik är inte tillgänglig, som beskrivs ovan.
Det finns en annan konsekvens av att inte använda NOEXPAND ledtråd, som jag nämnde i förbigående för ett par år sedan i min artikel, Optimizer Limitations with Filtered Indexes:
NOEXPANDtips behövs även i Enterprise Edition för att säkerställa att unikhetsgarantin från visningsindexen används av optimeraren.
Den här artikeln undersöker detta uttalande och dess konsekvenser mer i detalj.
Demoinställningar
Följande skript skapar en enkel tabell och indexerad vy:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Det skapar en enstaka kolumnhögtabell och en obegränsad vy av samma tabell med ett unikt klustrat index. Detta är inte avsett att vara ett realistiskt användningsfall för en indexerad vy; men det kommer att hjälpa till att illustrera nyckelpunkterna med ett minimum av distraktioner. Det viktiga är att bastabellen här inte har några index alls (inte ens ett klusterindex) men vyn har det, och det indexet är unikt.
Exempelfrågan
Tänk på följande enkla fråga mot bastabellen:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Exekveringsplanen du kommer att se för den här frågan beror på vilken version av SQL Server som används. Om inte Enterprise Edition (eller motsvarande) kommer du att se en plan så här:

SQL Server-frågeoptimeraren har valt att skanna bastabellen och tillämpa den angivna distinktheten med en Distinct Sorter-operator. Denna planform är helt förväntad, eftersom automatisk matchning av indexerade vyer inte är tillgänglig utanför Enterprise Edition. Jag kommer att sluta säga "Enterprise Edition eller motsvarande" från och med nu, men fortsätt att dra slutsatsen att jag menar alla utgåvor som stöder automatisk vymatchning när jag säger "Enterprise Edition" från och med nu.
Tipset EXPAND VIEWS
Det här är lite av en åtskillnad, men för att få samma plan på Enterprise Edition måste vi använda en EXPAND VIEWS frågetips:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Det kan tyckas lite konstigt att använda denna ledtråd när det finns inga vyreferenser i frågan, men det är så det fungerar. EXPAND VIEWS hint anger effektivt att matchning av indexerad vy ska inaktiveras under kompilering och optimering av frågan. För att vara tydlig:Utan denna ledtråd kan Enterprise Edition annars matcha (delar av) frågan med en eller flera indexerade vyer.
Med automatisk visningsmatchning aktiverad
Utan en EXPAND VIEWS ledtråd, kompilering av samma fråga på Developer Edition (till exempel) ger en annan plan:
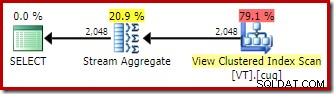
Tillämpningen av indexerad vymatchning innebär att exekveringsplanen har en skanning av det vyklustrade indexet istället för en bastabellskanning.
Samma plan skapas i det här fallet om frågan refererar till vyn direkt (istället för bastabellen):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; I alla utgåvor utökas vyreferensen innan frågeoptimeringen påbörjas. I Enterprise-ekvivalenta utgåvor kan den utökade formen matchas tillbaka till vyn senare. Detta är ett nyckelbegrepp att förstå när man tänker på hur frågekompilatorn och optimeraren använder indexerade vyer i SQL Server.
Strömningsaggregatet
Den mest intressanta skillnaden mellan de två planerna vi har sett hittills är Stream Aggregate i den vymatchade planen. Om du tittar på de uppskattade kostnaderna för operatörerna för tabellskanning och visningsskanning ser du att de är exakt likadana. Optimeraren bestämde sig inte för att använda den indexerade vyn eftersom det gjorde åtkomst till data billigare. Genom att skanna visningsindexet tillåter snarare DISTINCT kravet på att implementeras som ett strömaggregat, snarare än ett hashaggregat eller distinkt sortering (som i den första planen).
Ett strömaggregat kräver inmatning sorterad efter grupperingskolumn(erna). I det här fallet är distinkten likvärdig med gruppering efter en enda kolumn, och vyns unika klustrade index ger den nödvändiga beställningsgarantin. Optimerarens kostnadsmodell identifierar Stream Aggregate som ett billigare alternativ än Distinct Sortering eller Hash Aggregate för den här frågan. Detta är grunden för att optimeraren väljer att komma åt den indexerade vyn när automatisk vymatchning är tillgänglig.
Med allt som sagt och förstått är Stream Aggregate fortfarande oväntat:Med tanke på unikhetsgarantin som tillhandahålls av view index, finns det inget behov av att utföra denna gruppering alls. Den unika klustrade index säkerställer redan att kolumnen inte innehåller några dubbletter.
Detta, i ett nötskal, är problemet. När automatisk vymatchning används känner optimeraren igen beställningsgarantin från vyindexet, men inte unikhetsgarantin.
Använda en NOEXPAND-tips
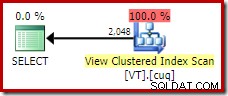
För att få den perfekta exekveringsplanen för den här frågan måste vi referera till vyn direkt och använda en NOEXPAND tabelltips:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Detta ger oss den plan som en erfaren databasperson förväntar sig; en som korrekt känner igen att den distinkta operationen är redundant och kan tas bort:
Ett andra exempel
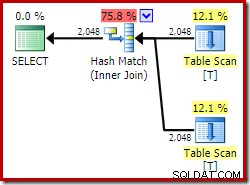
Att misslyckas med att utnyttja unikhetsgarantin från ett vyindex kan få andra effekter på den slutliga genomförandeplanen. Överväg nu en självkoppling av den indexerade vyn (igen, bara för att illustrera ett koncept – detta är inte avsett att vara en realistisk fråga):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Genom att använda Developer Edition kommer den valda exekveringsplanen inte alls åt den indexerade vyn och har en hash-join (ibland en indikation på att ett användbart index saknas):
Låt oss nu prova exakt samma fråga, men med en NOEXPAND tips om varje vyreferens:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Exekveringsplanen har nu två indexerade vyåtkomster och en sammanfogning:
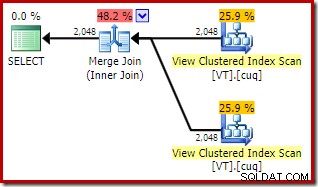
Den här nya planen har en mycket lägre uppskattad kostnad än hash-anslutningsplanen, så varför valde inte optimeraren det här alternativet tidigare? Vi kan se varför genom att lägga till en ledtråd för sammanfogning till den ursprungliga frågan:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Detta ger ett liknande utseende plan som väljer att komma åt vyn trots att NOEXPAND specificerades inte:
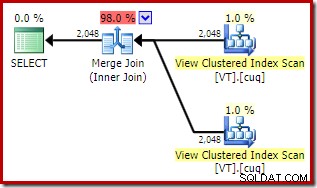
Den totala uppskattade kostnaden för denna plan är högre än båda tidigare exemplen. Merge Join i denna plan står också för en högre andel av den totala beräknade kostnaden än tidigare (98 % mot 48,2 %).
Anledningen till detta kan ses genom att titta på egenskaperna för sammanfogningen. I NOEXPAND plan, det var en en-till-många sammanfogning. I planen direkt ovan är det en många-till-många sammanfogning. Optimizerns kostnadsmodell tilldelar fler-till-många sammanslagningar en högre kostnad eftersom en tempdb-arbetstabell behövs för att hantera eventuella dubbletter.
Slutsatser
De garantier som ett unikt index ger kan vara ett kraftfullt optimeringsverktyg, så det är synd att automatisk indexmatchning för närvarande inte kan dra nytta av det. De potentiella fördelarna sträcker sig längre än att eliminera onödiga sammanslagningar eller möjliggöra en sammanslagning av en-till-många som vi ser i de föregående enkla exemplen. I allmänhet kan det vara svårt att upptäcka att en genomförandeplan är suboptimal eftersom optimeraren missade att dra nytta av en unikhetsgaranti.
Denna optimeringsbegränsning gäller inte bara det unika klustrade index som en vy måste ha för att kunna realiseras. I mer komplexa scenarier kan ytterligare icke-klustrade index också finnas på vyn; kanske för att spegla korsbordsrelationer som är svåra att genomdriva eller representera på annat sätt. Om dessa icke-klustrade index definieras som unika, kommer optimeraren att förbise dessa garantier också, om automatisk indexmatchning används.
Lägger man till detta till begränsningarna kring skapandet och användningen av statistisk information, verkar det som om att förlita sig på automatisk vymatchning kan resultera i sämre utförandeplaner. Det säkraste alternativet är förmodligen att uttryckligen referera till indexerade vyer och att använda en NOEXPAND tips varje gång – åtminstone tills dessa problem har åtgärdats i produkten.
Limiterande faktorer
Jag bör betona att problemet som beskrivs i den här artikeln endast gäller unikhetsgarantin som tillhandahålls av ett unikt vyindex. Om optimeraren kan få den nödvändiga unika informationen på annat sätt , är chansen god att optimeringsproblem undviks.
Till exempel kan det finnas ett lämpligt unikt index på en bastabell som hänvisas till av vyn. Eller, i fallet med en vy som innehåller aggregering, kan optimeraren redan härleda en användbar unikhetsgaranti från vyns GROUP BY klausul. Den vanliga metoden att lägga till ett vyklustrat index till grupperingsnycklarna lägger inte till någon extra unik information i så fall.
Icke desto mindre finns det tillfällen då denna "unika tillsyn" kan innebära att du får bättre kvalitet på genomförandeplaner genom att använda en explicit vyreferens och NOEXPAND tips, även i Enterprise Edition.