Obs! Det här inlägget publicerades ursprungligen endast i vår e-bok, High Performance Techniques for SQL Server, Volym 4. Du kan ta reda på om våra e-böcker här.
Jag får regelbundet frågan "Var ska jag börja när det gäller att försöka ställa in en SQL Server-instans?" Mitt första svar är att fråga dem om konfigurationen av deras instans. Om vissa saker inte är korrekt konfigurerade kan det vara bortkastad ansträngning att börja titta på långvariga eller dyra frågor direkt.
Jag har bloggat om vanliga saker som administratörer missar där jag delar många av de inställningar som administratörer bör ändra från en standardinstallation av SQL Server. För prestationsrelaterade objekt säger jag till dem att de bör kontrollera följande:
- Minnesinställningar
- Uppdaterar statistik
- Indexunderhåll
- MAXDOP och kostnadströskel för parallellitet
- tempdb bästa praxis
- Optimera för ad hoc-arbetsbelastningar
När jag väl kommit förbi konfigurationsobjekten frågar jag om de har tittat på fil- och väntastatistik samt högkostnadsfrågor. För det mesta är svaret "nej" - med en förklaring att de inte är säkra på hur de hittar informationen.
Vanligtvis är den vanliga kompatibiliteten när någon säger att de behöver ställa in en SQL Server att den går långsamt. Vad betyder långsam? Är det en viss rapport, en specifik tillämpning eller allt? Började det bara hända, eller har det blivit värre med tiden? Jag börjar med att ställa de vanliga triagefrågorna om hur minne, CPU och diskanvändning är jämfört med när saker och ting är normalt, började problemet bara hända och vad som nyligen ändrades. Om inte klienten fångar en baslinje, har de inga mätvärden att jämföra mot för att veta om aktuell statistik är onormal.
Nästan varje SQL Server som jag arbetar på har mer än en användardatabas. När en klient rapporterar att SQL-servern går långsamt är de oftast oroliga för en specifik applikation som orsakar problem för deras kunder. En rejäl reaktion är att omedelbart fokusera på just den databasen, men ofta kan en annan process konsumera värdefulla resurser och applikationens databas påverkas. Till exempel, om du har en stor rapportdatabas och någon startade en massiv rapport som mättar disken, spikar CPU och tömmer planens cache, kan du satsa på att de andra användardatabaserna skulle sakta ner medan rapporten genereras.
Jag gillar alltid att börja med att titta på filstatistiken. För SQL Server 2005 och senare kan du fråga sys.dm_io_virtual_file_stats DMV för att få I/O-statistik för varje data och loggfil. Denna DMV ersatte funktionen fn_virtualfilestats. För att fånga filstatistiken gillar jag att använda ett skript som Paul Randal satte ihop:fånga IO-latenser under en tidsperiod. Det här skriptet kommer att fånga en baslinje och, 30 minuter senare (om du inte ändrar varaktigheten i sektionen WAITFOR DELAY), fånga statistiken och beräkna deltan mellan dem. Pauls manus gör också lite matte för att bestämma läs- och skrivlatenserna, vilket gör det mycket lättare för oss att läsa och förstå.
På min bärbara dator återställde jag en kopia av AdventureWorks2014-databasen på en USB-enhet så att jag skulle ha lägre diskhastighet; Jag startade sedan en process för att generera en belastning mot den. Du kan se resultaten nedan där min skrivlatens för min datafil är 240ms och skrivlatens för min loggfil är 46ms. Latenser så här höga är besvärliga.
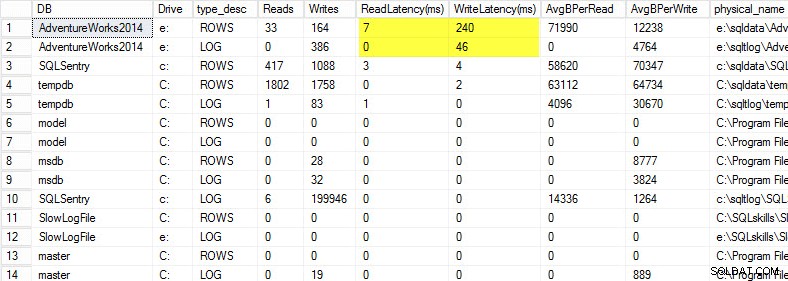
Allt över 20 ms bör betraktas som dåligt, som jag delade i ett tidigare inlägg:övervakning av läs-/skrivfördröjning. Min läsfördröjning är anständig, men AdventureWorks2014-databasen lider av långsamma skrivningar. I det här fallet skulle jag undersöka vad som genererar skrivningarna samt undersöka mitt I/O-undersystems prestanda. Om detta hade varit för höga läsfördröjningar skulle jag börja undersöka frågeprestanda (varför gör den så många läsningar, till exempel från saknade index), såväl som övergripande I/O-undersystems prestanda.
Det är viktigt att känna till den övergripande prestandan för ditt I/O-delsystem, och det bästa sättet att veta vad det kan är genom att benchmarka det. Glenn Berry berättar om detta i sin artikel som analyserar I/O-prestanda för SQL Server. Glenn förklarar latens, IOPS och genomströmning och visar upp CrystalDiskMark som är ett kostnadsfritt verktyg som du kan använda för att basera din lagring.
Efter att ha tagit reda på hur filstatistiken presterar, gillar jag att titta på väntestatistik genom att använda DMV sys.dm_os_wait_stats, som returnerar information om alla väntetider som inträffade. För detta vänder jag mig till ett annat manus som Paul Randal tillhandahåller i sin fånga väntestatistik för en tids blogginlägg. Pauls manus gör lite matematik för oss igen, men ännu viktigare, det utesluter många av de godartade väntan som vi vanligtvis inte bryr oss om. Det här skriptet har också en VÄNTA FÖRDRÖJNING och är inställt på 30 minuter. Att läsa väntestatistik kan vara lite svårare:Du kan ha väntetider som verkar vara höga baserat på procent, men den genomsnittliga väntetiden är så låg att det inte är något att oroa sig för.
Jag startade samma laddningsprocess och fångade min väntestatistik, som jag har visat nedan. För förklaringar till många av dessa väntetyper kan du läsa ett annat av Pauls blogginlägg, väntestatistik eller snälla berätta för mig var det gör ont, plus några av hans inlägg på den här bloggen.
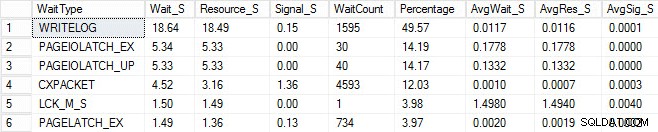
I denna konstruerade utdata kan PAGEIOLATCH-väntningarna indikera en flaskhals med mitt I/O-undersystem, men kan också vara ett minnesproblem, tabellsökningar istället, eller en mängd andra problem. I mitt fall vet vi att det är ett diskproblem, eftersom jag lagrar databasen på ett USB-minne. LCK_M_S väntetiden är mycket hög, men det finns bara en instans av väntan. Min WRITELOG är också högre än jag skulle vilja se, men det är förståeligt att känna till latensproblemen med USB-minnet. Detta visar också CXPACKET-väntningar, och det skulle vara lätt att få ett knä-ryck och tro att du har ett problem med parallellism/MAXDOP, men AvgWait_S-räknaren är väldigt låg. Var försiktig när du använder väntar på felsökning. Låt det vara en guide för att berätta saker som inte är problemet samt ge dig en riktning om var du ska leta efter problem. Korrekt felsökning är att korrelera beteenden från flera områden för att begränsa problemet.
Efter att ha tittat på filen och väntestatistiken börjar jag gräva i de höga kostnadsfrågorna baserat på de problem jag hittade. För detta vänder jag mig till Glenn Berrys Diagnostic Information Queries. Dessa uppsättningar av frågor är de go-to-skript som många konsulter använder. Glenn och samhället tillhandahåller ständigt uppdateringar för att göra dem så informativa och robusta som möjligt. En av mina favoritfrågor är de mest cachade frågorna efter antal körningar. Jag älskar att hitta frågor eller lagrade procedurer som har hög execution_count i kombination med höga total_logical_reads. Om dessa frågor har tuningmöjligheter kan du snabbt göra stor skillnad för servern. Också inkluderade i skripten är toppcachelagrade SP:er efter totala logiska läsningar och toppcachelagrade SP:er av totala fysiska läsningar. Båda dessa är bra för att leta efter höga läsningar med höga exekveringsantal så att du kan minska antalet I/O.
Utöver Glenns manus gillar jag att använda Adam Machanics sp_whoisactive för att se vad som körs just nu.
Det finns mycket mer med prestandajustering än att bara titta på fil- och väntestatistik och högkostnadsfrågor, men det är där jag gillar att börja. Det är ett sätt att snabbt triage en miljö för att börja avgöra vad som orsakar problemet. Det finns inget helt idiotsäkert sätt att ställa in:vad varje produktions-DBA behöver är en checklista med saker att köra igenom för att eliminera och en riktigt bra samling skript att köra igenom för att analysera systemets tillstånd. Att ha en baslinje är nyckeln till att snabbt utesluta normalt kontra onormalt beteende. Min goda vän Erin Stellato har en hel kurs i Pluralsight som heter SQL Server:Benchmarking och Baselining om du behöver hjälp med att sätta upp och fånga din baslinje.
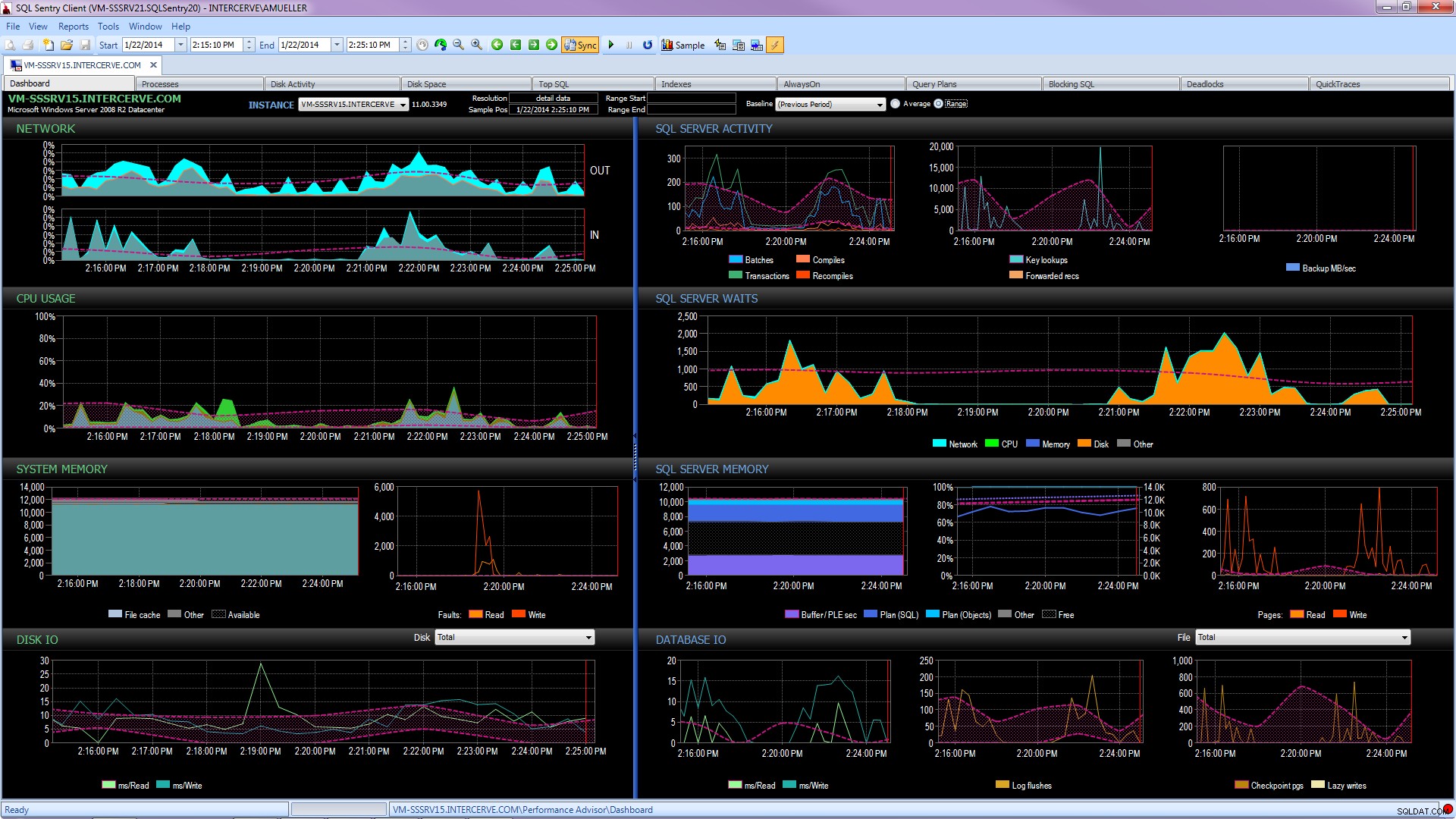
Ännu bättre, skaffa ett toppmodernt verktyg som SQL Sentry Performance Advisor som inte bara samlar in och lagrar historisk information för profilering och trender, och ger enkel tillgång till alla detaljer som nämns ovan och mer, utan det ger också möjligheten att jämföra aktivitet med inbyggda eller användardefinierade baslinjer, effektivt underhålla index utan att lyfta ett finger och varna eller automatisera svar baserat på en mycket robust arkitektur för anpassade villkor. Följande skärmdump visar den historiska vyn av Performance Advisor-instrumentpanelen, med diskväntningar i orange, databas I/O längst ner till höger och baslinjer som jämför den aktuella och föregående perioden på varje graf (klicka för att förstora):
Kvalitetsövervakningsverktyg är inte gratis, men de tillhandahåller massor av funktionalitet och support som låter dig fokusera på prestandaproblemen på dina servrar, istället för att fokusera på frågor, jobb och varningar som kan låter dig fokusera på dina prestationsproblem – men bara när du har rätt till dem. Det finns ofta ett stort värde i att inte uppfinna hjulet igen.