Den här artikeln utforskar några mindre välkända frågeoptimerares funktioner och begränsningar och förklarar orsakerna till extremt dålig hash-join-prestanda i ett specifikt fall.
Exempeldata
Det exempel på dataskapande skriptet som följer bygger på en befintlig tabell med tal. Om du inte redan har en av dessa kan skriptet nedan användas för att skapa ett effektivt. Den resulterande tabellen kommer att innehålla en enda heltalskolumn med tal från en till en miljon:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Själva provdatan består av två tabeller, T1 och T2. Båda har en sekventiell heltals primärnyckelkolumn som heter pk och en andra nullbar kolumn med namnet c1. Tabell T1 har 600 000 rader där jämna rader har samma värde för c1 som pk-kolumnen, och udda rader är null. Tabell c2 har 32 000 rader där kolumn c1 är NULL i varje rad. Följande skript skapar och fyller i dessa tabeller:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; De första tio raderna med exempeldata i varje tabell ser ut så här:
Sammanfogar de två borden
Detta första test involverar att sammanfoga de två tabellerna i kolumn c1 (inte pk-kolumnen), och returnera pk-värdet från tabell T1 för rader som sammanfogar:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Frågan returnerar faktiskt inga rader eftersom kolumn c1 är NULL i alla rader i tabell T2, så inga rader kan matcha predikatet för likhetskoppling. Detta kan låta som en udda sak att göra, men jag är säker på att det är baserat på en verklig produktionsfråga (mycket förenklad för att underlätta diskussionen).
Observera att detta tomma resultat inte beror på inställningen av ANSI_NULLS, eftersom det bara styr hur jämförelser med en noll-literal eller variabel hanteras. För kolumnjämförelser avvisar ett likhetspredikat alltid nollor.
Utförandeplanen för denna enkla anslutningsfråga har några intressanta funktioner. Vi kommer först att titta på pre-execution ('uppskattad') plan i SQL Sentry Plan Explorer:
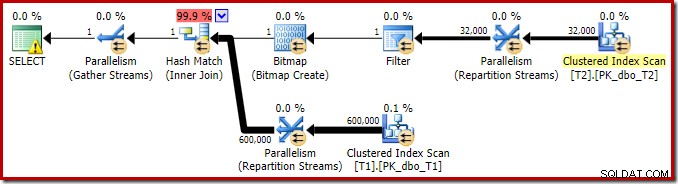
Varningen på SELECT-ikonen klagar bara på ett saknat index i tabell T1 för kolumn c1 (med pk som en inkluderad kolumn). Indexförslaget är irrelevant här.
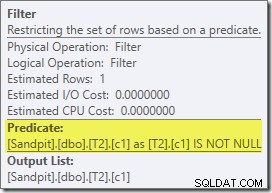
Den första riktiga posten av intresse i denna plan är filtret:
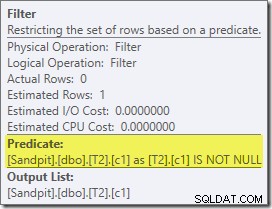
Detta IS NOT NULL-predikat visas inte i källfrågan, även om det är underförstått i join-predikatet som tidigare nämnts. Det är intressant att det har brutits ut som en explicit extra operatör, och placerats före joinoperationen. Observera att även utan filtret skulle frågan fortfarande ge korrekta resultat – själva joinen skulle fortfarande avvisa nollvärdena.
Filtret är också nyfiket av andra skäl. Den har en beräknad kostnad på exakt noll (även om den förväntas fungera på 32 000 rader), och den har inte tryckts ner i Clustered Index Scan som ett restpredikat. Optimeraren är normalt ganska sugen på att göra detta.
Båda dessa saker förklaras av det faktum att detta filter introduceras i en omskrivning efter optimering. Efter att frågeoptimeraren har slutfört sin kostnadsbaserade bearbetning finns det ett relativt litet antal omskrivningar av fasta planer som övervägs. En av dessa är ansvarig för att introducera filtret.
Vi kan se resultatet av kostnadsbaserat planval (före omskrivningen) med odokumenterade spårningsflaggor 8607 och den välbekanta 3604 för att dirigera textutdata till konsolen (meddelandefliken i SSMS):
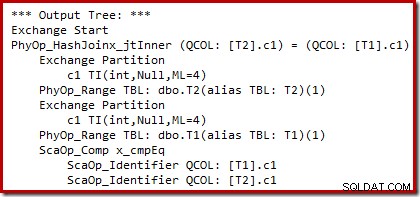
Utdataträdet visar en hash-join, två skanningar och några parallellitetsoperatorer (utbyte). Det finns inget null-avvisande filter i kolumnen c1 i tabell T2.
Den särskilda omskrivningen efter optimering tittar uteslutande på bygginmatningen för en hash-join. Beroende på dess bedömning av situationen kan den lägga till ett explicit filter för att avvisa rader som är null i joinnyckeln. Effekten av filtret på beräknat antal rader skrivs också in i exekveringsplanen, men eftersom kostnadsbaserad optimering redan är slutförd beräknas ingen kostnad för filtret. Om det inte är uppenbart, är beräkningskostnader ett slöseri med ansträngning om alla kostnadsbaserade beslut redan har fattats.
Filtret förblir direkt på bygginmatningen istället för att tryckas ner i Clustered Index Scan eftersom den huvudsakliga optimeringsaktiviteten har slutförts. Omskrivningarna efter optimering är i själva verket sista minuten justeringar av en färdig exekveringsplan.
En andra, och ganska separat, omskrivning efter optimering är ansvarig för Bitmap-operatören i den slutliga planen (du kanske har märkt att den också saknades i 8607-utgången):
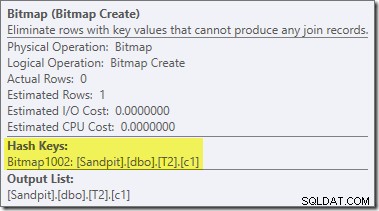
Denna operatör har också en uppskattad kostnad för både I/O och CPU noll. Den andra saken som identifierar den som en operatör som introduceras av en sen tweak (snarare än under kostnadsbaserad optimering) är att dess namn är Bitmap följt av ett nummer. Det finns andra typer av bitmappar som introduceras under kostnadsbaserad optimering som vi kommer att se lite senare.
För nu är det viktiga med den här bitmappen att den registrerar c1-värden som ses under byggfasen av hash-join. Den färdiga bitmappen skjuts till probesidan av kopplingen när hashen övergår från byggfas till probefas. Bitmappen används för att utföra tidig semi-join-reduktion, vilket eliminerar rader från probesidan som omöjligt kan gå med. om du behöver mer information om detta, se min tidigare artikel om ämnet.
Den andra effekten av bitmappen kan ses på sondens Clustered Index Scan:
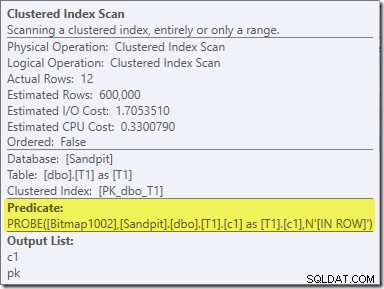
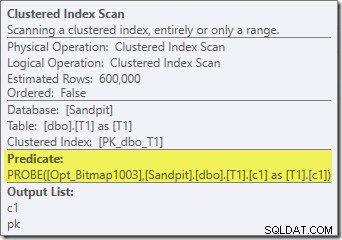
Skärmdumpen ovan visar den färdiga bitmappen som kontrolleras som en del av Clustered Index Scan i tabell T1. Eftersom källkolumnen är ett heltal (en bigint skulle också fungera) skjuts bitmappskontrollen hela vägen in i lagringsmotorn (som indikeras av "INROW"-kvalificeraren) istället för att kontrolleras av frågeprocessorn. Mer generellt kan bitmappen appliceras på vilken operatör som helst på probsidan, från växeln och nedåt. Hur långt frågeprocessorn kan driva bitmappen beror på typen av kolumn och versionen av SQL Server.
För att slutföra analysen av huvuddragen i denna utförandeplan måste vi titta på planen efter utförande ('faktisk'):
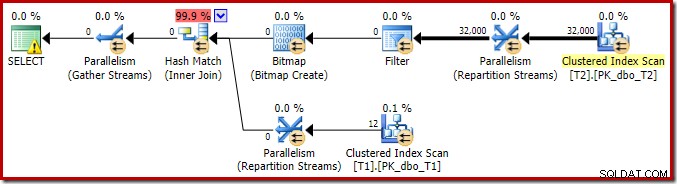
Det första att lägga märke till är fördelningen av rader över trådar mellan T2-skanningen och Repartition Streams-utbytet omedelbart ovanför det. Vid en testkörning såg jag följande distribution på ett system med fyra logiska processorer:
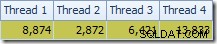
Fördelningen är inte speciellt jämn, vilket ofta är fallet för en parallell skanning på ett relativt litet antal rader, men åtminstone alla trådar fick en del arbete. Trådfördelningen mellan samma Repartition Streams-utbyte och filtret är mycket olika:
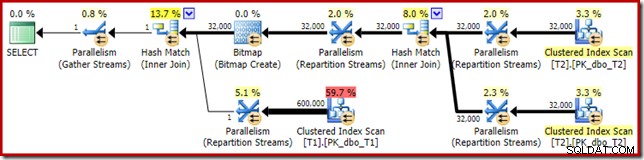
Detta visar att alla 32 000 rader från tabell T2 behandlades av en enda tråd. För att se varför måste vi titta på bytesegenskaperna:

Detta utbyte, liksom det på probesidan av hash-join, måste säkerställa att rader med samma join-nyckelvärden hamnar i samma instans av hash-join. På DOP 4 finns det fyra hash-joins, var och en med sin egen hashtabell. För korrekta resultat måste rader på byggsidan och rader på sondens sida med samma kopplingsnycklar komma fram till samma hash-koppling; annars kan vi kontrollera en rad på probsidan mot fel hashtabell.
I en parallell plan i radläge uppnår SQL Server detta genom att partitionera om båda ingångarna med samma hashfunktion på join-kolumnerna. I det aktuella fallet är kopplingen på kolumn c1, så ingångarna fördelas över trådar genom att tillämpa en hashfunktion (partitioneringstyp:hash) på kopplingsnyckelkolumnen (c1). Problemet här är att kolumn c1 bara innehåller ett enda värde – null – i tabell T2, så alla 32 000 rader ges samma hashvärde, eftersom alla hamnar i samma tråd.
Den goda nyheten är att inget av detta verkligen spelar någon roll för den här frågan. Omskrivningsfiltret efter optimering eliminerar alla rader innan mycket arbete är gjort. På min bärbara dator körs frågan ovan (som inte ger några resultat, som förväntat) på cirka 70 ms .
Sammanfogar tre bord
För det andra testet lägger vi till en extra join från tabell T2 till sig själv på dess primärnyckel:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Detta ändrar inte de logiska resultaten av frågan, men det ändrar exekveringsplanen:
Som förväntat har självkopplingen av tabell T2 på dess primärnyckel ingen effekt på antalet rader som kvalificerar sig från den tabellen:
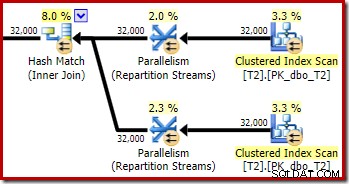
Fördelningen av rader över trådar är också bra i detta planavsnitt. För skanningarna liknar den tidigare eftersom den parallella skanningen distribuerar rader till trådar på begäran. Exchange-ompartitionen baseras på en hash av join-nyckeln, som är pk-kolumnen den här gången. Med tanke på intervallet för olika pk-värden är den resulterande trådfördelningen också mycket jämn:
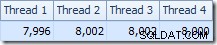
Om vi vänder oss till det mer intressanta avsnittet av den beräknade planen, finns det några skillnader från testet med två tabeller:

Än en gång, slutar växeln på byggsidan med att dirigera alla rader till samma tråd eftersom c1 är kopplingsnyckeln, och därav partitioneringskolumnen för Repartition Streams-växlingarna (kom ihåg att c1 är null för alla rader i tabell T2).
Det finns två andra viktiga skillnader i denna del av planen jämfört med föregående test. För det första finns det inget filter för att ta bort null-c1-rader från byggsidan av hash-join. Förklaringen till det är knuten till den andra skillnaden – bitmappen har ändrats, även om det inte är uppenbart från bilden ovan:
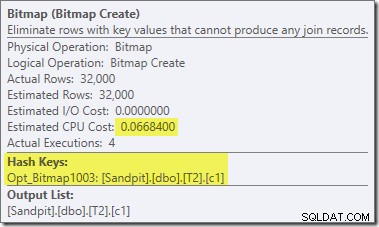
Detta är en Opt_Bitmap, inte en bitmap. Skillnaden är att denna bitmapp introducerades under kostnadsbaserad optimering, inte genom en omskrivning i sista minuten. Mekanismen som tar hänsyn till optimerade bitmappar är associerad med bearbetning av star-join-frågor. Stjärnkopplingslogiken kräver minst tre sammanfogade tabeller, så detta förklarar varför en optimerad bitmapp beaktades inte i exemplet med två tabeller.
Denna optimerade bitmapp har en uppskattad CPU-kostnad som inte är noll och påverkar direkt den övergripande planen som väljs av optimeraren. Dess effekt på probe-sidans kardinalitetsuppskattning kan ses hos Repartition Streams-operatören:
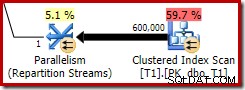
Notera att kardinalitetseffekten ses vid utbytet, även om bitmappen så småningom trycks hela vägen ner i lagringsmotorn ('INROW') precis som vi såg i det första testet (men notera Opt_Bitmap-referensen nu):
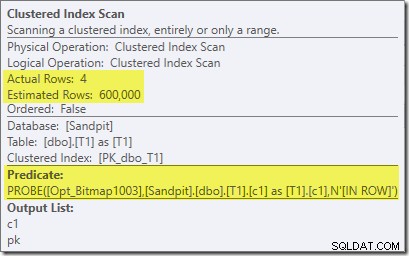
Planen efter genomförandet ('faktisk') är som följer:
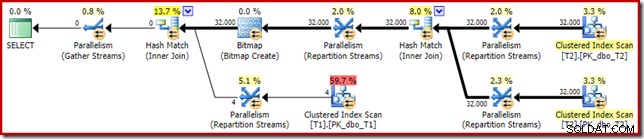
Den förutspådda effektiviteten av den optimerade bitmappen innebär att den separata omskrivningen efter optimering för nollfiltret inte tillämpas. Personligen tycker jag att detta är olyckligt eftersom att eliminera nollvärdena tidigt med ett filter skulle förneka behovet av att bygga bitmappen, fylla i hashtabellerna och utföra den bitmappsförbättrade skanningen av tabell T1. Ändå bestämmer optimeraren något annat och det finns bara inget att bråka med i det här fallet.
Trots den extra självkopplingen av tabell T2, och det extra arbetet som är förknippat med det saknade filtret, ger denna exekveringsplan fortfarande det förväntade resultatet (inga rader) på kort tid. En typisk körning på min bärbara dator tar cirka 200 ms .
Ändra datatyp
För detta tredje test kommer vi att ändra datatypen för kolumn c1 i båda tabellerna från heltal till decimal. Det är inget speciellt med detta val; samma effekt kan ses med vilken numerisk typ som helst som inte är heltal eller bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Återanvända sökfrågan med tre kopplingar:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Den beräknade genomförandeplanen ser mycket bekant ut:
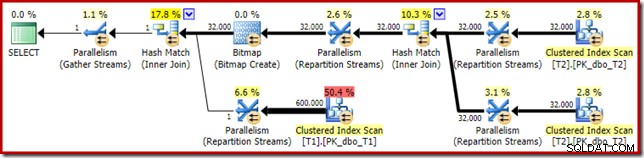
Bortsett från det faktum att den optimerade bitmappen inte längre kan tillämpas 'INROW' av lagringsmotorn på grund av förändringen av datatyp, är exekveringsplanen i huvudsak identisk. Infångningen nedan visar förändringen i skanningsegenskaper:
Tyvärr påverkas prestandan ganska dramatiskt. Den här frågan körs inte på 70 ms eller 200 ms, utan på cirka 20 minuter . I testet som gav följande plan efter körning var körtiden faktiskt 22 minuter och 29 sekunder:

Den mest uppenbara skillnaden är att Clustered Index Scan i tabell T1 returnerar 300 000 rader även efter att det optimerade bitmappsfiltret har tillämpats. Detta är vettigt, eftersom bitmappen är byggd på rader som bara innehåller nollor i c1-kolumnen. Bitmappen tar bort rader som inte är noll från T1-skanningen och lämnar bara de 300 000 raderna med nollvärden för c1. Kom ihåg att hälften av raderna i T1 är null.
Trots det verkar det konstigt att sammanfogning av 32 000 rader med 300 000 rader tar över 20 minuter. Om du undrade, var en CPU-kärna kopplad till 100 % under hela körningen. Förklaringen till denna dåliga prestanda och extrema resursanvändning bygger på några idéer som vi utforskade tidigare:
Vi vet till exempel redan att trots de parallella exekveringsikonerna hamnar alla rader från T2 på samma tråd. Som en påminnelse kräver den parallella hash-kopplingen i radläge ompartitionering på kopplingskolumnerna (c1). Alla rader från T2 har samma värde – null – i kolumn c1, så alla rader hamnar på samma tråd. På samma sätt har alla rader från T1 som passerar bitmappsfiltret också noll i kolumn c1, så de partitioneras också om till samma tråd. Detta förklarar varför en enda kärna gör allt arbete.
Det kan fortfarande tyckas orimligt att hash-sammanfogning av 32 000 rader med 300 000 rader ska ta 20 minuter, särskilt eftersom sammanfogningskolumnerna på båda sidor är null och inte kommer att gå med ändå. För att förstå detta måste vi tänka på hur denna hash-join fungerar.
Bygginmatningen (de 32 000 raderna) skapar en hashtabell med hjälp av join-kolumnen, c1. Eftersom varje build-side-rad innehåller samma värde (null) för join-kolumn c1, betyder detta att alla 32 000 rader hamnar i samma hash-bucket. När hash-sammanfogningen växlar till sondering för matchningar, hashas varje rad på sondsidan med en noll c1-kolumn också till samma hink. Hash-anslutningen måste sedan kontrollera alla 32 000 poster i den hinken för en matchning.
Att kontrollera de 300 000 probraderna resulterar i att 32 000 jämförelser görs 300 000 gånger. Detta är det värsta fallet för en hash-join:Alla byggda sidorader hash till samma hink, vilket resulterar i vad som i huvudsak är en kartesisk produkt. Detta förklarar den långa exekveringstiden och konstant 100 % processorutnyttjande eftersom hashen följer den långa hash-bucket-kedjan.
Denna dåliga prestanda hjälper till att förklara varför omskrivningen efter optimering för att eliminera nollvärden på bygginmatningen till en hash-join existerar. Det är olyckligt att filtret inte användes i det här fallet.
Lösningar
Optimeraren väljer denna planform eftersom den felaktigt uppskattar att den optimerade bitmappen kommer att filtrera bort alla rader från tabell T1. Även om denna uppskattning visas vid uppdelningsströmmarna istället för Clustered Index Scan, är detta fortfarande grunden för beslutet. Som en påminnelse är här det relevanta avsnittet av förutförandeplanen igen:
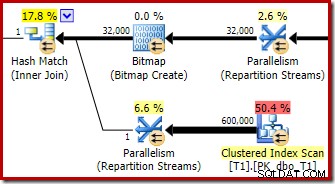
Om detta vore en korrekt uppskattning skulle det inte ta någon tid alls att bearbeta hash-join. Det är olyckligt att selektivitetsuppskattningen för den optimerade bitmappen är så mycket felaktig när datatypen inte är ett enkelt heltal eller bigint. Det verkar som om en bitmapp byggd på en heltals- eller bigint-nyckel också kan filtrera bort null-rader som inte kan gå med. Om så verkligen är fallet är detta en viktig anledning att föredra heltals- eller bigint-sammanfogningskolumner.
Lösningarna som följer är till stor del baserade på idén att eliminera de problematiska optimerade bitmapparna.
Serial exekvering
Ett sätt att förhindra att optimerade bitmappar övervägs är att kräva en icke-parallell plan. Radlägesbitmappsoperatorer (optimerade eller inte) ses bara i parallella planer:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Den frågan uttrycks med något annorlunda syntax med en FORCE ORDER-tips för att generera en planform som är lättare att jämföra med de tidigare parallella planerna. Den väsentliga funktionen är MAXDOP 1-tipset.
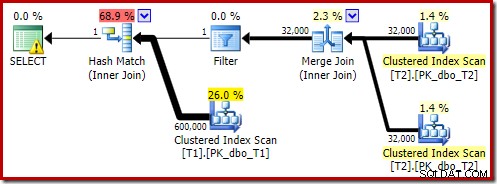
Den beräknade planen visar att omskrivningsfiltret efter optimering återinförs:
Den efterexekverade versionen av planen visar att den filtrerar bort alla rader från bygginmatningen, vilket innebär att söksidans skanning kan hoppas över helt:
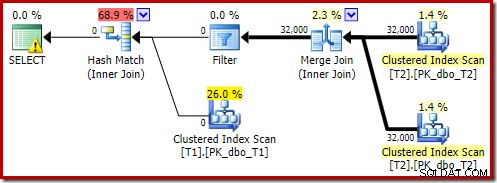
Som du kan förvänta dig körs den här versionen av frågan väldigt snabbt - cirka 20 ms i genomsnitt för mig. Vi kan uppnå en liknande effekt utan FORCE ORDER-tipset och frågeomskrivning:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
Optimeraren väljer en annan planform i det här fallet, med filtret placerat direkt ovanför skanningen av T2:
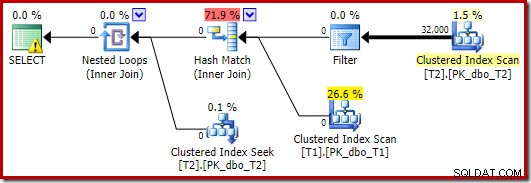
Detta körs ännu snabbare – på cirka 10 ms – som man kan förvänta sig. Naturligtvis skulle detta inte vara ett bra val om antalet rader som finns (och går att sammanfoga) var mycket större.
Stänga av optimerade bitmappar
Det finns ingen frågetips för att stänga av optimerade bitmappar, men vi kan uppnå samma effekt med ett par odokumenterade spårningsflaggor. Som alltid är detta bara för räntevärde; du skulle aldrig vilja använda dessa i ett riktigt system eller program:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);>
Den resulterande genomförandeplanen är:
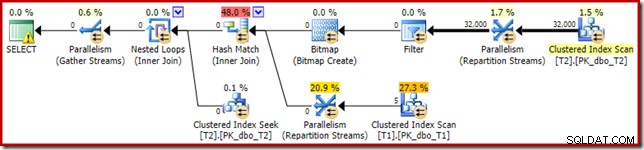
Bitmappen där är en omskrivningsbitmapp efter optimering, inte en optimerad bitmapp:
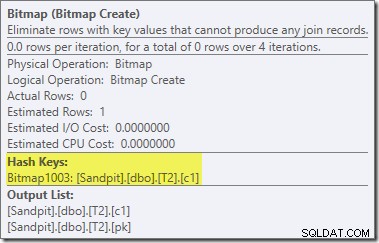
Notera nollkostnadsuppskattningarna och bitmappsnamnet (snarare än Opt_Bitmap). utan en optimerad bitmapp för att förvränga kostnadsuppskattningarna, aktiveras omskrivningen efter optimering för att inkludera ett null-avvisande filter. Den här exekveringsplanen löper på cirka 70 ms .
Samma exekveringsplan (med filter och icke-optimerad bitmapp) kan också skapas genom att inaktivera optimerarregeln som är ansvarig för att generera star join bitmappsplaner (igen, strikt odokumenterade och inte för verklig användning):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Inklusive ett explicit filter
Detta är det enklaste alternativet, men man skulle bara kunna tänka sig att göra det om man är medveten om de frågor som diskuterats hittills. Nu när vi vet att vi måste eliminera nollvärden från T2.c1 kan vi lägga till detta direkt i frågan:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
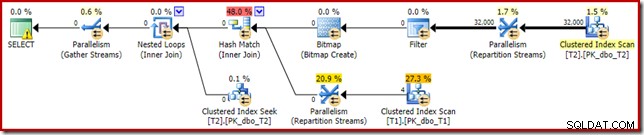
T2.c1 IS NOT NULL; -- New! Den resulterande beräknade genomförandeplanen är kanske inte riktigt vad du kan förvänta dig:
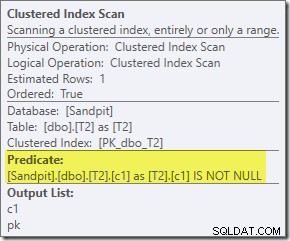
Det extra predikatet vi lade till har skjutits in i mitten Clustered Index Scan av T2:
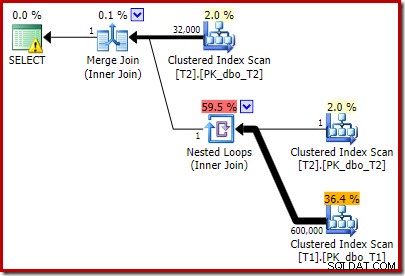
Planen efter genomförandet är:
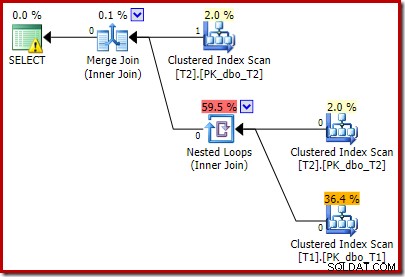
Lägg märke till att Merge Join stängs av efter att ha läst en rad från dess översta ingång och sedan misslyckas med att hitta en rad på dess nedre ingång, på grund av effekten av predikatet vi lade till. Clustered Index Scan av tabell T1 exekveras aldrig alls, eftersom Nested Loops-anslutningen aldrig får en rad på sin körinmatning. Det här sista frågeformuläret körs på en eller två millisekunder.
Sluta tankar
Den här artikeln har täckt en hel del mark för att utforska några mindre välkända frågeoptimerares beteenden och förklara orsakerna till extremt dåliga hash-join-prestanda i ett specifikt fall.
Det kan vara frestande att fråga varför optimeraren inte rutinmässigt lägger till noll-avvisande filter innan jämställdhetsanslutningar. Man kan bara anta att detta inte skulle vara fördelaktigt i tillräckligt vanliga fall. De flesta joins förväntas inte stöta på många null =noll-avslag, och rutinmässigt kan det bli kontraproduktivt att lägga till predikat, särskilt om många join-kolumner finns. För de flesta anslutningar är det förmodligen ett bättre alternativ (ur ett kostnadsmodellperspektiv) att avvisa nollvärden i kopplingsoperatören än att införa ett explicit filter.
Det verkar som att det finns ett försök att förhindra att de allra värsta fallen manifesterar sig genom omskrivningen efter optimering som är utformad för att avvisa rader med null-join innan de når build-ingången för en hash-join. Det verkar som att det finns en olycklig interaktion mellan effekten av optimerade bitmappsfilter och tillämpningen av denna omskrivning. Det är också olyckligt att när detta prestationsproblem uppstår är det mycket svårt att diagnostisera utifrån enbart genomförandeplanen.
För tillfället verkar det bästa alternativet vara medvetet om detta potentiella prestandaproblem med hash-kopplingar på null-kolumner, och att lägga till explicita noll-avvisande predikat (med en kommentar!) för att säkerställa att en effektiv exekveringsplan tas fram, om det behövs. Att använda en MAXDOP 1-tips kan också avslöja en alternativ plan med kontrollampan Filter närvarande.
Som en allmän regel tenderar frågor som ansluter sig till kolumner av heltalstyp och letar efter data som finns att passa optimeringsmodellen och exekveringsmotorns kapacitet snarare än alternativen.
Bekräftelser
Jag vill tacka SQL_Sasquatch (@sqL_handLe) för hans tillåtelse att svara på hans ursprungliga artikel med en teknisk analys. Provdatan som används här är starkt baserad på den artikeln.
Jag vill också tacka Rob Farley (blogg | twitter) för våra tekniska diskussioner genom åren, och särskilt en i januari 2015 där vi diskuterade implikationerna av extra noll-avvisande predikat för equi-joins. Rob har skrivit om relaterade ämnen flera gånger, inklusive i Inverse Predicates – titta åt båda hållen innan du korsar.