För nästan ett år sedan publicerade jag min lösning för sidnumrering i SQL Server, vilket innebar att jag använde en CTE för att hitta nyckelvärdena för uppsättningen rader i fråga och sedan gå tillbaka från CTE till källtabellen för att hämta de andra kolumnerna för just den "sidan" med rader. Detta visade sig vara mest fördelaktigt när det fanns ett smalt index som stödde beställningen som användaren begärde, eller när beställningen baserades på klustringsnyckeln, men till och med presterade lite bättre utan ett index för att stödja den önskade sorteringen.
Sedan dess har jag undrat om ColumnStore-index (både klustrade och icke-klustrade) kan hjälpa något av dessa scenarier. TL;DR :Baserat på detta experiment isolerat är svaret på rubriken på det här inlägget ett rungande NEJ . Om du inte vill se testinställningarna, koden, exekveringsplanerna eller graferna, hoppa gärna till min sammanfattning, tänk på att min analys är baserad på ett mycket specifikt användningsfall.
Inställningar
På en ny virtuell dator med SQL Server 2016 CTP 3.2 (13.0.900.73) installerad körde jag igenom ungefär samma setup som tidigare, bara denna gång med tre tabeller. Först en traditionell tabell med en smal klustringsnyckel och flera stödjande index:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Därefter en tabell med ett klustrat ColumnStore-index:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
Och slutligen, en tabell med ett icke-klustrat ColumnStore-index som täcker alla kolumner:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Lägg märke till att för båda tabellerna med ColumnStore-index utelämnade jag indexet som skulle stödja snabbare sökningar på sorteringen "Telefonbok" (efternamn, förnamn).
Testdata
Jag fyllde sedan i den första tabellen med 1 000 000 slumpmässiga rader, baserat på ett skript som jag har återanvänt från tidigare inlägg:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Sedan använde jag den tabellen för att fylla de andra två med exakt samma data och byggde om alla index:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Den totala storleken för varje tabell:
| Tabell | Reserverad | Data | Index |
|---|---|---|---|
| Kunder | 463 200 kB | 154 344 KB | 308 576 kB |
| Customers_CCI | 117 280 kB | 30 288 KB | 86 536 KB |
| Customers_NCCI | 349 480 KB | 154 344 KB | 194 976 kB |
Och antalet rader/sidor för de relevanta indexen (det unika indexet på e-post var mer för att jag skulle vara barnvakt för mitt eget datagenereringsskript än något annat):
| Tabell | Index | rader | Sidor |
|---|---|---|---|
| Kunder | PK_Kunder | 1 000 000 | 19 377 |
| Kunder | Telefonbok_Kunder | 1 000 000 | 17 209 |
| Kunder | Active_Customers | 808 012 | 13 977 |
| Customers_CCI | PK_CustomersCCI | 1 000 000 | 2 737 |
| Customers_CCI | Customers_CCI | 1 000 000 | 3 826 |
| Customers_NCCI | PK_CustomersNCCI | 1 000 000 | 19 377 |
| Customers_NCCI | Customers_NCCI | 1 000 000 | 16 971 |
Procedurer
Sedan, för att se om ColumnStore-indexen skulle slå in och göra något av scenarierna bättre, körde jag samma uppsättning frågor som tidigare, men nu mot alla tre tabellerna. Jag blev åtminstone lite smartare och gjorde två lagrade procedurer med dynamisk SQL för att acceptera tabellkällan och sorteringsordningen. (Jag är väl medveten om SQL-injektion; det här är inte vad jag skulle göra i produktionen om dessa strängar kom från en slutanvändare, så ta det inte som en rekommendation att göra det. Jag litar tillräckligt på mig själv på min sluten miljö att det inte är ett problem för dessa tester.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Sedan piskade jag upp lite mer dynamisk SQL för att generera alla kombinationer av anrop jag skulle behöva göra för att anropa både de gamla och nya lagrade procedurerna, i alla tre önskade sorteringsordningarna och vid olika sidnummer (för att simulera behov en sida nära början, mitten och slutet av sorteringsordningen). Så att jag kunde kopiera PRINT mata ut och klistra in den i SQL Sentry Plan Explorer för att få körtidsmätningar, jag körde den här batchen två gånger, en gång med procedures CTE med P_Old , och sedan igen med P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Detta producerade utdata så här (36 anrop totalt för den gamla metoden (P_Old ), och 36 anropar den nya metoden (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Jag vet, det här är väldigt besvärligt; vi kommer snart till punchline, jag lovar.
Resultat
Jag tog de två uppsättningarna med 36 uttalanden och startade två nya sessioner i Plan Explorer, och körde varje uppsättning flera gånger för att säkerställa att vi fick data från en varm cache och tog medelvärden (jag kunde jämföra kall och varm cache också, men jag tror att det finns tillräckligt med variabler här).
Jag kan direkt berätta ett par enkla fakta utan att ens visa dig stödjande grafer eller planer:
- I inget scenario slog den "gamla" metoden den nya CTE-metoden Jag främjade i mitt tidigare inlägg, oavsett vilken typ av index som fanns. Så det gör det enkelt att praktiskt taget ignorera hälften av resultaten, åtminstone när det gäller varaktighet (vilket är det metriska slutanvändarna bryr sig mest om).
- Inget ColumnStore-index klarade sig bra när man sökte mot slutet av resultatet – de gav bara fördelar i början, och bara i ett par fall.
- Vid sortering efter primärnyckel (klustrade eller inte), närvaron av ColumnStore-index hjälpte inte – igen, när det gäller varaktighet.
Med dessa sammanfattningar ur vägen, låt oss ta en titt på några tvärsnitt av varaktighetsdata. Först, resultaten av frågan sorterade efter förnamn fallande, sedan e-post, utan hopp om att använda ett befintligt index för sortering. Som du kan se i diagrammet var prestandan inkonsekvent – med lägre sidnummer gick den icke-klustrade ColumnStore bäst; vid högre sidnummer vann det traditionella indexet alltid:
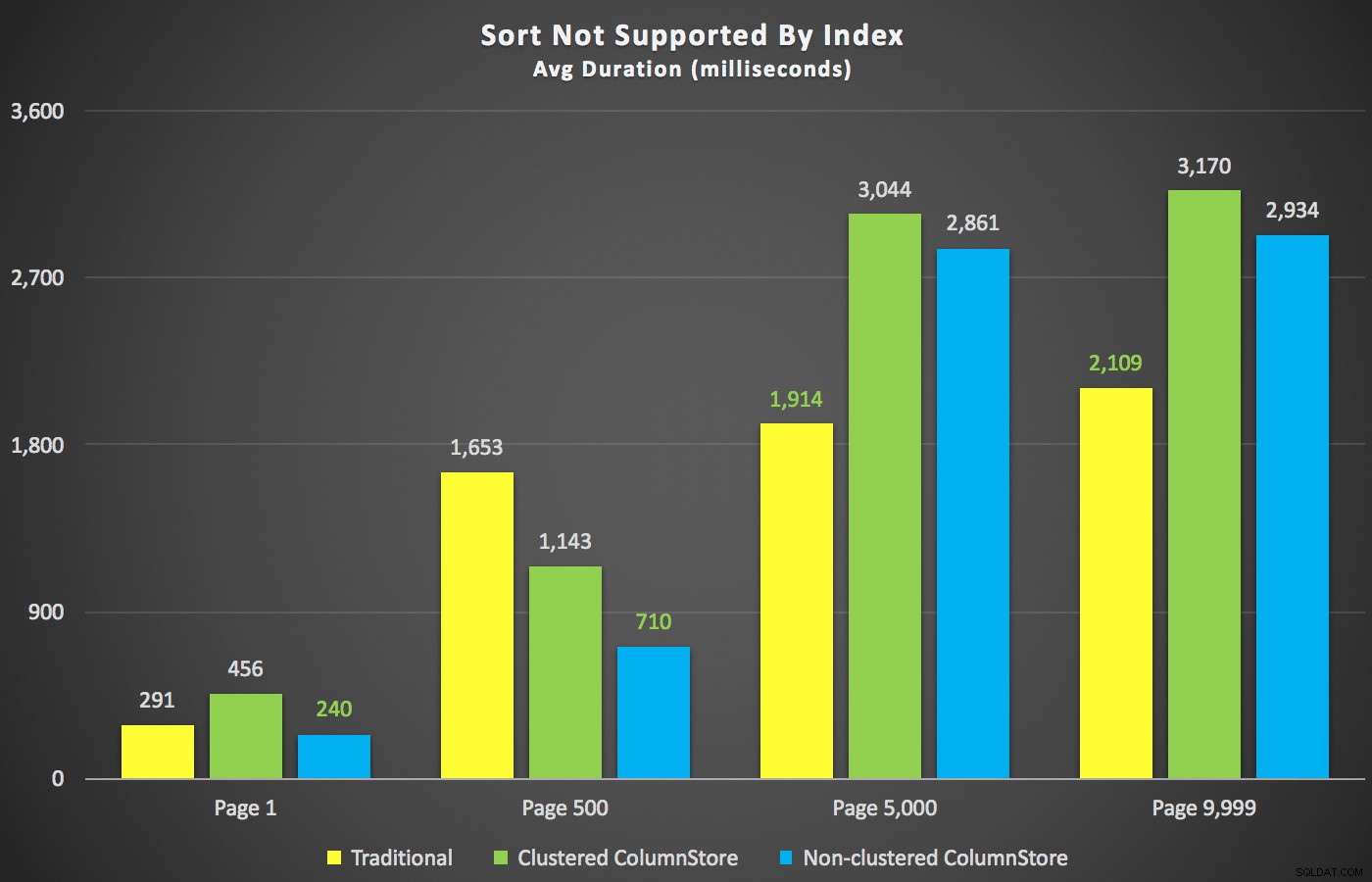 Längd (millisekunder) för olika sidnummer och olika indextyper
Längd (millisekunder) för olika sidnummer och olika indextyper
Och sedan de tre planerna som representerar de tre olika typerna av index (med gråskala lagt till av Photoshop för att belysa de stora skillnaderna mellan planerna):
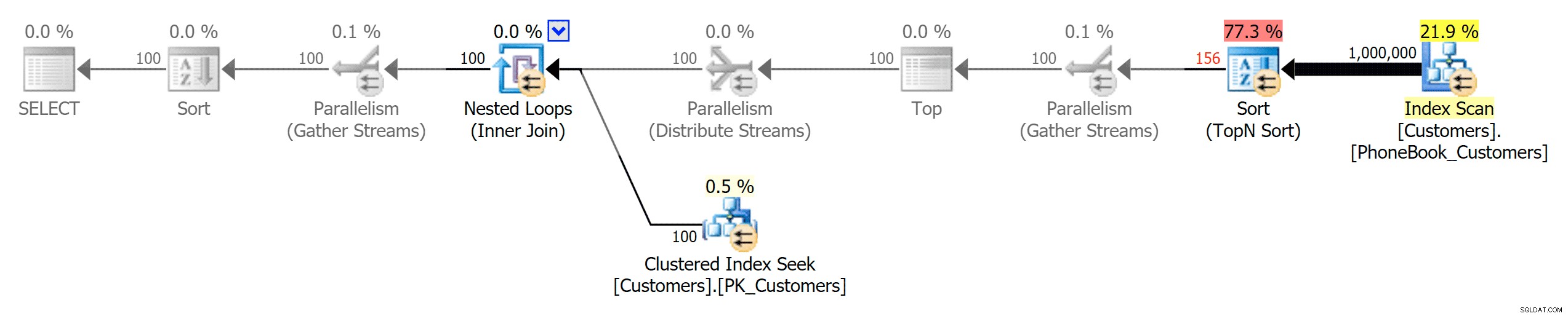 Planera för traditionellt index
Planera för traditionellt index
 Planera för klustrade ColumnStore-index
Planera för klustrade ColumnStore-index
 Planera för icke-klustrade ColumnStore-index
Planera för icke-klustrade ColumnStore-index
Ett scenario jag var mer intresserad av, redan innan jag började testa, var telefonbokssortering (efternamn, förnamn). I det här fallet var ColumnStore-indexen faktiskt ganska skadliga för resultatet:
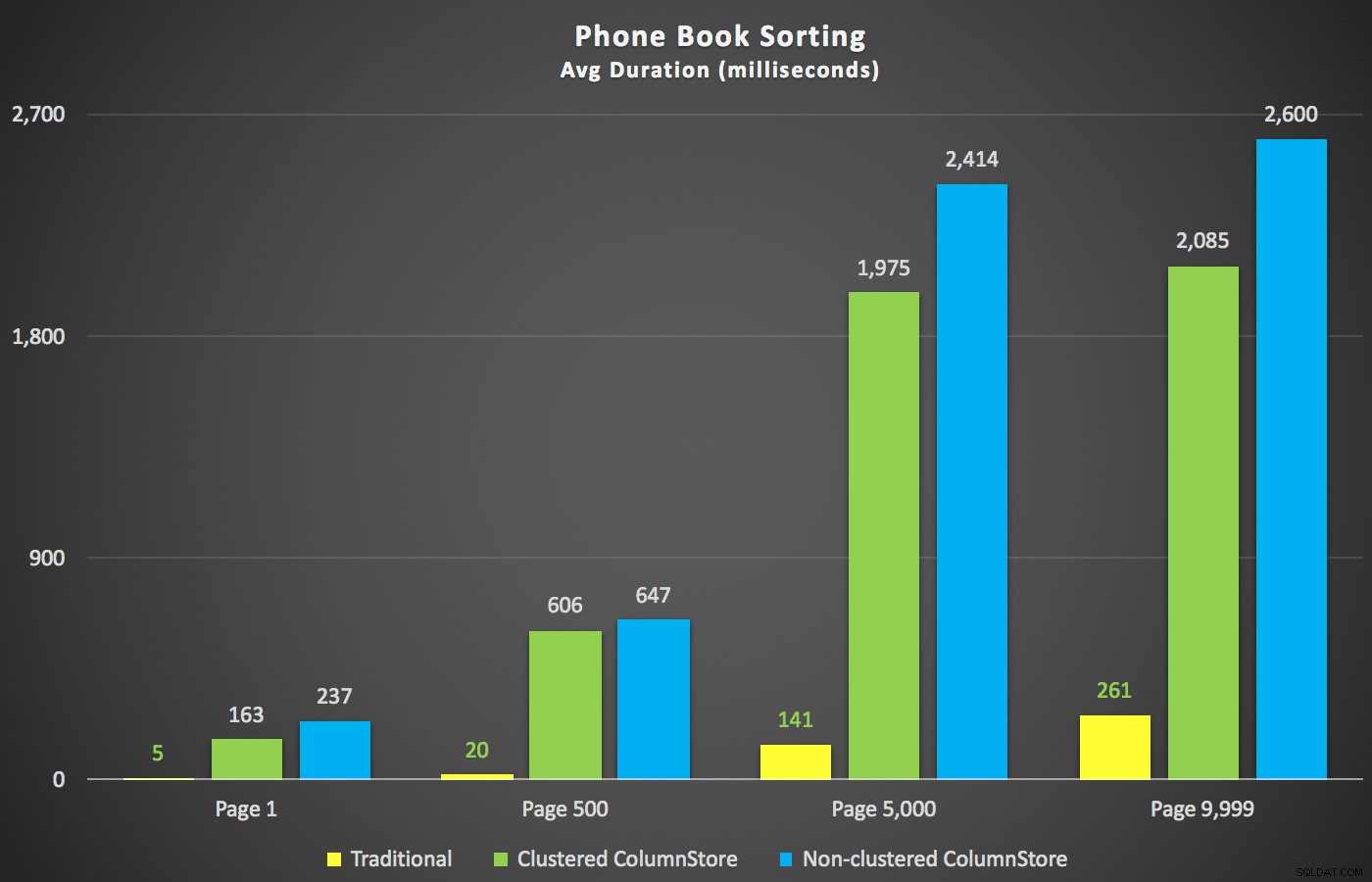
ColumnStore-planerna här är nästan spegelbilder till de två ColumnStore-planerna som visas ovan för den sorten som inte stöds. Anledningen är densamma i båda fallen:dyra skanningar eller sorteringar på grund av brist på ett sorteringsstödjande index.
Så härnäst skapade jag stödjande "PhoneBook"-index på tabellerna med ColumnStore-indexen också, för att se om jag kunde övertala en annan plan och/eller snabbare exekveringstider i något av dessa scenarier. Jag skapade dessa två index och byggde sedan om igen:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Här var de nya varaktigheterna:
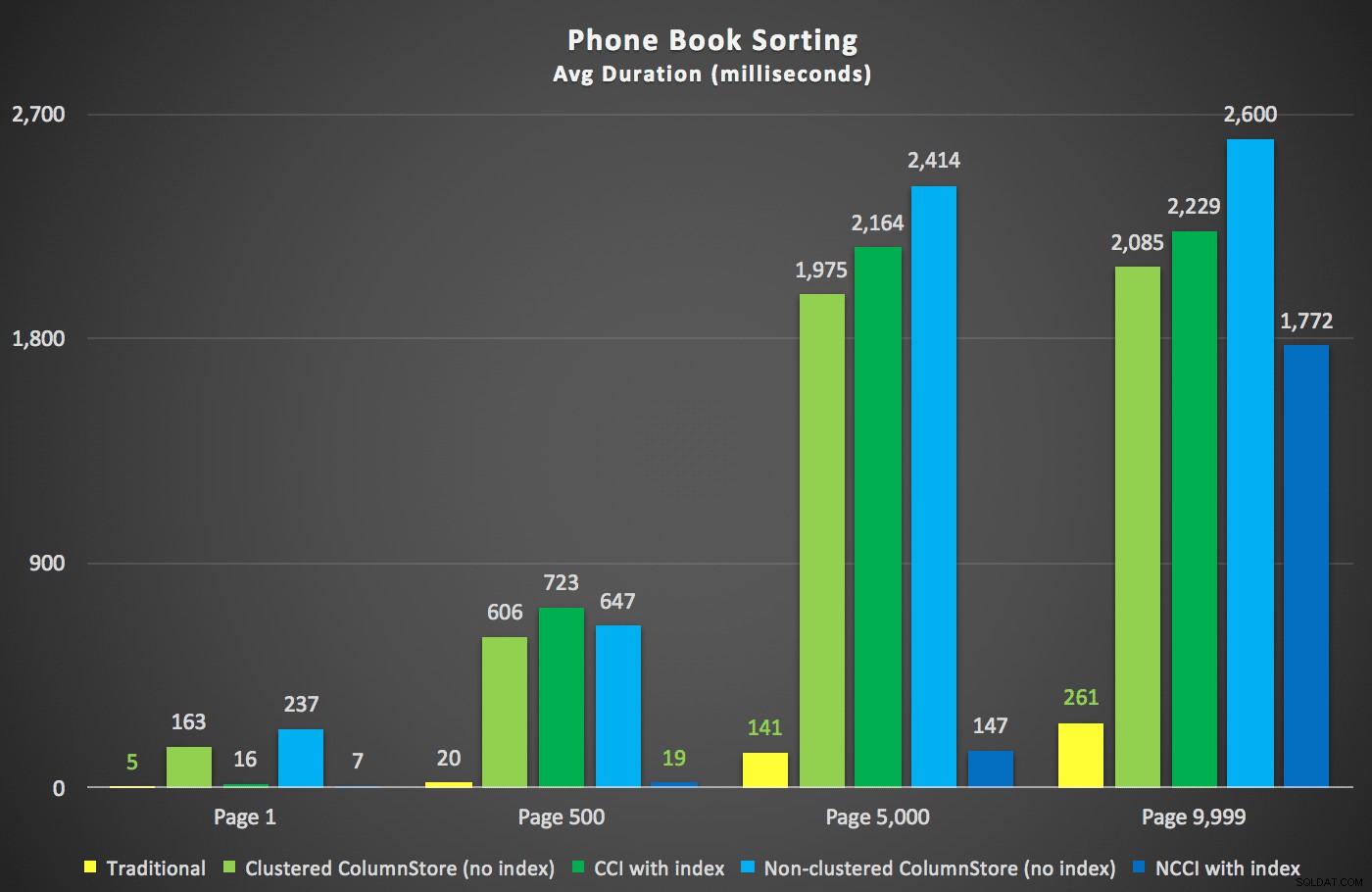
Mest intressant här är att nu sökningsfrågan mot tabellen med det icke-klustrade ColumnStore-indexet verkar hålla jämna steg med det traditionella indexet, tills vi kommer bortom mitten av tabellen. När vi tittar på planerna kan vi se att på sidan 5 000 används en traditionell indexskanning och ColumnStore-indexet ignoreras helt:
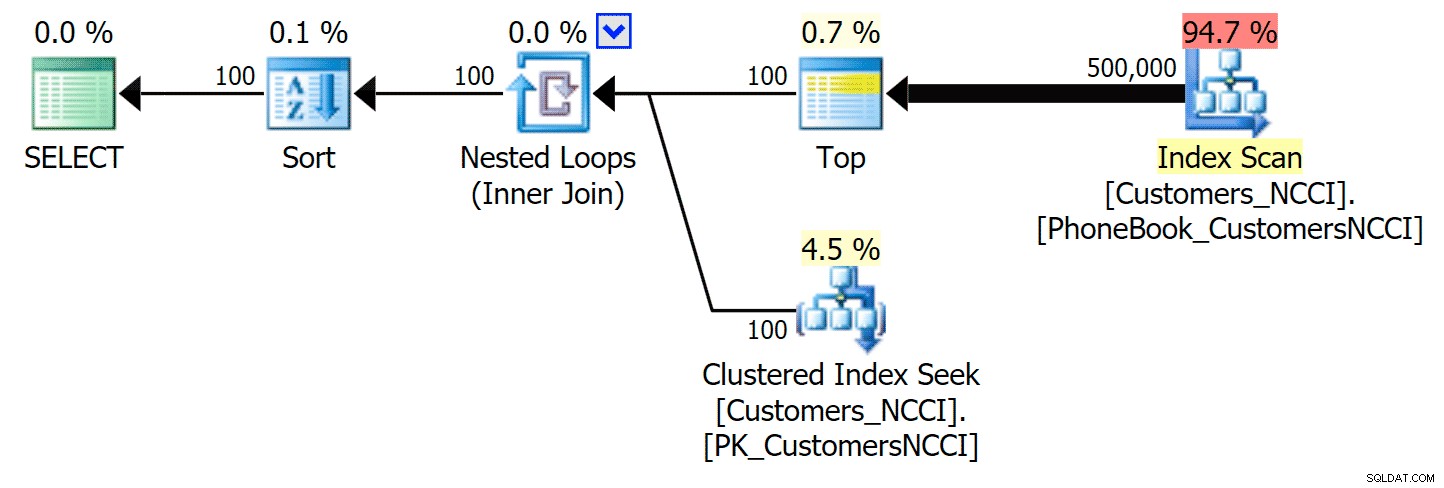 Telefonboksplan som ignorerar det icke-klustrade ColumnStore-indexet
Telefonboksplan som ignorerar det icke-klustrade ColumnStore-indexet
Men någonstans mellan mittpunkten på 5 000 sidor och "slutet" av tabellen på 9 999 sidor har optimeraren nått en slags tipppunkt och väljer nu – för exakt samma fråga – att skanna det icke-klustrade ColumnStore-indexet :
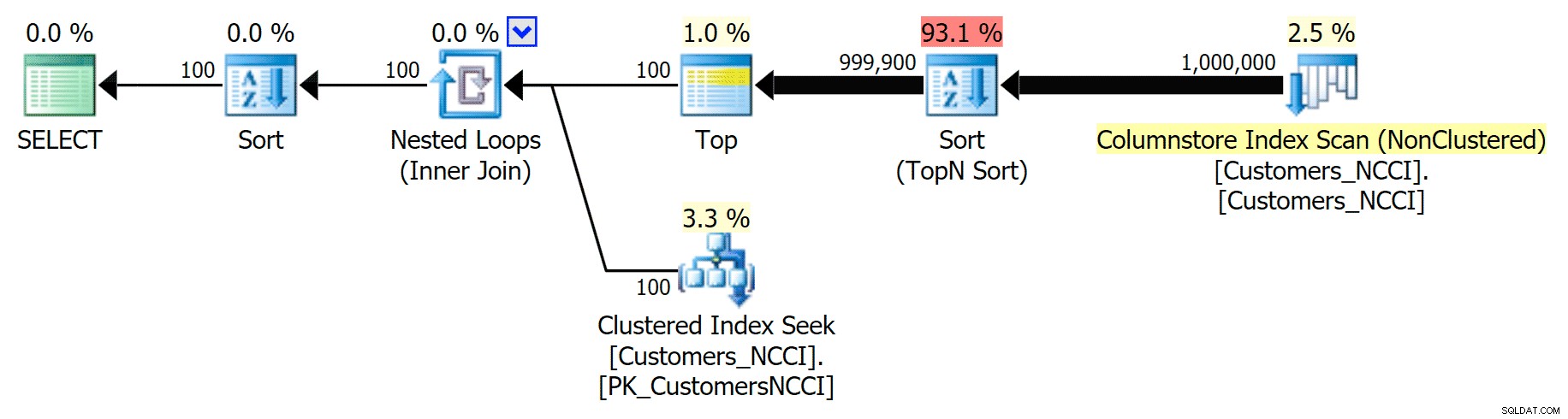 Tipps för telefonboksplanen och använder ColumnStore-indexet
Tipps för telefonboksplanen och använder ColumnStore-indexet
Detta visar sig vara ett inte så bra beslut av optimeraren, främst på grund av kostnaden för sorteringsoperationen. Du kan se hur mycket bättre varaktigheten blir om du antyder det vanliga indexet:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Detta ger följande plan, nästan identisk med den första planen ovan (en något högre kostnad för skanningen, dock helt enkelt för att det finns mer utdata):
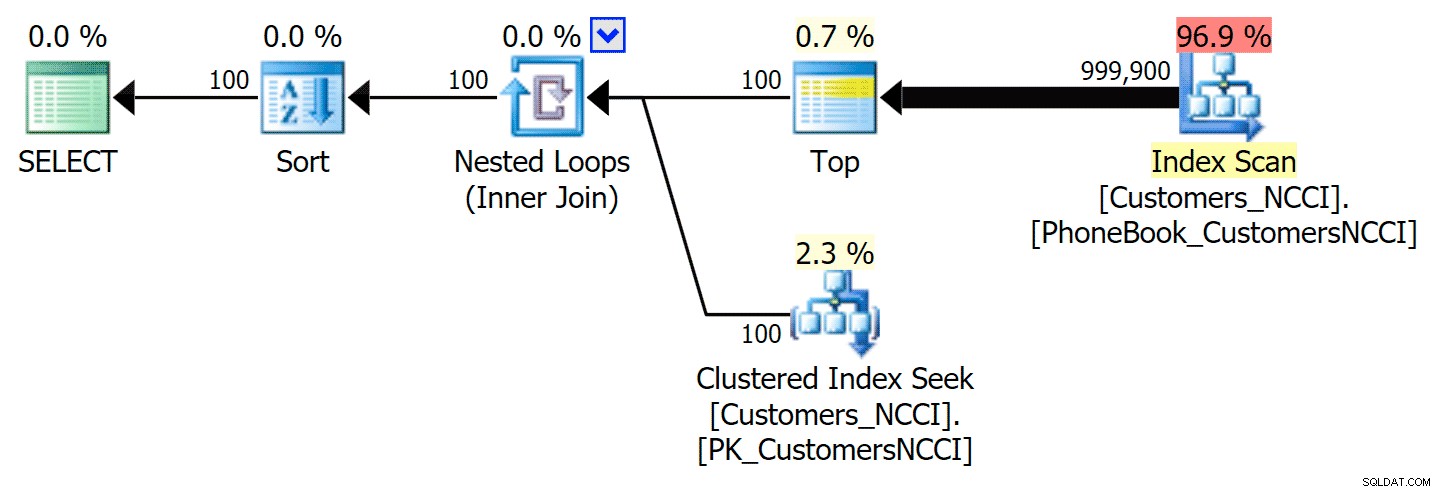 Telefonbokplan med antydt index
Telefonbokplan med antydt index
Du kan uppnå samma sak med OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) istället för det explicita indextipset. Tänk bara på att detta är samma sak som att inte ha ColumnStore-indexet där i första hand.
Slutsats
Även om det finns ett par kantfall ovan där ett ColumnStore-index (knappt) kan löna sig, verkar det inte som att de passar bra för detta specifika sidnumreringsscenario. Jag tror, viktigast av allt, medan ColumnStore visar betydande utrymmesbesparingar på grund av komprimering, är körtidsprestandan inte fantastisk på grund av sorteringskraven (även om dessa sorteringar beräknas köras i batchläge, en ny optimering för SQL Server 2016).
I allmänhet skulle detta kunna göra med mycket mer tid som spenderas på forskning och testning; i piggy-backning av tidigare artiklar, ville jag ändra så lite som möjligt. Jag skulle till exempel gärna vilja hitta den vändpunkten, och jag skulle också vilja erkänna att det här inte är några tester i stor skala (på grund av VM-storlek och minnesbegränsningar), och att jag lät dig gissa om mycket körtidsmåtten (mest för korthetens skull, men jag vet inte att ett diagram med läsningar som inte alltid är proportionella mot varaktigheten verkligen skulle berätta för dig). Dessa tester förutsätter också lyxen med SSD:er, tillräckligt med minne, en alltid varm cache och en enanvändarmiljö. Jag skulle verkligen vilja utföra ett större batteri av tester mot mer data, på större servrar med långsammare diskar och instanser med mindre minne, hela tiden med simulerad samtidighet.
Som sagt, detta kan också bara vara ett scenario som ColumnStore inte är designat för att hjälpa till att lösa i första hand, eftersom den underliggande lösningen med traditionella index redan är ganska effektiv på att dra ut en smal uppsättning rader – inte precis ColumnStores styrhytt. En annan variabel att lägga till i matrisen är kanske sidstorlek – alla tester ovan drar 100 rader åt gången, men vad händer om vi är ute efter 10 000 eller 100 000 rader åt gången, oavsett hur stor den underliggande tabellen är?
Har du en situation där din OLTP-arbetsbelastning förbättrades helt enkelt genom att lägga till ColumnStore-index? Jag vet att de är designade för arbetsbelastningar i datalagerstil, men om du har sett fördelar någon annanstans skulle jag gärna höra om ditt scenario och se om jag kan införliva några differentiatorer i min testrigg.