När vi skriver en lagrad procedur vill vi ofta att den ska bete sig på olika sätt baserat på användarinmatning. Låt oss titta på följande exempel:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Denna lagrade procedur, som jag skapade i AdventureWorks2017-databasen, har två parametrar:@CustomerID och @SortOrder. Den första parametern, @CustomerID, påverkar raderna som ska returneras. Om ett specifikt kund-ID skickas till den lagrade proceduren, returnerar den alla beställningar (topp 10) för denna kund. Annars, om det är NULL, returnerar den lagrade proceduren alla beställningar (topp 10), oavsett kund. Den andra parametern, @SortOrder, bestämmer hur data ska sorteras – efter OrderDate eller SalesOrderID. Observera att endast de första 10 raderna kommer att returneras enligt sorteringsordningen.
Så användare kan påverka frågans beteende på två sätt – vilka rader som ska returneras och hur de sorteras. För att vara mer exakt finns det fyra olika beteenden för den här frågan:
- Returnera de 10 översta raderna för alla kunder sorterade efter OrderDate (standardbeteende)
- Returnera de 10 översta raderna för en specifik kund sorterade efter OrderDate
- Returnera de 10 översta raderna för alla kunder sorterade efter SalesOrderID
- Returnera de 10 översta raderna för en specifik kund sorterade efter SalesOrderID
Låt oss testa den lagrade proceduren med alla fyra alternativen och undersöka exekveringsplanen och statistiken IO.
Returnera de 10 bästa raderna för alla kunder sorterade efter orderdatum
Följande är koden för att exekvera den lagrade proceduren:
EXECUTE Sales.GetOrders; GO
Här är genomförandeplanen:
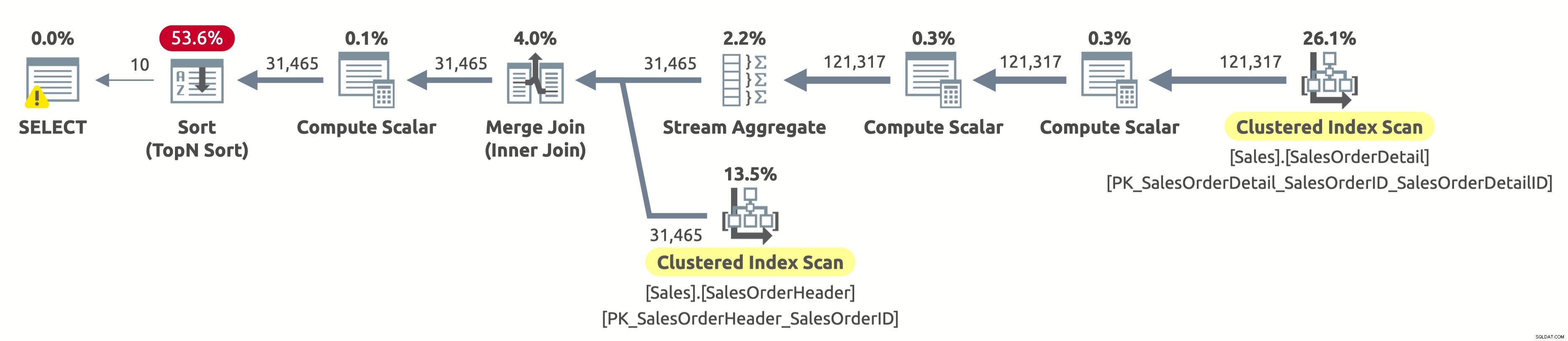
Eftersom vi inte har filtrerat efter kund måste vi skanna hela tabellen. Optimeraren valde att skanna båda tabellerna med hjälp av index på SalesOrderID, vilket möjliggjorde ett effektivt Stream Aggregate samt en effektiv Merge Join.
Om du kontrollerar egenskaperna för operatorn Clustered Index Scan i tabellen Sales.SalesOrderHeader hittar du följande predikat:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] som [SalesOrders].[CustomerID]=[ @CustomerID] ELLER [@CustomerID] ÄR NULL. Frågeprocessorn måste utvärdera detta predikat för varje rad i tabellen, vilket inte är särskilt effektivt eftersom det alltid kommer att utvärderas till sant.
Vi behöver fortfarande sortera all data efter OrderDate för att returnera de första 10 raderna. Om det fanns ett index på OrderDate, skulle optimeraren förmodligen ha använt det för att skanna endast de första 10 raderna från Sales.SalesOrderHeader, men det finns inget sådant index, så planen verkar bra med tanke på de tillgängliga indexen.
Här är utdata från statistik IO:
- Tabell 'SalesOrderHeader'. Scan count 1, logiskt läser 689
- Tabell 'SalesOrderDetail'. Scan count 1, logiskt läser 1248
Om du frågar varför det finns en varning på SELECT-operatören, så är det en överdriven beviljandevarning. I det här fallet beror det inte på att det finns ett problem i exekveringsplanen, utan snarare för att frågeprocessorn begärde 1 024 kB (vilket är minimum som standard) och använde endast 16 kB.
Ibland är plancaching inte en så bra idé
Därefter vill vi testa scenariot att returnera de 10 översta raderna för en specifik kund sorterade efter OrderDate. Nedan är koden:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Utförandeplanen är exakt densamma som tidigare. Den här gången är planen väldigt ineffektiv eftersom den skannar båda tabellerna bara för att returnera 3 beställningar. Det finns mycket bättre sätt att utföra den här frågan.
Anledningen, i det här fallet, är plancache. Exekveringsplanen genererades i den första exekveringen baserat på parametervärdena i den specifika exekveringen – en metod som kallas parametersniffning. Den planen lagrades i planens cache för återanvändning, och från och med nu kommer varje anrop till denna lagrade procedur att återanvända samma plan.
Detta är ett exempel där plancachelagring inte är en så bra idé. På grund av arten av denna lagrade procedur, som har 4 olika beteenden, förväntar vi oss att få en annan plan för varje beteende. Men vi har fastnat för en enda plan, som bara är bra för ett av de fyra alternativen, baserat på alternativet som användes i den första exekveringen.
Låt oss inaktivera plancachelagring för denna lagrade procedur, bara så att vi kan se den bästa planen som optimeraren kan komma med för vart och ett av de tre andra beteendena. Vi kommer att göra detta genom att lägga till WITH RECOMPILE till kommandot EXECUTE.
Returnera de 10 bästa raderna för en specifik kund sorterade efter orderdatum
Följande är koden för att returnera de 10 översta raderna för en specifik kund sorterade efter OrderDate:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Följande är genomförandeplanen:
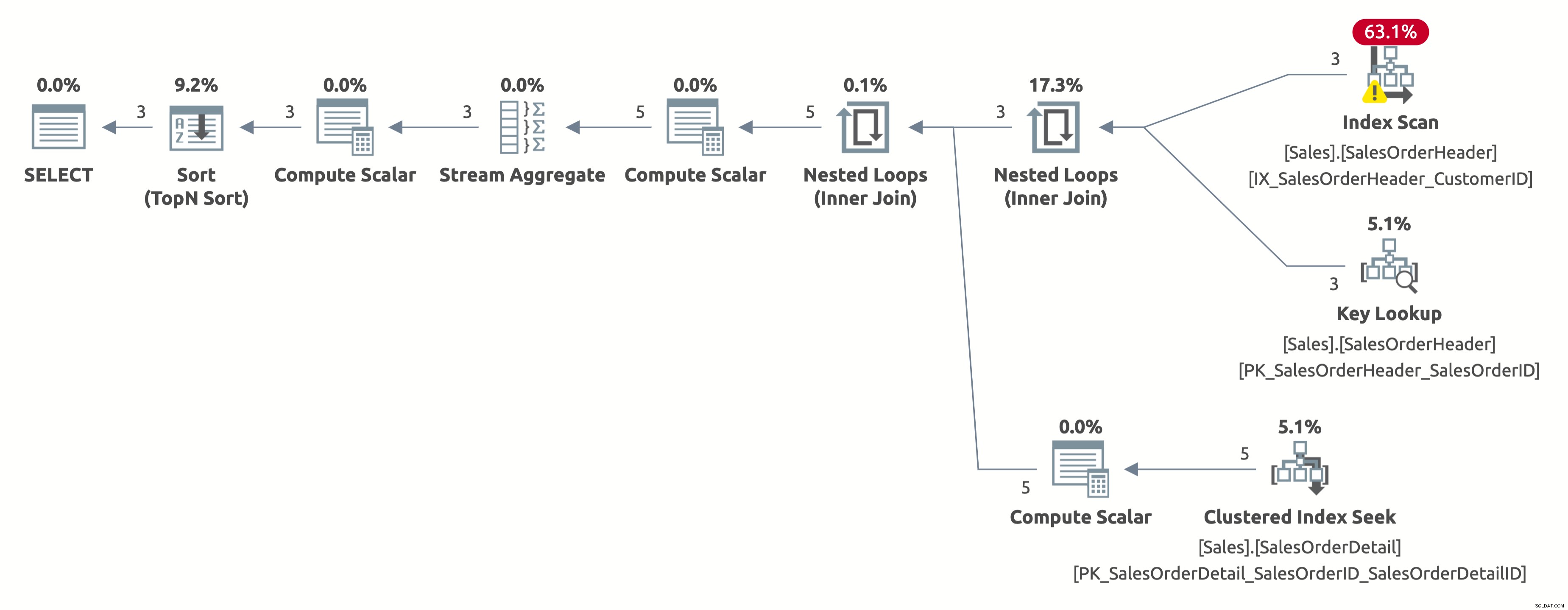
Den här gången får vi en bättre plan, som använder ett index på CustomerID. Optimeraren uppskattar korrekt 2,6 rader för Kund-ID =11006 (det faktiska antalet är 3). Men lägg märke till att den utför en indexsökning istället för en indexsökning. Den kan inte utföra en indexsökning eftersom den måste utvärdera följande predikat för varje rad i tabellen:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] som [SalesOrders].[CustomerID]=[@CustomerID ] ELLER [@Kund-ID] ÄR NULL.
Här är utdata från statistik IO:
- Tabell 'SalesOrderDetail'. Scan count 3, logiskt läser 9
- Tabell 'SalesOrderHeader'. Scan count 1, logiskt läser 66
Returnera de 10 bästa raderna för alla kunder sorterade efter försäljningsorder-ID
Följande är koden för att returnera de 10 översta raderna för alla kunder sorterade efter SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Följande är genomförandeplanen:
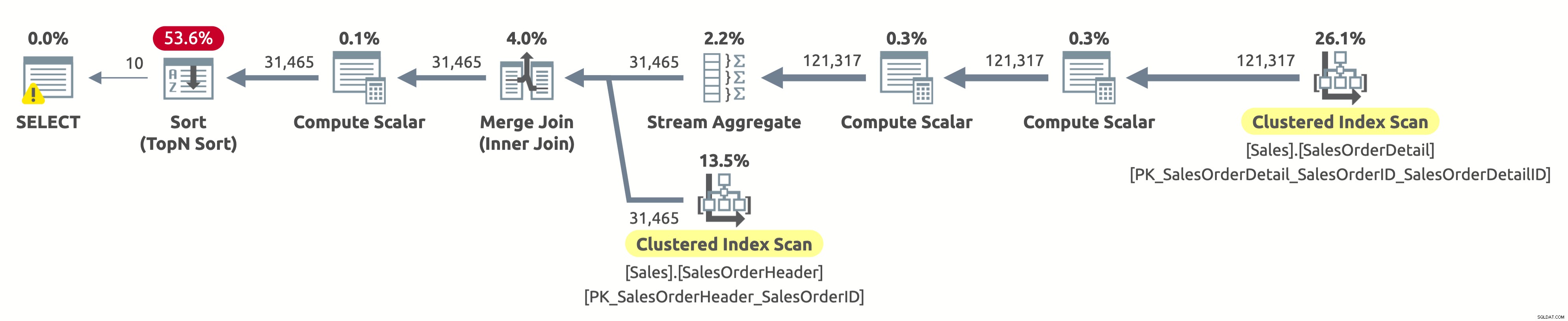
Hej, det här är samma utförandeplan som i det första alternativet. Men den här gången är något fel. Vi vet redan att de klustrade indexen på båda tabellerna är sorterade efter SalesOrderID. Vi vet också att planen skannar båda i den logiska ordningen för att behålla sorteringsordningen (egenskapen Ordered är satt till True). Operatören Merge Join behåller också sorteringsordningen. Eftersom vi nu ber om att sortera resultatet efter SalesOrderID, och det redan är sorterat på det sättet, varför måste vi då betala för en dyr sorteringsoperatör?
Tja, om du kollar sorteringsoperatorn kommer du att märka att den sorterar data enligt Expr1004. Och om du markerar Compute Scalar-operatorn till höger om sorteringsoperatorn, kommer du att upptäcka att Expr1004 är som följer:

Det är ingen vacker syn, jag vet. Detta är uttrycket som vi har i ORDER BY-satsen i vår fråga. Problemet är att optimeraren inte kan utvärdera detta uttryck vid kompilering, så den måste beräkna det för varje rad vid körning och sedan sortera hela postuppsättningen baserat på det.
Utdata från statistik IO är precis som i den första exekveringen:
- Tabell 'SalesOrderHeader'. Scan count 1, logiskt läser 689
- Tabell 'SalesOrderDetail'. Scan count 1, logiskt läser 1248
Returnera de 10 bästa raderna för en specifik kund sorterade efter SalesOrderID
Följande är koden för att returnera de 10 översta raderna för en specifik kund sorterade efter SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Utförandeplanen är densamma som i det andra alternativet (retur de 10 översta raderna för en specifik kund sorterade efter OrderDate). Planen har samma två problem, som vi redan har nämnt. Det första problemet är att utföra en indexsökning snarare än en indexsökning på grund av uttrycket i WHERE-satsen. Det andra problemet är att utföra en dyr sortering på grund av uttrycket i ORDER BY-satsen.
Så, vad ska vi göra?
Låt oss först påminna oss själva om vad vi har att göra med. Vi har parametrar som bestämmer strukturen på frågan. För varje kombination av parametervärden får vi en annan frågestruktur. När det gäller parametern @CustomerID är de två olika beteendena NULL eller NOT NULL, och de påverkar WHERE-satsen. När det gäller parametern @SortOrder finns det två möjliga värden, och de påverkar ORDER BY-satsen. Resultatet är fyra möjliga frågestrukturer, och vi skulle vilja ha en annan plan för var och en.
Sedan har vi två distinkta problem. Den första är plancaching. Det finns bara en enda plan för den lagrade proceduren, och den kommer att genereras baserat på parametervärdena i den första exekveringen. Det andra problemet är att även när en ny plan genereras är den inte effektiv eftersom optimeraren inte kan utvärdera de "dynamiska" uttrycken i WHERE-satsen och i ORDER BY-satsen vid kompileringstillfället.
Vi kan försöka lösa dessa problem på flera sätt:
- Använd en serie IF-ELSE-satser
- Dela upp proceduren i separata lagrade procedurer
- Använd ALTERNATIV (OMKOMPILERA)
- Generera frågan dynamiskt
Använd en serie IF-ELSE-satser
Tanken är enkel:istället för de "dynamiska" uttrycken i WHERE-satsen och i ORDER BY-satsen, kan vi dela upp exekveringen i fyra grenar med hjälp av IF-ELSE-satser – en gren för varje möjligt beteende.
Till exempel, följande är koden för den första grenen:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Detta tillvägagångssätt kan hjälpa till att skapa bättre planer, men det har vissa begränsningar.
För det första blir den lagrade proceduren ganska lång och det är svårare att skriva, läsa och underhålla. Och det är när vi bara har två parametrar. Om vi hade 3 parametrar skulle vi ha 8 grenar. Föreställ dig att du behöver lägga till en kolumn i SELECT-satsen. Du skulle behöva lägga till kolumnen i 8 olika frågor. Det blir en underhållsmardröm, med stor risk för mänskliga misstag.
För det andra har vi fortfarande problemet med plancaching och parametersniffning i viss utsträckning. Detta beror på att i den första exekveringen kommer optimeraren att generera en plan för alla 4 frågorna baserat på parametervärdena i den exekveringen. Låt oss säga att den första exekveringen kommer att använda standardvärdena för parametrarna. Specifikt kommer värdet på @CustomerID att vara NULL. Alla frågor kommer att optimeras baserat på det värdet, inklusive frågan med WHERE-satsen (SalesOrders.CustomerID =@CustomerID). Optimeraren kommer att uppskatta 0 rader för dessa frågor. Låt oss nu säga att den andra körningen kommer att använda ett icke-nullvärde för @CustomerID. Den cachade planen, som uppskattar 0 rader, kommer att användas, även om kunden kan ha många beställningar i tabellen.
Dela upp proceduren i separata lagrade procedurer
Istället för fyra grenar inom samma lagrade procedur kan vi skapa fyra separata lagrade procedurer, var och en med relevanta parametrar och motsvarande fråga. Sedan kan vi antingen skriva om applikationen för att bestämma vilken lagrad procedur som ska köras enligt önskat beteende. Eller, om vi vill att det ska vara transparent för applikationen, kan vi skriva om den ursprungliga lagrade proceduren för att bestämma vilken procedur som ska köras baserat på parametervärdena. Vi kommer att använda samma IF-ELSE-satser, men istället för att köra en fråga i varje gren kommer vi att köra en separat lagrad procedur.
Fördelen är att vi löser planens cachningsproblem eftersom varje lagrad procedur nu har sin egen plan, och planen för varje lagrad procedur kommer att genereras i sin första exekvering baserat på parametersniffning.
Men vi har fortfarande underhållsproblemet. Vissa människor kanske säger att nu är det ännu värre, eftersom vi måste upprätthålla flera lagrade procedurer. Återigen, om vi ökar antalet parametrar till 3, skulle vi sluta med 8 distinkta lagrade procedurer.
Använd ALTERNATIV (OMKOMPILERA)
OPTION (OMKOMPILERA) fungerar som magi. Du behöver bara säga orden (eller lägga till dem i frågan), så händer magi. Verkligen, det löser så många problem eftersom det kompilerar frågan vid körning, och det gör det för varje körning.
Men du måste vara försiktig eftersom du vet vad de säger:"Med stor makt kommer stort ansvar." Om du använder OPTION (RECOMPILE) i en fråga som körs väldigt ofta på ett upptaget OLTP-system, kan du döda systemet eftersom servern behöver kompilera och generera en ny plan i varje exekvering, med mycket CPU-resurser. Det här är verkligen farligt. Men om frågan bara körs då och då, låt oss säga en gång varannan minut, då är det förmodligen säkert. Men testa alltid påverkan i din specifika miljö.
I vårt fall, förutsatt att vi säkert kan använda OPTION (RECOMPILE), är allt vi behöver göra att lägga till de magiska orden i slutet av vår fråga, som visas nedan:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Låt oss nu se magin i aktion. Till exempel är följande plan för det andra beteendet:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
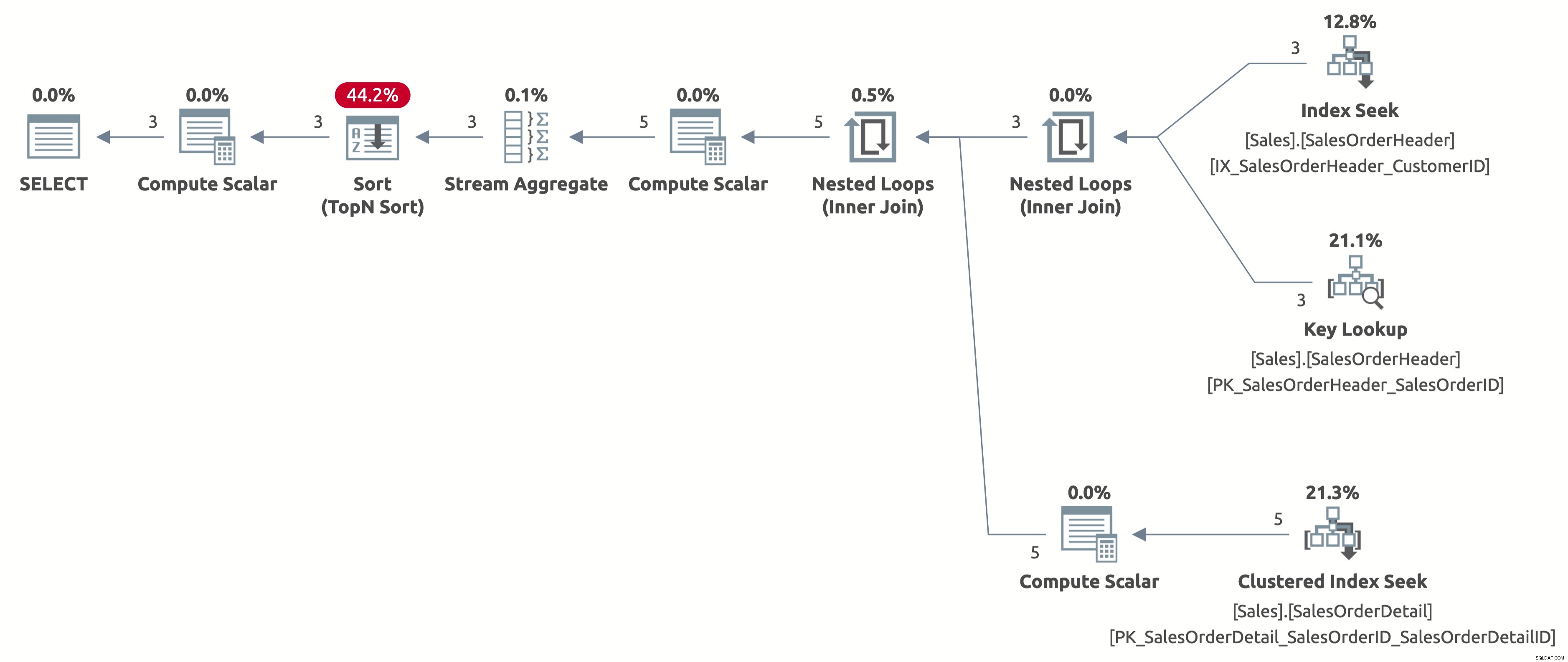
Nu får vi en effektiv indexsökning med en korrekt uppskattning av 2,6 rader. Vi behöver fortfarande sortera efter OrderDate, men nu är sorteringen direkt efter Order Date, och vi behöver inte längre beräkna CASE-uttrycket i ORDER BY-satsen. Detta är den bästa möjliga planen för detta frågebeteende baserat på tillgängliga index.
Här är utdata från statistik IO:
- Tabell 'SalesOrderDetail'. Scan count 3, logiskt läser 9
- Tabell 'SalesOrderHeader'. Scan count 1, logiskt läser 11
Anledningen till att OPTION (RECOMPILE) är så effektiv i det här fallet är att det löser exakt de två problem vi har här. Kom ihåg att det första problemet är plancache. OPTION (RECOMPILE) eliminerar detta problem helt eftersom det kompilerar om frågan varje gång. Det andra problemet är optimerarens oförmåga att utvärdera det komplexa uttrycket i WHERE-satsen och i ORDER BY-satsen vid kompilering. Eftersom OPTION (RECOMPILE) händer vid körning, löser det problemet. För vid körning har optimeraren mycket mer information jämfört med kompileringstid, och det gör hela skillnaden.
Nu ska vi se vad som händer när vi provar det tredje beteendet:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
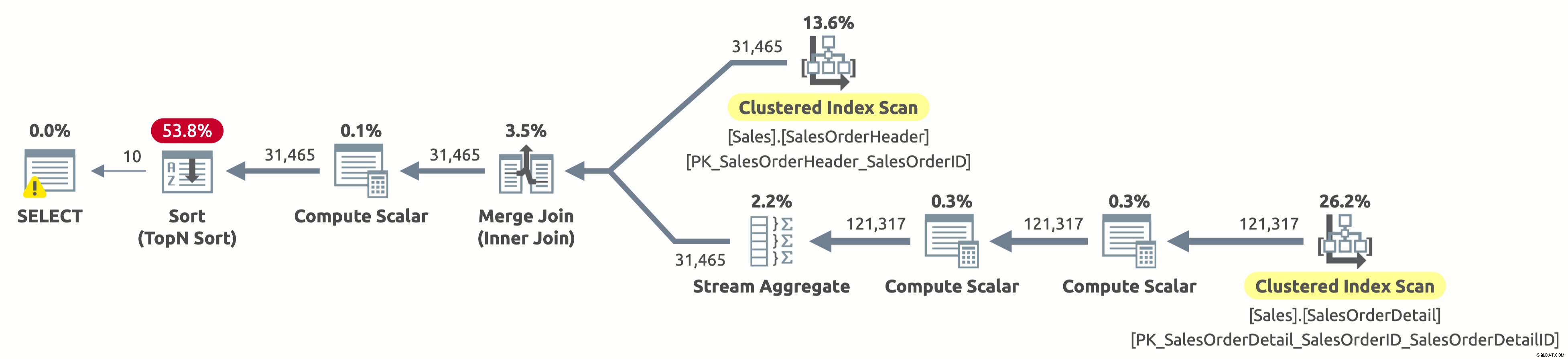
Houston Vi har ett problem. Planen skannar fortfarande båda tabellerna helt och hållet och sorterar sedan allt, istället för att bara skanna de första 10 raderna från Sales.SalesOrderHeader och undvika sorteringen helt. Vad hände?
Detta är ett intressant "case" och det har att göra med CASE-uttrycket i ORDER BY-satsen. CASE-uttrycket utvärderar en lista med villkor och returnerar ett av resultatuttrycken. Men resultatuttrycken kan ha olika datatyper. Så vad skulle datatypen vara för hela CASE-uttrycket? Tja, CASE-uttrycket returnerar alltid datatypen med högsta prioritet. I vårt fall har kolumnen OrderDate datatypen DATETIME, medan kolumnen SalesOrderID har datatypen INT. Datatypen DATETIME har högre prioritet, så CASE-uttrycket returnerar alltid DATETIME.
Detta betyder att om vi vill sortera efter SalesOrderID måste CASE-uttrycket först implicit konvertera värdet för SalesOrderID till DATETIME för varje rad innan det sorteras. Se Compute Scalar-operatorn till höger om sorteringsoperatorn i planen ovan? Det är precis vad det gör.
Detta är ett problem i sig och det visar hur farligt det kan vara att blanda olika datatyper i ett enda CASE-uttryck.
Vi kan komma runt det här problemet genom att skriva om ORDER BY-satsen på andra sätt, men det skulle göra koden ännu fulare och svårare att läsa och underhålla. Så jag går inte i den riktningen.
Låt oss istället prova nästa metod...
Generera frågan dynamiskt
Eftersom vårt mål är att generera 4 olika frågestrukturer inom en enda fråga, kan dynamisk SQL vara väldigt praktisk i det här fallet. Tanken är att bygga frågan dynamiskt baserat på parametervärdena. På så sätt kan vi bygga de fyra olika frågestrukturerna i en enda kod, utan att behöva underhålla fyra kopior av frågan. Varje frågestruktur kompileras en gång, när den körs första gången, och den kommer att få den bästa planen eftersom den inte innehåller några komplexa uttryck.
Denna lösning är väldigt lik lösningen med flera lagrade procedurer, men istället för att behålla 8 lagrade procedurer för 3 parametrar, underhåller vi bara en enda kod som bygger frågan dynamiskt.
Jag vet, dynamisk SQL är också ful och kan ibland vara ganska svår att underhålla, men jag tror att det fortfarande är lättare än att underhålla flera lagrade procedurer, och det skalas inte exponentiellt när antalet parametrar ökar.
Följande är koden:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Observera att jag fortfarande använder en intern parameter för kund-ID, och jag kör den dynamiska koden med sys.sp_executesql för att skicka parametervärdet. Detta är viktigt av två skäl. Först, för att undvika flera kompilationer av samma frågestruktur för olika värden av @Kund-ID. För det andra, för att undvika SQL-injektion.
Om du försöker köra den lagrade proceduren nu med olika parametervärden kommer du att se att varje frågebeteende eller frågestruktur får den bästa exekveringsplanen, och var och en av de fyra planerna kompileras endast en gång.
Som ett exempel är följande plan för det tredje beteendet:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
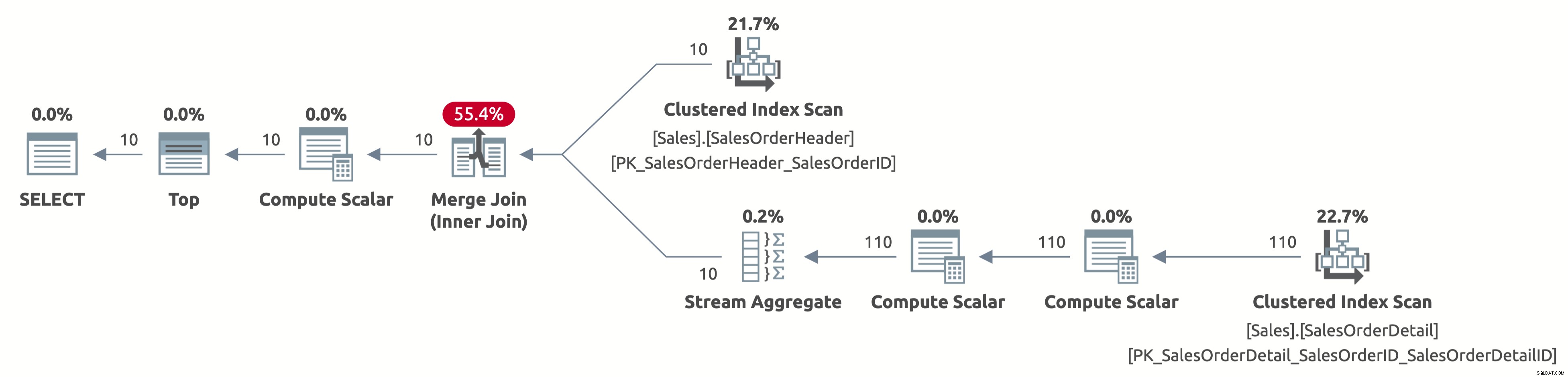
Nu skannar vi bara de första 10 raderna från Sales.SalesOrderHeader-tabellen, och vi skannar också bara de första 110 raderna från Sales.SalesOrderDetail-tabellen. Dessutom finns det ingen sorteringsoperator eftersom data redan är sorterade efter försäljningsorder-ID.
Här är utdata från statistik IO:
- Tabell 'SalesOrderDetail'. Scan count 1, logiskt läser 4
- Tabell 'SalesOrderHeader'. Scan count 1, logiskt läser 3
Slutsats
När du använder parametrar för att ändra strukturen på din fråga, använd inte komplexa uttryck i frågan för att härleda det förväntade beteendet. I de flesta fall kommer detta att leda till dålig prestanda, och av goda skäl. Det första skälet är att planen kommer att genereras baserat på den första körningen, och sedan kommer alla efterföljande körningar att återanvända samma plan, vilket bara är lämpligt för en frågestruktur. Det andra skälet är att optimeraren är begränsad i sin förmåga att utvärdera dessa komplexa uttryck vid kompilering.
Det finns flera sätt att övervinna dessa problem, och vi undersökte dem i den här artikeln. I de flesta fall skulle den bästa metoden vara att bygga frågan dynamiskt baserat på parametervärdena. På så sätt kommer varje frågestruktur att kompileras en gång med bästa möjliga plan.
När du bygger frågan med dynamisk SQL, se till att använda parametrar där det är lämpligt och verifiera att din kod är säker.