Förra året presenterade jag en lösning för att simulera Availability Group-läsbara sekundärer utan att investera i Enterprise Edition. Inte för att hindra människor från att köpa Enterprise Edition, eftersom det finns många fördelar utanför AG:er, men mer för dem som inte har någon chans att någonsin ha Enterprise Edition:
- Läsbara sekundärer på en budget
Jag försöker vara en obeveklig förespråkare för Standard Edition-kunden; det är nästan ett löpande skämt som säkerligen – med tanke på antalet funktioner som den får i varje ny utgåva – att utgåvan som helhet är på väg att utfasas. I privata möten med Microsoft har jag drivit på för att funktioner också ska inkluderas i Standard Edition, särskilt med funktioner som är mycket mer fördelaktiga för små företag än de med obegränsad hårdvarubudget.
Enterprise Edition-kunder åtnjuter fördelarna med hantering och prestanda som erbjuds av tabellpartitionering, men den här funktionen är inte tillgänglig i Standard Edition. En idé slog mig nyligen att det finns ett sätt att uppnå åtminstone några av partitioneringens fördelar på vilken utgåva som helst, och det involverar inte partitionerade vyer. Detta är inte att säga att partitionerade vyer inte är ett genomförbart alternativ värt att överväga; dessa beskrivs väl av andra, inklusive Daniel Hutmacher (Partitionerade vyer över tabellpartitionering) och Kimberly Tripp (Partitioned Tables v. Partitioned Views–Varför finns de ens kvar?). Min idé är bara lite enklare att genomföra.
Din nya hjälte:filtrerade index
Nu, jag vet, den här funktionen är ett ord på fyra bokstäver för vissa; innan du går vidare bör du vara nöjd med filtrerade index, eller åtminstone vara medveten om deras begränsningar. Lite läsning för att ge dig en rättvis balans innan jag försöker sälja på dem:
- Jag pratar om flera brister i Hur filtrerade index kan vara en kraftfullare funktion och pekar ut massor av Connect-objekt som du kan rösta på;
- Paul White (@SQL_Kiwi) talar om inställningsproblem i Optimizer-begränsningar med filtrerade index och även i en oväntad bieffekt av att lägga till ett filtrerat index; och,
- Jes Borland (@grrl_geek) berättar för oss vad du kan (och inte kan) göra med filtrerade index.
Läs alla dessa? Och du är fortfarande här? Bra.
TL;DR för detta är att du kan använda filtrerade index för att hålla alla dina "heta data" i en separat fysisk struktur, och även på separat underliggande hårdvara (du kan ha en snabb SSD- eller PCIe-enhet tillgänglig, men det kan t håller hela bordet).
Ett snabbt exempel
Det finns många användningsfall där en del av informationen efterfrågas mycket oftare än resten – tänk på en butik som hanterar beställningar, ett bageri som planerar leveranser av bröllopstårta eller en fotbollsstadion som mäter närvaro- och koncessionsdata. I dessa fall handlar det mesta eller hela den dagliga frågeaktiviteten om "aktuella" data.
Låt oss hålla det enkelt; vi skapar en databas med en mycket smal ordertabell:
SKAPA DATABAS PoorManPartition;GO ANVÄND PoorManPartition;GO CREATE TABLE dbo.Orders( OrderID INT IDENTITY(1,1) PRIMÄRNYCKEL, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, . .andra kolumner...);
Låt oss nu säga att du har tillräckligt med utrymme på din snabba lagring för att behålla en månads data (med gott om utrymme för att ta hänsyn till säsongsvariationer och framtida tillväxt). Vi kan lägga till en ny filgrupp och placera en datafil på den snabba enheten.
ÄNDRA DATABAS PoorManPartition LÄGG TILL FILGROUP HotData;GO ÄNDRA DATABAS PoorManPartition LÄGG TILL FIL ( Namn =N'HotData', Filnamn =N'Z:\folder\HotData.mdf', Storlek =100MB, FileGrowth =25MB) TILL FILEGROUP;
Låt oss nu skapa ett filtrerat index på vår HotData-filgrupp, där filtret inkluderar allt från början av november 2015, och de vanliga kolumnerna som är involverade i tidsbaserade frågor finns i nyckel- eller inkluderingslistan:
SKAPA INDEX FilteredIndex PÅ dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151101' AND OrderDate <'20151201' ON HotData;
Vi kan infoga några rader och kontrollera exekveringsplanen för att vara säkra på att täckta frågor faktiskt kan använda indexet:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Resultat:index_id rader -------- ---- 1 3 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106';
Den resulterande exekveringsplanen använder visserligen det filtrerade indexet (även om filterpredikatet i frågan inte matchar indexdefinitionen exakt):
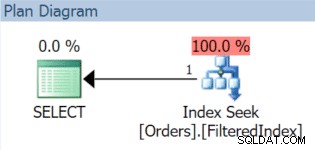
Nu rullar den 1 december runt och det är dags att byta ut vår novemberdata och ersätta den med december. Vi kan bara återskapa det filtrerade indexet med ett nytt filterpredikat och använda DROP_EXISTING alternativ:
SKAPA INDEX FilteredIndex PÅ dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151201' OCH OrderDate <'20160101' MED (DROP_EXISTING =ON) ON HotData;
Nu kan vi lägga till några fler rader, kontrollera partitionsstatistiken och köra vår tidigare fråga och en ny för att kontrollera vilka index som används:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Resultat:index_id rows -------- ---- 1 5 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106'; VÄLJ OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151202' AND OrderDate <'20151204';
I det här fallet får vi en klustrad indexskanning med novemberfrågan:
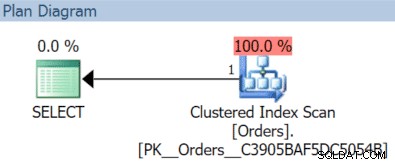
(Men det skulle vara annorlunda om vi hade ett separat, ofiltrerat index med OrderDate som nyckel.)
Och jag kommer inte att visa det igen, men med decemberfrågan får vi samma filtrerade indexsökning som tidigare.
Du kan också ha flera index, ett för den aktuella månaden, ett för föregående månad, och så vidare, och du kan bara hantera dem separat (den 1 december släpper du bara indexet från oktober och låter novembers vara ifred, till exempel) . Du kan också upprätthålla flera index för kortare eller längre tidsperioder (nuvarande och föregående vecka, nuvarande och föregående kvartal), etc. Lösningen är ganska flexibel.
På grund av begränsningarna för filtrerade index kommer jag inte att försöka driva detta som en perfekt lösning, och inte heller en komplett ersättning för tabellpartitionering eller partitionerade vyer. Att byta ut en partition är till exempel en metadataoperation, samtidigt som man återskapar ett index med DROP_EXISTING kan ha mycket loggning (och eftersom du inte är på Enterprise Edition kan den inte köras online). Du kanske också upptäcker att partitionerade vyer är snabbare för dig – det finns mer arbete kring att underhålla separata fysiska tabeller och de begränsningar som gör den partitionerade vyn möjlig, men utdelningen när det gäller frågeprestanda kan vara bättre i vissa fall.
Automatisering
Återskapandet av indexet kan automatiseras ganska enkelt, med hjälp av ett enkelt jobb som gör något så här en gång i månaden (eller vad din "heta" fönsterstorlek är):
DECLARE @sql NVARCHAR(MAX), @dt DATE =DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql =N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>=''' + CONVERT(CHAR(8), @dt, 112) + N''' MED (DROP_EXISTING =ON ) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Du kan också skapa flera index månader i förväg, ungefär som att skapa framtida partitioner i förväg – trots allt kommer de framtida indexen inte att uppta något utrymme förrän det finns data som är relevanta för deras predikat. Och du kan bara släppa indexen som segmenterade äldre data som du nu vill ska bli kalla.
Bakblick
Efter att jag avslutat den här artikeln kom jag förstås över ett annat av Kimberly Tripps inlägg, som du bör läsa innan du fortsätter med något jag förespråkar här (och som jag hade läst innan jag började):
- Vad sägs om filtrerade index istället för partitionering?
Av flera anledningar är Kimberly mycket mer för partitionerade vyer för att implementera något som liknar partitionering i Standard Edition; Men för vissa scenarier fascinerar användningen av filtrerade index mig fortfarande tillräckligt för att fortsätta med mina experiment. Ett av de områden där filtrerade index kan vara fördelaktiga är när din "heta" data har flera kriterier – inte bara uppdelad efter datum, utan också efter andra attribut (kanske vill du ha snabba frågor mot alla beställningar från denna månad som är för en specifik nivå av kund eller över ett visst dollarbelopp).
Nästa...
I ett framtida inlägg kommer jag att spela med det här konceptet på ett avancerade system, med lite verklig volym och arbetsbelastning. Jag vill upptäcka prestandaskillnader mellan den här lösningen, ett icke-filtrerat täckande index, en partitionerad vy och en partitionerad tabell. Inuti en virtuell dator på en bärbar dator med endast tillgängliga SSD-enheter skulle förmodligen inte ge realistiska eller rättvisa tester i stor skala.