Redan i januari 2015 skrev min gode vän och kollega SQL Server MVP Rob Farley om en ny lösning på problemet med att hitta medianen i SQL Server-versioner före 2012. Förutom att det är en intressant läsning i sig, visar det sig vara ett bra exempel att använda för att demonstrera en del avancerad analys av exekveringsplaner och för att lyfta fram några subtila beteenden hos frågeoptimeraren och exekveringsmotorn.
Enkel median
Även om Robs artikel specifikt riktar sig till en grupperad medianberäkning, tänker jag börja med att tillämpa hans metod på ett stort enstaka medianberäkningsproblem, eftersom den belyser de viktiga frågorna tydligast. Provdatan kommer återigen från Aaron Bertrands originalartikel:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Att tillämpa Rob Farleys teknik på detta problem ger följande kod:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Som vanligt har jag kommenterat att räkna antalet rader i tabellen och ersatt det med en konstant för att undvika en källa till prestandavariationer. Utförandeplanen för den viktiga frågan är som följer:

Den här frågan körs i 5800ms på min testmaskin.
Sortspillet
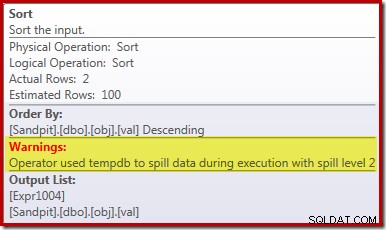
Den primära orsaken till denna dåliga prestanda bör vara tydlig från att titta på exekveringsplanen ovan:Varningen på Sorteringsoperatören visar att ett otillräckligt arbetsutrymmesminne orsakade ett nivå 2 (multipass) spill till fysisk tempdb disk:
I versioner av SQL Server före 2012 skulle du behöva övervaka separat för sorteringsspillhändelser för att se detta. Hur som helst, den otillräckliga sorteringsminnesreservationen orsakas av ett kardinalitetsuppskattningsfel, som den förutförande (uppskattade) planen visar:

Kardinalitetsuppskattningen på 100 rader vid sorteringsingången är en (jävligt inexakt) gissning av optimeraren, på grund av det lokala variabeluttrycket i föregående toppoperator:

Observera att detta uppskattningsfel för kardinalitet inte är ett radmålsproblem. Att använda spårningsflagga 4138 tar bort radmålseffekten under den första toppen, men uppskattningen efter topp kommer fortfarande att vara en gissning på 100 rader (så minnesreservationen för sorteringen kommer fortfarande att vara alldeles för liten):

Antyder värdet för den lokala variabeln
Det finns flera sätt vi kan lösa detta problem med uppskattning av kardinalitet. Ett alternativ är att använda en ledtråd för att ge optimeraren information om värdet i variabeln:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Genom att använda tipset förbättras prestandan till 3250ms från 5800ms. Planen efter utförande visar att sorten inte längre spills:

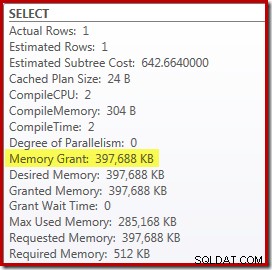
Det finns dock ett par nackdelar med detta. För det första kräver den här nya exekveringsplanen 388 MB minnesbeviljande – minne som annars skulle kunna användas av servern för att cachelagra planer, index och data:
För det andra kan det vara svårt att välja ett bra nummer för tipset som kommer att fungera bra för alla framtida avrättningar, utan att reservera minne i onödan.
Lägg också märke till att vi var tvungna att antyda ett värde för variabeln som är 10 % högre än det faktiska värdet för variabeln för att eliminera utsläppet helt. Detta är inte ovanligt, eftersom den allmänna sorteringsalgoritmen är snarare mer komplex än en enkel sortering på plats. Att reservera minne lika med storleken på uppsättningen som ska sorteras kommer inte alltid (eller ens i allmänhet) att vara tillräckligt för att undvika spill under körning.
Bädda in och återkompilera
Ett annat alternativ är att dra fördel av Parameter Embedding Optimization aktiverad genom att lägga till en omkompileringstips på frågenivå på SQL Server 2008 SP1 CU5 eller senare. Den här åtgärden gör det möjligt för optimeraren att se körtidsvärdet för variabeln och optimera därefter:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Detta förbättrar körtiden till 3150ms – 100 ms bättre än att använda OPTIMIZE FOR antydan. Anledningen till denna ytterligare lilla förbättring kan urskiljas från den nya planen efter genomförandet:

Uttrycket (2 – @Count % 2) – som tidigare sett i den andra Top-operatören – kan nu vikas ned till ett enda känt värde. En omskrivning efter optimering kan sedan kombinera Toppen med Sorteringen, vilket resulterar i en enda Top N Sortering. Denna omskrivning var inte möjlig tidigare eftersom att kollapsa Top + Sorter till en Top N Sortera bara fungerar med ett konstant bokstavligt Top-värde (inte variabler eller parametrar).
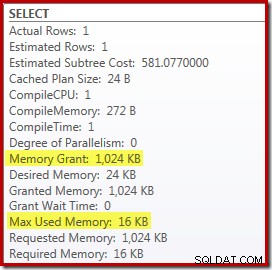
Att ersätta Top och Sort med en Top N Sort har en liten gynnsam effekt på prestandan (100ms här), men det eliminerar också nästan helt minneskravet, eftersom en Top N Sort bara behöver hålla reda på N högsta (eller lägsta) rader, snarare än hela uppsättningen. Som ett resultat av denna ändring i algoritm visar efterexekveringsplanen för den här frågan att minsta 1 MB minne reserverades för Top N Sortering i denna plan, och endast 16KB användes under körning (kom ihåg att full-sort-planen krävde 388 MB):
Undvika omkompilering
Den (uppenbara) nackdelen med att använda tipset om kompileringsfrågan är att det kräver en fullständig kompilering vid varje körning. I det här fallet är overheaden ganska liten – cirka 1ms CPU-tid och 272KB minne. Trots det finns det ett sätt att justera frågan så att vi får fördelarna med en Top N Sortering utan att använda några tips och utan att kompilera om.
Idén kommer från att inse att ett maximum två rader kommer att krävas för den slutliga medianberäkningen. Det kan vara en rad, eller det kan vara två vid körning, men det kan aldrig bli fler. Denna insikt innebär att vi kan lägga till ett logiskt redundant Top (2) mellansteg till frågan enligt följande:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Den nya Top (med den så viktiga konstanta bokstaven) innebär att den slutliga utförandeplanen innehåller den önskade Top N Sort-operatorn utan att kompilera om:

Prestandan för den här exekveringsplanen är oförändrad från den omkompilerade versionen vid 3150ms och minneskravet är detsamma. Observera dock att avsaknaden av parameterinbäddning innebär att kardinalitetsuppskattningarna under sorteringen är gissningar på 100 rader (även om det inte påverkar prestandan här).
Det viktigaste i detta skede är att om du vill ha en Top N Sort med lågt minne måste du använda en konstant literal, eller aktivera optimeraren för att se en literal via parameterinbäddningsoptimering.
The Compute Scalar
Eliminerar 388 MB minnesbidrag (samtidigt som det gör en prestandaförbättring på 100 ms) är verkligen värt besväret, men det finns en mycket större prestandavinst tillgänglig. Det osannolika målet för denna slutliga förbättring är Compute Scalar precis ovanför Clustered Index Scan.
Denna Compute Scalar relaterar till uttrycket (0E + f.val) som finns i AVG samlas i frågan. Om det ser konstigt ut för dig är detta ett ganska vanligt frågeskrivande trick (som att multiplicera med 1,0) för att undvika heltalsaritmetik i medelberäkningen, men det har några mycket viktiga bieffekter.
Det finns ett speciellt händelseförlopp här som vi måste följa steg för steg.
Lägg först märke till att 0E är en konstant bokstavlig nolla, med en float data typ. För att lägga till detta till heltalskolumnen val, måste frågeprocessorn konvertera kolumnen från heltal till flytande (i enlighet med datatypsföreträdesreglerna). En liknande typ av konvertering skulle vara nödvändig om vi hade valt att multiplicera kolumnen med 1,0 (en bokstavlig med en implicit numerisk datatyp). Det viktiga är att detta rutintrick inför ett uttryck .
Nu försöker SQL Server i allmänhet trycka ner uttryck planträdet så långt det är möjligt vid sammanställning och optimering. Detta görs av flera skäl, bland annat för att göra det enklare att matcha uttryck med beräknade kolumner, och för att underlätta förenklingar med hjälp av begränsningsinformation. Denna push-down policy förklarar varför Compute Scalar verkar mycket närmare planens bladnivå än vad uttryckets ursprungliga textposition i frågan skulle antyda.
En risk med att utföra denna push-down är att uttrycket kan komma att beräknas fler gånger än nödvändigt. De flesta planer har ett minskande antal rader när vi flyttar upp i planträdet, på grund av effekten av sammanfogningar, aggregering och filter. Att trycka ner uttryck i trädet riskerar därför att utvärdera dessa uttryck fler gånger (d.v.s. på fler rader) än nödvändigt.
För att mildra detta introducerade SQL Server 2005 en optimering där Compute Scalars helt enkelt kan definiera ett uttryck, med arbetet med att faktiskt utvärdera uttrycket uppskjuten tills en senare operatör i planen kräver resultatet. När denna optimering fungerar som avsett, är effekten att få alla fördelar med att trycka ner uttryck i trädet, samtidigt som man faktiskt bara utvärderar uttrycket så många gånger som faktiskt behövs.
Vad alla dessa Compute Scalar-grejer betyder
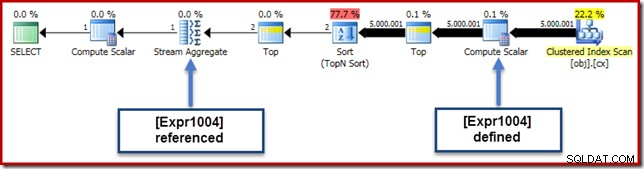
I vårt exempel är 0E + val uttrycket var ursprungligen associerat med AVG aggregat, så vi kan förvänta oss att se det vid (eller något efter) Stream Aggregate. Det här uttrycket trycktes ned trädet för att bli en ny Compute Scalar precis efter skanningen, med uttrycket märkt som [Expr1004].
När vi tittar på exekveringsplanen kan vi se att [Expr1004] refereras av Stream Aggregate (Flikextrakt för Plan Explorer Expressions visas nedan):

Allt annat lika, utvärdering av uttryck [Expr1004] skulle skjutas upp tills aggregatet behöver dessa värden för summadelen av medelberäkningen. Eftersom aggregatet bara någonsin kan stöta på en eller två rader, bör detta resultera i att [Expr1004] endast utvärderas en eller två gånger:
Tyvärr är det inte riktigt så det fungerar här. Problemet är den blockerande sorteringsoperatorn:
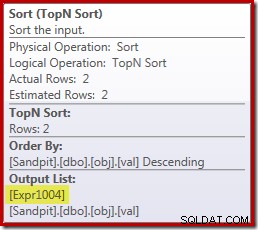
Detta tvingar fram utvärdering av [Expr1004], så istället för att det bara utvärderas en eller två gånger vid Stream Aggregate, betyder sorteringen att vi i slutändan konverterar val kolumn till en flytande och lägga till noll till den 5 000 001 gånger!
En lösning
Helst skulle SQL Server vara lite smartare på allt detta, men det är inte så det fungerar idag. Det finns ingen frågetips för att förhindra att uttryck trycks ner i planträdet, och vi kan inte heller tvinga fram Compute Scalars med en planguide. Det finns oundvikligen en odokumenterad spårflagga, men det är inte en jag ansvarsfullt kan prata om i det aktuella sammanhanget.
Så, på gott och ont, lämnar detta oss med att försöka hitta en frågeomskrivning som råkar förhindra att SQL Server separerar uttrycket från aggregatet och trycker ner det förbi sorteringen, utan att ändra resultatet av frågan. Det här är inte så lätt som du kanske tror, men modifieringen (visserligen lite udda) nedan uppnår detta med ett CASE uttryck på en icke-deterministisk inneboende funktion:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Utförandeplanen för denna slutliga form av frågan visas nedan:

Lägg märke till att en Compute Scalar inte längre visas mellan Clustered Index Scan och Top. 0E + val uttrycket beräknas nu vid Stream Aggregate på maximalt två rader (snarare än fem miljoner!) och prestandan ökar med ytterligare 32 % från 3150 ms till 2150 ms som ett resultat.
Detta går fortfarande inte så bra att jämföra med prestandan på undersekund för OFFSET och dynamiska markörmedianberäkningslösningar, men det representerar fortfarande en mycket betydande förbättring jämfört med de ursprungliga 5800ms för denna metod på en stor enmedianproblemuppsättning.
CASE-tricket kommer naturligtvis inte att fungera i framtiden. Takeaway handlar inte så mycket om att använda konstiga kasusuttrycksknep, som det handlar om de potentiella prestandaimplikationerna av Compute Scalars. När du väl känner till den här typen av saker kanske du tänker två gånger innan du multiplicerar med 1,0 eller lägger till float noll i en genomsnittsberäkning.
Uppdatering: Se den första kommentaren för en bra lösning av Robert Heinig som inte kräver några odokumenterade knep. Något att tänka på när du nästa gång blir frestad att multiplicera ett heltal med decimal (eller flytande) ett i ett genomsnittligt aggregat.
Grupperad median
För fullständighetens skull, och för att koppla denna analys närmare tillbaka till Robs ursprungliga artikel, kommer vi att avsluta med att tillämpa samma förbättringar på en grupperad medianberäkning. De mindre uppsättningsstorlekarna (per grupp) betyder att effekterna blir mindre, naturligtvis.
Den grupperade medianprovdatan (igen som ursprungligen skapad av Aaron Bertrand) omfattar tiotusen rader för var och en av hundra imaginära säljare:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Att tillämpa Rob Farleys lösning direkt ger följande kod, som körs på 560ms på min maskin.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
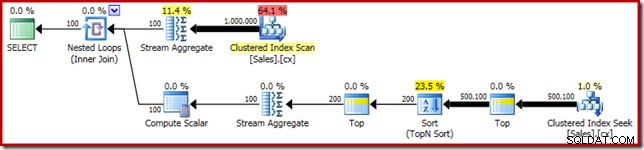
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Utförandeplanen har uppenbara likheter med den enda medianen:
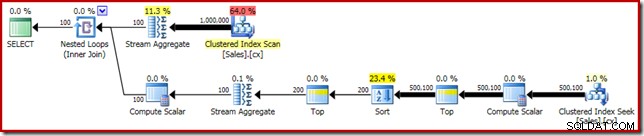
Vår första förbättring är att ersätta Sort med en Top N Sortera, genom att lägga till en explicit Top (2). Detta förbättrar exekveringstiden något från 560 ms till 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Utförandeplanen visar Top N Sortering som förväntat:
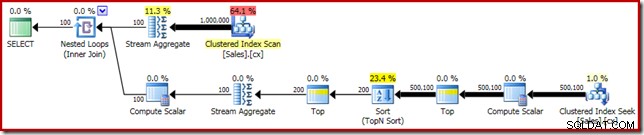
Slutligen distribuerar vi det udda CASE-uttrycket för att ta bort det pushade Compute Scalar-uttrycket. Detta förbättrar prestandan ytterligare till 450 ms (en 20 % förbättring jämfört med originalet):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Den färdiga utförandeplanen är som följer: