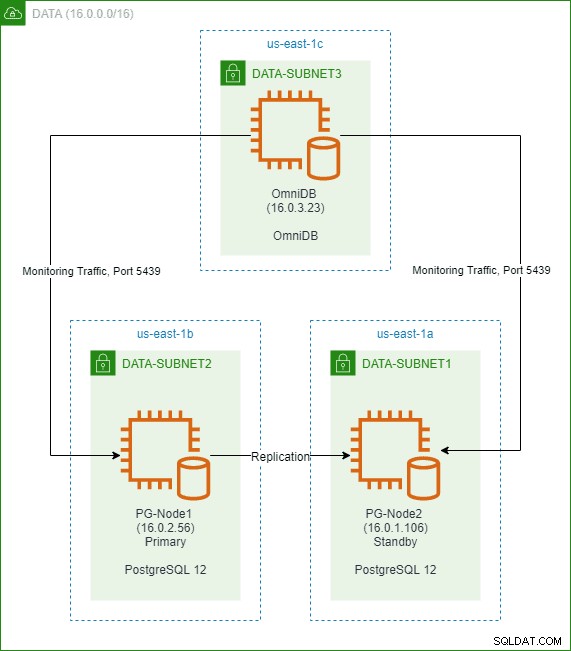
I en tidigare artikel i den här serien skapade vi ett PostgreSQL 12-kluster med två noder i AWS-molnet. Vi installerade och konfigurerade också 2ndQuadrant OmniDB i en tredje nod. Bilden nedan visar arkitekturen:
Vi kunde ansluta till både den primära och standbynoden från OmniDB:s webbaserade användargränssnitt. Vi återställde sedan en exempeldatabas som heter "dvdrental" i den primära noden som började replikera till standby.
I den här delen av serien kommer vi att lära oss hur man skapar och använder en övervakningspanel i OmniDB. DBA:er och driftteam föredrar ofta grafiska verktyg snarare än komplexa frågor för att visuellt inspektera databasens hälsa. OmniDB kommer med ett antal viktiga widgets som enkelt kan användas i en övervakningspanel. Som vi kommer att se senare tillåter det också användare att skriva sina egna övervakningswidgets.
Bygga en prestandaövervakningsinstrumentpanel
Låt oss börja med standardinstrumentpanelen OmniDB kommer med.
I bilden nedan är vi anslutna till den primära noden (PG-Node1). Vi högerklickar på instansnamnet och väljer sedan "Monitor" från popup-menyn och väljer sedan "Dashboard".
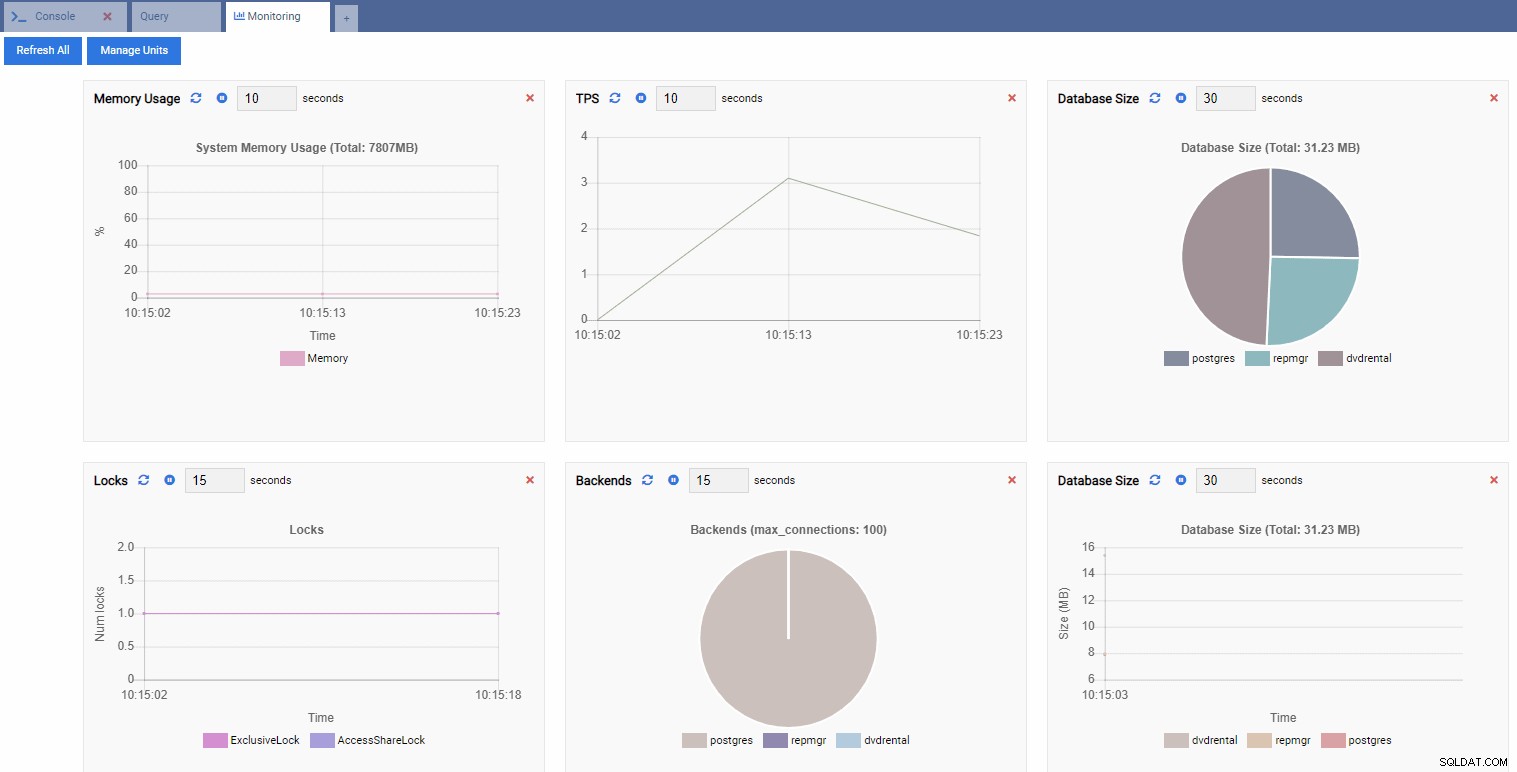
Detta öppnar en instrumentpanel med några widgetar i.
I OmniDB-termer kallas de rektangulära widgetarna i instrumentpanelen Monitoring Units . Var och en av dessa enheter visar ett specifikt mått från PostgreSQL-instansen den är ansluten till och uppdaterar dynamiskt dess data.
Förstå övervakningsenheter
OmniDB kommer med fyra typer av övervakningsenheter:
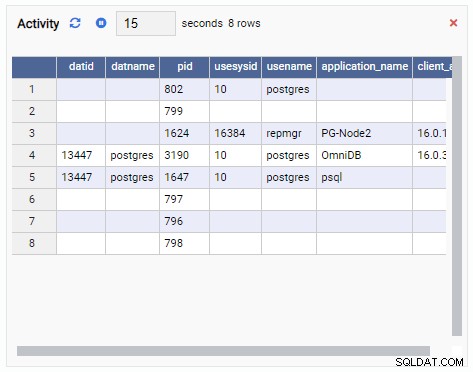
- Ett rutnät är en tabellstruktur som visar resultatet av en fråga. Detta kan till exempel vara utdata från SELECT * FROM pg_stat_replication. Ett rutnät ser ut så här:
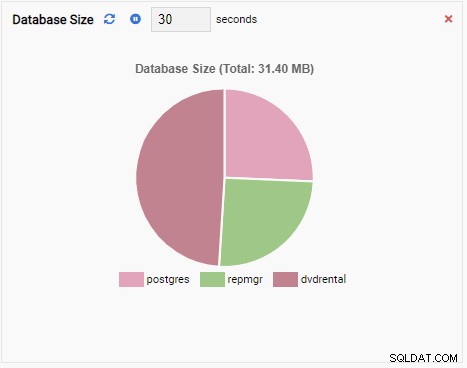
- Ett diagram visar data i grafiskt format, som linjer eller cirkeldiagram. När det uppdateras ritas hela diagrammet om på skärmen med ett nytt värde, och det gamla värdet är borta. Med dessa övervakningsenheter kan vi bara se det aktuella värdet på måtten. Här är ett exempel på ett diagram:
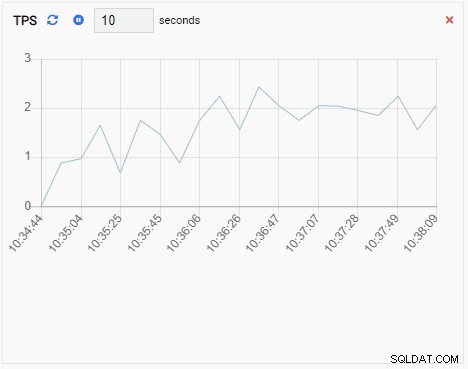
- En Lägg till diagram är också en övervakningsenhet av diagramtyp, förutom när den uppdateras lägger den till det nya värdet till den befintliga serien. Med Chart-Append kan vi enkelt se trender över tid. Här är ett exempel:
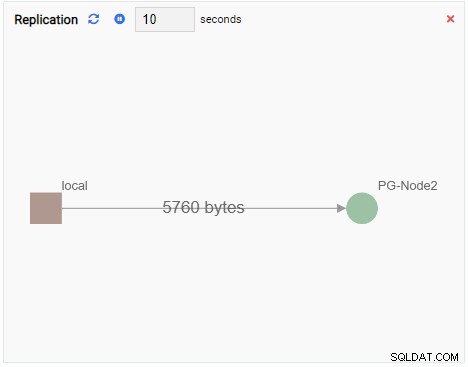
- Ett diagram visar relationer mellan PostgreSQL-klusterinstanser och ett tillhörande mått. Liksom diagramövervakningsenheten uppdaterar en grafövervakningsenhet också sitt gamla värde med ett nytt. Bilden nedan visar den aktuella noden (PG-Node1) replikerar till PG-Node2:
Varje övervakningsenhet har ett antal gemensamma element:
- Övervakningsenhetens namn
- En "uppdatera"-knapp för att manuellt uppdatera enheten
- En "paus"-knapp för att tillfälligt stoppa övervakningsenheten från att uppdateras
- En textruta som visar det aktuella uppdateringsintervallet. Detta kan ändras
- En "stäng"-knapp (rött kryss) för att ta bort övervakningsenheten från instrumentpanelen
- Det faktiska ritområdet för övervakningen
Förbyggda övervakningsenheter
OmniDB kommer med ett antal övervakningsenheter för PostgreSQL som vi kan lägga till i vår instrumentpanel. För att komma åt dessa enheter klickar vi på knappen "Hantera enheter" högst upp på instrumentpanelen:
Detta öppnar listan "Hantera enheter":
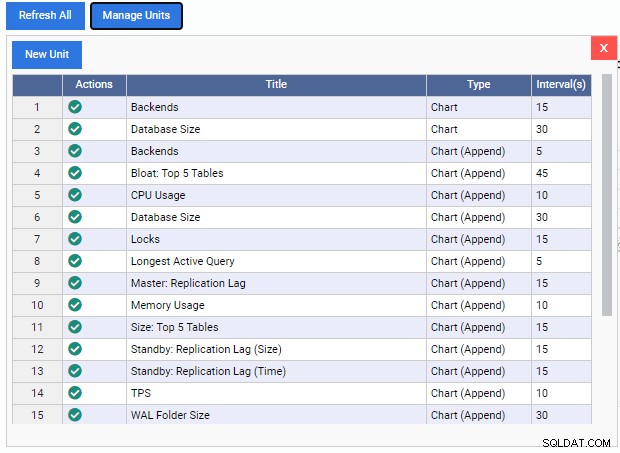
Som vi kan se finns det få förbyggda övervakningsenheter här. Koderna för dessa övervakningsenheter är fritt nedladdningsbara från 2ndQuadrants GitHub-repo. Varje enhet som listas här visar dess namn, typ (Diagram, Chart Append, Graph eller Grid) och standarduppdateringsfrekvensen.
För att lägga till en övervakningsenhet till instrumentpanelen behöver vi bara klicka på den gröna bocken under kolumnen "Åtgärder" för den enheten. Vi kan blanda och matcha olika övervakningsenheter för att bygga den instrumentpanel vi vill ha.
I bilden nedan har vi lagt till följande enheter för vår prestandaövervakningsinstrumentpanel och tagit bort allt annat:
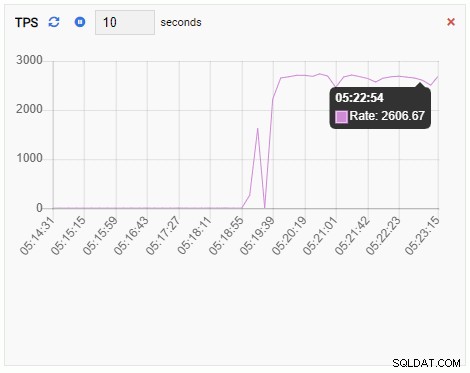
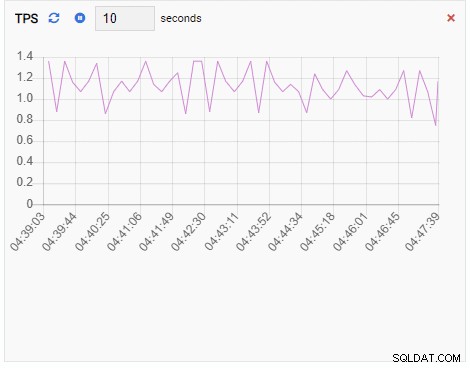
TPS (transaktion per sekund):
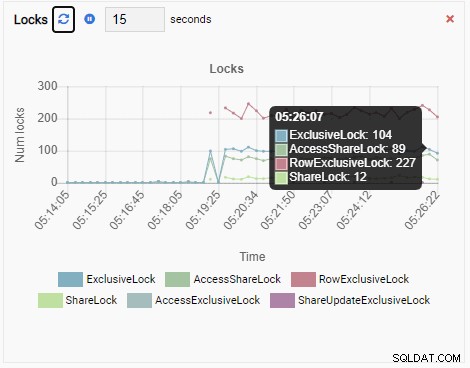
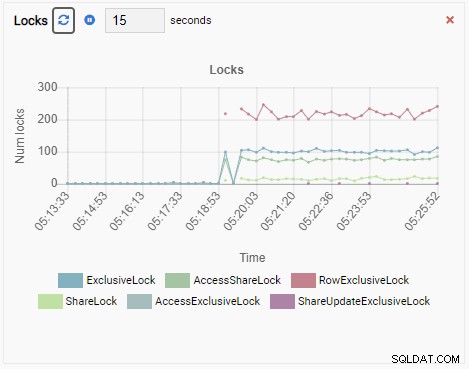
Antal lås:
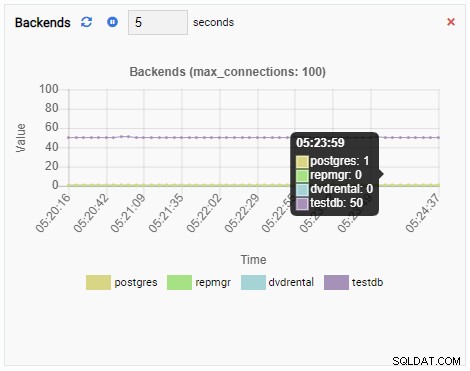
Antal backends:
Eftersom vår instans är inaktiv kan vi se att värdena för TPS, Locks och Backends är minimala.
Testa övervakningspanelen
Vi kommer nu att köra pgbench i vår primära nod (PG-Node1). pgbench är ett enkelt benchmarking-verktyg som levereras med PostgreSQL. Liksom de flesta andra verktyg i sitt slag skapar pgbench ett exempel på OLTP-systems schema och tabeller i en databas när det initieras. Efter det kan den emulera flera klientanslutningar, var och en kör ett antal transaktioner på databasen. I det här fallet kommer vi inte att benchmarka den primära PostgreSQL-noden; vi kommer bara att skapa databasen för pgbench och se om våra instrumentpanelens övervakningsenheter uppfattar förändringen i systemets hälsa.
Först skapar vi en databas för pgbench i den primära noden:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "SKAPA DATABAS testdb";SKAPA DATABAS
Därefter initierar vi "testdb"-databasen för pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbdroppar gamla tabeller...skapar tabeller...genererar data...100000 av 2000000 tupler (5%) klara (förflutna 0,02 s, återstående 0,43 s)200000 av 2000000 tupler (10%) klara (förflutna 0,05 s, återstående 0,41 s av 0000 %)...0000 0002 s)... klar (förflutit 1,84 s, återstående 0,00 s) dammsugning...skapar primärnycklar...klar.
Med databasen initierad startar vi nu själva laddningsprocessen. I kodavsnittet nedan ber vi pgbench att börja med 50 samtidiga klientanslutningar mot testdb-databasen, där varje anslutning kör 100 000 transaktioner på sina tabeller. Belastningstestet kommer att köras över två trådar.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbstartar vakuum...slut.……Om vi nu går tillbaka till vår OmniDB-instrumentpanel ser vi att övervakningsenheterna visar mycket olika resultat.
TPS-måttet visar ganska högt värde. Det finns ett plötsligt hopp från mindre än 2 till fler än 2000:
Antalet backends har ökat. Som väntat har testdb 50 anslutningar mot sig medan andra databaser är inaktiva:
Och slutligen, antalet radexklusiva lås i testdb-databasen är också högt:
Föreställ dig nu detta. Du är en DBA och du använder OmniDB för att hantera en flotta av PostgreSQL-instanser. Du får ett samtal för att undersöka långsam prestanda i ett av fallen.
Genom att använda en instrumentpanel som den vi just såg (även om den är väldigt enkel), kan du enkelt hitta grundorsaken. Du kan kontrollera antalet backends, lås, tillgängligt minne etc. för att se vad som orsakar problemet.
Och det är där OmniDB kan vara ett riktigt användbart verktyg.
Skapa anpassade övervakningsenheter
Ibland kommer vi att behöva skapa våra egna övervakningsenheter. För att skriva en ny övervakningsenhet klickar vi på knappen "Ny enhet" i listan "Hantera enheter". Detta öppnar en ny flik med en tom arbetsyta för att skriva kod:
Överst på skärmen måste vi ange ett namn för vår övervakningsenhet, välja dess typ och ange dess standarduppdateringsintervall. Vi kan även välja en befintlig enhet som mall.
Under rubriken finns två textrutor. "Data Script"-redigeraren är där vi skriver kod för att få data för vår övervakningsenhet. Varje gång en enhet uppdateras körs dataskriptkoden. "Chart Script"-redigeraren är där vi skriver kod för att rita den faktiska enheten. Detta körs när enheten dras första gången.
All dataskriptkod är skriven i Python. För övervakningsenheten för diagramtyp behöver OmniDB att diagramskriptet är skrivet i Chart.js.
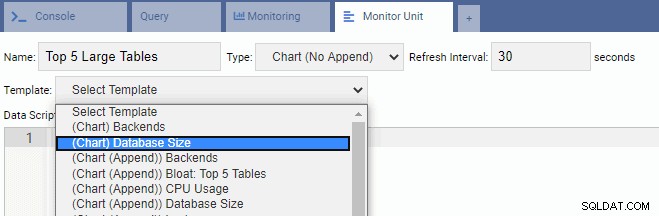
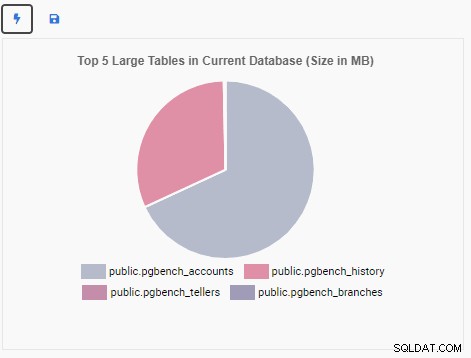
Vi kommer nu att skapa en övervakningsenhet för att visa topp 5 stora tabeller i den aktuella databasen. Baserat på den databas som valts i OmniDB kommer övervakningsenheten att ändra sin visning för att återspegla namnen på de fem största tabellerna i databasen.
För att skriva en ny enhet är det bäst att börja med en befintlig mall och ändra dess kod. Detta kommer att spara både tid och ansträngning. I följande bild har vi döpt vår övervakningsenhet till "Topp 5 stora tabeller". Vi har valt att det ska vara av diagramtyp (ingen tillägg) och tillhandahållit en uppdateringshastighet på 30 sekunder. Vi har också baserat vår övervakningsenhet på mallen för databasstorlek:
Textrutan Data Script fylls automatiskt i med koden för Database Size Monitoring Unit:
från datetime import datetimefrom random import randintdatabases =connection.Query(''' SELECT d.datname AS datname, round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) d.d.storlek _ fROM pg-database. datname not in ('mall0','mall1')''')data =[]färg =[]etikett =[]för db i databaser.Rader: data.append(db["size") color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FRÅN pg_catalog.pg_database WHERE NOT datistemplate'l" result"l" ":etikett, "dataset":[ { "data":data, "bakgrundsfärg":färg, "etikett":"Datauppsättning 1" } : " MB)" }Och textrutan Diagramskript är också fylld med kod:
total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FRÅN pg_catalog.pg_database WHERE NOT datistemplate'' ') result type" {":" ') , "data":Inga, "options":{ "responsive":True, "title":{ "display":True, "text":"Databasstorlek "(+str") "total:"_) } }}Vi kan modifiera dataskriptet för att få de 5 översta stora tabellerna i databasen. I skriptet nedan har vi behållit det mesta av originalkoden, förutom SQL-satsen:
från datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tabellnamn", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" FRÅN pg_class C LEFT JOIN pg_namespace N ON (N.oid =C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') OCH C.relkind <> 'i' AND nspname !~ '^pg_DER to BY 2 DESC LIMIT 5;''')data =[]färg =[]etikett =[]för tabell i tabeller. Rader: data.append(tabell["tabellstorlek"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(tabell["tabellnamn" ])result ={ "etiketter":etikett, "dataset":[ { "data":data, "bakgrundsfärg":färg, ”etikett” }Här får vi den kombinerade storleken på varje tabell och dess index i den aktuella databasen. Vi sorterar resultaten i fallande ordning och väljer de fem översta raderna.
Därefter fyller vi i tre Python-arrayer genom att iterera över resultatuppsättningen.
Slutligen bygger vi en JSON-sträng baserat på arrayernas värden.
I textrutan Diagramskript har vi modifierat koden för att ta bort det ursprungliga SQL-kommandot. Här specificerar vi bara den kosmetiska aspekten av diagrammet. Vi definierar diagrammet som pajtyp och tillhandahåller en titel för det:
result ={ "type":"pie", "data":Inga, "options":{ "responsive":True, "title":{ "display":True, " Tabeller i aktuell databas (storlek i MB)" } }}Nu kan vi testa enheten genom att klicka på blixtikonen. Detta kommer att visa den nya övervakningsenheten i förhandsgranskningen:
Därefter sparar vi enheten genom att klicka på diskikonen. En meddelanderuta bekräftar att enheten har sparats:
Vi går nu tillbaka till vår övervakningspanel och lägger till den nya övervakningsenheten:
Lägg märke till hur vi har ytterligare två ikoner under kolumnen "Åtgärder" för vår anpassade övervakningsenhet. En är för att redigera den, den andra är för att ta bort den från OmniDB.
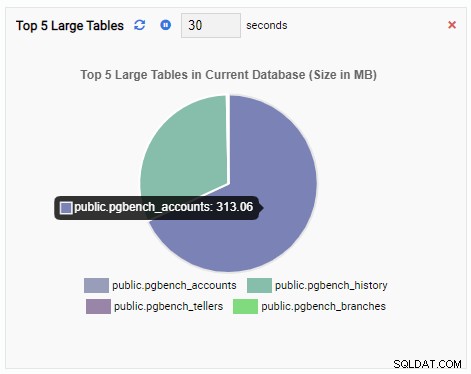
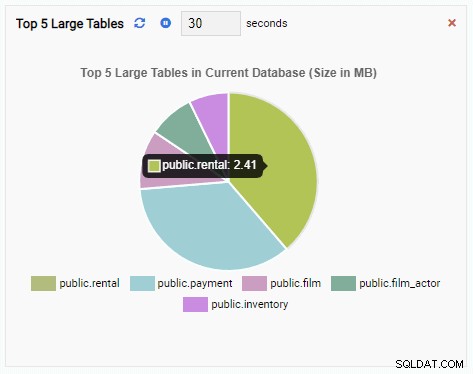
Övervakningsenheten "Topp 5 stora tabeller" visar nu de fem största tabellerna i den aktuella databasen:
Om vi stänger instrumentpanelen, byter till en annan databas från navigeringsfönstret och öppnar instrumentpanelen igen, kommer vi att se att övervakningsenheten har ändrats för att återspegla tabellerna i den databasen:
Slutord
Detta avslutar vår tvådelade serie om OmniDB. Som vi såg har OmniDB några fiffiga övervakningsenheter som PostgreSQL DBA:er kommer att finna användbara för prestationsspårning. Vi såg hur vi kan använda dessa enheter för att identifiera potentiella flaskhalsar i servern. Vi såg också hur man skapar våra egna anpassade enheter. Läsare uppmuntras att skapa och testa prestandaövervakningsenheter för sina specifika arbetsbelastningar. 2ndQuadrant välkomnar alla bidrag till OmniDB Monitoring Unit GitHub-repo.