I en tidigare blogg hade vi diskuterat hur man migrerar en fristående Moodle-inställning till skalbar installation baserad på en klustrad databas. Nästa steg du måste tänka på är failover-mekanismen - vad gör du om och när din databastjänst går ner.
En misslyckad databasserver är inte ovanlig om du har MySQL-replikering som din backend-Moodle-databas, och om det händer måste du hitta ett sätt att återställa din topologi genom att till exempel marknadsföra en standby-server till bli en ny primär server. Att ha automatisk failover för din Moodle MySQL-databas hjälper apparnas drifttid. Vi kommer att förklara hur failover-mekanismer fungerar och hur man bygger in automatisk failover i din installation.
Hög tillgänglighetsarkitektur för MySQL-databas
Hög tillgänglighetsarkitektur kan uppnås genom att klustera din MySQL-databas på ett par olika sätt. Du kan använda MySQL-replikering, ställa in flera repliker som noga följer din primära databas. Utöver det kan du sätta en databaslastbalanserare för att dela läs/skrivtrafiken och fördela trafiken över läs-skriv- och skrivskyddade noder. Databasarkitektur med hög tillgänglighet som använder MySQL-replikering kan beskrivas enligt nedan:
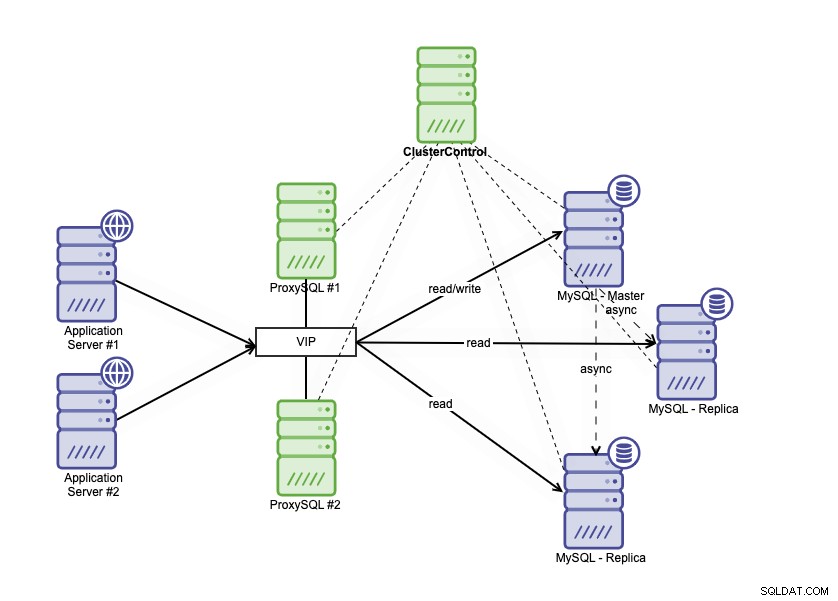
Den består av en primär databas, två databasrepliker och databaslastbalanserare (i den här bloggen använder vi ProxySQL som databaslastbalanserare), och keepalived som en tjänst för att övervaka ProxySQL-processerna. Vi använder virtuell IP-adress som en enda anslutning från applikationen. Trafiken kommer att distribueras till den aktiva lastbalanseraren baserat på rollflaggan i Keepalved.
ProxySQL kan analysera trafiken och förstå om en begäran är en läsning eller en skrivning. Den kommer sedan att vidarebefordra förfrågan till lämplig(a) värd(ar).
Filover på MySQL-replikering
MySQL-replikering använder binär loggning för att replikera data från den primära till replikerna. Replikerna ansluter till den primära noden, och varje ändring replikeras och skrivs till repliknodernas reläloggar via IO_THREAD. Efter att ändringarna har lagrats i reläloggen fortsätter SQL_THREAD-processen med att applicera data i replikdatabasen.
Standardinställningen för parameter read_only i en replik är PÅ. Den används för att skydda själva repliken från all direkt skrivning, så ändringarna kommer alltid från den primära databasen. Detta är viktigt eftersom vi inte vill att repliken ska avvika från den primära servern. Failover-scenario i MySQL-replikering inträffar när den primära inte kan nås. Det kan finnas många anledningar till detta; t.ex. serverkraschar eller nätverksproblem.
Du måste främja en av replikerna till primär, inaktivera den skrivskyddade parametern på den marknadsförda repliken så att den kan vara skrivbar. Du måste också ändra den andra repliken för att ansluta till den nya primära. I GTID-läge behöver du inte notera det binära loggnamnet och positionen varifrån du ska återuppta replikeringen. Men i traditionell binlogbaserad replikering behöver du definitivt veta det sista binära loggnamnet och positionen för att fortsätta. Failover i binlog-baserad replikering är en ganska komplex process, men även failover i GTID-baserad replikering är inte trivialt heller eftersom du måste se upp för saker som felaktiga transaktioner. Att upptäcka ett fel är en sak, och att sedan reagera på felet inom en kort fördröjning är förmodligen inte möjligt utan automatisering.
Hur ClusterControl aktiverar automatisk failover
ClusterControl har förmågan att utföra automatisk failover för din Moodle MySQL-databas. Det finns en funktion för automatisk återställning för kluster och noder som utlöser failover-processen när den primära databasen kraschar.
Vi kommer att simulera hur Automatic Failover sker i ClusterControl. Vi kommer att få den primära databasen att krascha och bara se på ClusterControl-instrumentpanelen. Nedan är den aktuella topologin för klustret:
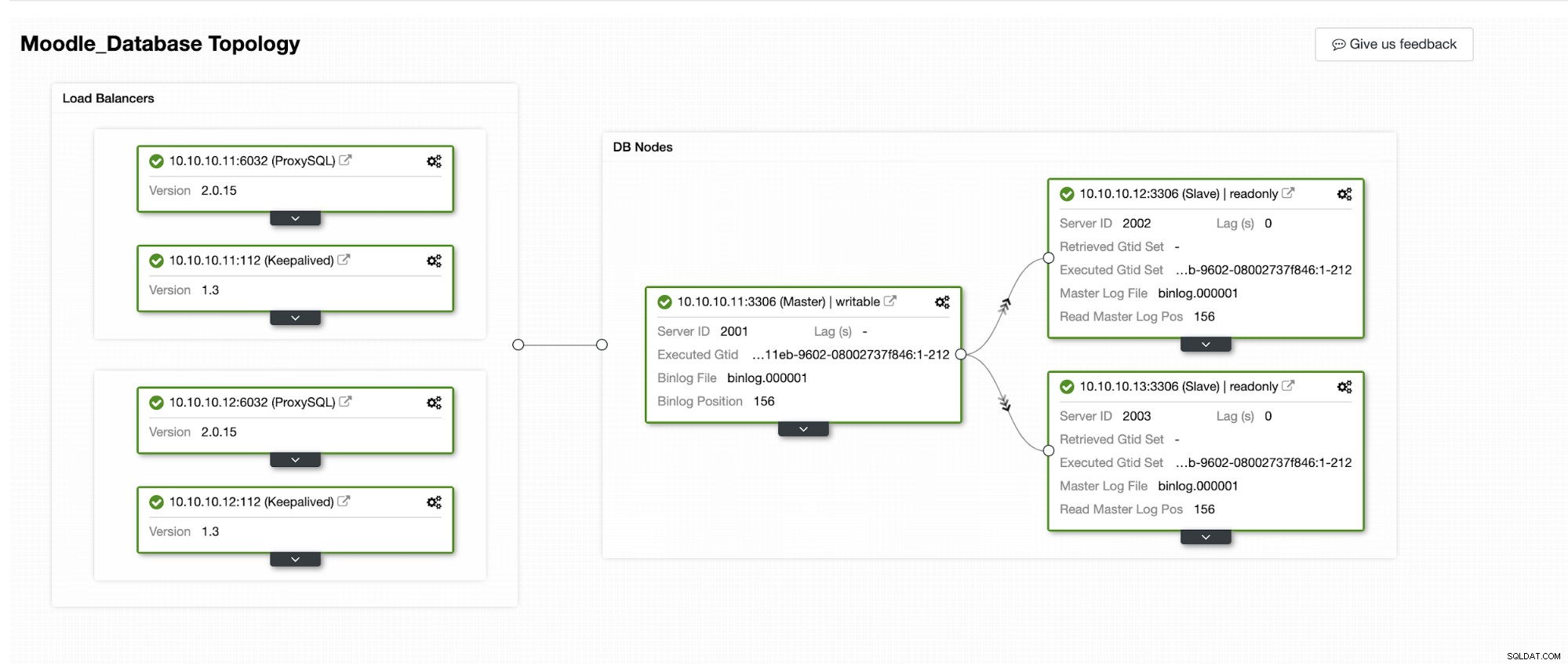
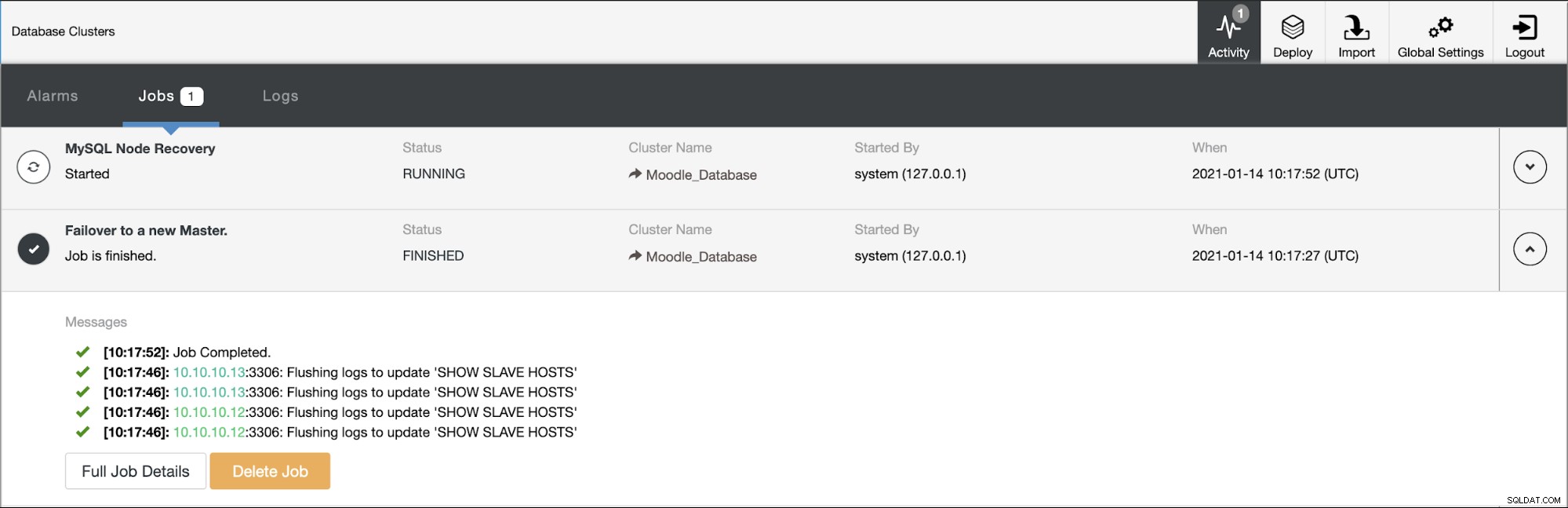
Den primära databasen använder IP-adress 10.10.10.11 och replikerna är:10.10.10.12 och 10.10.10.13. När kraschen inträffar på den primära, utlöser ClusterControl en varning och en failover startar som visas i bilden nedan:
En av replikerna kommer att flyttas upp till primär, vilket resulterar i Topologin som i bilden nedan:
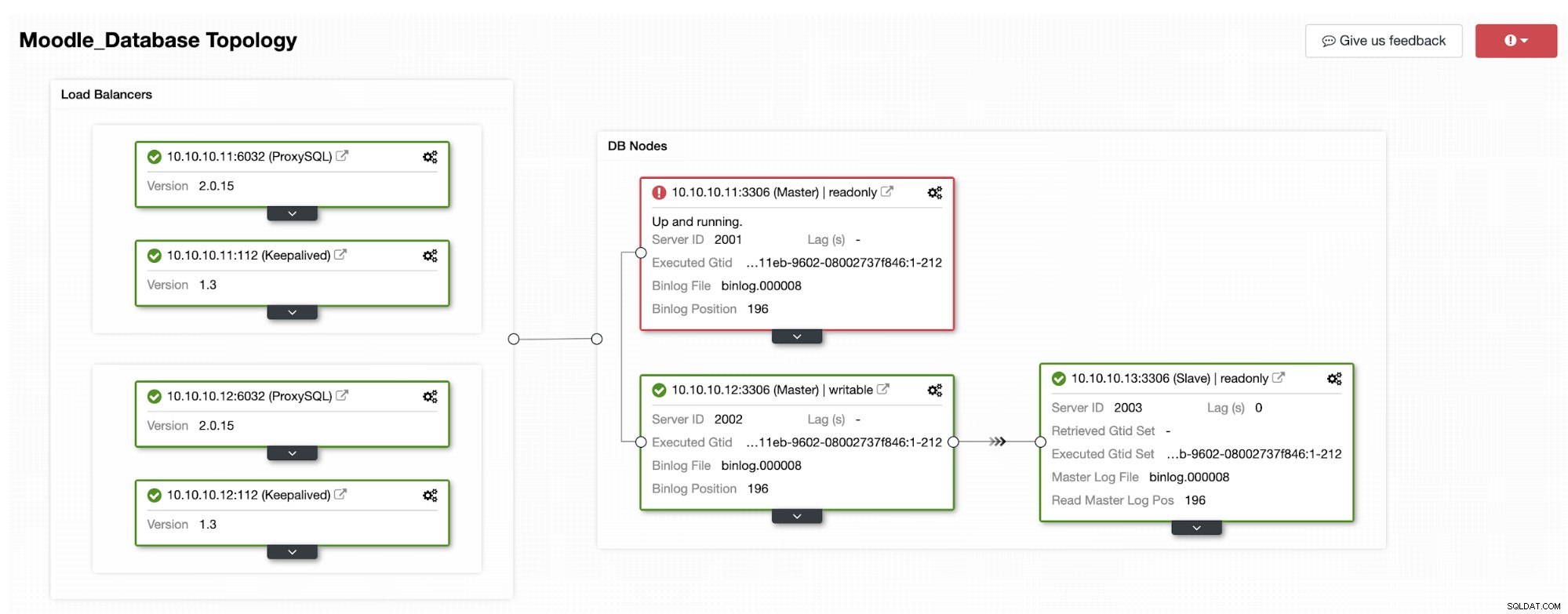
IP-adressen 10.10.10.12 betjänar nu skrivtrafiken som primär, och även vi har bara en replika som har IP-adress 10.10.10.13. På ProxySQL-sidan kommer proxyn att upptäcka den nya primära automatiskt. Hostgroup (HG10) betjänar fortfarande skrivtrafiken som har medlem 10.10.10.12 som visas nedan:

Värdgrupp (HG20) kan fortfarande betjäna läst trafik, men som du kan se noden 10.10.10.11 är offline på grund av kraschen :
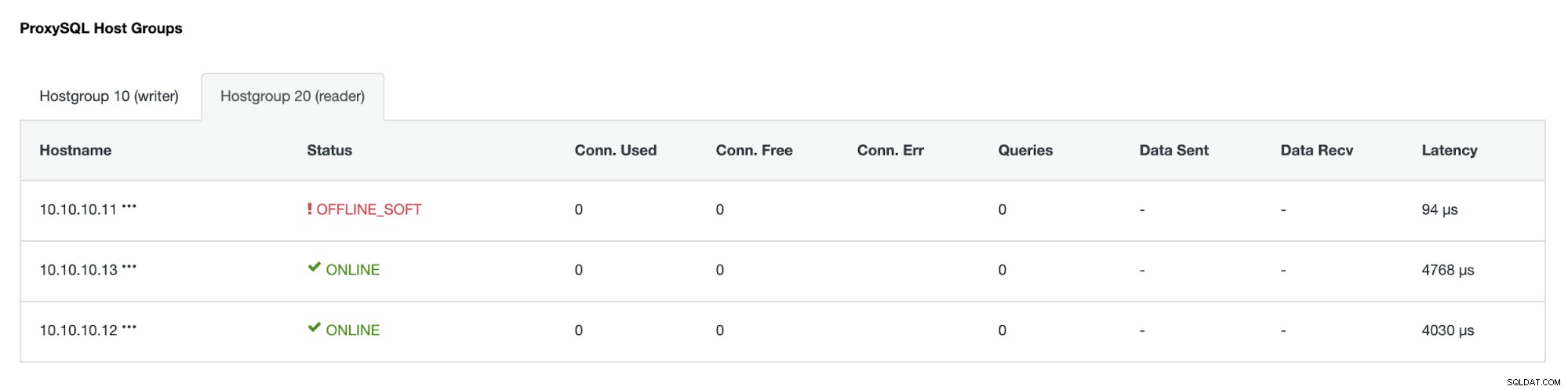
När den primära misslyckade servern är online igen kommer den inte att återupptas automatiskt -introducerad i databastopologin. Detta för att undvika att förlora felsökningsinformation, eftersom att återinföra noden som en replika kan kräva att vissa loggar eller annan information skrivs över. Men det är möjligt att konfigurera auto-rejoin för den misslyckade noden.