I mitt förra inlägg ("Dude, vem äger den där #temp-tabellen?") föreslog jag att du i SQL Server 2012 och senare kunde använda Extended Events för att övervaka skapandet av #temp-tabeller. Detta skulle tillåta dig att korrelera specifika objekt som tar upp mycket utrymme i tempdb med sessionen som skapade dem (till exempel för att avgöra om sessionen kan dödas för att försöka frigöra utrymmet). Vad jag inte diskuterade är omkostnaderna för denna spårning – vi förväntar oss att utökade händelser är lättare än spår, men ingen övervakning är helt gratis.
Eftersom de flesta människor lämnar standardspårningen aktiverad lämnar vi det på plats. Vi testar båda högarna med SELECT INTO (som standardspårningen inte kommer att samla in) och klustrade index (vilket det kommer att göra), och vi kommer att tajma satsen på egen hand som en baslinje, och sedan köra partiet igen med Extended Event-sessionen igång. Vi kommer också att testa mot både SQL Server 2012 och SQL Server 2014. Batchen i sig är ganska enkel:
STÄLL IN NOCOUNT PÅ; VÄLJ SYSDATETIME();GO -- kör den här delen för endast heapbatchen:SELECT TOP (100) [object_id] INTO #foo FRÅN sys.all_objects BESTÄLLNING EFTER [object_id];SLÄPP TABELL #foo; -- kör den här delen endast för CIX-batchen:CREATE TABLE #bar(id INT PRIMARY KEY);INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects BESTÄLLNING EFTER [object_id];; GÅ 100000 VÄLJ SYSDATETIME();
Båda instanserna har tempdb konfigurerat med fyra datafiler och med TF 1117 och TF 1118 aktiverade, i en virtuell dator med fyra processorer, 16 GB minne och endast SSD. Jag skapade avsiktligt små #temp-tabeller för att förstärka eventuella observerade effekter på själva batchen (som skulle drunkna om det tog lång tid att skapa #temp-tabellerna eller orsakade överdriven autotillväxt).
Jag körde dessa batcher i varje scenario, och här var resultaten, mätt i batchvaraktighet i sekunder:
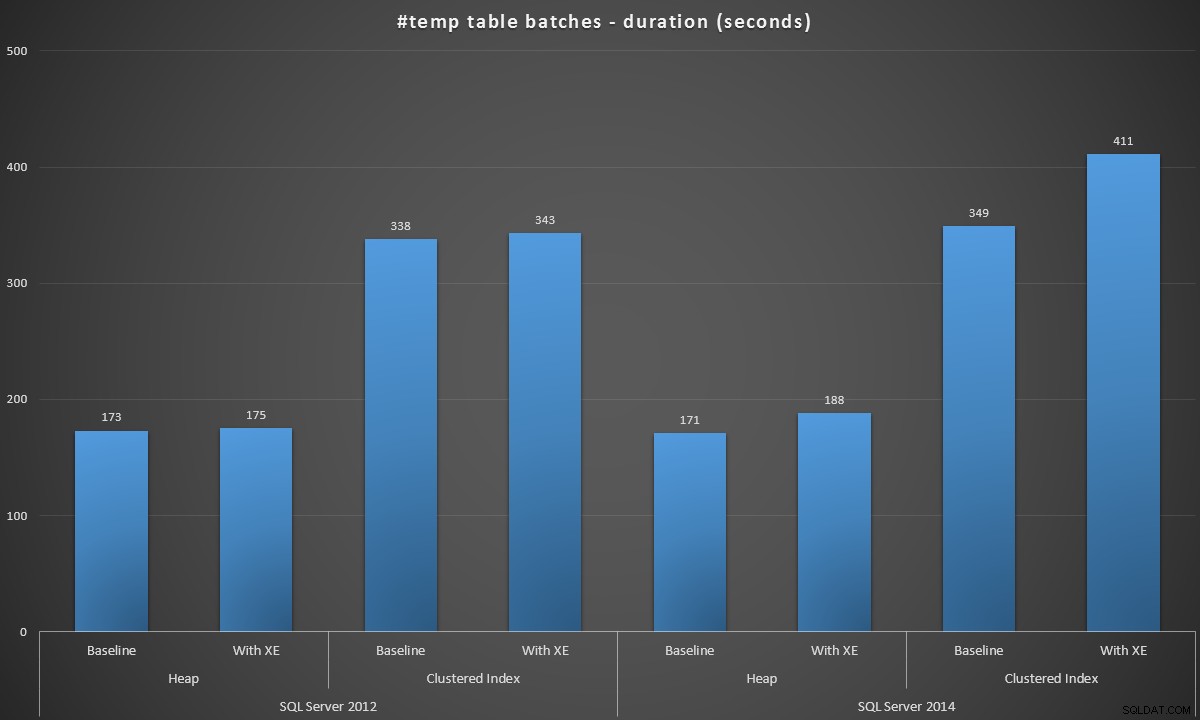
Batchlängd, i sekunder, för att skapa 100 000 #temp-tabeller
Om vi uttrycker data lite annorlunda, om vi dividerar 100 000 med varaktigheten, kan vi visa antalet #temp-tabeller vi kan skapa per sekund i varje scenario (läs:genomströmning). Här är resultaten:
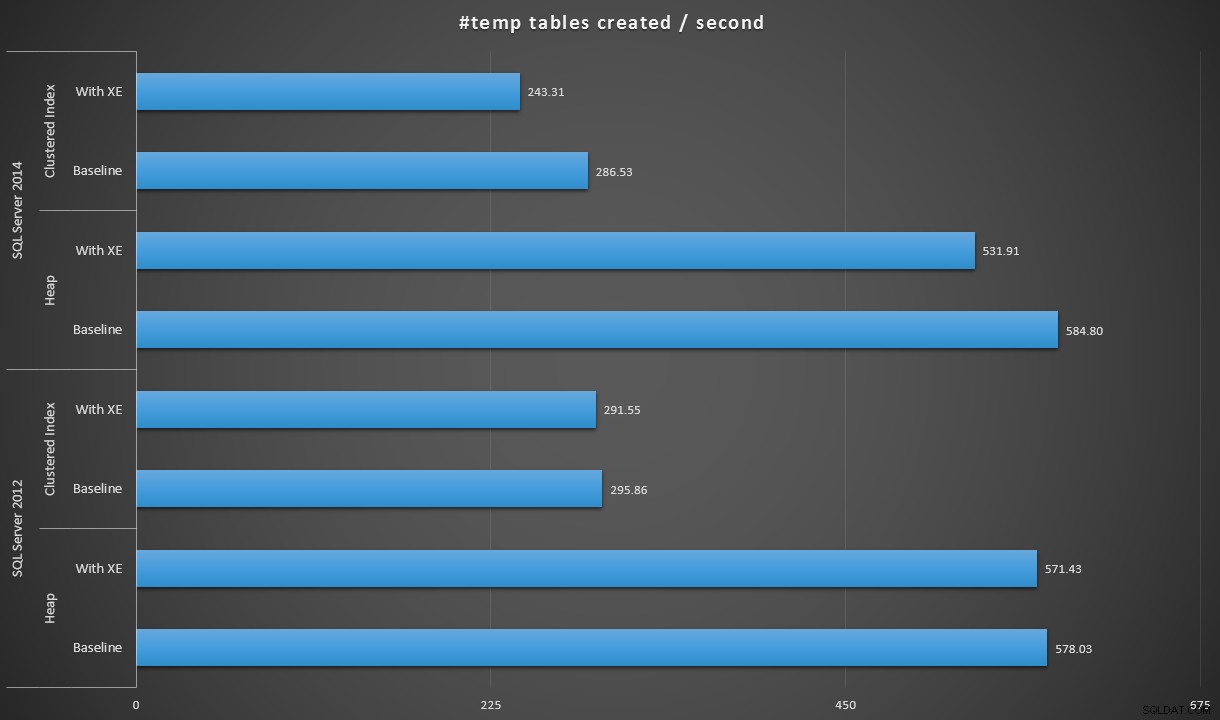
#temp tabeller skapade per sekund under varje scenario
Resultaten var lite överraskande för mig – jag förväntade mig att, med SQL Server 2014-förbättringarna i ivrig skrivlogik, skulle högpopulationen åtminstone gå mycket snabbare. Högen 2014 var två ynka sekunder snabbare än 2012 vid baslinjekonfigurationen, men Extended Events drev upp tiden ganska mycket (ungefär en 10% ökning jämfört med baslinjen); medan den klustrade indextiden var jämförbar med 2012 vid baslinjen, men ökade med nästan 18 % med Extended Events aktiverat. Under 2012 var deltan för heaps och klustrade index mycket mer blygsamma – 1,1 % respektive 1,5 %. (Och för att vara tydlig, inga autotillväxthändelser inträffade under något av testerna.)
Så jag tänkte, vad händer om jag skapade en smalare, elakare session med utökade evenemang? Visst skulle jag kunna ta bort några av dessa åtgärdskolumner – kanske behöver jag bara inloggningsnamn och spid, och kan ignorera appnamnet, värdnamnet och potentiellt dyra sql_text. Kanske skulle jag kunna släppa det extra filtret mot commit (samla dubbelt så många händelser, men mindre CPU spenderas på filtrering) och tillåta flera händelseförluster för att minska den potentiella påverkan på arbetsbelastningen. Den här smalare sessionen ser ut så här:
SKAPA HÄNDELSESESSION [TempTableCreation2014_LeanerMeaner] PÅ SERVER LÄGG TILL HÄNDELSER sqlserver.object_created( ACTION ( sqlserver.server_principal_name, sqlserver.session_id ) WHERE ( sqlserver.like_icodesqDAR_geta_fil_fil_fil_fil_fil_fil_fil_fil_2014_serv_file.com ( SET FILENAME ='c:\temp\TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32768, MAX_ROLLOVER_FILES =10)MED ( EVENT_RETENTION_MODE =ALLOW_MULTIPLE_EVENTION_LOSS]Föregående STYRELSE1VÄNDIGT 1 SÄTT 1FÖREVÄNDIGT 2;Ack, nej, samma resultat. Drygt tre minuter för högen och knappt sju minuter för det klustrade indexet. För att gräva djupare i var den extra tiden spenderades tittade jag på 2014 års instans med SQL Sentry och körde bara den klustrade indexbatchen utan att några Extended Event-sessioner konfigurerats. Sedan körde jag batchen igen, den här gången med den lättare XE-sessionen konfigurerad. Batchtiderna var 5:47 (347 sekunder) och 6:55 (415 sekunder) – så mycket i linje med föregående batch (jag var glad att se att vår övervakning inte bidrog längre till varaktigheten :-)) . Jag validerade att inga händelser avbröts, och återigen att inga autogrow-händelser inträffade.
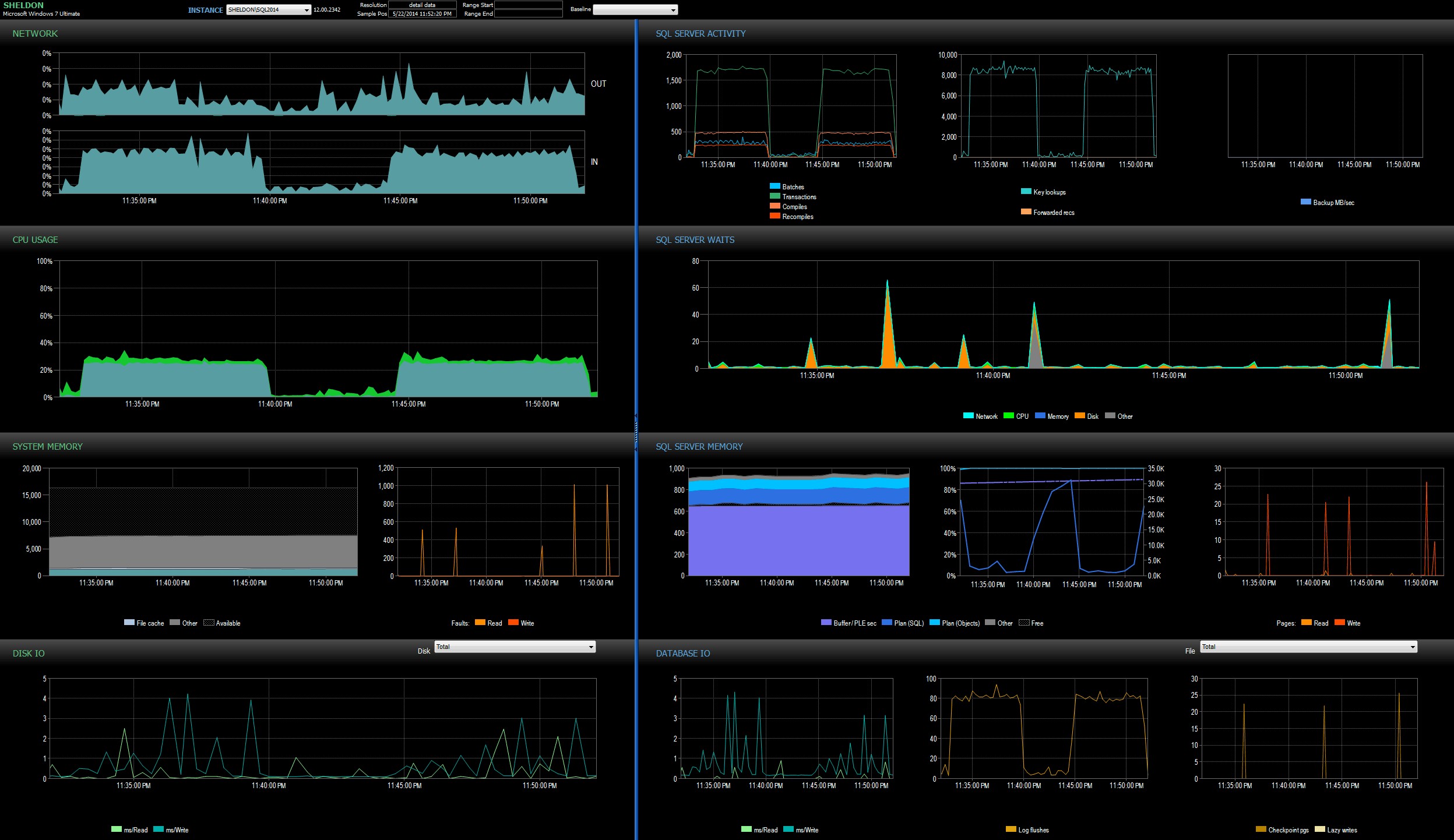
Jag tittade på SQL Sentry-instrumentpanelen i historikläge, vilket gjorde att jag snabbt kunde se prestandastatistiken för båda batcherna sida vid sida:
SQL Sentry-instrumentpanel, i historikläge, som visar båda batchernaBåda partierna var praktiskt taget identiska när det gäller nätverk, CPU, transaktioner, kompileringar, nyckeluppslag etc. Det finns en viss skillnad i Waits – topparna under den första batchen var uteslutande WRITELOG, medan det fanns några mindre CXPACKET-väntningar i andra satsen. Min arbetsteori långt efter midnatt är att kanske en stor del av fördröjningen som observerades berodde på kontextväxling orsakad av Extended Event-processen. Eftersom vi inte har någon insyn i exakt vad XE gör under täcket, och inte heller vet vilken underliggande mekanik som har förändrats i XE mellan 2012 och 2014, det är den historia jag kommer att hålla fast vid för nu, tills jag är mer bekväm med xperf och/eller WinDbg.
Slutsats
I vilket fall som helst är det tydligt att spårning av #temp-tabellskapande inte är gratis, och kostnaden kan variera beroende på vilken typ av #temp-tabeller du skapar, mängden information du samlar in i dina XE-sessioner och till och med versionen av SQL Server du använder. Så du kan köra liknande tester som jag har gjort här och bestämma hur värdefullt det är att samla in denna information i din miljö.