I de senaste bloggarna tog vi upp hur man kör ett Galera-kluster på Docker, oavsett om det är på fristående Docker eller på Docker Swarm med flera värdar med överlagringsnätverk. I det här blogginlägget kommer vi att titta på att köra Galera Cluster på Kubernetes, ett orkestreringsverktyg för att köra containrar i stor skala. Vissa delar är olika, till exempel hur applikationen ska ansluta till klustret, hur Kubernetes hanterar failover och hur lastbalanseringen fungerar i Kubernetes.
Kubernetes vs Docker Swarm
Vårt yttersta mål är att säkerställa att Galera Cluster körs tillförlitligt i en containermiljö. Vi har tidigare täckt Docker Swarm, och det visade sig att köra Galera Cluster på den har ett antal blockerare, som hindrar den från att vara produktionsklar. Vår resa fortsätter nu med Kubernetes, ett containerorkestreringsverktyg av produktionskvalitet. Låt oss se vilken nivå av "produktionsberedskap" den kan stödja när du kör en tillståndsfull tjänst som Galera Cluster.
Innan vi går vidare, låt oss lyfta fram några av de viktigaste skillnaderna mellan Kubernetes (1.6) och Docker Swarm (17.03) när vi kör Galera Cluster på containrar:
- Kubernetes stöder två hälsokontrollsonder - livlighet och beredskap. Detta är viktigt när du kör ett Galera-kluster på containrar, eftersom en levande Galera-container inte betyder att den är redo att serveras och bör inkluderas i lastbalanseringsuppsättningen (tänk på en sammanfognings-/donatorstat). Docker Swarm stöder bara en hälsokontrollsond som liknar Kubernetes livlighet, en behållare är antingen frisk och fortsätter att gå eller ohälsosam och blir omplanerad. Läs här för mer information.
- Kubernetes har en instrumentpanel för användargränssnitt som är tillgänglig via "kubectl proxy".
- Docker Swarm stöder endast round-robin lastbalansering (ingress), medan Kubernetes använder minst anslutning.
- Docker Swarm stöder routingmesh för att publicera en tjänst till det externa nätverket, medan Kubernetes stöder något liknande som heter NodePort, såväl som externa lastbalanserare (GCE GLB/AWS ELB) och externa DNS-namn (som för v1.7)
Installera Kubernetes med Kubeadm
Vi kommer att använda kubeadm för att installera ett Kubernetes-kluster med 3 noder på CentOS 7. Det består av 1 master och 2 noder (minions). Vår fysiska arkitektur ser ut så här:
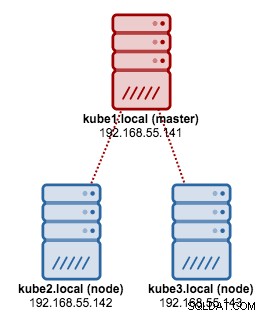
1. Installera kubelet och Docker på alla noder:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. På mastern, initiera mastern, kopiera konfigurationsfilen, konfigurera Pod-nätverket med Weave och installera Kubernetes Dashboard:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Sedan på de andra återstående noderna:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Kontrollera att noderna är klara:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3Vi har nu ett Kubernetes-kluster för Galera Cluster-distribution.
Galera Cluster på Kubernetes
I det här exemplet kommer vi att distribuera ett MariaDB Galera Cluster 10.1 med Docker-avbildning hämtad från vårt DockerHub-förråd. YAML-definitionsfilerna som används i den här distributionen finns under exempel-kubernetes-katalogen i Github-förvaret.
Kubernetes stöder ett antal distributionskontroller. För att distribuera ett Galera-kluster kan man använda:
- ReplicaSet
- StatefulSet
Var och en av dem har sina egna för- och nackdelar. Vi kommer att undersöka var och en av dem och se vad som är skillnaden.
Förutsättningar
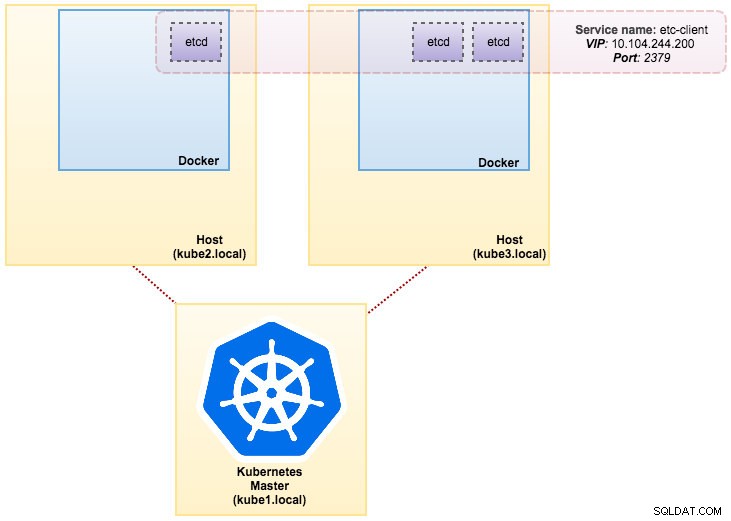
Bilden som vi byggde kräver en etcd (fristående eller kluster) för att upptäcka tjänster. För att köra ett etcd-kluster krävs att varje etcd-instans körs med olika kommandon så vi kommer att använda Pods-kontroller istället för Deployment och skapa en tjänst som heter "etcd-client" som slutpunkt till etcd Pods. Definitionsfilen etcd-cluster.yaml berättar allt.
För att distribuera ett 3-pod etcd-kluster, kör helt enkelt:
$ kubectl create -f etcd-cluster.yamlKontrollera om etcd-klustret är klart:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dVår arkitektur ser nu ut ungefär så här:
 Severalnines MySQL på Docker:How to Containerize Your DatabaseUpptäck allt du behöver förstå när du överväger att köra en MySQL-tjänst toppen av Docker-containervirtualisering Ladda ner vitboken
Severalnines MySQL på Docker:How to Containerize Your DatabaseUpptäck allt du behöver förstå när du överväger att köra en MySQL-tjänst toppen av Docker-containervirtualisering Ladda ner vitboken Använda ReplicaSet
Ett ReplicaSet säkerställer att ett specificerat antal pod-"repliker" körs vid varje given tidpunkt. En Deployment är dock ett koncept på högre nivå som hanterar ReplicaSets och ger deklarativa uppdateringar till pods tillsammans med många andra användbara funktioner. Därför rekommenderas det att använda Deployments istället för att direkt använda ReplicaSets, såvida du inte behöver anpassad uppdateringsorkestrering eller inte behöver uppdateringar alls. När du använder distributioner behöver du inte oroa dig för att hantera replicaSets som de skapar. Implementeringar äger och hanterar sina ReplicaSets.
I vårt fall kommer vi att använda Deployment som arbetsbelastningskontroller, som visas i denna YAML-definition. Vi kan skapa Galera Cluster ReplicaSet och Service direkt genom att köra följande kommando:
$ kubectl create -f mariadb-rs.ymlVerifiera om klustret är klart genom att titta på ReplicaSet (rs), pods (po) och tjänster (svc):
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dFrån utgången ovan kan vi illustrera våra Pods och Service enligt nedan:
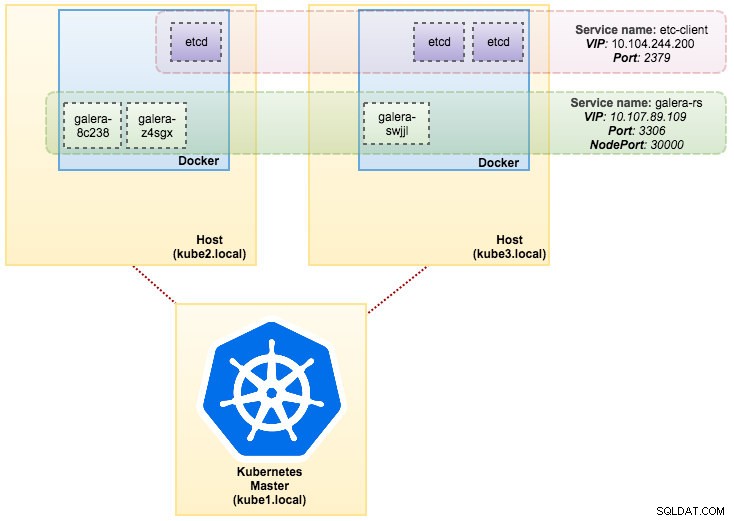
Att köra Galera Cluster på ReplicaSet liknar att behandla det som ett tillståndslöst program. Den orkestrerar skapande, radering och uppdateringar av poddar och kan riktas mot Horizontal Pod Autoscales (HPA), d.v.s. en ReplicaSet kan skalas automatiskt om den uppfyller vissa trösklar eller mål (CPU-användning, paket-per-sekund, begäran-per-sekund etc).
Om en av Kubernetes-noderna går ner kommer nya Pods att schemaläggas på en tillgänglig nod för att möta de önskade replikerna. Volymer som är associerade med podden kommer att raderas om podden tas bort eller omplaneras. Pod-värdnamnet kommer att genereras slumpmässigt, vilket gör det svårare att spåra var behållaren hör hemma genom att helt enkelt titta på värdnamnet.
Allt detta fungerar ganska bra i test- och iscensättningsmiljöer, där du kan utföra en fullständig containerlivscykel som att distribuera, skala, uppdatera och förstöra utan några beroenden. Det är enkelt att skala upp och ned genom att uppdatera YAML-filen och lägga upp den i Kubernetes-klustret eller genom att använda kommandot skala:
$ kubectl scale replicaset galera-rs --replicas=5Använda StatefulSet
Känd som PetSet på pre 1.6 version, StatefulSet är det bästa sättet att distribuera Galera Cluster i produktion, eftersom:
- Att radera och/eller skala ner en StatefulSet kommer inte att radera de volymer som är associerade med StatefulSet. Detta görs för att säkerställa datasäkerhet, vilket i allmänhet är mer värdefullt än en automatisk rensning av alla relaterade StatefulSet-resurser.
- För en StatefulSet med N repliker, när Pods distribueras, skapas de sekventiellt, i ordning från {0 .. N-1 }.
- När Pods tas bort avslutas de i omvänd ordning, från {N-1 .. 0}.
- Innan en skalningsoperation tillämpas på en Pod måste alla dess föregångare vara igång och redo.
- Innan en Pod avslutas måste alla dess efterföljare stängas av helt.
StatefulSet ger förstklassigt stöd för stateful containrar. Det ger en distributions- och skalningsgaranti. När ett Galera-kluster med tre noder skapas, kommer tre Pods att distribueras i ordningen db-0, db-1, db-2. db-1 kommer inte att distribueras innan db-0 är "Kör och redo", och db-2 kommer inte att distribueras förrän db-1 är "Kör och redo". Om db-0 skulle misslyckas, efter att db-1 är "Kör och redo", men innan db-2 lanseras, kommer db-2 inte att startas förrän db-0 har framgångsrikt återlanserats och blir "Kör och redo".
Vi kommer att använda Kubernetes implementering av beständig lagring som heter PersistentVolume och PersistentVolumeClaim. Detta för att säkerställa databeständighet om podden flyttades om till den andra noden. Även om Galera Cluster tillhandahåller den exakta kopian av data på varje replik, är det bra att ha data bestående i varje pod för felsökning och återställning.
För att skapa en beständig lagring måste vi först skapa PersistentVolume för varje pod. PV:er är volymplugins som Volymer i Docker, men har en livscykel oberoende av varje enskild pod som använder PV. Eftersom vi kommer att distribuera ett Galera-kluster med 3 noder måste vi skapa 3 PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirOvanstående definition visar att vi kommer att skapa 3 PV, mappade till Kubernetes-nodernas fysiska väg med 10 GB lagringsutrymme. Vi definierade ReadWriteOnce, vilket innebär att volymen kan monteras som läs-skriv av endast en enda nod. Spara raderna ovan i mariadb-pv.yml och skicka dem till Kubernetes:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdDärefter definierar du PersistentVolumeClaim-resurserna:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"Ovanstående definition visar att vi skulle vilja göra anspråk på PV-resurserna och använda spec.selector.matchLabels för att leta efter vår PV (metadata.labels.app:galera-ss ) baserat på respektive podindex (metadata.labels.podindex ) tilldelad av Kubernetes. metadata.name resursen måste använda formatet "{volumeMounts.name}-{pod}-{ordinal index}" definierat under spec.templates.containers så Kubernetes vet vilken monteringspunkt som ska mappa anspråket till podden.
Spara raderna ovan i mariadb-pvc.yml och skicka dem till Kubernetes:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdVår persistenta lagring är nu klar. Vi kan sedan starta Galera Cluster-distributionen genom att skapa en StatefulSet-resurs tillsammans med Headless-tjänstresursen som visas i mariadb-ss.yml:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdHämta nu sammanfattningen av vår StatefulSet-distribution:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dVid denna tidpunkt kan vårt Galera-kluster som körs på StatefulSet illustreras som i följande diagram:
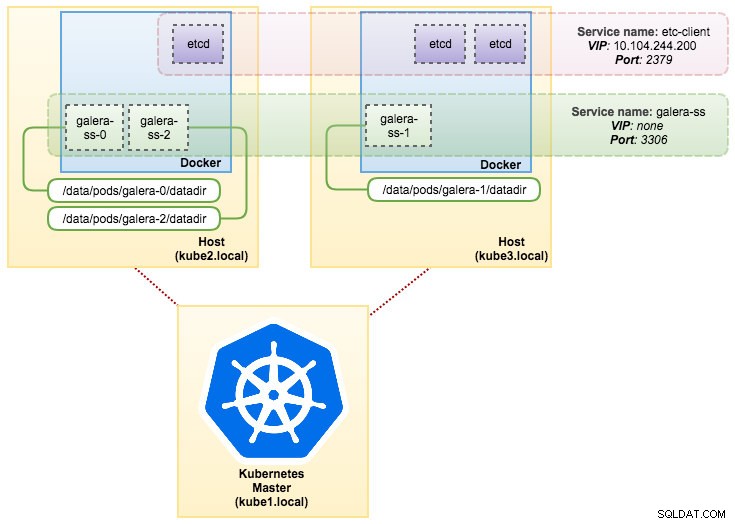
Att köra på StatefulSet garanterar konsekventa identifierare som värdnamn, IP-adress, nätverks-ID, klusterdomän, Pod-DNS och lagring. Detta gör att Podden enkelt kan skilja sig från andra i en grupp Pods. Volymen kommer att behållas på värden och kommer inte att tas bort om Podden tas bort eller omplaneras till en annan nod. Detta möjliggör dataåterställning och minskar risken för total dataförlust.
På den negativa sidan kommer implementeringstiden att vara N-1 gånger (N =repliker) längre eftersom Kubernetes kommer att följa ordningsföljden när resurserna distribueras, ändras eller tas bort. Det skulle vara lite krångligt att förbereda PV och påståenden innan du funderar på att skala ditt kluster. Observera att uppdatering av ett befintligt StatefulSet för närvarande är en manuell process, där du bara kan uppdatera spec.replicas för tillfället.
Ansluter till Galera Cluster Service och Pods
Det finns ett par sätt du kan ansluta till databasklustret. Du kan ansluta direkt till porten. I "galera-rs"-tjänstexemplet använder vi NodePort, och exponerar tjänsten på varje Nodes IP vid en statisk port (NodePorten). En ClusterIP-tjänst, som NodePort-tjänsten kommer att dirigera till, skapas automatiskt. Du kommer att kunna kontakta NodePort-tjänsten utanför klustret genom att begära {NodeIP}:{NodePort} .
Exempel för att ansluta till Galera Cluster externt:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000Inom Kubernetes nätverksutrymme kan Pods ansluta via kluster-IP eller tjänstnamn internt som kan hämtas genom att använda följande kommando:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>Från tjänstelistan kan vi se att Galera Cluster ReplicaSet Cluster-IP är 10.107.89.109. Internt kan en annan pod komma åt databasen via denna IP-adress eller tjänstnamn med den exponerade porten, 3306:
(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Du kan också ansluta till den externa NodePorten från valfri pod på port 30000:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Anslutningen till backend-podarna kommer att lastbalanseras i enlighet med detta baserat på minsta anslutningsalgoritm.
Sammanfattning
Vid det här laget verkar det mycket mer lovande att köra Galera Cluster på Kubernetes i produktion jämfört med Docker Swarm. Som diskuterades i det förra blogginlägget, hanteras farhågorna på olika sätt med hur Kubernetes orkestrerar behållare i StatefulSet, (även om det fortfarande är en betafunktion i v1.6). Vi hoppas verkligen att det föreslagna tillvägagångssättet kommer att hjälpa till att driva Galera Cluster på containrar i stor skala i produktionen.