För några veckor sedan var SQLskills-teamet i Tampa för vårt Performance Tuning Immersion Event (IE2) och jag täckte baslinjerna. Baslinjer är ett ämne som ligger mig nära och varmt om hjärtat, eftersom de är så värdefulla av många anledningar. Två av dessa anledningar, som jag alltid tar upp oavsett om jag undervisar eller arbetar med klienter, är att använda baslinjer för att felsöka prestanda, och sedan också trendanvändning och tillhandahålla uppskattningar av kapacitetsplanering. Men de är också viktiga när du ställer in prestanda eller testar – oavsett om du tänker på dina befintliga prestandamått som baslinjer eller inte.
Under modulen granskade jag olika källor för data som Performance Monitor, DMV:erna och spårnings- eller XE-data, och en fråga kom upp relaterad till dataladdningar. Specifikt var frågan om det är bättre att ladda data till en tabell utan index och sedan skapa dem när de är klara, jämfört med att ha indexen på plats under dataladdningen. Mitt svar var, "vanligtvis, ja". Min personliga erfarenhet har varit att så är alltid fallet, men man vet aldrig vilken varning eller engångsscenario någon kan stöta på där prestandaförändringen inte är vad som förväntades, och som med alla prestationsfrågor vet du inte säkert förrän du testar den. Tills du upprättar en baslinje för en metod och sedan ser om den andra metoden förbättrar den baslinjen, gissar du bara. Jag tänkte att det skulle vara kul att testa det här scenariot, inte bara för att bevisa vad jag förväntar mig ska vara sant, utan också för att visa vilka mätvärden jag skulle undersöka, varför och hur man fångar dem. Om du har gjort prestandatester tidigare är detta förmodligen gammaldags. Men för dem av er nybörjare kommer jag att gå igenom processen jag följer för att hjälpa dig komma igång. Inse att det finns många sätt att härleda svaret på "Vilken metod är bättre?" Jag förväntar mig att du kommer att ta den här processen, justera den och göra den till din med tiden.
Vad försöker du bevisa?
Det första steget är att bestämma exakt vad du testar. I vårt fall är det enkelt:är det snabbare att ladda data till en tom tabell och sedan lägga till indexen, eller är det snabbare att ha indexen i tabellen under dataladdningen? Men vi kan lägga till lite variation här om vi vill. Tänk på tiden det tar att ladda data till en hög och skapa sedan de klustrade och icke-klustrade indexen, kontra den tid det tar att ladda data till ett klustrade index, och skapa sedan de icke-klustrade indexen. Är det någon skillnad i prestanda? Skulle klustringsnyckeln vara en faktor? Jag förväntar mig att databelastningen kommer att orsaka att befintliga icke-klustrade index fragmenteras, så jag kanske vill se vilken inverkan det har på den totala varaktigheten av att återuppbygga indexen efter belastningen. Det är viktigt att omfånga detta steg så mycket som möjligt och vara mycket specifik om vad du vill mäta, eftersom detta kommer att avgöra vilken data du fångar in. För vårt exempel kommer våra fyra tester att vara:
Test 1: Ladda data i en hög, skapa det klustrade indexet, skapa de icke-klustrade indexen
Test 2: Ladda data till ett klustrade index, skapa de icke-klustrade indexen
Test 3: Skapa klustrade index och icke-klustrade index, ladda data
Test 4: Skapa det klustrade indexet och de icke-klustrade indexen, ladda data, bygg om de icke-klustrade indexen
Vad behöver du veta?
I vårt scenario är vår primära fråga "vilken metod är snabbast"? Därför vill vi mäta varaktighet och för att göra det måste vi fånga en starttid och en sluttid. Vi skulle kunna lämna det där, men vi kanske vill förstå hur resursutnyttjandet ser ut för varje metod, eller så vill vi kanske veta de högsta väntetiderna, eller antalet transaktioner eller antalet dödlägen. Vilken data som är mest intressant och relevant beror på vilka processer du jämför. Att fånga antalet transaktioner är inte så intressant för vår databelastning; men för en kodändring kan det vara det. Eftersom vi skapar index och bygger om dem är jag intresserad av hur mycket IO varje metod genererar. Även om den totala varaktigheten förmodligen är den avgörande faktorn i slutändan, kan det vara användbart att titta på IO för att inte bara förstå vilket alternativ som genererar mest IO, utan också om databaslagringen fungerar som förväntat.
Var finns data du behöver?
När du har bestämt vilken data du behöver bestämmer du varifrån den ska hämtas. Vi är intresserade av varaktighet, så vi vill registrera den tid varje dataladdningstest startar och när det slutar. Vi är också intresserade av IO, och vi kan hämta denna data från flera platser – Performance Monitor-räknare och sys.dm_io_virtual_file_stats DMV kommer att tänka på.
Förstå att vi skulle kunna få dessa data manuellt. Innan vi kör ett test kan vi välja mot sys.dm_io_virtual_file_stats och spara de aktuella värdena i en fil. Vi kan notera tiden och sedan starta testet. När det är klart noterar vi tiden igen, frågar sys.dm_io_virtual_file_stats igen och beräknar skillnader mellan värden för att mäta IO.
Det finns många brister i denna metodik, nämligen att den lämnar betydande utrymme för fel; vad händer om du glömmer att notera starttiden, eller glömmer att fånga filstatistik innan du börjar? En mycket bättre lösning är att automatisera inte bara exekveringen av skriptet, utan även datafångsten. Vi kan till exempel skapa en tabell som innehåller vår testinformation – en beskrivning av vad testet är, vilken tid det började och vilken tid det slutfördes. Vi kan inkludera filstatistiken i samma tabell. Om vi samlar in andra mätvärden kan vi lägga till dem i tabellen. Eller så kan det vara lättare att skapa en separat tabell för varje uppsättning data vi samlar in. Till exempel, om vi lagrar filstatistikdata i en annan tabell, måste vi ge varje test ett unikt id, så att vi kan matcha vårt test med rätt filstatistikdata. När vi samlar in filstatistik måste vi fånga värdena för vår databas innan vi börjar, och sedan efter, och beräkna skillnaden. Vi kan sedan lagra den informationen i sin egen tabell, tillsammans med det unika test-ID:t.
Ett exempel på övning
För det här testet skapade jag en tom kopia av tabellen Sales.SalesOrderHeader med namnet Sales.Big_SalesOrderHeader, och jag använde en variant av ett skript som jag använde i mitt partitioneringsinlägg för att ladda data till tabellen i batcher om cirka 25 000 rader. Du kan ladda ner skriptet för dataladdningen här. Jag körde det fyra gånger för varje variant, och jag varierade också det totala antalet infogade rader. För den första uppsättningen tester infogade jag 20 miljoner rader, och för den andra uppsättningen infogade jag 60 miljoner rader. Varaktighetsdata är inte förvånande:
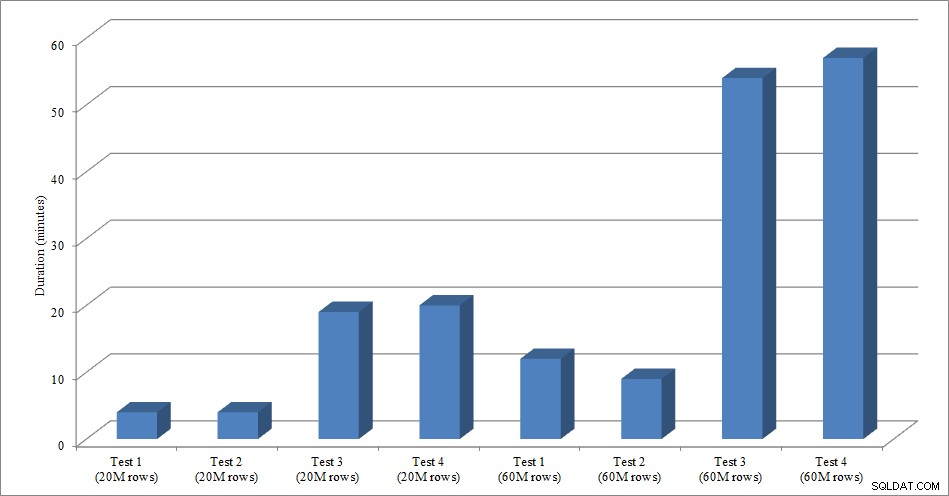
Dataladdningslängd
Att ladda data, utan de icke-klustrade indexen, är mycket snabbare än att ladda den med de icke-klustrade indexen som redan finns på plats. Vad jag tyckte var intressant är att för belastningen på 20 miljoner rader var den totala varaktigheten ungefär densamma mellan test 1 och test 2, men test 2 var snabbare när man laddade 60 miljoner rader. I vårt test var vår klustringsnyckel SalesOrderID, som är en identitet och därför en bra klustringsnyckel för vår belastning eftersom den är stigande. Om vi hade en klustringsnyckel som var en GUID istället, kan laddningstiden vara längre på grund av slumpmässiga infogningar och siddelningar (en annan variant som vi skulle kunna testa).
Härmar IO-data trenden i varaktighetsdata? Ja, med skillnaderna att indexen redan är på plats, eller inte, ännu mer överdrivna:
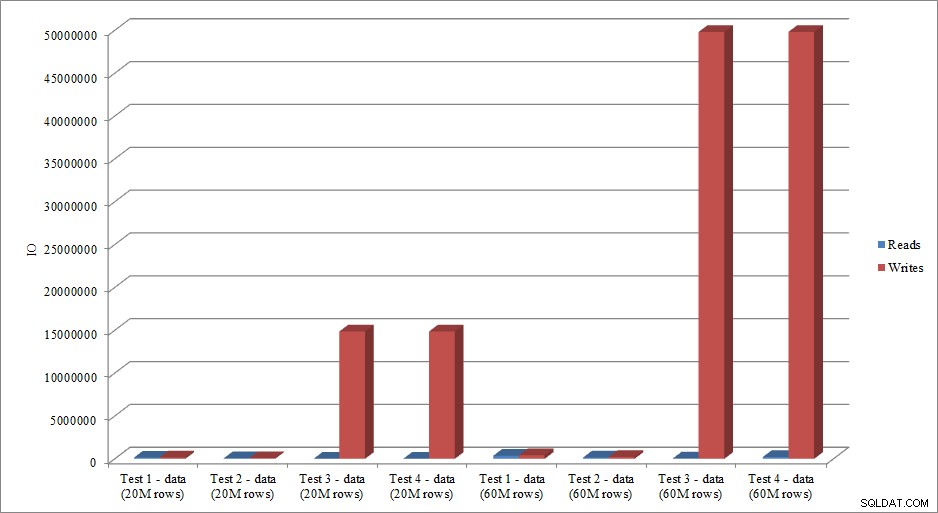
Dataladdning läser och skriver
Metoden som jag har presenterat här för prestandatestning, eller mätning av förändringar i prestanda baserat på modifieringar av kod, design, etc., är bara ett alternativ för att fånga baslinjeinformation. I vissa scenarier kan detta vara överdrivet. Om du har en fråga som du försöker ställa in, kan det ta längre tid att ställa in den här processen för att fånga data än att göra justeringar av frågan! Om du har gjort någon mängd frågejusteringar har du förmodligen för vana att fånga STATISTICS IO och STATISTICS TIME-data, tillsammans med frågeplanen, och sedan jämföra utdata när du gör ändringar. Jag har gjort detta i flera år, men jag upptäckte nyligen ett bättre sätt ... SQL Sentry Plan Explorer PRO. Faktum är att efter att jag slutfört alla belastningstester som jag beskrev ovan, gick jag igenom och körde om mina tester genom PE och fann att jag kunde fånga den information jag ville ha, utan att behöva ställa in mina datainsamlingstabeller.
Inom Plan Explorer PRO har du möjlighet att få den faktiska planen – PE kommer att köra frågan mot den valda instansen och databasen och returnera planen. Och med den får du alla andra fantastiska data som PE tillhandahåller (tidsstatistik, läsning och skrivning, IO för tabell), samt väntestatistiken, vilket är en trevlig fördel. Med vårt exempel började jag med det första testet – skapa högen, ladda data och sedan lägga till det klustrade indexet och icke-klustrade indexen – och körde sedan alternativet Get Actual Plan. När det var klart ändrade jag mitt skripttest 2, körde alternativet Get Actual Plan igen. Jag upprepade detta för det tredje och fjärde testet, och när jag var klar hade jag detta:
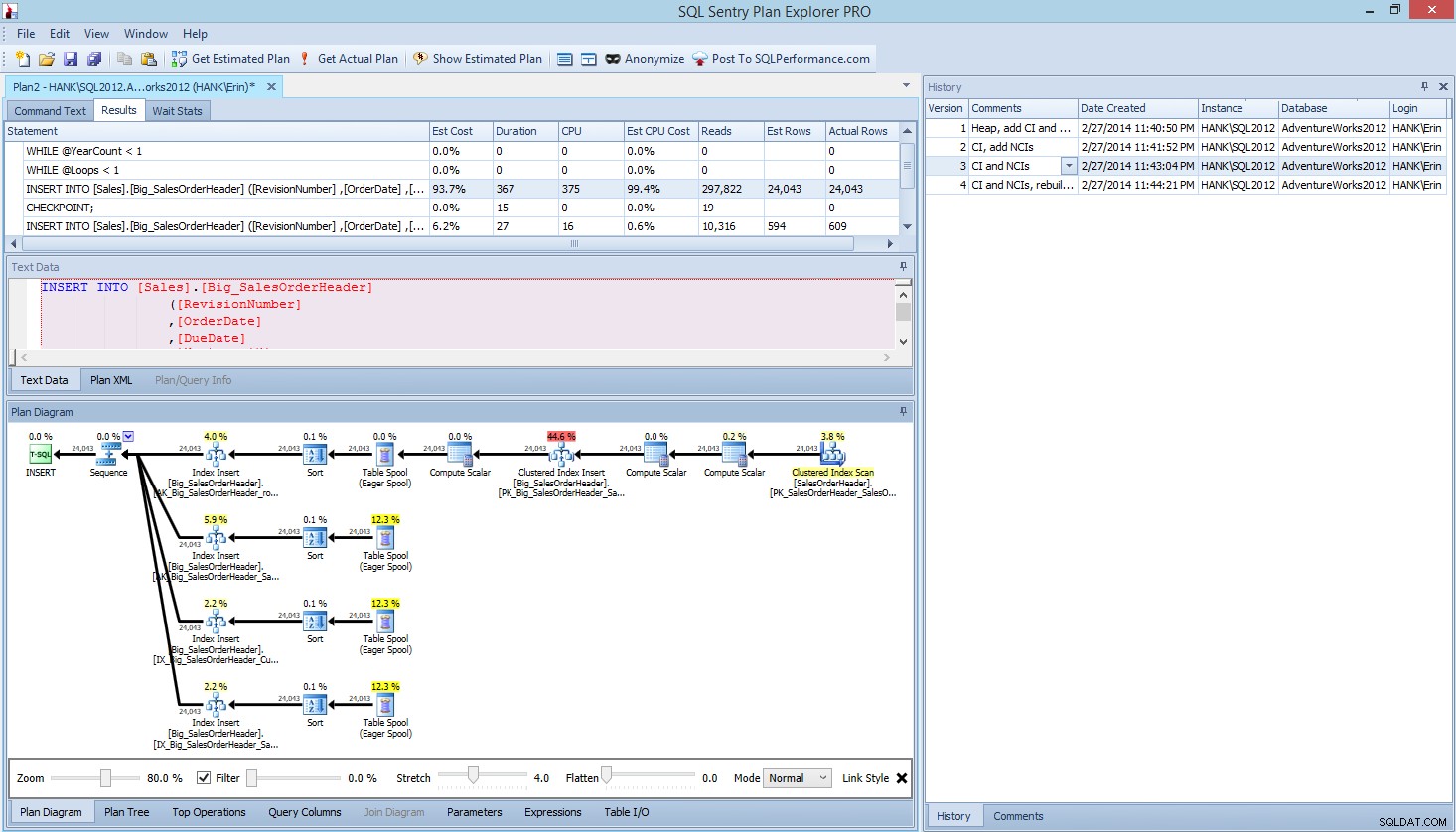
Planera Explorer PRO-vy efter att ha kört fyra tester
Lägger du märke till historikrutan på höger sida? Varje gång jag ändrade min kod och återskapade den faktiska planen, sparade den en ny uppsättning information. Jag har möjligheten att spara denna data som en .pesession-fil för att dela med en annan medlem i mitt team, eller gå tillbaka senare och bläddra igenom de olika testerna och borra i olika uttalanden inom partiet vid behov, titta på olika mätvärden, t.ex. som varaktighet, CPU och IO. I skärmdumpen ovan har jag markerat INFOGA från Test 3, och frågeplanen visar uppdateringarna för alla fyra icke-klustrade indexen.
Sammanfattning
Som med så många uppgifter i SQL Server, finns det många sätt att fånga och granska data när du kör prestandatester eller utför trimning. Ju mindre manuell ansträngning du behöver göra, desto bättre, eftersom det ger mer tid att faktiskt göra ändringar, förstå effekterna och sedan gå vidare till din nästa uppgift. Oavsett om du anpassar ett skript för att fånga data, eller låter ett tredjepartsverktyg göra det åt dig, är stegen jag beskrev fortfarande giltiga:
- Definiera vad du vill förbättra
- Omfattning dina tester
- Fastställ vilken data som kan användas för att mäta förbättringar
- Bestämma hur du ska samla in data
- Konfigurera en automatiserad metod, när det är möjligt, för testning och insamling
- Testa, utvärdera och upprepa vid behov
Lycka till med testet!