Benjamin Nevarez är en oberoende konsult baserad i Los Angeles, Kalifornien, som specialiserat sig på justering och optimering av SQL Server-frågor. Han är författare till "SQL Server 2014 Query Tuning &Optimization" och "Inside the SQL Server Query Optimizer" och medförfattare till "SQL Server 2012 Internals". Med mer än 20 års erfarenhet av relationsdatabaser har Benjamin också varit föredragshållare vid många SQL Server-konferenser, inklusive PASS Summit, SQL Server Connections och SQLBits. Benjamins blogg finns på https://www.benjaminnevarez.com och han kan också nås via e-post på admin på benjaminnevarez dot com och på twitter på @BenjaminNevarez.
Även om det mesta av informationen, bloggarna och dokumentationen om SQL Server 2014 har fokuserat på Hekaton och andra nya funktioner, har inte många detaljer lämnats om den nya kardinalitetskalkylatorn. För närvarande talar BOL endast indirekt om det i avsnittet Vad är nytt (databasmotor) och säger att SQL Server 2014 "inkluderar avsevärda förbättringar av komponenten som skapar och optimerar frågeplaner" och ALTER DATABASE uttalande visar hur man aktiverar eller inaktiverar dess beteende. Lyckligtvis kan vi få lite ytterligare information genom att läsa forskningsartikeln Testing Cardinality Estimation Models in SQL Server av Campbell Fraser et al. Även om fokus för uppsatsen är kvalitetssäkringsprocessen för den nya uppskattningsmodellen, erbjuder den också en grundläggande introduktion till den nya kardinalitetsskattaren och motiveringen till dess omdesign.
Så vad är en kardinalitetsuppskattare? En kardinalitetsuppskattare är komponenten i frågeprocessorn vars uppgift är att uppskatta antalet rader som returneras av relationsoperationer i en fråga. Denna information, tillsammans med en del annan data, används av frågeoptimeraren för att välja en effektiv exekveringsplan. Kardinalitetsuppskattning är i sig inexakt, eftersom det är en matematisk modell som bygger på statistisk information. Den bygger också på flera antaganden som, även om de inte är dokumenterade, har varit kända genom åren – några av dem inkluderar antaganden om enhetlighet, oberoende, inneslutning och inkludering. En kort beskrivning av dessa antaganden följer.
- Enhet . Används när fördelningen för ett attribut är okänd, till exempel inom intervallrader i ett histogramsteg eller när ett histogram inte är tillgängligt.
- Oberoende . Används när attributen i en relation är oberoende, såvida inte en korrelation mellan dem är känd.
- Inneslutning . Används när två attribut kan vara lika, antas de vara samma.
- Inkludering . Används när man jämför ett attribut med en konstant, det antas att det alltid finns en matchning.
Det är intressant att jag nyligen talade om några av begränsningarna i dessa antaganden vid mitt senaste föredrag på PASS-toppmötet, kallat Besegra begränsningarna för frågeoptimeraren. Ändå blev jag förvånad över att läsa i tidningen att författarna medger att dessa antaganden, enligt deras erfarenhet i praktiken, är "ofta felaktiga."
Den nuvarande kardinalitetskalkylatorn skrevs tillsammans med hela frågeprocessorn för SQL Server 7.0, som släpptes i december 1998. Uppenbarligen har denna komponent stått inför flera förändringar under flera år och flera versioner av SQL Server, inklusive korrigeringar, justeringar och tillägg till tillgodose kardinalitetsuppskattning för nya T-SQL-funktioner. Så du kanske tänker, varför byta ut en komponent som har använts framgångsrikt i cirka 15 år?
Varför en ny kardinalitetskalkylator
Uppsatsen förklarar några av anledningarna till omdesignen, inklusive:
- För att anpassa kardinalitetsuppskattaren till nya arbetsbelastningsmönster.
- Ändringar som gjorts i kardinalitetskalkylatorn under åren gjorde komponenten svår att "felsöka, förutsäga och förstå."
- Att försöka förbättra den nuvarande modellen var svårt med den nuvarande arkitekturen, så en ny design skapades, fokuserad på separationen av uppgifterna för (a) att bestämma hur en viss uppskattning ska beräknas och (b) att faktiskt utföra beräkningen .
Jag är inte säker på om mer information om den nya kardinalitetskalkylatorn kommer att publiceras av Microsoft. Det har trots allt inte publicerats så många detaljer om den gamla kardinalitetsskattaren på 15 år; till exempel hur någon specifik kardinalitetsuppskattning beräknas. Å andra sidan finns det nya utökade händelser som vi kan använda för att felsöka problem med kardinalitetsuppskattning, eller bara för att utforska hur det fungerar. Dessa händelser inkluderar query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors och query_rpc_set_cardinality .
Planera regressioner
Ett stort problem som kommer att tänka på med en sådan enorm förändring i frågeoptimeraren är planregressioner. Rädslan för planregressioner har ansetts vara det största hindret för förbättringar av frågeoptimerare. Regressioner är problem som introduceras efter att en korrigering har tillämpats på frågeoptimeraren och ibland hänvisas till som det klassiska "två fel gör ett rätt". Detta kan hända när två dåliga uppskattningar, till exempel en som överskattar ett värde och den andra som underskattar det, tar bort varandra, vilket lyckligtvis ger en bra uppskattning. Att korrigera endast ett av dessa värden kan nu leda till en dålig uppskattning som kan påverka valet av plan negativt och orsaka en regression.
För att undvika regressioner relaterade till den nya kardinalitetsuppskattaren tillhandahåller SQL Server ett sätt att aktivera eller inaktivera den, eftersom det beror på databaskompatibilitetsnivån. Detta kan ändras med ALTER DATABASE uttalande, som antytts tidigare. Att ställa in en databas till kompatibilitetsnivån 120 kommer att använda den nya kardinalitetsuppskattaren, medan en kompatibilitetsnivå mindre än 120 kommer att använda den gamla kardinalitetsuppskattaren. Dessutom, när du väl använder en specifik kardinalitetsuppskattare, finns det två spårningsflaggor du kan använda för att ändra till den andra. Även om jag för tillfället inte ser spårningsflaggorna dokumenterade någonstans, nämns de som en del av beskrivningen av query_optimizer_force_both_cardinality_estimation_behaviors utökat evenemang. Spårningsflagga 2312 kan användas för att aktivera den nya kardinalitetsuppskattaren, medan spårningsflagga 9481 kan användas för att inaktivera den. Du kan till och med använda spårningsflaggor för en specifik fråga med QUERYTRACEON tips (även om det ännu inte är dokumenterat om detta kommer att stödjas heller).
Exempel
Slutligen nämner tidningen också några testade scenarier som den överbefolkade primärnyckeln, enkel koppling eller problemet med stigande nyckel. Den visar också hur författarna experimenterade med flera scenarier (eller modellvariationer) och i vissa fall "slappnade av" några av antagandena som gjorts av kardinalitetsskattaren, till exempel när det gäller antagandet om oberoende, från fullständigt oberoende till fullständig korrelation. och något däremellan tills bra resultat hittades.
Även om det inte finns några detaljer på papperet bestämmer jag mig för att börja testa några av dessa scenarier för att försöka förstå hur den nya kardinalitetsuppskattaren fungerar. För nu kommer jag att visa dig exempel med antagande om oberoende och stigande nycklar. Jag testade också enhetlighetsantagandet men har hittills inte kunnat hitta någon skillnad vid uppskattning.
Låt oss börja med exemplet med antagande om oberoende. Låt oss först se det nuvarande beteendet. För det, se till att du använder den gamla kardinalitetskalkylatorn genom att köra följande uttalande i AdventureWorks2012-databasen:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Kör sedan:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Vi får uppskattningsvis 196 rekord som visas härnäst:

På liknande sätt kommer följande påstående att få en uppskattning av 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Om vi använder båda predikaten har vi följande fråga, som kommer att ha ett uppskattat antal rader på 1,93862 (avrundat uppåt till 2 rader om du använder SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Detta värde beräknas med antagande av totalt oberoende av båda predikaten, som använder formeln (196 * 194) / 19614.0 (där 19614 är det totala antalet rader i tabellen). Att använda en total korrelation bör ge oss en uppskattning av 194, eftersom alla poster med postnummer 91502 tillhör Burbank. Den nya kardinalitetsuppskattaren uppskattar ett värde som inte förutsätter totalt oberoende eller total korrelation. Ändra till den nya kardinalitetsuppskattaren med följande uttalande:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Att köra samma uttalande igen kommer att ge en uppskattning av 19,3931 rader, vilket du kan se är ett värde mellan antagande av totalt oberoende och total korrelation (avrundat uppåt till 19 rader i Plan Explorer). Formeln som används är selektiviteten för det mest selektiva filtret * SQRT(selektiviteten för det näst mest selektiva filtret) eller (194/19614.0) * SQRT(196/19614.0) * 19614 vilket ger 19.393:

Om du har aktiverat den nya kardinalitetsuppskattaren på databasnivå köp vill inaktivera den för en specifik fråga för att undvika en planregression, kan du använda spårningsflagga 9481 som förklarats tidigare:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Obs:QUERYTRACEON-frågetipset används för att tillämpa en spårningsflagga på frågenivå och för närvarande stöds den endast i ett begränsat antal scenarier. För mer information om QUERYTRACEON-frågetipset kan du titta på https://support.microsoft.com/kb/2801413.
Låt oss nu titta på det stigande nyckelproblemet, ett ämne som jag har förklarat mer i detalj i det här inlägget. Den traditionella rekommendationen från Microsoft för att åtgärda detta problem är att manuellt uppdatera statistik efter att ha laddat data, som förklaras här – vilket beskriver problemet på följande sätt:
Statistik över stigande eller fallande nyckelkolumner, som IDENTITY eller tidsstämpelkolumner i realtid, kan kräva mer frekventa statistikuppdateringar än vad frågeoptimeraren utför. Infoga operationer lägger till nya värden i stigande eller fallande kolumner. Antalet rader som lagts till kan vara för litet för att utlösa en statistikuppdatering. Om statistiken inte är uppdaterad och frågor väljs från de senast tillagda raderna, kommer den aktuella statistiken inte att ha kardinalitetsuppskattningar för dessa nya värden. Detta kan resultera i felaktiga uppskattningar av kardinalitet och långsam frågeprestanda. Till exempel kommer en fråga som väljer från de senaste försäljningsorderdatumen att ha felaktiga kardinalitetsuppskattningar om statistiken inte uppdateras för att inkludera kardinalitetsuppskattningar för de senaste försäljningsorderdatumen.
Rekommendationen i min artikel var att använda spårningsflaggor 2389 och 2390, som först publicerades av Ian Jose i hans artikel Ascending Keys and Auto Quick Corrected Statistics. Du kan läsa min artikel för en förklaring och exempel på hur man använder dessa spårningsflaggor för att undvika detta problem. Dessa spårningsflaggor fungerar fortfarande på SQL Server 2014 CTP2. Men ännu bättre, de behövs inte längre om du använder den nya kardinalitetskalkylatorn.
Använder samma exempel i mitt inlägg:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Infoga några data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Eftersom vi skapade ett index har vi ny statistik. Att köra följande fråga kommer att skapa en bra uppskattning av 35 rader:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Om vi infogar ny data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Du kan se uppskattningen med den gamla kardinalitetsuppskattaren som visas härnäst:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Eftersom det lilla antalet infogade poster inte var tillräckligt för att utlösa en automatisk uppdatering av statistikobjektet, känner det aktuella histogrammet inte till de nya poster som lagts till och frågeoptimeraren använder uppskattningsvis 1 rad. Alternativt kan du använda spårningsflaggor 2389 och 2390 för att få en bättre uppskattning. Men om du försöker samma fråga med den nya kardinalitetsuppskattaren får du följande uppskattning:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
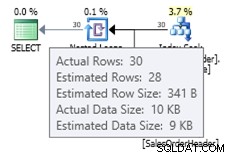
I det här fallet får vi en bättre uppskattning än den gamla kardinalitetsuppskattaren (eller så får vi samma uppskattning som att använda spårflaggor 2389 eller 2390). Det uppskattade värdet på 27,9631 (återigen, avrundat till 28 av Plan Explorer) beräknas med hjälp av densitetsinformationen för statistikobjektet multiplicerat med antalet rader i tabellen; det vill säga 0,0008992806 * 31095. Densitetsvärdet kan erhållas med:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Slutligen, kom ihåg att ingenting som nämns i den här artikeln är dokumenterat, och detta är beteendet jag har observerat hittills i SQL Server 2014 CTP2. Allt av detta kan ändras i en senare CTP- eller RTM-version av produkten.