Det är sedan länge etablerat att tabellvariabler med ett stort antal rader kan vara problematiska, eftersom optimeraren alltid ser dem som att de har en rad. Utan en omkompilering efter att tabellvariabeln har fyllts i (sedan dess att den är tom), finns det ingen kardinalitet för tabellen, och automatiska omkompileringar sker inte eftersom tabellvariabler inte ens är föremål för en omkompileringströskel. Planer är därför baserade på en tabellkardinalitet på noll, inte en, men minimivärdet ökas till ett som Paul White (@SQL_Kiwi) beskriver i detta dba.stackexchange-svar.
Sättet som vi vanligtvis kan komma runt det här problemet är att lägga till OPTION (RECOMPILE) till frågan som refererar till tabellvariabeln, vilket tvingar optimeraren att inspektera tabellvariabelns kardinalitet efter att den har fyllts i. För att undvika behovet av att manuellt ändra varje fråga för att lägga till en explicit omkompileringstips, har en ny spårningsflagga (2453) introducerats i SQL Server 2012 Service Pack 2 och SQL Server 2014 Kumulativ uppdatering #3:
- KB #2952444 :FIX:Dålig prestanda när du använder tabellvariabler i SQL Server 2012 eller SQL Server 2014
När spårningsflaggan 2453 är aktiv kan optimeraren erhålla en korrekt bild av tabellkardinalitet efter att tabellvariabeln har skapats. Detta kan vara A Good Thing™ för många frågor, men förmodligen inte alla, och du bör vara medveten om hur det fungerar annorlunda än OPTION (RECOMPILE) . Mest anmärkningsvärt är att parameterinbäddningsoptimeringen Paul White talar om i det här inlägget sker under OPTION (RECOMPILE) , men inte under denna nya spårningsflagga.
Ett enkelt test
Mitt första test bestod av att bara fylla i en tabellvariabel och välja från den; detta gav det alltför välbekanta uppskattade antalet rader på 1. Här är testet jag körde (och jag lade till omkompileringstipset för att jämföra):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Genom att använda SQL Sentry Plan Explorer kan vi se att den grafiska planen för båda frågorna i det här fallet är identisk, förmodligen åtminstone delvis eftersom detta bokstavligen är en trivial plan:

Grafisk plan för en trivial indexskanning mot @t
Uppskattningarna är dock inte desamma. Även om spårningsflaggan är aktiverad får vi fortfarande en uppskattning av 1 som kommer ut från indexskanningen om vi inte använder omkompileringstipset:
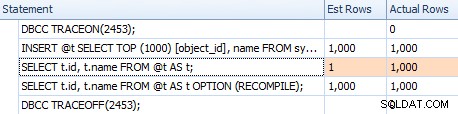
Jämföra uppskattningar för en trivial plan i utdragsrutnätet
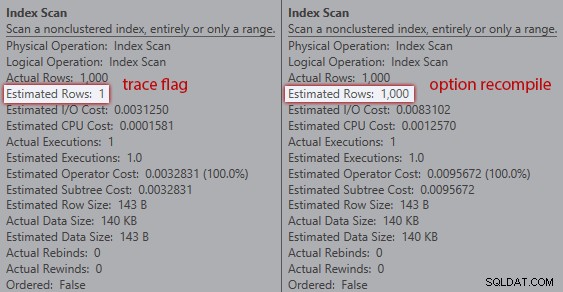
Jämföra uppskattningar mellan spårningsflagga (vänster) och omkompilera (höger)
Om du någonsin har varit runt mig personligen kan du förmodligen föreställa dig ansiktet jag gjorde vid det här laget. Jag trodde säkert att antingen KB-artikeln angav fel spårningsflagganummer eller att jag behövde någon annan inställning aktiverad för att den verkligen skulle vara aktiv.
Benjamin Nevarez (@BenjaminNevarez) påpekade snabbt för mig att jag behövde titta närmare på "Bugar som är fixade i SQL Server 2012 Service Pack 2" KB-artikeln. Även om de har skymt texten bakom en dold punkt under Höjdpunkter> Relationell motor, gör fixlistans artikel ett något bättre jobb med att beskriva spårningsflaggans beteende än den ursprungliga artikeln (betoning min):
Om en tabellvariabel förenas med andra tabeller i SQL Server kan det resultera i långsam prestanda på grund av ineffektivt val av frågeplan eftersom SQL Server inte stöder statistik eller spårar antal rader i en tabellvariabel när en frågeplan kompileras.Så det framgår av den här beskrivningen att spårningsflaggan endast är avsedd att lösa problemet när tabellvariabeln deltar i en join. (Varför den skillnaden inte görs i den ursprungliga artikeln har jag ingen aning om.) Men det fungerar också om vi får frågorna att göra lite mer arbete – ovanstående fråga anses trivial av optimeraren, och spårningsflaggan gör det inte ens försöka göra något i så fall. Men det kommer att slå in om kostnadsbaserad optimering utförs, även utan anslutning; spårflaggan har helt enkelt ingen effekt på triviala planer. Här är ett exempel på en icke-trivial plan som inte involverar en join:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Denna plan är inte längre trivial; optimering markeras som full. Huvuddelen av kostnaden flyttas till en sorteringsoperatör:
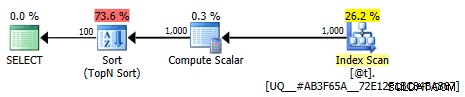
Mindre trivial grafisk plan
Och uppskattningarna står i linje för båda frågorna (jag sparar verktygstipsen den här gången, men jag kan försäkra dig om att de är desamma):

Uttalsrutnät för mindre triviala planer med och utan omkompileringstipset
Så det verkar som att KB-artikeln inte är exakt korrekt – jag kunde tvinga fram det beteende som förväntades av spårflaggan utan att införa en join. Men jag vill testa det med en join också.
Ett bättre test
Låt oss ta det här enkla exemplet, med och utan spårflaggan:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Utan spårningsflaggan uppskattar optimeraren att en rad kommer från indexskanningen mot tabellvariabeln. Men med spårningsflaggan aktiverad får den de 1 000 raderna slå på:
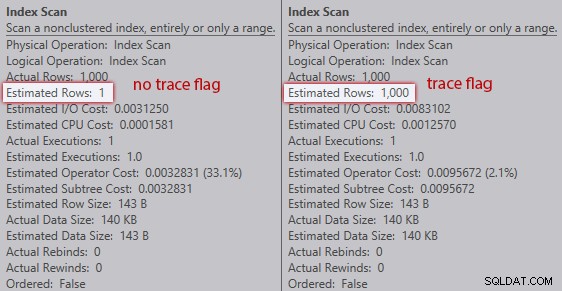
Jämförelse av indexsökningsuppskattningar (ingen spårflagga till vänster, spårningsflagga till höger)
Skillnaderna slutar inte där. Om vi tar en närmare titt kan vi se en mängd olika beslut som optimeraren har fattat, alla härrörande från dessa bättre uppskattningar:
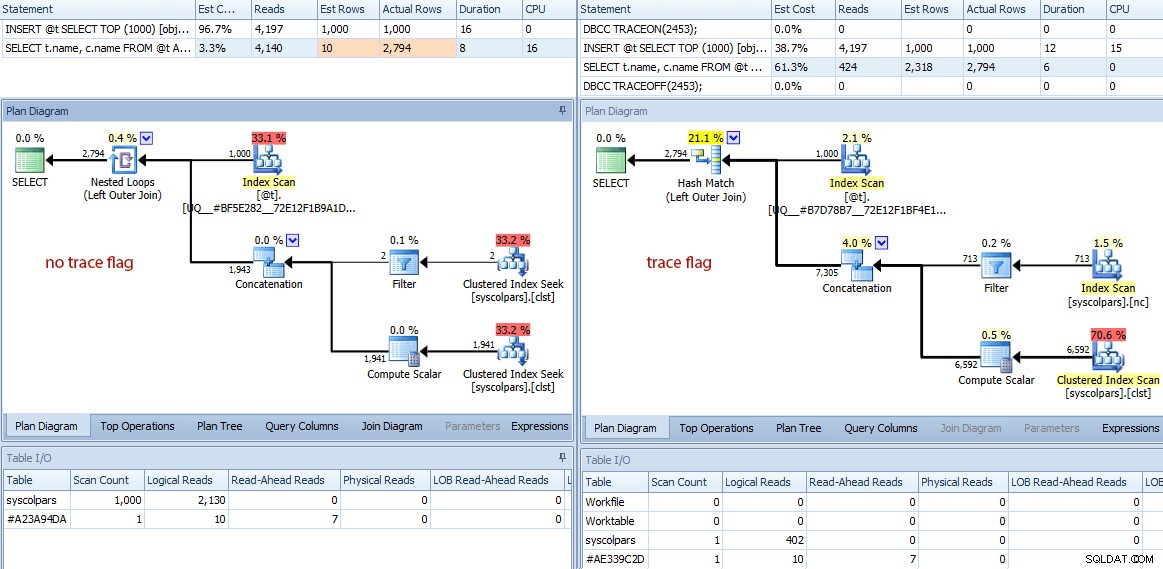
Jämförelse av planer (ingen spårflagga till vänster, spårningsflagga till höger)
En snabb sammanfattning av skillnaderna:
- Frågan utan spårningsflaggan har utfört 4 140 läsoperationer, medan frågan med den förbättrade uppskattningen endast har utfört 424 (ungefär 90 % minskning).
- Optimeraren uppskattade att hela frågan skulle returnera 10 rader utan spårningsflaggan, och mycket mer exakta 2 318 rader när man använder spårningsflaggan.
- Utan spårningsflaggan valde optimeraren att utföra en kapslad loop-koppling (vilket är vettigt när en av ingångarna uppskattas vara mycket liten). Detta ledde till att sammanlänkningsoperatorn och båda indexsökningarna kördes 1 000 gånger, i motsats till hashmatchningen som valts under spårningsflaggan, där sammanlänkningsoperatorn och båda skanningarna endast körs en gång.
- Tabell I/O-fliken visar också 1 000 skanningar (avståndssökningar förklädda som indexsökningar) och ett mycket högre logiskt läsantal mot
syscolpars(systemtabellen bakomsys.all_columns). - Även om varaktigheten inte påverkades nämnvärt (24 millisekunder mot 18 millisekunder), kan du förmodligen föreställa dig vilken typ av inverkan dessa andra skillnader kan ha på en mer seriös fråga.
- Om vi byter diagrammet till uppskattade kostnader kan vi se hur mycket olika tabellvariabeln kan lura optimeraren utan spårningsflaggan:
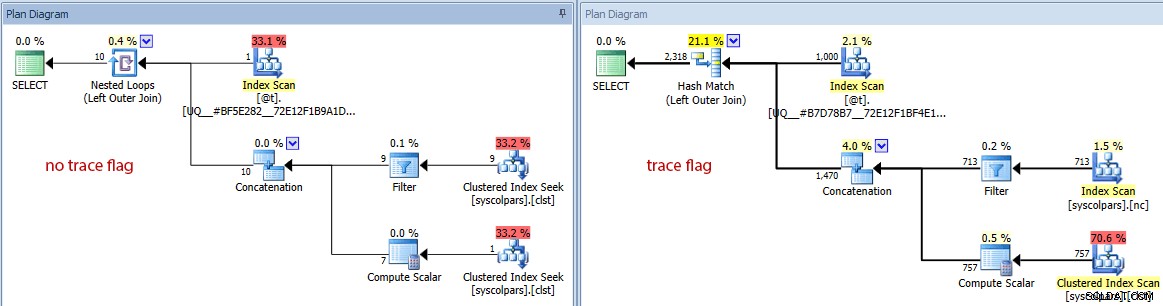
Jämföra beräknat antal rader (ingen spårflagga till vänster, spåra flagga till höger)
Det är tydligt och inte chockerande att optimeraren gör ett bättre jobb med att välja rätt plan när den har en korrekt bild av kardinaliteten som är involverad. Men till vilken kostnad?
Omkompilerar och overhead
När vi använder OPTION (RECOMPILE) med ovanstående batch, utan spårningsflaggan aktiverad, får vi följande plan – som är ganska identisk med planen med spårningsflaggan (den enda märkbara skillnaden är att de beräknade raderna är 2 316 istället för 2 318):
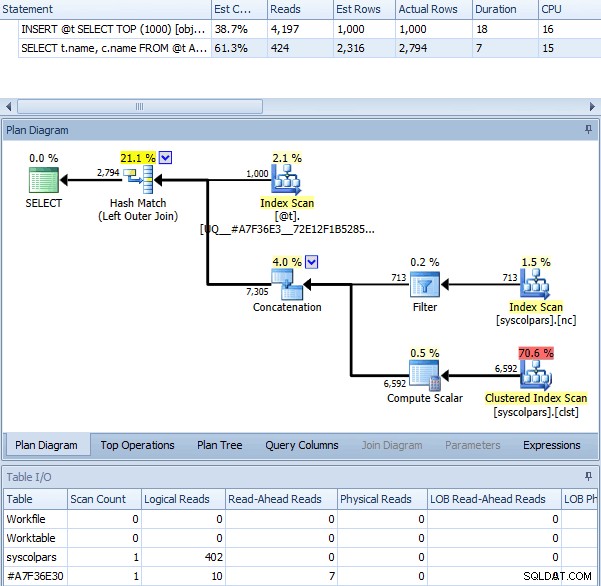
Samma fråga med OPTION (OMKOMPILERA)
Så detta kan få dig att tro att spårningsflaggan ger liknande resultat genom att utlösa en omkompilering åt dig varje gång. Vi kan undersöka detta med en mycket enkel session med utökade evenemang:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Jag körde följande uppsättning batcher, som körde 20 frågor utan (a) inget omkompileringsalternativ eller spårningsflagga, (b) omkompileringsalternativet och (c) en spårningsflagga på sessionsnivå.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Sedan tittade jag på händelsedata:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
Resultaten visar att inga omkompileringar skedde under standardfrågan, satsen som hänvisar till tabellvariabeln kompilerades om en gång under spårningsflaggan och, som du kan förvänta dig, varje gång med RECOMPILE alternativ:
| sql_text | recompile_count |
|---|---|
| /* kompilera om */ DECLARE @t TABELL (i INT … | 20 |
| /* spårningsflagga */ DBCC TRACEON(2453); FÖRKLARA @t … | 1 |
Resultat av fråga mot XEvents-data
Därefter stängde jag av sessionen Extended Events och ändrade sedan batchen för att mäta i skala. Koden mäter i huvudsak 1 000 iterationer av att skapa och fylla i en tabellvariabel, och sedan väljer dess resultat till en #temp-tabell (ett sätt att undertrycka utdata från så många engångsresultatuppsättningar), med var och en av de tre metoderna.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Jag körde denna batch 10 gånger och tog medelvärden; de var:
| Metod | Genomsnittlig varaktighet (millisekunder) |
|---|---|
| Standard | 23 148,4 |
| Kompilera om | 29 959,3 |
| Spårningsflagga | 22 100,7 |
Genomsnittlig varaktighet för 1 000 iterationer
I det här fallet var det mycket långsammare att få rätt uppskattningar varje gång med hjälp av omkompileringstipset än standardbeteendet, men att använda spårningsflaggan var något snabbare. Detta är vettigt eftersom – även om båda metoderna korrigerar standardbeteendet att använda en falsk uppskattning (och få en dålig plan som ett resultat), tar omkompileringar resurser och, när de inte eller kan ge en mer effektiv plan, tenderar de att bidra till den totala batchvaraktigheten.
Det verkar okomplicerat, men vänta...
Ovanstående test är något – och avsiktligt – felaktigt. Vi infogar samma antal rader (1 000) i tabellvariabeln varje gång . Vad händer om den initiala populationen av tabellvariabeln varierar för olika batcher? Visst kommer vi att se omkompileringar då, även under spårflaggan, eller hur? Dags för ett nytt prov. Låt oss ställa in en något annorlunda session för utökade händelser, bara med ett annat målfilnamn (för att inte blanda ihop data från den andra sessionen):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Låt oss nu inspektera denna batch och ställa in radantal för varje iteration som är väsentligt olika. Vi kör detta tre gånger och tar bort lämpliga kommentarer så att vi har en batch utan spårningsflagga eller explicit omkompilering, en batch med spårningsflaggan och en batch med OPTION (RECOMPILE) (att ha en korrekt kommentar i början gör dessa partier lättare att identifiera på platser som Extended Events output):
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
Jag körde dessa batcher i Management Studio, öppnade dem individuellt i Plan Explorer och filtrerade satsträdet på bara SELECT fråga. Vi kan se olika beteende i de tre satserna genom att titta på beräknade och faktiska rader:

Jämförelse av tre batcher, tittar på uppskattade och faktiska rader
I rutnätet längst till höger kan du tydligt se var omkompileringar inte skedde under spårningsflaggan
Vi kan kontrollera XEvents-data för att se vad som faktiskt hände med omkompileringar:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Resultat:
| sql_text | recompile_count |
|---|---|
| /* kompilera om */ DECLARE @i INT =1; MEDAN … | 6 |
| /* spårningsflagga */ DECLARE @i INT =1; MEDAN … | 4 |
Resultat av fråga mot XEvents-data
Mycket intressant! Under spårningsflaggan *ser* vi omkompileringar, men bara när runtime-parametervärdet har varierat avsevärt från det cachade värdet. När körtidsvärdet är annorlunda, men inte särskilt mycket, får vi ingen omkompilering, och samma uppskattningar används. Så det är tydligt att spårningsflaggan introducerar en omkompileringströskel för tabellvariabler, och jag har bekräftat (genom ett separat test) att denna använder samma algoritm som den som beskrivs för #temp-tabeller i denna "urgamla" men fortfarande relevanta uppsats. Jag kommer att bevisa detta i ett uppföljande inlägg.
Återigen kommer vi att testa prestanda, köra batchen 1 000 gånger (med Extended Event-sessionen avstängd) och mäta varaktigheten:
| Metod | Genomsnittlig varaktighet (millisekunder) |
|---|---|
| Standard | 101 285,4 |
| Kompilera om | 111 423,3 |
| Spårningsflagga | 110 318,2 |
Genomsnittlig varaktighet för 1 000 iterationer
I det här specifika scenariot förlorar vi cirka 10 % av prestandan genom att tvinga fram en omkompilering varje gång eller genom att använda en spårningsflagga. Inte riktigt säker på hur deltat fördelades:Var planerna baserade på bättre uppskattningar inte väsentligt bättre? Omkompileringar kompenserade eventuella prestandavinster med så mycket ? Jag vill inte lägga för mycket tid på det här, och det var ett trivialt exempel, men det visar dig att det kan vara en oförutsägbar affär att leka med hur optimeraren fungerar. Ibland kan du ha det bättre med standardbeteendet kardinalitet =1, med vetskapen om att du aldrig kommer att orsaka några onödiga omkompileringar. Där spårningsflaggan kan vara mycket meningsfull är om du har frågor där du upprepade gånger fyller i tabellvariabler med samma uppsättning data (t.ex. en postnummeruppslagstabell) eller om du alltid använder 50 eller 1 000 rader (t.ex. fyller i en tabellvariabel för användning i paginering). I vilket fall som helst bör du definitivt testa vilken inverkan detta har på varje arbetsbelastning där du planerar att införa spårningsflaggan eller explicita omkompileringar.
TVP och tabelltyper
Jag var också nyfiken på hur detta skulle påverka tabelltyper och om vi skulle se några förbättringar i kardinalitet för TVP, där samma symptom finns. Så jag skapade en enkel tabelltyp som efterliknar tabellvariabeln som används hittills:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Sedan tog jag ovanstående batch och ersatte helt enkelt DECLARE @t TABLE(id INT PRIMARY KEY); med DECLARE @t dbo.t; – allt annat förblev exakt detsamma. Jag körde samma tre omgångar, och här är vad jag såg:

Jämföra uppskattningar och faktiska värden mellan standardbeteende, alternativkompilering och spårningsflagga 2453
Så ja, det verkar som att spårningsflaggan fungerar på exakt samma sätt med TVP:er – omkompilering genererar nya uppskattningar för optimeraren när radantalet överstiger omkompileringströskeln och hoppas över när radantalet är "tillräckligt nära."
För-, nackdelar och varningar
En fördel med spårningsflaggan är att du kan undvika en del kompilerar om och fortfarande ser tabellkardinalitet – så länge du förväntar dig att antalet rader i tabellvariabeln är stabilt, eller inte observerar betydande planavvikelser på grund av varierande kardinalitet. En annan är att du kan aktivera det globalt eller på sessionsnivå och inte behöver introducera omkompileringstips för alla dina frågor. Och slutligen, åtminstone i fallet där tabellvariabelns kardinalitet var stabil, ledde korrekta uppskattningar till bättre prestanda än standarden, och även bättre prestanda än att använda omkompileringsalternativet – alla dessa sammanställningar kan verkligen läggas ihop.
Det finns vissa nackdelar också såklart. En som jag nämnde ovan är den jämfört med OPTION (RECOMPILE) du går miste om vissa optimeringar, såsom parameterinbäddning. En annan är att spårningsflaggan inte kommer att ha den inverkan du förväntar dig på triviala planer. Och en jag upptäckte på vägen är att använda QUERYTRACEON ledtråd för att genomdriva spårningsflaggan på frågenivå fungerar inte – så vitt jag kan se måste spårningsflaggan vara på plats när tabellvariabeln eller TVP skapas och/eller fylls i för att optimeraren ska se kardinalitet ovan 1.
Tänk på att att köra spårningsflaggan globalt introducerar möjligheten till frågeplansregression till alla frågor som involverar en tabellvariabel (vilket är anledningen till att den här funktionen introducerades under en spårningsflagga i första hand), så se till att testa hela din arbetsbelastning oavsett hur du använder spårflaggan. Dessutom, när du testar detta beteende, vänligen gör det i en användardatabas; några av de optimeringar och förenklingar som du normalt förväntar dig inträffar helt enkelt inte när kontexten är inställd på tempdb, så alla beteenden du observerar där kanske inte förblir konsekventa när du flyttar koden och inställningarna till en användardatabas.
Slutsats
Om du använder tabellvariabler eller TVP:er med ett stort men relativt konsekvent antal rader, kan du tycka att det är fördelaktigt att aktivera denna spårningsflagga för vissa partier eller procedurer för att få korrekt tabellkardinalitet utan att manuellt tvinga fram en omkompilering av enskilda frågor. Du kan också använda spårningsflaggan på instansnivå, vilket kommer att påverka alla frågor. Men som alla förändringar måste du i båda fallen vara noggrann med att testa prestandan för hela din arbetsbelastning, se till att explicit se efter eventuella regressioner och se till att du vill ha spårningsflaggans beteende eftersom du kan lita på stabiliteten hos din tabellvariabel radräkningar.
Jag är glad att se spårningsflaggan läggas till i SQL Server 2014, men det skulle vara bättre om det bara blev standardbeteendet. Inte för att det finns någon betydande fördel med att använda stora tabellvariabler framför stora #temp-tabeller, men det skulle vara trevligt att se mer paritet mellan dessa två temporära strukturtyper som skulle kunna dikteras på en högre nivå. Ju mer paritet vi har, desto mindre behöver folk fundera över vilken de ska använda (eller åtminstone ha färre kriterier att ta hänsyn till när de väljer). Martin Smith har en bra Q &A över på dba.stackexchange som förmodligen nu ska uppdateras:Vad är skillnaden mellan en temporär tabell och en tabellvariabel i SQL Server?
Viktig anmärkning
Om du ska installera SQL Server 2012 Service Pack 2 (oavsett om det är för att använda denna spårningsflagga eller inte), se även mitt inlägg om en regression i SQL Server 2012 och 2014 som kan – i sällsynta fall – introducera potentiell dataförlust eller korruption under ombyggnader av onlineindex. Det finns kumulativa uppdateringar tillgängliga för SQL Server 2012 SP1 och SP2 och även för SQL Server 2014. Det kommer inte att finnas någon fix för 2012 RTM-grenen.
Ytterligare testning
Jag har andra saker på min lista att testa. För det första skulle jag vilja se om denna spårningsflagga har någon effekt på In-Memory-tabelltyper i SQL Server 2014. Jag kommer också att bevisa bortom allt tvivel att spårningsflagga 2453 använder samma omkompileringströskel för tabeller. variabler och TVPs som det gör för #temp-tabeller.