Läst engagerad är den näst svagaste av de fyra isoleringsnivåerna som definieras av SQL-standarden. Ändå är det standardisoleringsnivån för många databasmotorer, inklusive SQL Server. Det här inlägget i en serie om isoleringsnivåer och ACID-egenskaperna för transaktioner tittar på de logiska och fysiska garantierna som faktiskt tillhandahålls av läskommitterad isolering.
Logiska garantier
SQL-standarden kräver att en transaktion som körs under läskommitterad isolering endast läser committed data. Den uttrycker detta krav genom att förbjuda samtidighetsfenomenet som kallas för smutsig läsning. En smutsig läsning inträffar när en transaktion läser data som har skrivits av en annan transaktion, innan den andra transaktionen slutförs. Ett annat sätt att uttrycka detta på är att säga att en smutsig läsning inträffar när en transaktion läser oengagerad data.
Standarden nämner också att en transaktion som körs vid läskommitterad isolering kan stöta på samtidighetsfenomen som kallas icke-repeterbara läsningar och fantomer . Även om många böcker förklarar dessa fenomen i termer av att en transaktion kan se ändrade eller nya dataobjekt om data senare läses om, kan denna förklaring förstärka missuppfattningen att samtidighetsfenomen endast kan uppstå i en explicit transaktion som innehåller flera uttalanden. Så är det inte. Ett enskilt uttalande utan en explicit transaktion är lika sårbar för de icke-repeterbara läs- och fantomfenomenen, som vi kommer att se inom kort.
Det är i stort sett allt standarden har att säga om ämnet läs engagerad isolering. Vid första anblicken verkar läsning av enbart engagerad data vara en ganska bra garanti för ett förnuftigt beteende, men som alltid finns djävulen i detaljen. Så fort du börjar leta efter potentiella kryphål i den här definitionen blir det bara för lätt att hitta tillfällen där våra lästa transaktioner kanske inte ger de resultat vi kan förvänta oss. Återigen kommer vi att diskutera dessa mer i detalj om ett ögonblick eller två.
Olika fysiska implementeringar
Det finns åtminstone två saker som betyder att det observerade beteendet för den läskommitterade isoleringsnivån kan vara ganska olika på olika databasmotorer. För det första, inte SQL-standardens krav på att endast läsa engagerad data betyda nödvändigtvis att den registrerade data som läses av en transaktion kommer att vara den senaste engagerad data.
En databasmotor tillåts läsa en committerad version av en rad från någon tidpunkt som helst i det förflutna , och fortfarande följa SQL-standarddefinitionen. Flera populära databasprodukter implementerar läsbetingad isolering på detta sätt. Frågeresultat som erhållits under den här implementeringen av läsbetrodd isolering kan vara godtyckligt föråldrade , jämfört med det aktuella tillståndet för databasen. Vi kommer att ta upp detta ämne eftersom det gäller SQL Server i nästa inlägg i serien.
Det andra jag vill uppmärksamma dig på är att SQL-standarddefinitionen inte gör det förhindra att en viss implementering tillhandahåller ytterligare skydd för samtidighetseffekter utöver att förhindra smutsiga läsningar . Standarden specificerar bara att smutsavläsning inte är tillåten, den kräver inte att andra samtidighetsfenomen måste tillåtas vid varje given isoleringsnivå.
För att vara tydlig med denna andra punkt kan en standardkompatibel databasmotor implementera alla isoleringsnivåer med serialiserbar beteende om den så önskar. Vissa stora kommersiella databasmotorer tillhandahåller också en implementering av läs-committed som går långt utöver att bara förhindra smutsiga läsningar (även om ingen går så långt som att tillhandahålla fullständig isolering i ACID ordets mening).
Utöver det, för flera populära produkter, läs engagerad isolering är lägst isoleringsnivå tillgänglig; deras implementeringar av läs oengagerad isolering är exakt samma som läst begått. Detta tillåts av standarden, men den här typen av skillnader lägger till komplexitet till den redan svåra uppgiften att migrera kod från en plattform till en annan. När man talar om beteendet på en isoleringsnivå är det vanligtvis viktigt att specificera den specifika plattformen också.
Så vitt jag vet är SQL Server unik bland de stora kommersiella databasmotorerna genom att tillhandahålla två implementeringar av den läskommitterade isoleringsnivån, var och en med mycket olika fysiska beteenden. Det här inlägget täcker det första av dessa, låsning läs engagerad.
SQL Server Locking Read Committed
Om databasalternativet READ_COMMITTED_SNAPSHOT är OFF , SQL Server använder en låsning implementering av den läskommitterade isoleringsnivån, där delade lås används för att förhindra att en samtidig transaktion samtidigt modifierar data, eftersom modifiering skulle kräva ett exklusivt lås, som inte är kompatibelt med det delade låset.
Den viktigaste skillnaden mellan att SQL Server låser läs committed och låsning av repeterbar läsning (som också tar delade lås vid läsning av data) är att läs committed släpper det delade låset så snart som möjligt , medan repeterbar läsning håller dessa lås till slutet av den omslutande transaktionen.
När låsning av läs committed får lås med radgranularitet, släpps det delade låset som tas på en rad när ett delat lås tas på nästa rad . Vid granularitet på sidan släpps det delade sidlåset när den första raden på nästa sida läses, och så vidare. Såvida inte ett lås-granularitetstips tillhandahålls med frågan, bestämmer databasmotorn vilken granularitetsnivå som ska börja med. Observera att granularitetstips endast behandlas som förslag av motorn, ett mindre granulärt lås än vad som begärts kan fortfarande tas initialt. Lås kan också eskaleras under körning från rad- eller sidnivå till partitions- eller tabellnivå beroende på systemkonfiguration.
Det viktiga här är att delade lås vanligtvis bara hålls under mycket kort tid medan uttalandet körs. För att uttryckligen ta itu med en vanlig missuppfattning, gör det inte låsning av läs committed håll delade lås till slutet av uttalandet.
Låsning av engagerade läsbeteenden
De kortsiktiga delade låsen som används av SQL Server-låsningsimplementeringen av läs-committed ger väldigt få av de garantier som vanligtvis förväntas av en databastransaktion av T-SQL-programmerare. I synnerhet ett uttalande som körs under låsning läs begått isolering:
- Kan stöta på samma rad flera gånger;
- Kan missa vissa rader helt; och
- Gör det inte ge en punkt-i-tidsvy av uppgifterna
Den listan kan tyckas mer som en beskrivning av de konstiga beteenden du kan associera mer med användningen av NOLOCK tips, men alla dessa saker kan verkligen hända när man använder låsning av läs-engagerad isolering.
Exempel
Tänk på den enkla uppgiften att räkna raderna i en tabell, med hjälp av den uppenbara ensatsfrågan. Under låsning av läs engagerad isolering med radlåsningsgranularitet kommer vår fråga att ta ett delat lås på den första raden, läsa det, släppa det delade låset, gå vidare till nästa rad, och så vidare tills den når slutet av strukturen läser. För det här exemplets skull, anta att vår fråga läser ett index b-träd i stigande nyckelordning (även om den lika gärna kan använda en fallande ordning eller någon annan strategi).
Eftersom endast en enda rad är aktielåst vid varje given tidpunkt, är det helt klart möjligt för samtidiga transaktioner att modifiera de olåsta raderna i indexet som vår sökning korsar. Om dessa samtidiga ändringar ändrar indexnyckelvärden kommer de att få rader att flytta runt inom indexstrukturen. Med den möjligheten i åtanke illustrerar diagrammet nedan två problematiska scenarier som kan uppstå:
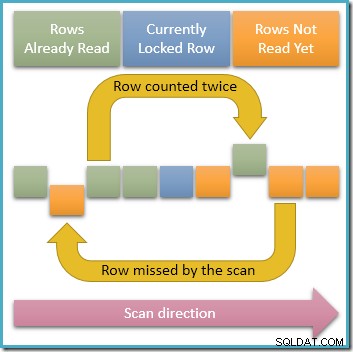
Den översta pilen visar en rad som vi redan har räknat med dess indexnyckel modifierad samtidigt så att raden flyttas före den aktuella skanningspositionen i indexet, vilket betyder att raden kommer att räknas två gånger . Den andra pilen visar en rad som vår skanning inte har stött på ännu flyttar sig bakom skanningspositionen, vilket betyder att raden inte räknas överhuvudtaget.
Inte en punkt-i-tidsvy
Föregående avsnitt visade hur låsning av läs committed kan missa data helt, eller räkna samma objekt flera gånger (mer än två gånger, om vi har otur). Den tredje punkten i listan över oväntade beteenden angav att låsning av begångna läsningar inte heller ger en punkt-i-tidsvy av data.
Resonemanget bakom det uttalandet borde nu vara lätt att se. Vår räknefråga kunde till exempel enkelt läsa data som infogades av samtidiga transaktioner efter att vår fråga började köras. På samma sätt kan data som vår fråga ser modifieras av samtidig aktivitet efter att vår fråga startar och innan den slutförs. Slutligen kan data vi har läst och räknat raderas av en samtidig transaktion innan vår förfrågan slutförs.
Uppenbarligen motsvarar data som ses av ett uttalande eller transaktion som körs under låsande läs-beslutad isolering inget enskilt tillstånd av databasen vid en viss tidpunkt . De data vi möter kan mycket väl komma från en mängd olika tidpunkter, med den enda gemensamma faktorn är att varje objekt representerade det senaste säkrade värdet av den datan vid den tidpunkt då den lästes (även om det mycket väl kan ha förändrats eller försvunnit sedan).
Hur allvarliga är dessa problem?
Allt detta kan tyckas vara ett ganska ulligt tillstånd om du är van vid att tänka på dina ensatsförfrågningar och explicita transaktioner som logiskt exekverade omedelbart, eller som att de körs mot en enda bestämd tidpunktstillstånd i databasen när du använder standard isoleringsnivå för SQL Server. Det passar verkligen inte bra med begreppet isolering i SYRA bemärkelse.
Med tanke på den uppenbara svagheten i garantierna som tillhandahålls av låsning av läs-beslutad isolering, kan du börja undra hur några av din produktion T-SQL-kod har någonsin fungerat korrekt! Naturligtvis kan vi acceptera att användning av en isoleringsnivå under serialiserbar innebär att vi avstår från fullständig ACID-transaktionsisolering i utbyte mot andra potentiella fördelar, men hur allvarliga kan vi förvänta oss att dessa problem ska vara i praktiken?
Saknade och dubbelräknade rader
Dessa två första problem är i huvudsak beroende av samtidig aktivitet som ändrar nycklar i en indexstruktur som vi för närvarande skannar. Observera att skanning här inkluderar den partiella avsökningsdelen av en indexsökning , såväl som den välbekanta obegränsade index- eller tabellskanningen.
Om vi (intervall) skannar en indexstruktur vars nycklar vanligtvis inte modifieras av någon samtidig aktivitet, borde dessa två första frågor inte vara något praktiskt problem. Det är dock svårt att vara säker på detta, eftersom frågeplaner kan ändras till att använda en annan åtkomstmetod, och det nya sökta indexet kan innehålla flyktiga nycklar.
Vi måste också komma ihåg att många produktionsfrågor egentligen bara behöver en ungefärlig eller bästa möjliga svar på vissa typer av frågor i alla fall. Det faktum att vissa rader saknas eller dubbelräknas kanske inte spelar så stor roll i det bredare schemat. På ett system med många samtidiga ändringar kan det till och med vara svårt att vara säker på att resultatet var felaktiga, med tanke på att uppgifterna ändras så ofta. I den sortens situation kan ett ungefär korrekt svar vara tillräckligt bra för datakonsumentens syften.
Ingen tidpunktsvy
Den tredje frågan (frågan om en så kallad "konsekvent" tidpunktssyn av data) kommer också ner på samma sorts överväganden. För rapporteringsändamål, där inkonsekvenser tenderar att resultera i besvärliga frågor från datakonsumenterna, är en ögonblicksbildsvy ofta att föredra. I andra fall kan den sortens inkonsekvenser som uppstår på grund av avsaknaden av en punkt-i-tid-vy av data mycket väl vara acceptabel.
Problematiska scenarier
Det finns också många fall där de angivna problemen kommer vara viktig. Till exempel om du skriver kod som upprätthåller affärsregler i T-SQL måste du vara noga med att välja en isoleringsnivå (eller vidta andra lämpliga åtgärder) för att garantera korrekthet. Många affärsregler kan upprätthållas med hjälp av främmande nycklar eller begränsningar, där krångligheterna med val av isoleringsnivå hanteras automatiskt åt dig av databasmotorn. Som en allmän tumregel använder du den inbyggda uppsättningen deklarativ integritet funktioner är att föredra framför att bygga dina egna regler i T-SQL.
Det finns en annan bred klass av frågor som inte riktigt upprätthåller en affärsregel i sig , men som trots det kan få olyckliga konsekvenser när den körs på standardnivån för låsning av läs committed isolation. Dessa scenarier är inte alltid lika självklara som de ofta citerade exemplen på att överföra pengar mellan bankkonton, eller att säkerställa att saldot över ett antal länkade konton aldrig faller under noll. Betrakta till exempel följande fråga som identifierar förfallna fakturor som en input till någon process som skickar ut strängt formulerade påminnelsebrev:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Det är uppenbart att vi inte skulle vilja skicka ett brev till någon som helt och hållet hade betalat sin faktura i omgångar, helt enkelt för att samtidig databasaktivitet vid tidpunkten för vår förfrågan gjorde att vi beräknade en felaktig summa av mottagna betalningar. Verkliga frågor om riktiga produktionssystem är ofta mycket mer komplexa än det enkla exemplet ovan, naturligtvis.
För att avsluta för idag, ta en titt på följande fråga och se om du kan upptäcka hur många möjligheter det finns för att något oavsiktligt ska inträffa, om flera sådana frågor körs samtidigt på den låsande läs-beslutade isoleringsnivån (kanske medan andra orelaterade transaktioner ändrar också tabellen ärende):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; När du väl börjar leta efter alla små sätt som en fråga kan gå fel på den här isoleringsnivån kan det vara svårt att stoppa. Kom ihåg de förbehåll som noterats tidigare kring det verkliga behovet av helt isolerade och exakta resultat vid tidpunkten. Det är helt okej att ha frågor som ger tillräckligt bra resultat, så länge du är medveten om de avvägningar du gör genom att använda read committed.
Nästa gång
Nästa del i den här serien tittar på den andra fysiska implementeringen av read committed isolation tillgänglig i SQL Server, read committed snapshot isolation.
[ Se indexet för hela serien ]