Enstaka predikat
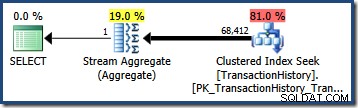
Att uppskatta antalet rader som kvalificeras av ett enda frågepredikat är ofta enkelt. När ett predikat gör en enkel jämförelse mellan en kolumn och ett skalärt värde är chansen god att kardinalitetsuppskattaren kommer att kunna härleda en uppskattning av god kvalitet från statistikhistogrammet. Till exempel ger följande AdventureWorks-fråga en exakt korrekt uppskattning av 203 rader (förutsatt att inga ändringar har gjorts i data sedan statistiken byggdes):
VÄLJ COUNT_BIG(*)FROM Production.TransactionHistory AS THWHERE TH.TransactionDate ='20070903';
Tittar på statistikhistogrammet för TransactionDate kolumn, är det tydligt att se var denna uppskattning kom ifrån:
DBCC SHOW_STATISTICS ( 'Production.TransactionHistory', 'TransactionDate')WITH HISTOGRAM;
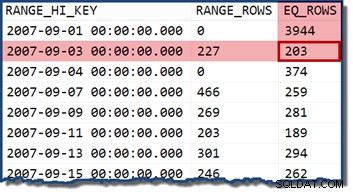
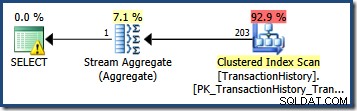
Om vi ändrar frågan för att ange ett datum som faller inom en histogramsegment, antar kardinalitetsuppskattaren att värdena är jämnt fördelade. Använder datumet 2007-09-02 ger en uppskattning av 227 rader (från RANGE_ROWS inträde). Som en intressant sidonotering förblir uppskattningen på 227 rader oavsett vilken tidsdel vi kan lägga till datumvärdet (TransactionDate kolumnen är en datetime datatyp).
Om vi försöker frågan igen med datumet 2007-09-05 eller 2007-09-06 (som båda faller mellan 2007-09-04 och 2007-09-07 histogramsteg), antar kardinalitetsuppskattaren 466 RANGE_ROWS är jämnt fördelade mellan de två värdena, och uppskattar 233 rader i båda fallen.
Det finns många andra detaljer för kardinalitetsuppskattning för enkla predikat, men det föregående kommer att fungera som en uppfräschning för våra nuvarande syften.
Problemen med flera predikat
När en fråga innehåller mer än ett kolumnpredikat blir kardinalitetsuppskattningen svårare. Tänk på följande fråga med två enkla predikat (som var och en är lätt att uppskatta ensam):
VÄLJ COUNT_BIG(*)FROM Production.TransactionHistory SOM THWHERE TH.TransactionID MELLAN 100000 OCH 168412 OCH TH.TransactionDate MELLAN '20070901' OCH '20080313';
De specifika värdeintervallen i frågan är medvetet valda så att båda predikaten identifierar exakt samma rader. Vi kan enkelt modifiera frågevärdena för att resultera i hur mycket överlappning som helst, inklusive ingen överlappning alls. Föreställ dig nu att du är kardinalitetsuppskattaren:hur skulle du härleda en kardinalitetsuppskattning för den här frågan?
Problemet är svårare än det kanske låter vid första tillfället. Som standard skapar SQL Server automatiskt statistik med en kolumn på båda predikatkolumnerna. Vi kan också skapa flerkolumnstatistik manuellt. Ger detta oss tillräckligt med information för att göra en bra uppskattning för dessa specifika värden? Vad sägs om det mer allmänna fallet där det kan finnas någon grad av överlappning?
Med hjälp av de två statistiska objekten med en kolumn kan vi enkelt härleda en uppskattning för varje predikat med hjälp av histogrammetoden som beskrivs i föregående avsnitt. För de specifika värdena i frågan ovan visar histogrammen att TransactionID intervallet förväntas matcha 68412.4 rader och TransactionDate intervallet förväntas matcha 68 413 rader. (Om histogrammen var perfekta skulle dessa två siffror vara exakt likadana.)
Vad histogrammen inte kan berätta för oss är hur många från dessa två uppsättningar rader som kommer att vara samma rader . Allt vi kan säga baserat på histograminformationen är att vår uppskattning bör vara någonstans mellan noll (för ingen överlappning alls) och 68412,4 rader (fullständig överlappning).
Att skapa statistik med flera kolumner ger ingen hjälp för den här frågan (eller för intervallfrågor i allmänhet). Statistik med flera kolumner skapar fortfarande bara ett histogram över den först namngivna kolumnen, vilket i huvudsak duplicerar histogrammet som är associerat med en av de automatiskt skapade statistikerna. Den ytterligare densiteten information som tillhandahålls av statistiken med flera kolumner kan vara användbar för att tillhandahålla information om genomsnittliga fall för frågor som innehåller flera likhetspredikat, men de är inte till någon hjälp för oss här.
För att göra en uppskattning med en hög grad av tillförlitlighet skulle vi behöva SQL Server för att ge bättre information om datadistributionen – ungefär som en flerdimensionell statistik histogram. Så vitt jag vet erbjuder ingen kommersiell databasmotor för närvarande en sådan här anläggning, även om flera tekniska artiklar har publicerats i ämnet (inklusive en Microsoft Research som använde en intern utveckling av SQL Server 2000).
Utan att veta något om datakorrelationer och överlappningar för särskilda värdeintervall är det inte klart hur vi ska gå tillväga för att ta fram en bra uppskattning för vår fråga. Så, vad gör SQL Server här?
SQL Server 7 – 2012
Kardinalitetsuppskattaren i dessa versioner av SQL Server antar i allmänhet att värden för olika attribut i en tabell distribueras helt oberoende av varandra. Detta oberoendeantagande är sällan en korrekt återspegling av verklig data, men den har fördelen av att göra det enklare beräkningar.
OCH selektivitet
Med antagandet om oberoende, två predikat sammankopplade med AND (känd som en konjunktion ) med selektiviteter S1 och S2 , resulterar i en kombinerad selektivitet av:
(S1 * S2)
Om termen inte är bekant för dig, selektivitet är ett tal mellan 0 och 1, som representerar bråkdelen av rader i tabellen som passerar predikatet. Till exempel, om ett predikat väljer 12 rader från en tabell med 100 rader, är selektiviteten (12/100) =0,12.
I vårt exempel, TransactionHistory Tabellen innehåller totalt 113 443 rader. Predikatet på TransactionID beräknas (från histogrammet) kvalificera 68 412,4 rader, så selektiviteten är (68 412,4 / 113 443) eller ungefär 0,603055 . Predikatet på TransactionDate uppskattas på samma sätt ha en selektivitet på (68 413 / 113 443) =ungefär 0,603061 .
Att multiplicera de två selektiviteterna (med formeln ovan) ger en kombinerad selektivitetsuppskattning på 0,363679 . Att multiplicera denna selektivitet med tabellens kardinalitet (113 443) ger den slutliga uppskattningen på 41 256,8 rader:
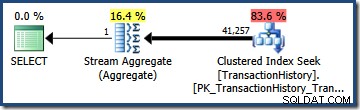
ELLER Selektivitet
Två predikat sammankopplade med OR (en disjunction ) med selektiviteter S1 och S2 , resulterar i en kombinerad selektivitet av:
(S1 + S2) – (S1 * S2)
Intuitionen bakom formeln är att lägga till de två selektiviteterna och sedan subtrahera uppskattningen för deras konjunktion (med hjälp av föregående formel). Det är klart att vi skulle kunna ha två predikat, var och en med selektivitet 0,8, men att bara addera dem tillsammans skulle ge en omöjlig kombinerad selektivitet på 1,6. Trots oberoende antagandet måste vi inse att de två predikaten kan ha en överlappning, så för att undvika dubbelräkning subtraheras den uppskattade selektiviteten för konjunktionen.
Vi kan enkelt modifiera vårt körexempel för att använda OR :
VÄLJ COUNT_BIG(*)FRÅN Production.TransactionHistory SOM THWHERE TH.TransactionID MELLAN 100000 OCH 168412 ELLER TH.TransactionDate MELLAN '20070901' OCH '20080313';
Ersätter predikatselektiviteterna med OR formel ger en kombinerad selektivitet av:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Multiplicerad med antalet rader i tabellen ger denna selektivitet oss den slutliga kardinalitetsuppskattningen på 95 568,6 :
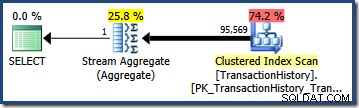
Ingen uppskattning (41 257 för AND fråga; 95 569 för OR query) är särskilt bra eftersom båda är baserade på ett modelleringsantagande som inte matchar datafördelningen särskilt väl. Båda frågorna returnerar faktiskt 68 413 rader (eftersom predikaten identifierar exakt samma rader).
Spårningsflagga 4137 – Minsta selektivitet
För SQL Server 2008 (R1) till och med 2012 släppte Microsoft en korrigering som ändrar hur selektivitet beräknas för AND endast kasus (konjunktiva predikat). Knowledge Base-artikeln i den länken innehåller inte många detaljer, men det visar sig att fixen ändrar selektivitetsformeln som används. Istället för att multiplicera de individuella selektiviteterna använder kardinalitetsuppskattningen för konjunktiva predikat nu enbart den lägsta selektiviteten.
För att aktivera det ändrade beteendet krävs en stödd spårningsflagga 4137. En separat Knowledge Base-artikel dokumenterar att denna spårningsflagga också stöds för användning per fråga via QUERYTRACEON tips:
VÄLJ COUNT_BIG(*)FROM Production.TransactionHistory SOM THWHERE TH.TransactionID MELLAN 100000 OCH 168412 OCH TH.TransactionDate MELLAN '20070901' OCH '20080313'OPTION (QUERYTRACEON );Med denna flagga aktiv använder kardinalitetsuppskattningen den lägsta selektiviteten för de två predikaten, vilket resulterar i en uppskattning på 68 412,4 rader:
Detta råkar vara nästan perfekt för vår fråga eftersom våra testpredikat är exakt korrelerade (och uppskattningarna som härrör från bashistogrammen är också mycket bra).
Det är ganska sällsynt att predikat är perfekt korrelerade så här med verklig data, men spårflaggan kan ändå hjälpa i vissa fall. Observera att det lägsta selektivitetsbeteendet kommer att gälla för alla konjunktiva (
AND) predikat i frågan; det finns inget sätt att specificera beteendet på en mer detaljerad nivå.Det finns ingen motsvarande spårningsflagga för att uppskatta disjunktiv (
OR) predikat som använder minsta selektivitet.SQL Server 2014
Selektivitetsberäkning i SQL Server 2014 fungerar på samma sätt som tidigare versioner (och spårningsflagga 4137 fungerar som tidigare) om databaskompatibilitetsnivån är lägre än 120, eller om spårningsflagga 9481 är aktiv. Att ställa in databaskompatibilitetsnivån är den officiella sätt att använda kardinalitetskalkylatorn före 2014 i SQL Server 2014. Spårningsflagga 9481 är effektiv för att göra samma sak som i skrivande stund, och fungerar även med
QUERYTRACEON, även om det inte är dokumenterat att göra det. Det finns inget sätt att veta vad RTM-beteendet för denna flagga kommer att vara.Om den nya kardinalitetsuppskattaren är aktiv använder SQL Server 2014 en annan standardformel för att kombinera konjunktiva och disjunktiva predikat. Även om den är odokumenterad har selektivitetsformeln för konjunktioner upptäckts och dokumenterats flera gånger nu. Den första jag minns att jag såg är i det här portugisiska blogginlägget och uppföljningsdelen två publicerades ett par veckor senare. För att sammanfatta, 2014 års syn på konjunktiva predikat är att använda exponentiell backoff: ges en tabell med kardinalitet C, och predikatselektiviteter S1 , S2 , S3 … Sn , där S1 är den mest selektiva och Sn minst:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …Uppskattningen beräknas det mest selektiva predikatet multiplicerat med tabellens kardinalitet, multiplicerat med kvadratroten av det näst mest selektiva predikatet, och så vidare med varje ny selektivitet som får ytterligare en kvadratrot.
Om man minns att selektivitet är ett tal mellan 0 och 1, är det tydligt att användningen av en kvadratrot flyttar talet närmare 1. Effekten är att ta hänsyn till alla predikat i den slutliga skattningen, men att minska effekten av de mindre selektiva predikaten. exponentiellt. Det finns utan tvekan mer logik i denna idé än under oberoendeantagandet , men det är fortfarande en fast formel – den ändras inte baserat på den faktiska graden av datakorrelation.
Kardinalitetsuppskattaren 2014 använder en exponentiell backoff-formel för båda konjunktiva och disjunktiva predikat, även om formeln som används i disjunktiven (
OR) fall har ännu inte dokumenterats (officiellt eller på annat sätt).SQL Server 2014 selektivitetsspårningsflaggor
Spårningsflagga 4137 (för att använda minsta selektivitet) gör inte fungerar i SQL Server 2014, om den nya kardinalitetsuppskattaren används vid kompilering av en fråga. Istället finns det en ny spårningsflagga 9471 . När denna flagga är aktiv används minsta selektivitet för att uppskatta flera konjunktiva och disjunktiva predikat. Detta är en förändring från 4137-beteendet, som bara påverkade konjunktiva predikat.
På liknande sätt, spåra flaggan 9472 kan specificeras för att anta oberoende för flera predikat, som tidigare versioner gjorde. Den här flaggan skiljer sig från 9481 (för att använda kardinalitetsuppskattaren före 2014) eftersom den nya kardinalitetsuppskattaren fortfarande kommer att användas under 9472, endast selektivitetsformeln för flera predikat påverkas.
Varken 9471 eller 9472 är dokumenterade i skrivande stund (även om de kan finnas hos RTM).
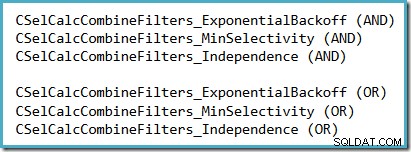
Ett bekvämt sätt att se vilket selektivitetsantagande som används i SQL Server 2014 (med den nya kardinalitetsuppskattaren aktiv) är att undersöka felsökningsutdata för selektivitetsberäkning som produceras när spårningsflaggor 2363 och 3604 är aktiva. Avsnittet att leta efter hänför sig till selektivitetskalkylatorn som kombinerar filter, där du kommer att se något av följande, beroende på vilket antagande som används:
Det finns inga realistiska utsikter att 2363 kommer att dokumenteras eller stödjas.
Sluta tankar
Det finns inget magiskt med exponentiell backoff, minimal selektivitet eller oberoende. Varje tillvägagångssätt representerar ett (väldigt) förenklat antagande som kan eller kanske inte ger en acceptabel uppskattning för en viss fråga eller datadistribution.
I vissa avseenden, exponentiell backoff representerar en kompromiss mellan de två ytterligheterna av oberoende och minsta selektivitet . Trots det är det viktigt att inte ha orimliga förväntningar på det. Tills ett mer exakt sätt hittas för att uppskatta selektivitet för flera predikat (med rimliga prestandaegenskaper) är det fortfarande viktigt att vara medveten om modellens begränsningar och se upp för (potentiella) uppskattningsfel i enlighet därmed.
De olika spårningsflaggorna ger viss kontroll över vilket antagande som används, men situationen är långt ifrån perfekt. För det första är den finaste granulariteten vid vilken en flagga kan tillämpas en enda fråga – uppskattningsbeteende kan inte specificeras på predikatnivån. Om du har en fråga där vissa predikat är korrelerade och andra oberoende, kanske spårningsflaggorna inte hjälper dig mycket utan att omfaktorisera frågan på ett eller annat sätt. På samma sätt kan en problematisk fråga ha predikatkorrelationer som inte är väl modellerade av något av de tillgängliga alternativen.
Ad-hoc användning av spårningsflaggor kräver samma behörigheter som
DBCC TRACEON– nämligen sysadmin . Det är förmodligen bra för personliga tester, men för produktion använd en planguide medQUERYTRACEONtips är ett bättre alternativ. Med en planguide krävs inga ytterligare behörigheter för att köra frågan (även om förhöjda behörigheter krävs för att skapa planguiden, naturligtvis).