Då och då ser jag att någon uttrycker ett krav på att skapa ett slumptal för en nyckel. Vanligtvis är detta för att skapa någon typ av surrogat kund-ID eller användar-ID som är ett unikt nummer inom ett visst intervall, men som inte utfärdas sekventiellt och därför är mycket mindre gissbart än en IDENTITY värde.
NEWID() löser gissningsproblemet, men prestandastraffet är vanligtvis en deal-breaker, särskilt när de är klustrade:mycket bredare nycklar än heltal och siddelning på grund av icke-sekventiella värden. NEWSEQUENTIALID() löser siddelningsproblemet, men är fortfarande en mycket bred nyckel, och återinför problemet att du kan gissa nästa värde (eller nyligen utfärdade värden) med en viss grad av noggrannhet.
Som ett resultat vill de ha en teknik för att generera ett slumpmässigt och unikt heltal. Att generera ett slumptal på egen hand är inte svårt, med metoder som RAND() eller CHECKSUM(NEWID()) . Problemet kommer när du måste upptäcka kollisioner. Låt oss ta en snabb titt på ett typiskt tillvägagångssätt, förutsatt att vi vill ha kund-ID-värden mellan 1 och 1 000 000:
DECLARE @rc INT =0, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1; -- eller ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1; -- eller KONVERTERA(INT, RAND() * 1000000) + 1;MED @rc =0BEGIN OM INTE FINNS (VÄLJ 1 FRÅN dbo.Customers WHERE CustomerID =@CustomerID) BEGIN INSERT dbo.Customers(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @rc =0; SLUT
När bordet blir större blir det inte bara dyrare att kontrollera efter dubbletter, utan dina odds för att generera en dubblett ökar också. Så det här tillvägagångssättet kan tyckas fungera okej när bordet är litet, men jag misstänker att det måste göra mer och mer ont med tiden.
Ett annat tillvägagångssätt
Jag är ett stort fan av extrabord; Jag har skrivit offentligt om kalendertabeller och taltabeller i ett decennium och använt dem mycket längre. Och det här är ett fall där jag tror att en i förväg ifylld tabell kan vara väldigt praktisk. Varför lita på att generera slumpmässiga siffror vid körning och hantera potentiella dubbletter, när du kan fylla i alla dessa värden i förväg och vet – med 100 % säkerhet, om du skyddar dina tabeller från obehörig DML – att nästa värde du väljer aldrig har varit använd tidigare?
CREATE TABLE dbo.RandomNumbers1( RowID INT, Value INT, --UNIQUE, PRIMARY KEY (RowID, Value));;WITH x AS ( SELECT TOP (1000000) s1.[object_id] FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id])INSERT dbo.RandomNumbers(Row)_SELECTr (Row)_SELECTr, Value ) OVER (ORDER BY [object_id]), n =ROW_NUMBER() OVER (ORDER BY NEWID())FRÅN xORDER BY r;
Denna population tog 9 sekunder att skapa (i en virtuell dator på en bärbar dator) och upptog cirka 17 MB på disken. Data i tabellen ser ut så här:
(Om vi var oroliga för hur siffrorna skulle fyllas i, kunde vi lägga till en unik begränsning i värdekolumnen, vilket skulle göra tabellen till 30 MB. Hade vi använt sidkomprimering skulle det ha varit 11 MB respektive 25 MB. )
Jag skapade ytterligare en kopia av tabellen och fyllde i den med samma värden, så att jag kunde testa två olika metoder för att härleda nästa värde:
CREATE TABLE dbo.RandomNumbers2( RowID INT, Value INT, -- UNIK PRIMÄRNYCKEL (RowID, Value)); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Nu, när som helst vi vill ha ett nytt slumpmässigt nummer, kan vi bara ta bort ett från stapeln av befintliga nummer och ta bort det. Detta förhindrar oss från att behöva oroa oss för dubbletter, och tillåter oss att dra siffror – med hjälp av ett klustrade index – som faktiskt redan är i slumpmässig ordning. (Strängt taget behöver vi inte ta bort siffrorna när vi använder dem; vi skulle kunna lägga till en kolumn för att indikera om ett värde har använts – detta skulle göra det lättare att återställa och återanvända det värdet i händelse av att en kund senare blir raderad eller något går fel utanför denna transaktion men innan de är helt skapade.)
DECLARE @holding TABLE(Kund-ID INT); DELETE TOP (1) dbo.RandomNumbers1OUTPUT deleted.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...other columns...) SELECT CustomerID, ...other params... FROM @holding;
Jag använde en tabellvariabel för att hålla mellanutgången, eftersom det finns olika begränsningar med komponerbar DML som kan göra det omöjligt att infoga i Kundtabellen direkt från DELETE (till exempel förekomsten av främmande nycklar). Ändå, eftersom jag erkände att det inte alltid kommer att vara möjligt, ville jag också testa den här metoden:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...andra params... INTO dbo.Customers(CustomerID, ...other columns...);
Observera att ingen av dessa lösningar verkligen garanterar slumpmässig ordning, särskilt om tabellen med slumptal har andra index (som ett unikt index i kolumnen Värde). Det finns inget sätt att definiera en beställning för en DELETE med TOP; från dokumentationen:
Så om du vill garantera slumpmässig beställning kan du göra något så här istället:
DECLARE @holding TABLE(Kund-ID INT);;WITH x AS ( VÄLJ TOP (1) Värde FRÅN dbo.RandomNumbers2 ORDER BY RowID)DELETE x OUTPUT deleted.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...other columns...) SELECT CustomerID, ...other params... FROM @holding;
En annan övervägande här är att, för dessa tester, har Kundtabellerna en klustrad primärnyckel i kolumnen Kund-ID; detta kommer säkerligen att leda till siddelningar när du infogar slumpmässiga värden. I den verkliga världen, om du hade det här kravet, skulle du förmodligen hamna i en kluster i en annan kolumn.
Notera att jag även har utelämnat transaktioner och felhantering här, men även dessa bör vara ett övervägande för produktionskoden.
Prestandatest
För att göra några realistiska prestandajämförelser skapade jag fem lagrade procedurer som representerar följande scenarier (testning av hastighet, distribution och kollisionsfrekvens för de olika slumpmässiga metoderna, samt hastigheten för att använda en fördefinierad tabell med slumptal):
- Körtidsgenerering med
CHECKSUM(NEWID()) - Körtidsgenerering med
CRYPT_GEN_RANDOM() - Körtidsgenerering med
RAND() - Fördefinierad taltabell med tabellvariabel
- Fördefinierad taltabell med direkt infogning
De använder en loggningstabell för att spåra varaktighet och antal kollisioner:
CREATE TABLE dbo.CustomerLog( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, kollisioner INT, varaktighet INT -- mikrosekunder);
Koden för procedurerna följer (klicka för att visa/dölja):
/* Runtime using CHECKSUM(NEWID()) */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]SOM BÖRJAN STÄLLA IN NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BÖRJA OM INTE FINNS (VÄLJ 1 FRÅN dbo.Customers_Runtime_Checksum WHERE CustomerID =@CustomerID ) BÖRJA INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kollisioner, varaktighet) SELECT 1, @collisions, @duration;ENDGO /* runtime using CRYPT_GEN_RANDOM() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]SOM BÖRJAN STÄLLA IN NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BÖRJA OM INTE FINNS (VÄLJ 1 FRÅN dbo.Customers_Runtime_CryptGen WHERE CustomerID =@CustomerID ) BÖRJA INSERT dbo.Customers_Runtime_CryptGen(CustomerID) VÄLJ @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kollisioner, varaktighet) SELECT 2, @collisions, @duration;ENDGO /* körtid med RAND() */ SKAPA PROCEDUR [dbo].[AddCustomer_Runtime_Rand]SOM BÖRJAN STÄLLA IN NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =CONVERT(INT, RAND() * 1000000) + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN IF NOT EXISTS (VÄLJ 1 FRÅN dbo.Customers_Runtime_Rand WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =CONVERT(INT, RAND() * 1000000) + 1, @collisions +=1, @rc =0; END END SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kollisioner, varaktighet) SELECT 3, @collisions, @duration;ENDGO /* fördefinierad med hjälp av en tabellvariabel */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]SOM BÖRJAN STÄLLA IN NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; DECLARE @holding TABLE(Kund-ID INT); DELETE TOP (1) dbo.RandomNumbers1 OUTPUT deleted.Value INTO @holding; INSERT dbo.Customers_Predefined_TableVariable(CustomerID) SELECT CustomerID FROM @holding; SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;ENDGO /* fördefinierad med en direkt infogning */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]SOM BÖRJAN STÄLLA IN NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct; SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;ENDGO
Och för att testa detta skulle jag köra varje lagrad procedur 1 000 000 gånger:
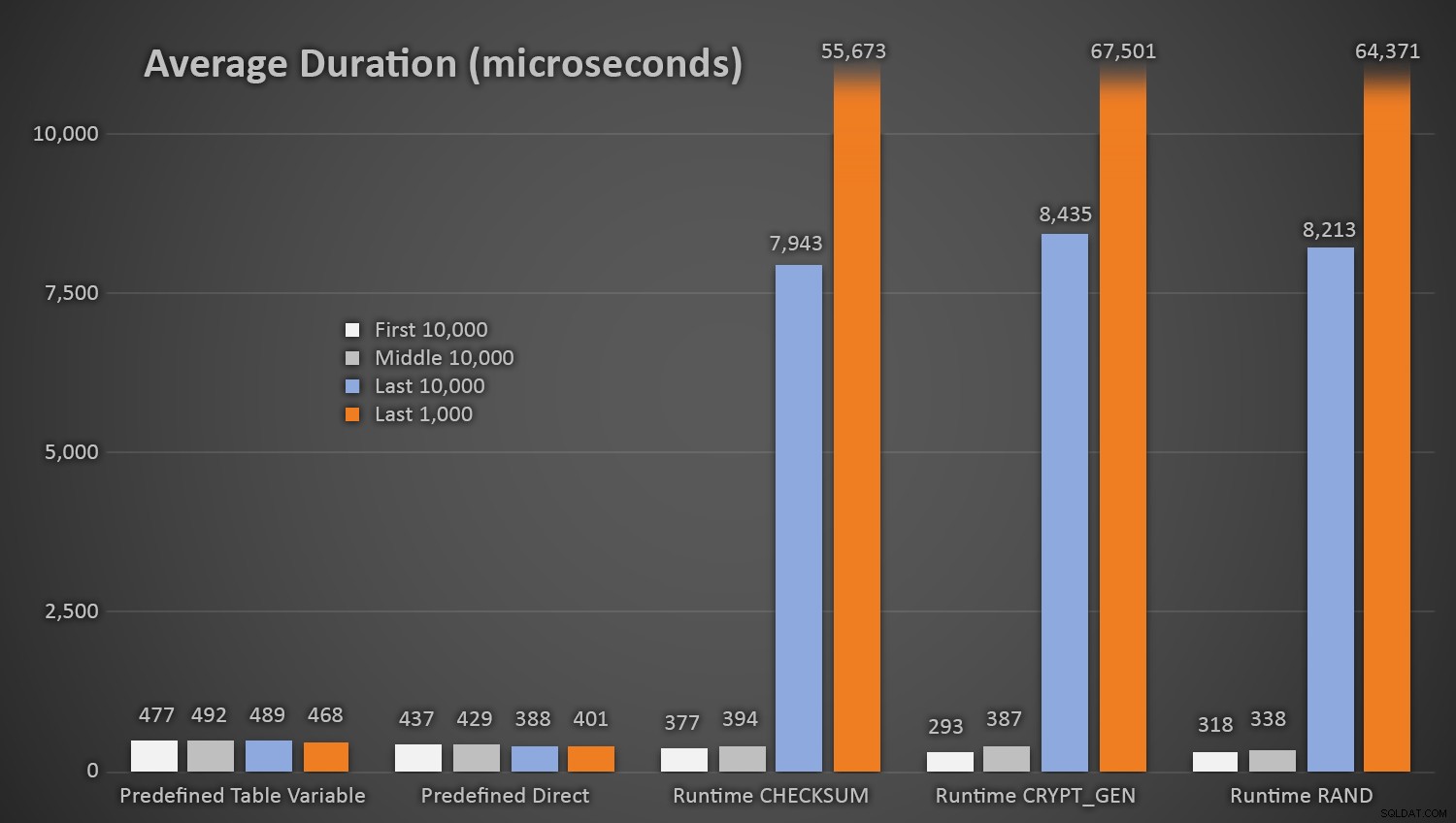
EXEC dbo.AddCustomer_Runtime_Checksum;EXEC dbo.AddCustomer_Runtime_CryptGen;EXEC dbo.AddCustomer_Runtime_Rand;EXEC dbo.AddCustomer_Predefined_TableVariable;EXEC dbo.Goddefinierad_1Direct;0Inte överraskande tog metoderna med den fördefinierade tabellen med slumptal något längre *i början av testet*, eftersom de var tvungna att utföra både läs- och skriv-I/O varje gång. Tänk på att dessa siffror är i mikrosekunder , här är den genomsnittliga varaktigheten för varje procedur, med olika intervall längs vägen (i genomsnitt över de första 10 000 avrättningarna, de mellersta 10 000 avrättningarna, de senaste 10 000 avrättningarna och de senaste 1 000 avrättningarna):
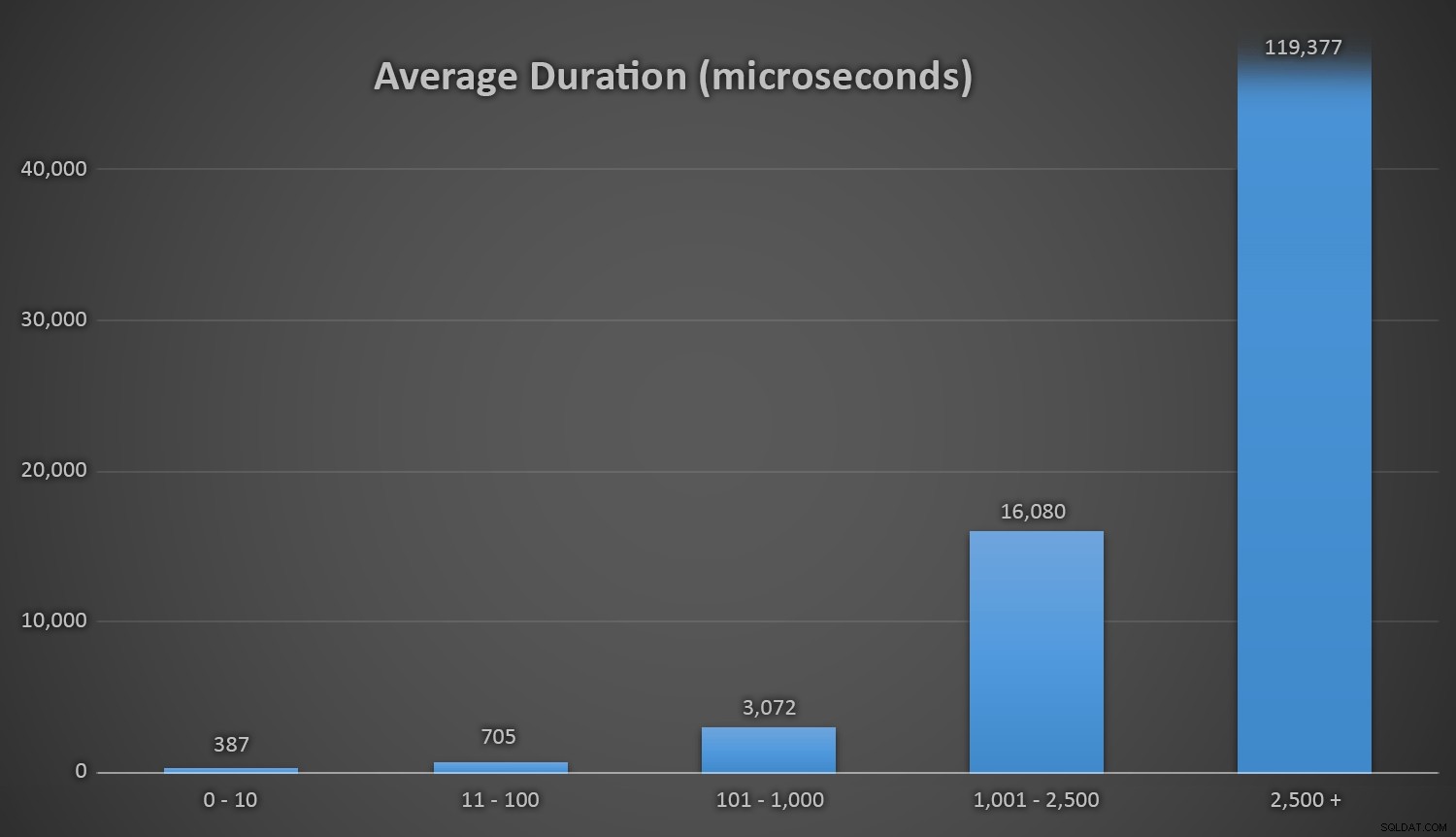
Genomsnittlig varaktighet (i mikrosekunder) av slumpmässig generering med olika metoderDetta fungerar bra för alla metoder när det finns få rader i Kundtabellen, men i takt med att tabellen blir större och större ökar kostnaden för att kontrollera det nya slumptalet mot befintlig data med runtime-metoderna avsevärt, både på grund av ökat I /O och även för att antalet kollisioner ökar (som tvingar dig att försöka igen). Jämför den genomsnittliga varaktigheten i följande intervall av kollisionsantal (och kom ihåg att det här mönstret endast påverkar körtidsmetoderna):
Genomsnittlig varaktighet (i mikrosekunder) under olika kollisionsintervallJag önskar att det fanns ett enkelt sätt att plotta varaktighet mot kollisionsantal. Jag lämnar dig med den här godbiten:på de tre sista insatserna, var följande körtidsmetoder tvungna att utföra så många försök innan de slutligen snubblade över det senaste unika ID de letade efter, och så här lång tid tog det:
| Antal kollisioner | Längd (mikrosekunder) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | 3:e till sista raden | 63 545 | 639 358 |
| Andra till sista raden | 164 807 | 1 605 695 | |
| Sista raden | 30 630 | 296 207 | |
| CRYPT_GEN_RANDOM() | 3:e till sista raden | 219 766 | 2 229 166 |
| Andra till sista raden | 255 463 | 2 681 468 | |
| Sista raden | 136 342 | 1 434 725 | |
| RAND() | 3:e till sista raden | 129 764 | 1 215 994 |
| Andra till sista raden | 220 195 | 2 088 992 | |
| Sista raden | 440 765 | 4 161 925 | |
Över lång tid och kollisioner nära slutet av linjen
Det är intressant att notera att den sista raden inte alltid är den som ger det högsta antalet kollisioner, så detta kan börja bli ett verkligt problem långt innan du har använt upp 999 000+ värden.
En annan övervägande
Du kanske vill överväga att ställa in någon form av varning eller avisering när tabellen RandomNumbers börjar komma under ett visst antal rader (då kan du fylla i tabellen igen med en ny uppsättning från 1 000 001 till 2 000 000, till exempel). Du skulle behöva göra något liknande om du genererade slumpmässiga siffror i farten – om du håller det inom ett intervall på 1 – 1 000 000, då måste du ändra koden för att generera siffror från ett annat intervall när du har har använt upp alla dessa värden.
Om du använder metoden slumptal vid körning kan du undvika denna situation genom att hela tiden ändra poolstorleken från vilken du drar ett slumptal (vilket också borde stabilisera och drastiskt minska antalet kollisioner). Till exempel istället för:
DECLARE @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Du kan basera poolen på antalet rader som redan finns i tabellen:
DECLARE @total INT =1000000 + ISNULL( (SELECT SUM(row_count) FROM sys.dm_db_partition_stats WHERE [object_id] =OBJECT_ID('dbo.Customers') AND index_id =1),0);
Nu är din enda verkliga oro när du närmar dig den övre gränsen för INT …
Obs:Jag skrev också nyligen ett tips om detta på MSSQLTips.com.