Varje produkt har buggar, och SQL Server är inget undantag. Att använda produktfunktioner på ett lite ovanligt sätt (eller att kombinera relativt nya funktioner tillsammans) är ett bra sätt att hitta dem. Buggar kan vara intressanta och till och med lärorika, men kanske går en del av glädjen förlorad när upptäckten resulterar i att din personsökare går igång klockan 04:00, kanske efter en särskilt social utekväll med vänner...
Buggan som är ämnet för det här inlägget är förmodligen ganska sällsynt i naturen, men det är inget klassiskt kantfodral. Jag känner till minst en konsult som har stött på det i ett produktionssystem. Om ett helt orelaterade ämne borde jag passa på att säga "hej" till Grumpy Old DBA (bloggen).
Jag börjar med lite relevant bakgrund om sammanslagningar. Om du är säker på att du redan vet allt som finns att veta om merge join, eller om du bara vill ta tag i det, skrolla gärna ner till avsnittet med titeln "The Bug."
Slå samman gå med
Merge join är inte särskilt komplicerat och kan vara mycket effektivt under rätt omständigheter. Den kräver att dess ingångar sorteras på join-nycklarna och fungerar bäst i ett-till-många-läge (där åtminstone av dess ingångar är unika på join-nycklarna). För en-till-många-kopplingar av måttlig storlek är seriell sammanfogning inte alls ett dåligt val, förutsatt att indatasorteringskraven kan uppfyllas utan att utföra en explicit sortering.
Att undvika en sortering uppnås oftast genom att utnyttja ordningen som tillhandahålls av ett index. Merge join kan också dra fördel av bevarad sorteringsordning från en tidigare, oundviklig sortering. En häftig sak med merge join är att den kan sluta bearbeta inmatningsrader så snart någon av ingångarna tar slut på rader. En sista sak:merge join bryr sig inte om indatasorteringsordningen är stigande eller fallande (även om båda ingångarna måste vara samma). Följande exempel använder en standardtabell för nummer för att illustrera de flesta av punkterna ovan:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Lägg märke till att indexen som upprätthåller primärnycklarna på dessa två tabeller är definierade som fallande. Frågeplanen för INSERT har ett antal intressanta funktioner:
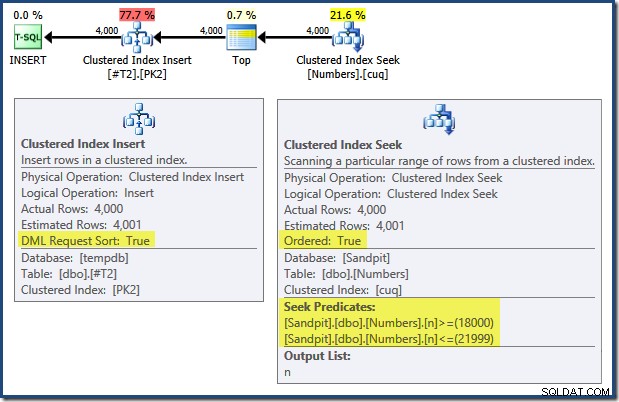
När man läser från vänster till höger (som bara är förnuftigt!) har Clustered Index Insert egenskapen "DML Request Sort". Detta innebär att operatören kräver rader i nyckelordning för Cluster Index. Det klustrade indexet (som upprätthåller primärnyckeln i detta fall) definieras som DESC , så rader med högre värden måste komma först. Det klustrade indexet på min Numbers-tabell är ASC , så frågeoptimeraren undviker en explicit sortering genom att först söka efter den högsta matchningen i tabellen Numbers (21 999) och sedan skanna mot den lägsta matchningen (18 000) i omvänd indexordning. Vyn "Planträd" i SQL Sentry Plan Explorer visar den omvända (bakåt) skanningen tydligt:
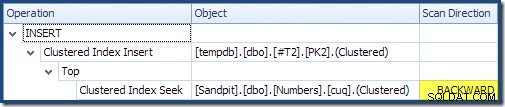
Bakåtskanning omvänder den naturliga ordningen för indexet. En bakåtsökning av en ASC indexnyckel returnerar rader i fallande nyckelordning; en bakåtsökning av en DESC indexnyckel returnerar rader i stigande nyckelordning. "Skanningsriktningen" indikerar inte returnerad nyckelorder i sig själv – du måste veta om indexet är ASC eller DESC för att göra det beslutet.
Använda dessa testtabeller och data (T1 har 10 000 rader numrerade från 10 000 till 19 999 inklusive; T2 har 4 000 rader numrerade från 18 000 till 21 999) följande fråga sammanfogar de två tabellerna och returnerar resultat i fallande ordning för båda nycklarna:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Frågan returnerar de korrekt matchande 2 000 raderna som du kan förvänta dig. Planen efter genomförandet är följande:
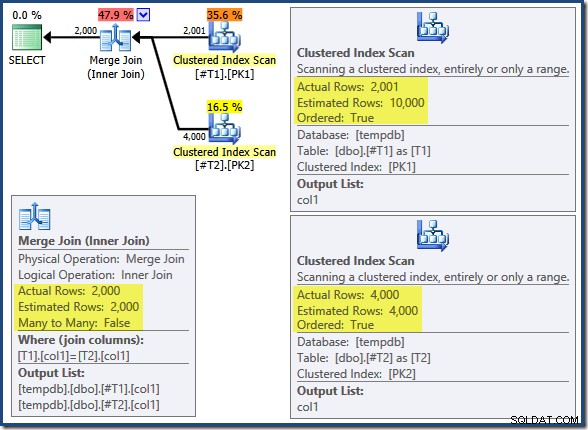
Merge Join körs inte i många-till-många-läge (den översta ingången är unik på join-nycklarna) och uppskattningen av 2 000 rader kardinalitet är exakt korrekt. Clustered Index Scan av tabell T2 är beställd (även om vi måste vänta ett ögonblick för att upptäcka om den ordningen är framåt eller bakåt) och kardinalitetsuppskattningen på 4 000 rader är också helt rätt. Clustered Index Scan av tabell T1 är också beställd, men endast 2 001 rader lästes medan 10 000 uppskattades. Planträdvyn visar att båda Clustered Index Scans är beställda framåt:
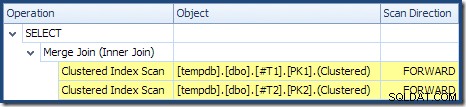
Kom ihåg att du läste en DESC index FORWARD kommer att producera rader i omvänd nyckelordning. Detta är exakt vad som krävs av ORDER BY T1.col DESC, T2.col1 DESC klausul, så ingen explicit sortering är nödvändig. Pseudokod för en-till-många Merge Join (reproducerad från Craig Freedmans Merge Join-blogg) är:

Den fallande ordningens skanning av T1 returnerar rader som börjar på 19 999 och arbetar ner mot 10 000. Den fallande ordningens skanning av T2 returnerar rader som börjar på 21 999 och arbetar ner mot 18 000. Alla 4 000 rader i T2 läses så småningom, men den iterativa sammanslagningsprocessen slutar när nyckelvärdet 17 999 läses från T1 , eftersom T2 tar slut på rader. Sammanfogningsbearbetningen slutförs därför utan att T1 helt lästs . Den läser rader från 19 999 ner till 17 999 inklusive; totalt 2 001 rader enligt exekveringsplanen ovan.
Kör gärna testet igen med ASC indexerar istället, och ändrar också ORDER BY sats från DESC till ASC . Den framställda utförandeplanen kommer att vara mycket lika, och inga sorteringar kommer att behövas.
För att sammanfatta de punkter som kommer att vara viktiga om ett ögonblick kräver Merge Join sorterade ingångar med join-nyckel, men det spelar ingen roll om nycklarna är sorterade stigande eller fallande.
Bugen
För att reproducera buggen måste minst en av våra tabeller partitioneras. För att resultaten ska kunna hanteras kommer det här exemplet att använda bara ett litet antal rader, så partitioneringsfunktionen behöver också små gränser:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
Den första tabellen innehåller två kolumner och är partitionerad på PRIMÄRNYCKELN:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
Den andra tabellen är inte partitionerad. Den innehåller en primärnyckel och en kolumn som kommer att ansluta till den första tabellen:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Exempeldata
Den första tabellen har 14 rader, alla med samma värde i SomeID kolumn. SQL Server tilldelar IDENTITY kolumnvärden, numrerade 1 till 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Den andra tabellen fylls helt enkelt i med IDENTITY värden från tabell ett:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Data i de två tabellerna ser ut så här:
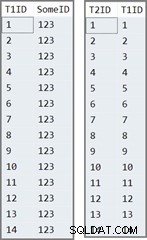
Testfrågan
Den första frågan förenar helt enkelt båda tabellerna och använder ett enda WHERE-satspredikat (som råkar matcha alla rader i detta mycket förenklade exempel):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Resultatet innehåller alla 14 rader, som förväntat:

På grund av det lilla antalet rader väljer optimeraren en kopplingsplan för kapslade loopar för denna fråga:
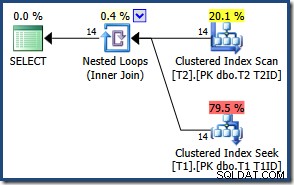
Resultaten är desamma (och fortfarande korrekta) om vi tvingar fram en hash- eller sammanfogning:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
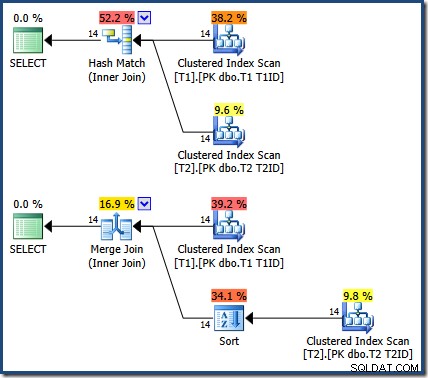
Sammanfogningen där är en-till-många, med en explicit sortering på T1ID krävs för tabellen T2 .
Det fallande indexproblemet
Allt är bra tills en dag (av goda skäl som inte behöver bekymra oss här) en annan administratör lägger till ett fallande index på SomeID kolumn i tabell 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Vår fråga fortsätter att ge korrekta resultat när optimeraren väljer en Nested Loops eller Hash Join, men det är en annan historia när en Merge Join används. Följande använder fortfarande en frågetips för att tvinga sammanfogningen, men detta är bara en konsekvens av det låga antalet rader i exemplet. Optimeraren skulle naturligtvis välja samma Merge Join-plan med olika tabelldata.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Utförandeplanen är:
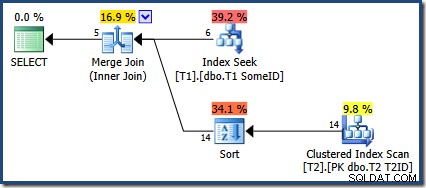
Optimeraren har valt att använda det nya indexet, men frågan producerar nu endast fem rader med utdata:

Vad hände med de andra 9 raderna? För att vara tydlig är detta resultat felaktigt. Data har inte ändrats, så alla 14 rader bör returneras (eftersom de fortfarande är med en plan för kapslade loopar eller Hash Join).
Orsak och förklaring
Det nya icke-klustrade indexet på SomeID deklareras inte som unik, så den klustrade indexnyckeln läggs tyst till alla icke-klustrade indexnivåer. SQL Server lägger till T1ID kolumn (den klustrade nyckeln) till det icke-klustrade indexet precis som om vi hade skapat indexet så här:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Lägg märke till avsaknaden av en DESC kvalificeraren på det tyst tillagda T1ID nyckel. Indexnycklar är ASC som standard. Detta är inget problem i sig (även om det bidrar). Det andra som händer med vårt index automatiskt är att det är partitionerat på samma sätt som bastabellen. Så, den fullständiga indexspecifikationen, om vi skulle skriva ut den explicit, skulle vara:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Det här är nu en ganska komplex struktur, med nycklar i alla möjliga olika ordningsföljder. Det är tillräckligt komplext för att frågeoptimeraren ska få fel när den resonerar om sorteringsordningen som indexet tillhandahåller. För att illustrera, överväg följande enkla fråga:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Den extra kolumnen visar oss bara vilken partition den aktuella raden tillhör. Annars är det bara en enkel fråga som returnerar T1ID värden i stigande ordning, WHERE SomeID = 123 . Tyvärr är resultaten inte vad som anges av frågan:
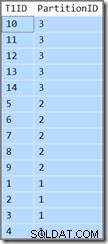
Frågan kräver att T1ID värden ska returneras i stigande ordning, men det är inte vad vi får. Vi får värden i stigande ordning per partition , men själva partitionerna returneras i omvänd ordning! Om partitionerna returnerades i stigande ordning (och T1ID värden förblev sorterade inom varje partition som visas) resultatet skulle vara korrekt.
Frågeplanen visar att optimeraren var förvirrad av den ledande DESC nyckeln i indexet och trodde att det behövde läsas partitionerna i omvänd ordning för korrekta resultat:
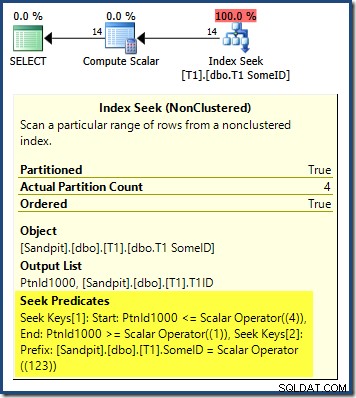
Partitionssökningen startar vid partitionen längst till höger (4) och fortsätter bakåt till partition 1. Du kanske tror att vi skulle kunna lösa problemet genom att uttryckligen sortera efter partitionsnummer ASC i ORDER BY klausul:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Den här frågan returerar samma resultat (detta är inte ett feltryck eller ett kopierings-/klistrafel):
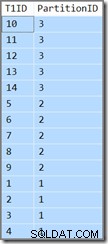
Partitions-id:t är fortfarande fallande ordning (ej stigande, som specificerat) och T1ID sorteras endast stigande inom varje partition. Sådan är optimerarens förvirring, den tror verkligen (ta ett djupt andetag nu) att genomsökning av det partitionerade indexet med ledande-nedåtgående nyckel i framåtriktning, men med omvända partitioner, kommer att resultera i den ordning som anges av frågan.
Jag skyller inte på det för att vara uppriktig, de olika sorteringsordningsövervägandena gör också att jag får ont i huvudet.
Som ett sista exempel, överväg:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Resultaten är:

Återigen, T1ID sorteringsordning inom varje partition är korrekt fallande, men själva partitionerna är listade bakåt (de går från 1 till 3 ner i raderna). Om partitionerna returnerades i omvänd ordning, skulle resultaten korrekt vara 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Tillbaka till Merge Join
Orsaken till de felaktiga resultaten med Merge Join-frågan är nu uppenbar:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
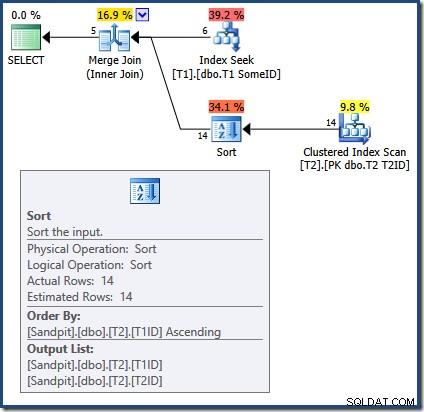
Merge Join kräver sorterade indata. Indata från T2 är uttryckligen sorterad efter T1TD så det är ok. Optimeraren motiverar felaktigt att indexet på T1 kan tillhandahålla rader i T1ID beställa. Som vi har sett är så inte fallet. Indexsökningen producerar samma utdata som en fråga vi redan har sett:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Endast de första 5 raderna finns i T1ID beställa. Nästa värde (5) är verkligen inte i stigande ordning, och Merge Join tolkar detta som end-of-stream snarare än att producera ett fel (personligen förväntade jag mig ett detaljhandelspåstående här). Hur som helst, effekten är att Merge Join felaktigt avslutar bearbetningen tidigt. Som en påminnelse är de (ofullständiga) resultaten:

Slutsats
Detta är en mycket allvarlig bugg enligt min åsikt. En enkel indexsökning kan returnera resultat som inte respekterar ORDER BY klausul. Mer till saken, optimerarens interna resonemang är helt trasigt för partitionerade icke-unika icke-klustrade index med en fallande inledande nyckel.
Ja, det här är en lite ovanligt arrangemang. Men som vi har sett kan korrekta resultat plötsligt ersättas av felaktiga resultat bara för att någon lagt till ett fallande index. Kom ihåg att det tillagda indexet såg oskyldigt ut:ingen explicit ASC/DESC nyckelfelmatchning och ingen explicit partitionering.
Felet är inte begränsat till Merge Joins. Eventuellt kan varje fråga som involverar en partitionerad tabell och som bygger på indexsorteringsordning (explicit eller implicit) falla offer. Denna bugg finns i alla versioner av SQL Server från 2008 till och med 2014 CTP 1. Windows SQL Azure Database stöder inte partitionering, så problemet uppstår inte. SQL Server 2005 använde en annan implementeringsmodell för partitionering (baserat på APPLY ) och lider inte av detta problem heller.
Om du har en stund, överväg att rösta på mitt Connect-objekt för detta fel.
Upplösning
Lösningen för det här problemet är nu tillgänglig och dokumenterad i en Knowledge Base-artikel. Observera att korrigeringen kräver en koduppdatering och spårningsflagga 4199 , vilket möjliggör en rad andra ändringar av frågeprocessorn. Det är ovanligt att ett fel med felaktiga resultat åtgärdas under 4199. Jag bad om förtydligande om det och svaret var:
Även om det här problemet involverar felaktiga resultat som andra snabbkorrigeringar som involverar frågeprocessorn har vi bara aktiverat denna korrigering under spårningsflagga 4199 för SQL Server 2008, 2008 R2 och 2012. Denna korrigering är dock "på" av standard utan spårningsflaggan i SQL Server 2014 RTM.