
Det här inlägget är en del av Oracle SQL tutorial och vi skulle diskutera analytiska funktioner i Oracle (Over by partition) med exempel, detaljerad förklaring.
Vi har redan studerat om Oracle Aggregate-funktion som avg ,sum ,count. Låt oss ta ett exempel
Låt oss först skapa exempeldata
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Nu kommer exemplet på aggregerade funktioner att ges enligt nedan
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Här kan vi se att det minskar antalet rader i var och en av frågorna. Nu kommer frågor vad vi ska göra om vi behöver ha alla rader returnerade med count(*) också
För det har oraklet tillhandahållit en uppsättning analytiska funktioner. Så för att lösa det sista problemet kan vi skriva som
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
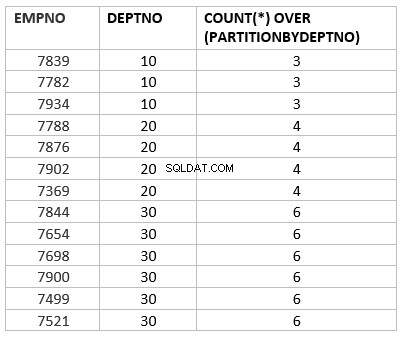
Här är count(*) over (partition by dept_no) den analytiska versionen av count aggregate-funktionen. Det huvudsakliga nyckelarbetet som skiljer sig genom aggregerad funktion är överpartition med
Analytiska funktioner beräknar ett aggregerat värde baserat på en grupp rader. De skiljer sig från aggregerade funktioner genom att de returnerar flera rader för varje grupp. Gruppen av rader kallas ett fönster och definieras av analytic_clausen.
Här är den allmänna syntaxen
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Exempel
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Låt oss gå igenom varje del
query_partition_clause
Det definierade gruppen av rader. Det kan gilla nedan
partition by deptno :grupp av rader av samma deptno
eller
() :Alla rader
SQL> select empno ,deptno , count(*) over () from emp;
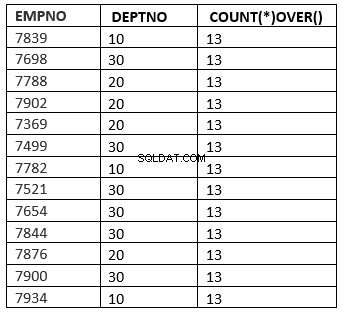
[ order_by_clause [ windowing_clause ] ]
Denna klausul används när du vill sortera raderna i partitionen. Detta är särskilt användbart om du vill att analytisk funktion ska beakta ordningen på raderna.
Exempel är funktionen radnummer
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
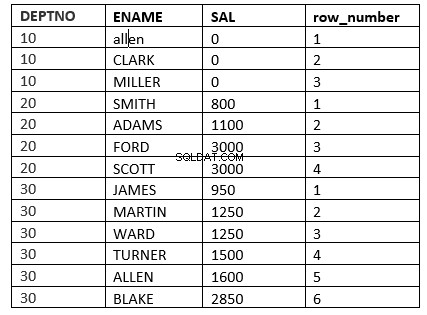
Ett annat exempel skulle vara
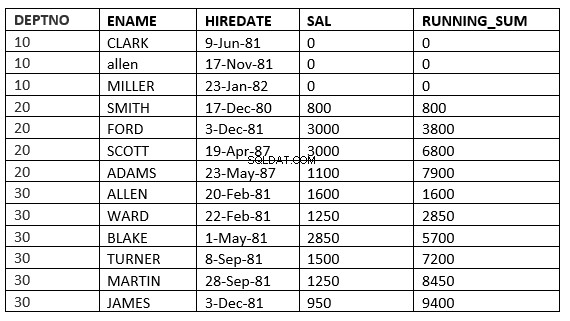
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
Detta används alltid med ordna efter klausul och ger mer kontroll över uppsättningen av rader i gruppen
Med Windowing-satsen, för varje rad, definieras ett glidande fönster med rader. Fönstret bestämmer radintervallet som används för att utföra beräkningarna för den aktuella raden. Fönsterstorlekar kan baseras på antingen ett fysiskt antal rader eller ett logiskt intervall som tid.
När du använder order by-sats och inget anges för windowing_clause, tas under standardvärdet för windowing_clausule
RANGE MELLAN UNBOUNDED PRECEDING OCH CURRENT ROW eller RANGE UNBOUNDED PRECEDING
Det betyder "Den nuvarande och föregående raderna i den aktuella partition är raderna som ska användas i beräkningen”
Exemplet nedan visar tydligt detta. Detta är det löpande genomsnittet på avdelningen
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
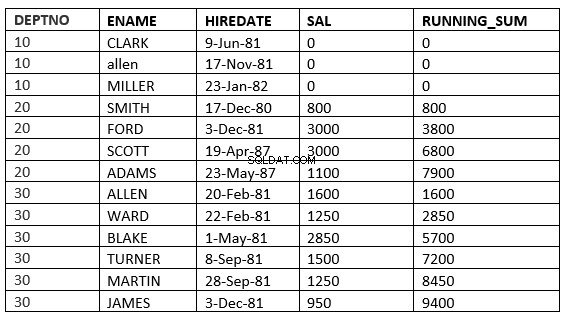
Nu kan windowing_clause definieras på flera sätt
Låt oss först förstå terminologin
RADER anger fönstret i fysiska enheter (rader).
RANGE anger fönstret som en logisk offset. RANGE-fönstersatssatsen kan endast användas med ORDER BY-satser som innehåller kolumner eller uttryck av numeriska eller datumdatatyper
PRECEDING – få rader före den nuvarande.
FÖLJER – få rader efter den aktuella.
OBEGRÄNSAD – när den används med PRECEDING eller FOLLOWING, återgår den allt före eller efter. AKTUELL RAD
Så det definieras generellt som
RADER OBEGRÄNSAD FÖREGÅENDE :De nuvarande och föregående raderna i den aktuella partitionen är de rader som ska användas i beräkningen
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
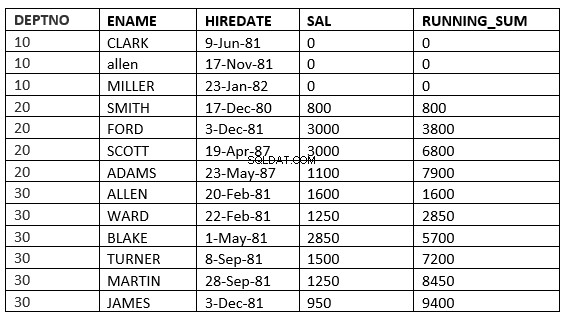
OMRÅDE OBEGRÄNSAT FÖREGÅENDE :De nuvarande och föregående raderna i den aktuella partitionen är de rader som ska användas i beräkningen. Eftersom intervallet är specificerat tar allt de värden som är lika med de aktuella raderna.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
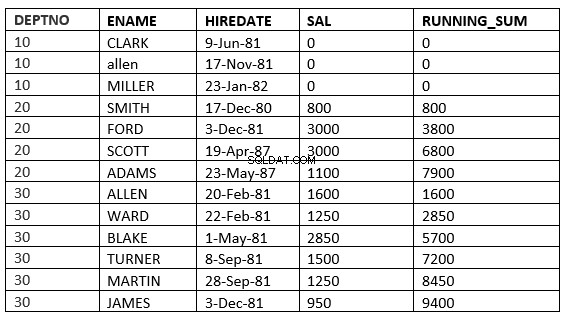
Du kanske inte ser skillnaden mellan intervall och rader eftersom hire_date är olika för alla. Skillnaden blir tydligare om vi använder sal som order by-klausul
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
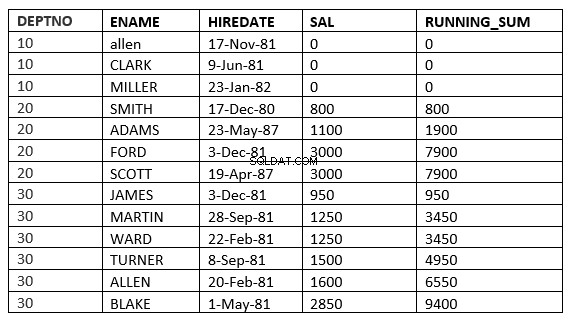
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
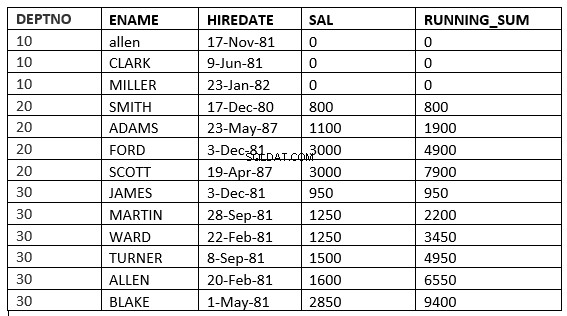
Du hittar skillnaden på rad 6
RANGE value_expr PRECEDING :Fönstret börjar med raden vars ORDER BY-värde är numeriska uttrycksrader mindre än, eller föregår, den aktuella raden och slutar med den aktuella raden som bearbetas.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
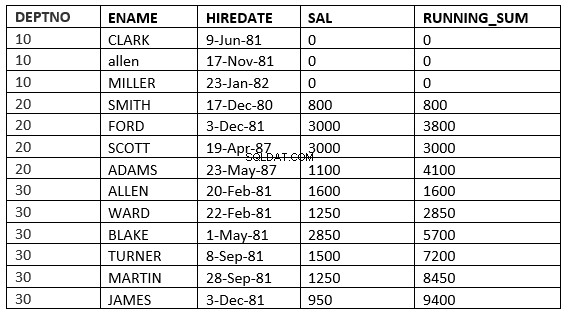
Här tar det alla rader där hyresdatumsvärdet faller inom 365 dagar före hyresdatumvärdet för den aktuella raden
ROWS value_expr PRECEDING :Fönstret börjar med den angivna raden och slutar med den aktuella raden som bearbetas
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
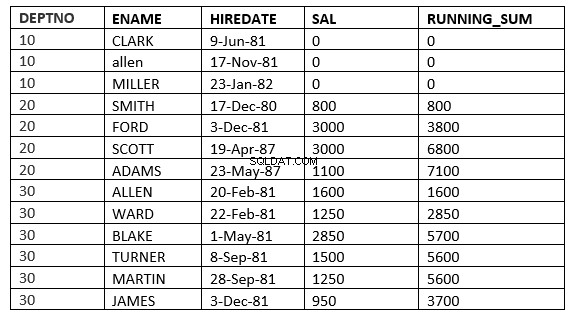
Här börjar fönstret från 2 rader före den aktuella raden
OMRÅDE MELLAN AKTUELL RAD och FÖLJANDE value_expr :Fönstret börjar med den aktuella raden och slutar med raden vars ORDER BY-värde är numeriska uttrycksrader mindre än eller följande
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
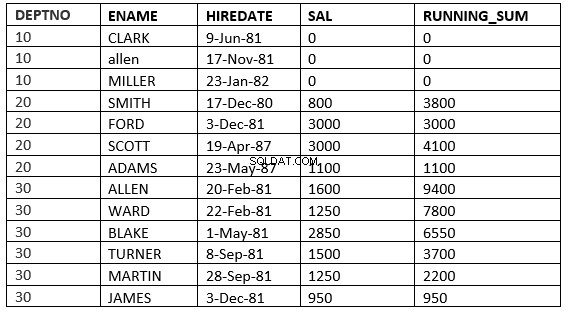
RADER MELLAN AKTUELL RAD och value_expr FÖLJER :Fönstret börjar med den aktuella raden och slutar med raderna efter den aktuella
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
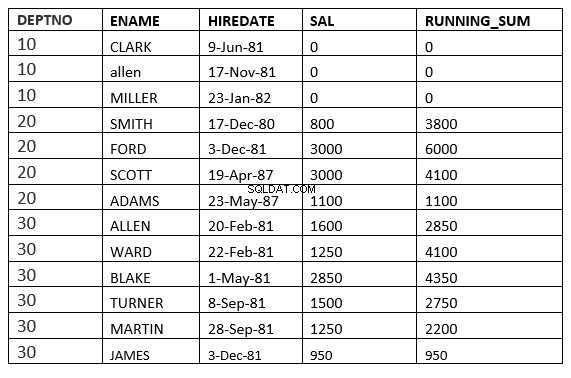
OMRÅDE MELLAN OBEGRÄNSAD FÖREGÅENDE och OBEGRÄNSAD FÖLJANDE
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
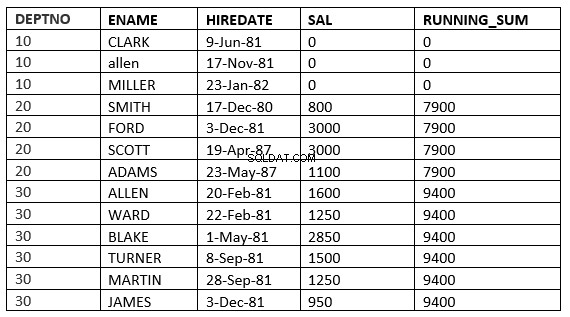
OMRÅDE MELLAN value_expr PRECEDING och value_expr FOLLOWING
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Några viktiga anmärkningar
(1)Analytiska funktioner är den sista uppsättningen operationer som utförs i en fråga förutom den sista ORDER BY-satsen. Alla joins och alla WHERE-, GROUP BY- och HAVING-satser är slutförda innan de analytiska funktionerna bearbetas. Därför kan analytiska funktioner endast visas i urvalslistan eller ORDER BY-satsen.
(2)Analytiska funktioner används vanligtvis för att beräkna kumulativa, rörliga, centrerade och rapporterande aggregat.
Jag hoppas att du gillar den här detaljerade förklaringen av analytiska funktioner i oracle (över av partitionsklausul)
Relaterade artiklar
LEAD-funktion i Oracle
DENSE-funktion i Oracle
Oracle LISTAGG-funktion
Aggregera data med hjälp av gruppfunktioner
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm