Partitionering är en SQL Server-funktion som ofta implementeras för att lindra utmaningar relaterade till hanterbarhet, underhållsuppgifter eller låsning och blockering. Administration av stora tabeller kan bli lättare med partitionering, och det kan förbättra skalbarhet och tillgänglighet. Dessutom kan en biprodukt av partitionering förbättras frågeprestanda. Det är inte en garanti eller givet, och det är inte den drivande orsaken till att implementera partitionering, men det är något som är värt att se över när du partitionerar ett stort bord.
Bakgrund
Som en snabb recension är SQL Server-partitioneringsfunktionen endast tillgänglig i Enterprise- och Developer Editions. Partitionering kan implementeras under den första databasdesignen, eller så kan den sättas på plats efter att en tabell redan har data i sig. Förstå att det inte alltid är snabbt och enkelt att ändra en befintlig tabell med data till en partitionerad tabell, men det är ganska genomförbart med god planering och fördelarna kan snabbt realiseras.
En partitionerad tabell är en där data separeras i mindre fysiska strukturer baserat på värdet för en specifik kolumn (kallad partitioneringskolumn, som definieras i partitionsfunktionen). Om du vill separera data efter år kan du använda en kolumn som heter DateSold som partitioneringskolumn, och all data för 2013 skulle finnas i en struktur, all data för 2012 skulle finnas i en annan struktur, etc. Dessa separata uppsättningar av data tillåta fokuserat underhåll (du kan bara bygga om en partition av ett index, snarare än hela indexet) och tillåta att data snabbt läggs till och tas bort eftersom de kan iscensättas innan de faktiskt läggs till eller tas bort från tabellen.
Inställningen
För att undersöka skillnaderna i frågeprestanda för en partitionerad kontra en icke-partitionerad tabell skapade jag två kopior av tabellen Sales.SalesOrderHeader från databasen AdventureWorks2012. Den icke-partitionerade tabellen skapades med endast ett klustrat index på SalesOrderID, den traditionella primärnyckeln för tabellen. Den andra tabellen var partitionerad på OrderDate, med OrderDate och SalesOrderID som klustringsnyckel, och hade inga ytterligare index. Observera att det finns många faktorer att ta hänsyn till när du bestämmer vilken kolumn som ska användas för partitionering. Partitionering använder ofta, men absolut inte alltid, ett datumfält för att definiera partitionsgränserna. Som sådan valdes OrderDate för det här exemplet, och exempelfrågor användes för att simulera typisk aktivitet mot SalesOrderHeader-tabellen. Uttrycken för att skapa och fylla i båda tabellerna kan laddas ner här.
Efter att ha skapat tabellerna och lagt till data, verifierades de befintliga indexen och statistiken uppdaterades sedan med FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Dessutom har båda tabellerna exakt samma datafördelning och minimal fragmentering.
Prestanda för en enkel fråga
Innan några ytterligare index lades till utfördes en grundläggande fråga mot båda tabellerna för att beräkna totalsummor som tjänats in av säljare för beställningar som gjordes i december 2012:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSTATISTIK IO OUTPUT
Tabell 'Arbetsbord'. Scan count 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Big_SalesOrderHeader'. Scan count 9, logiskt läser 2710440, fysiskt läser 2226, läs framåt läser 2658769, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'Arbetsbord'. Scan count 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Part_SalesOrderHeader'. Skanningsantal 9, logiskt läser 248128, fysiskt läser 3, läser framåt läser 245030, lob logiskt läser 0, lob fysiskt läser 0, lob läser framåt läser 0.

Total per säljare för december – icke-uppdelat bord
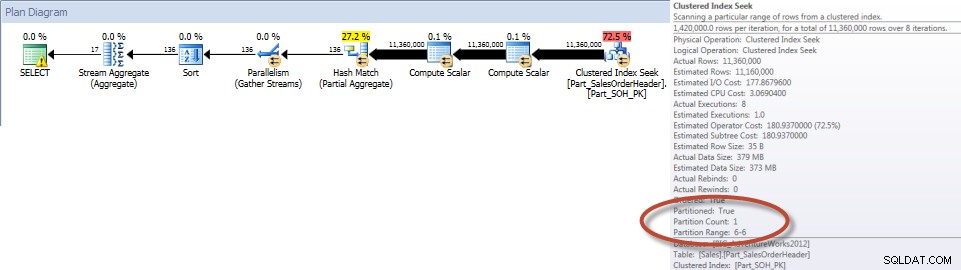
Total efter säljare för december – partitionerad tabell
Som väntat var frågan mot den icke-partitionerade tabellen tvungen att utföra en fullständig genomsökning av tabellen eftersom det inte fanns något index som stödde den. Däremot behövde frågan mot den partitionerade tabellen bara för att komma åt en partition i tabellen.
För att vara rättvis, om detta var en fråga som körs upprepade gånger med olika datumintervall, skulle det lämpliga icke-klustrade indexet finnas. Till exempel:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Med det här indexet skapat, när frågan körs om, sjunker I/O-statistiken och planen ändras för att använda det icke-klustrade indexet:
STATISTIK IO OUTPUT
Tabell 'Arbetsbord'. Scan count 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Big_SalesOrderHeader'. Scan count 9, logisk läser 42901, fysisk läser 3, läs framåt läser 42346, lob logisk läser 0, lob fysisk läser 0, lob läser framåt läser 0.

Total per säljare för december – NCI på icke-uppdelat bord
Med ett stödjande index kräver frågan mot Sales.Big_SalesOrderHeader betydligt färre läsningar än den klustrade indexskanningen mot Sales.Part_SalesOrderHeader, vilket inte är oväntat eftersom det klustrade indexet är mycket bredare. Om vi skapar ett jämförbart icke-klustrat index för Sales.Part_SalesOrderHeader ser vi liknande I/O-nummer:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATISTIK IO OUTPUT
Tabell 'Part_SalesOrderHeader'. Skanningsantal 9, logiskt läser 42894, fysiskt läser 1, läs framåt läser 42378, lob logiskt läser 0, lob fysiskt läser 0, lob läser framåt läser 0.
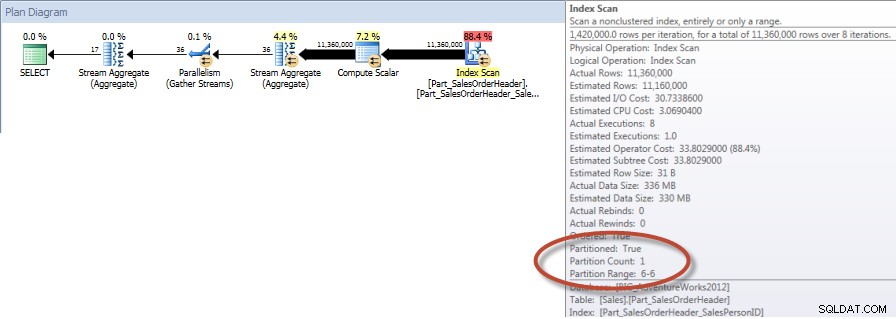
Total per säljare för december – NCI på partitionerad tabell med eliminering
Och om vi tittar på egenskaperna för den icke-klustrade Index Scan, kan vi verifiera att motorn endast har åtkomst till en partition (6).
Som nämnts ursprungligen implementeras inte partitionering vanligtvis för att förbättra prestandan. I exemplet som visas ovan fungerar inte frågan mot den partitionerade tabellen nämnvärt bättre så länge det lämpliga icke-klustrade indexet finns.
Prestanda för en ad hoc-fråga
En fråga mot den partitionerade tabellen kan överträffa samma fråga mot den icke-partitionerade tabellen i vissa fall, till exempel när frågan måste använda det klustrade indexet. Även om det är idealiskt att ha de flesta frågor som stöds av icke-klustrade index, tillåter vissa system ad-hoc-frågor från användare, och andra har frågor som kan köras så sällan att de inte kräver stödjande index. Mot tabellen SalesOrderHeader kan en användare köra följande fråga för att hitta beställningar från december 2012 som behövde skickas i slutet av året men inte gjorde det, för en viss uppsättning kunder och med en TotalDue större än $1000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSTATISTIK IO OUTPUT
Tabell 'Big_SalesOrderHeader'. Scan count 9, logiskt läser 2711220, fysiskt läser 8386, read-ahead läser 2662400, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Part_SalesOrderHeader'. Skanningsantal 9, logiskt läser 248128, fysiskt läser 0, läs framåt läser 243792, lob logiskt läser 0, lob fysiskt läser 0, lob läser framåt läser 0.
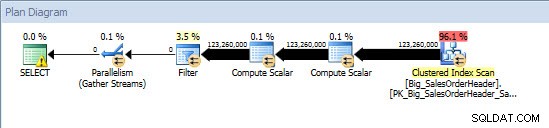
Ad-Hoc-fråga – icke-partitionerad tabell
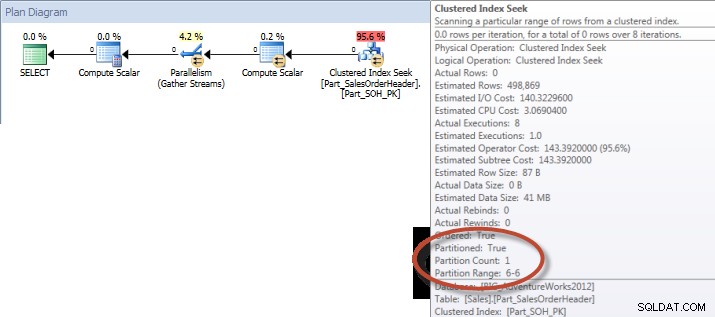
Ad-Hoc-fråga – partitionerad tabell
Mot den icke-partitionerade tabellen krävde frågan en fullständig genomsökning mot det klustrade indexet, men mot den partitionerade tabellen utförde frågan en indexsökning av det klustrade indexet, eftersom motorn använde partitionseliminering och bara läste den data den absolut behövde. I det här exemplet är det en betydande skillnad när det gäller I/O, och beroende på hårdvaran kan det vara en dramatisk skillnad i exekveringstid. Frågan kan optimeras genom att lägga till lämpligt index, men det är vanligtvis inte möjligt att indexera för varje singel fråga. I synnerhet för lösningar som tillåter ad-hoc-frågor är det rimligt att säga att du aldrig vet vad användarna kommer att göra. En fråga kan köras en gång och aldrig köras igen, och att skapa ett index i efterhand är meningslöst. Därför, när du byter från en icke-partitionerad tabell till en partitionerad tabell, är det viktigt att använda samma ansträngning och tillvägagångssätt som vanlig indexjustering; du vill verifiera att lämpliga index finns för att stödja majoriteten av frågorna.
Prestanda och indexjustering
En ytterligare faktor att tänka på när man skapar index för en partitionerad tabell är om man ska justera indexet eller inte. Index måste anpassas till tabellen om du planerar att byta data in och ut från partitioner. Genom att skapa ett icke-klustrat index på en partitionerad tabell skapas ett justerat index som standard, där partitioneringskolumnen läggs till som en inkluderad kolumn i indexet.
Ett icke-justerat index skapas genom att ange ett annat partitionsschema eller en annan filgrupp. Partitioneringskolumnen kan vara en del av indexet som en nyckelkolumn eller en inkluderad kolumn, men om tabellens partitionsschema inte används, eller en annan filgrupp används, kommer indexet inte att justeras.
Ett justerat index partitioneras precis som tabellen – data kommer att finnas i separata strukturer – och därför kan partitionseliminering inträffa. Ett ojusterat index existerar som en fysisk struktur och kanske inte ger den förväntade fördelen för en fråga, beroende på predikatet. Tänk på en fråga som räknar försäljningen efter kontonummer, grupperad efter månad:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Om du inte är så bekant med partitionering kan du skapa ett index som detta för att stödja frågan (observera att den PRIMÄRA filgruppen är specificerad):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Detta index är inte justerat, även om det inkluderar OrderDate eftersom det är en del av primärnyckeln. Kolumnerna ingår också om vi skapar ett justerat index, men notera skillnaden i syntax:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Vi kan verifiera vilka kolumner som finns i indexet med hjälp av Kimberly Tripps sp_helpindex:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex for Sales.Part_SalesOrderHeader
När vi kör vår fråga och tvingar den att använda det icke-justerade indexet, skannas hela indexet. Även om OrderDate är en del av indexet är det inte den ledande kolumnen så motorn måste kontrollera OrderDate-värdet för varje AccountNumber för att se om det infaller mellan 1 januari 2013 och 31 juli 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK IO OUTPUT
Tabell 'Arbetsbord'. Scan count 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Part_SalesOrderHeader'. Skanningsantal 9, logiskt läser 786861, fysiskt läser 1, läser framåt 770929, lob logiskt läser 0, lob fysiskt läser 0, lob läser framåt läser 0.
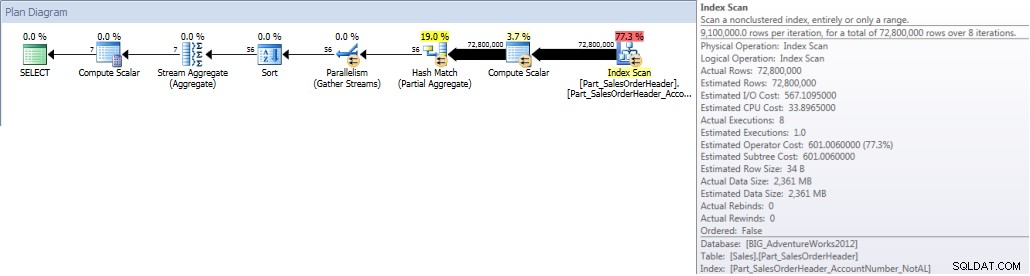
Kontosummor per månad (januari – juli 2013) med icke- Justerad NCI (tvingad)
Däremot, när frågan tvingas använda det justerade indexet, kan partitionseliminering användas och färre I/O krävs, även om OrderDate inte är en ledande kolumn i indexet.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK IO OUTPUT
Tabell 'Arbetsbord'. Scan count 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Part_SalesOrderHeader'. Scan count 9, logiskt läser 456258, fysiskt läser 16, läs framåt läser 453241, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
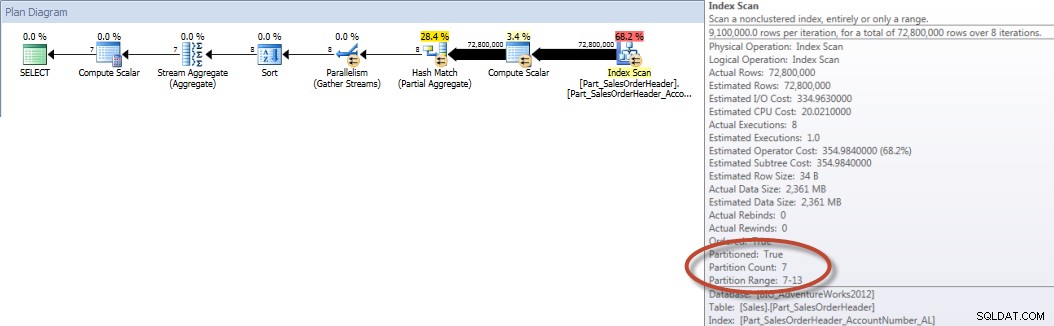
Kontosummor per månad (januari – juli 2013) med anpassad NCI (tvingad)
Sammanfattning
Beslutet att genomföra avskiljning är ett som kräver vederbörlig hänsyn och planering. Enkel hantering, förbättrad skalbarhet och tillgänglighet och en minskning av blockering är vanliga skäl till att partitionera tabeller. Att förbättra frågeprestanda är inte en anledning att använda partitionering, även om det kan vara en fördelaktig bieffekt i vissa fall. När det gäller prestanda är det viktigt att se till att din implementeringsplan innehåller en granskning av frågeprestanda. Bekräfta att dina index fortsätter att stödja dina frågor efter tabellen är partitionerad och verifiera att frågor som använder de klustrade och icke-klustrade indexen drar fördel av partitionseliminering där så är tillämpligt.