PostgreSQL-strömningsreplikering är ett utmärkt sätt att skala PostgreSQL-kluster och att göra det ger dem hög tillgänglighet. Som med varje replikering är tanken att slaven är en kopia av mastern och att slaven ständigt uppdateras med de ändringar som hände på mastern med hjälp av någon form av replikeringsmekanism.
Det kan hända att slaven av någon anledning blir ur synk med mastern. Hur kan jag ta tillbaka det till replikeringskedjan? Hur kan jag säkerställa att slaven åter är synkroniserad med mastern? Låt oss ta en titt i det här korta blogginlägget.
Vad är mycket användbart, det finns inget sätt att skriva på en slav om den är i återställningsläge. Du kan testa det så här:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionDet kan fortfarande hända att slaven skulle gå ur synk med mastern. Datakorruption - varken hårdvara eller mjukvara är utan buggar och problem. Vissa problem med hårddisken kan utlösa datakorruption på slaven. Vissa problem med "vakuum"-processen kan leda till att data ändras. Hur återhämtar man sig från det tillståndet?
Återbygga slaven med pg_basebackup
Huvudsteget är att tillhandahålla slaven med hjälp av data från mastern. Med tanke på att vi kommer att använda strömmande replikering kan vi inte använda logisk säkerhetskopiering. Lyckligtvis finns det ett färdigt verktyg som kan användas för att ställa in saker:pg_basebackup. Låt oss se vilka steg vi måste ta för att tillhandahålla en slavserver. För att göra det tydligt använder vi PostgreSQL 12 för syftet med detta blogginlägg.
Initialtillståndet är enkelt. Vår slav replikerar inte från sin herre. Data som den innehåller är skadad och kan inte användas eller lita på. Därför är det första steget vi kommer att göra att stoppa PostgreSQL på vår slav och ta bort data den innehåller:
example@sqldat.com:~# systemctl stop postgresqlEller till och med:
example@sqldat.com:~# killall -9 postgresLåt oss nu kontrollera innehållet i postgresql.auto.conf-filen, vi kan använda replikeringsuppgifter som lagras i den filen senare, för pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Vi är intresserade av användaren och lösenordet som används för att ställa in replikeringen.
Äntligen är vi ok att ta bort data:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*När data har tagits bort måste vi använda pg_basebackup för att hämta data från mastern:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointFlaggorna som vi använde har följande betydelse:
- -Xs: vi vill streama WAL medan säkerhetskopian skapas. Detta hjälper till att undvika problem med att ta bort WAL-filer när du har en stor datamängd.
- -P: vi skulle vilja se hur säkerhetskopieringen fortskrider.
- -R: vi vill att pg_basebackup ska skapa standby.signal-fil och förbereda postgresql.auto.conf-fil med anslutningsinställningar.
pg_basebackup väntar på kontrollpunkten innan säkerhetskopieringen påbörjas. Om det tar för lång tid kan du använda två alternativ. Först är det möjligt att ställa in kontrollpunktsläget till snabb i pg_basebackup med alternativet "-c fast". Alternativt kan du tvinga fram kontrollpunkter genom att utföra:
postgres=# CHECKPOINT;
CHECKPOINTPå ett eller annat sätt kommer pg_basebackup att starta. Med flaggan -P kan vi spåra framstegen:
416906/1588478 kB (26%), 0/1 tablespaceceaceNär säkerhetskopieringen är klar är allt vi behöver göra att se till att datakataloginnehållet har rätt användare och grupp tilldelad - vi körde pg_basebackup som 'root' därför vill vi ändra det till 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Det är allt, vi kan starta slaven och den bör börja replikera från mastern.
example@sqldat.com:~# systemctl start postgresqlDu kan dubbelkontrollera replikeringsförloppet genom att köra följande fråga på mastern:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Som du kan se replikerar båda slavarna korrekt.
Återbygga slaven med ClusterControl
Om du är en ClusterControl-användare kan du enkelt uppnå exakt samma sak bara genom att välja ett alternativ från användargränssnittet.
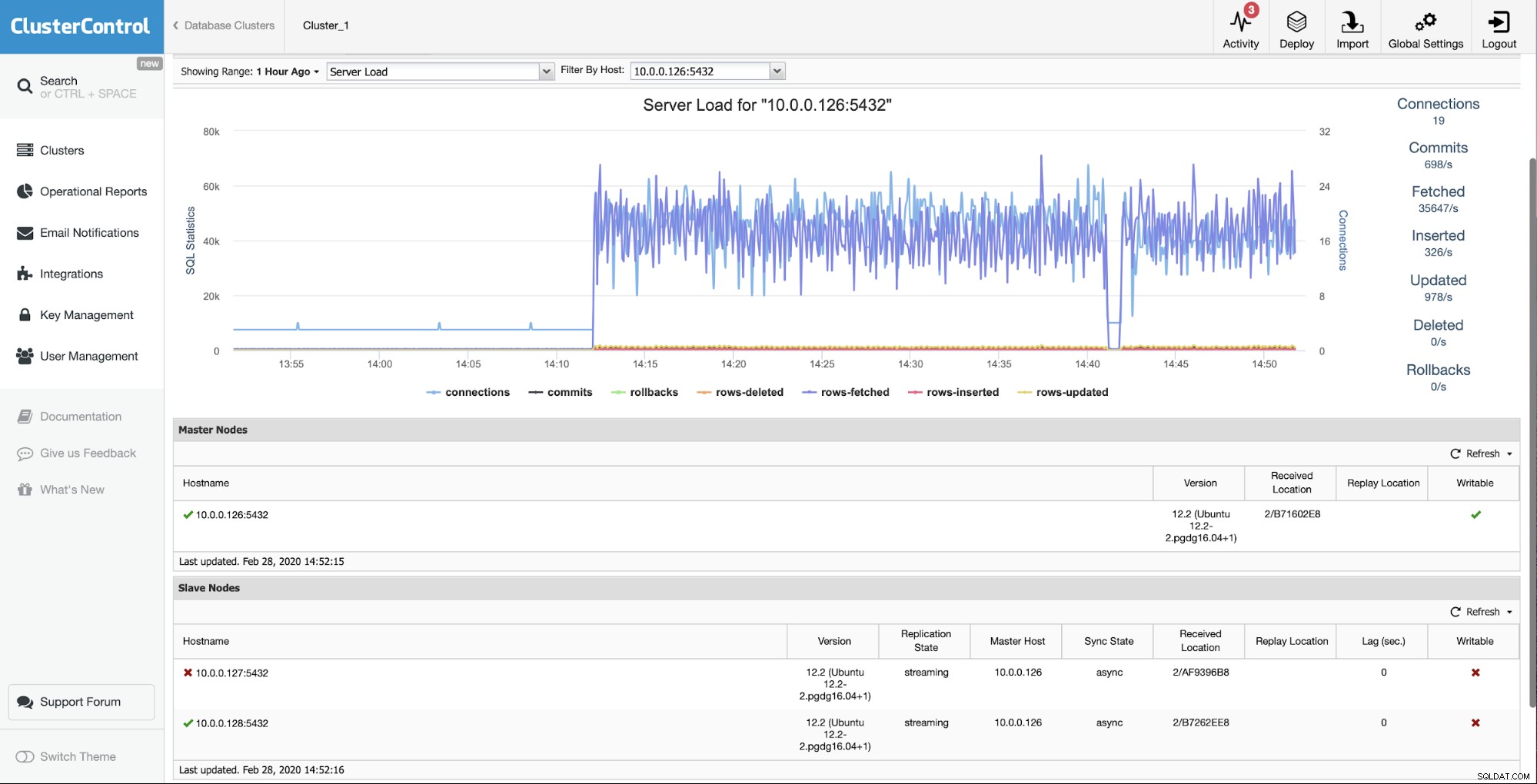
Utgångssituationen är att en av slavarna (10.0.0.127) är fungerar inte och det replikerar inte. Vi ansåg att ombyggnaden var det bästa alternativet för oss.
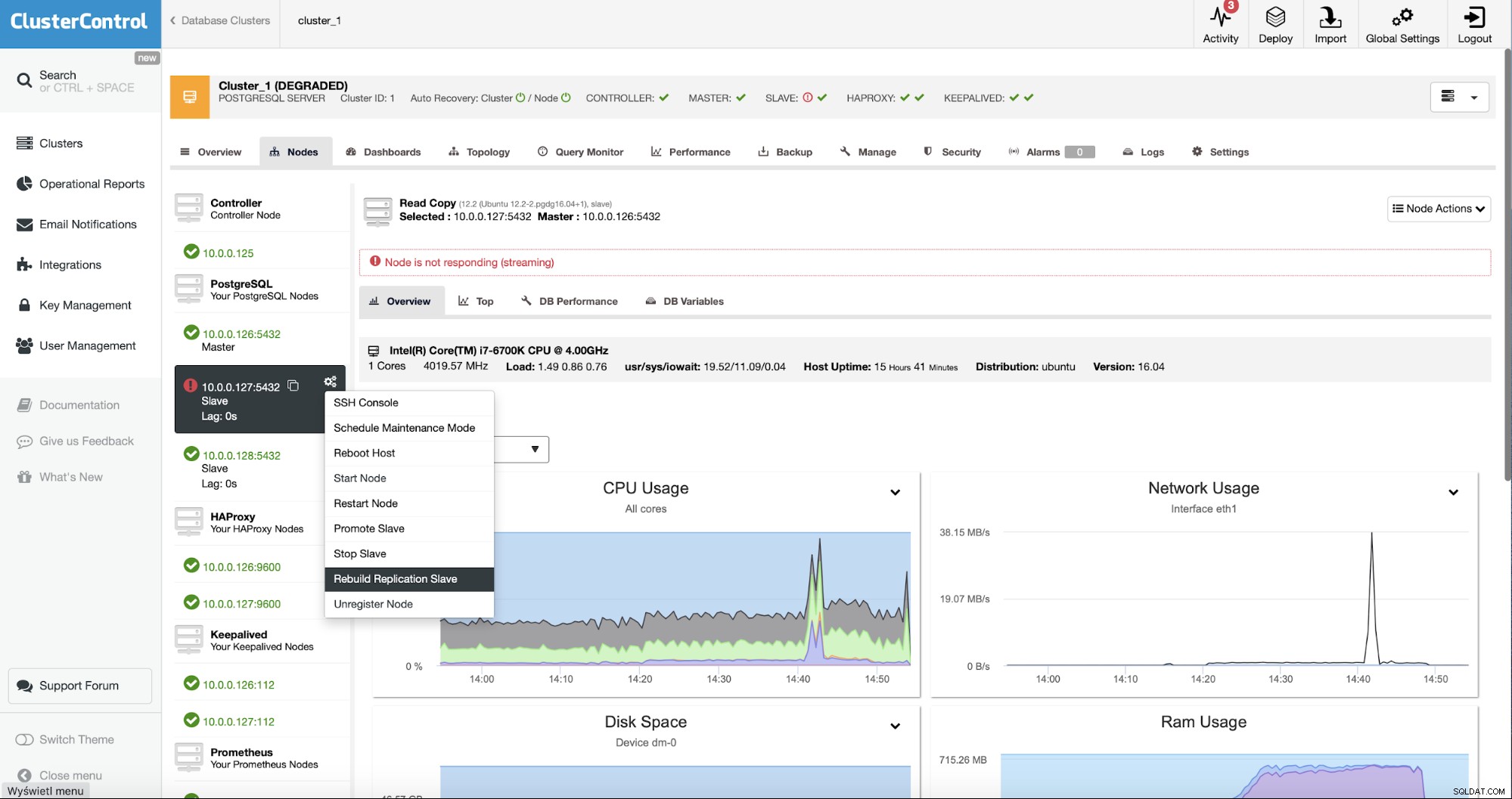
Som ClusterControl-användare behöver vi bara gå till "Noder" " och kör "Rebuild Replication Slave"-jobbet.
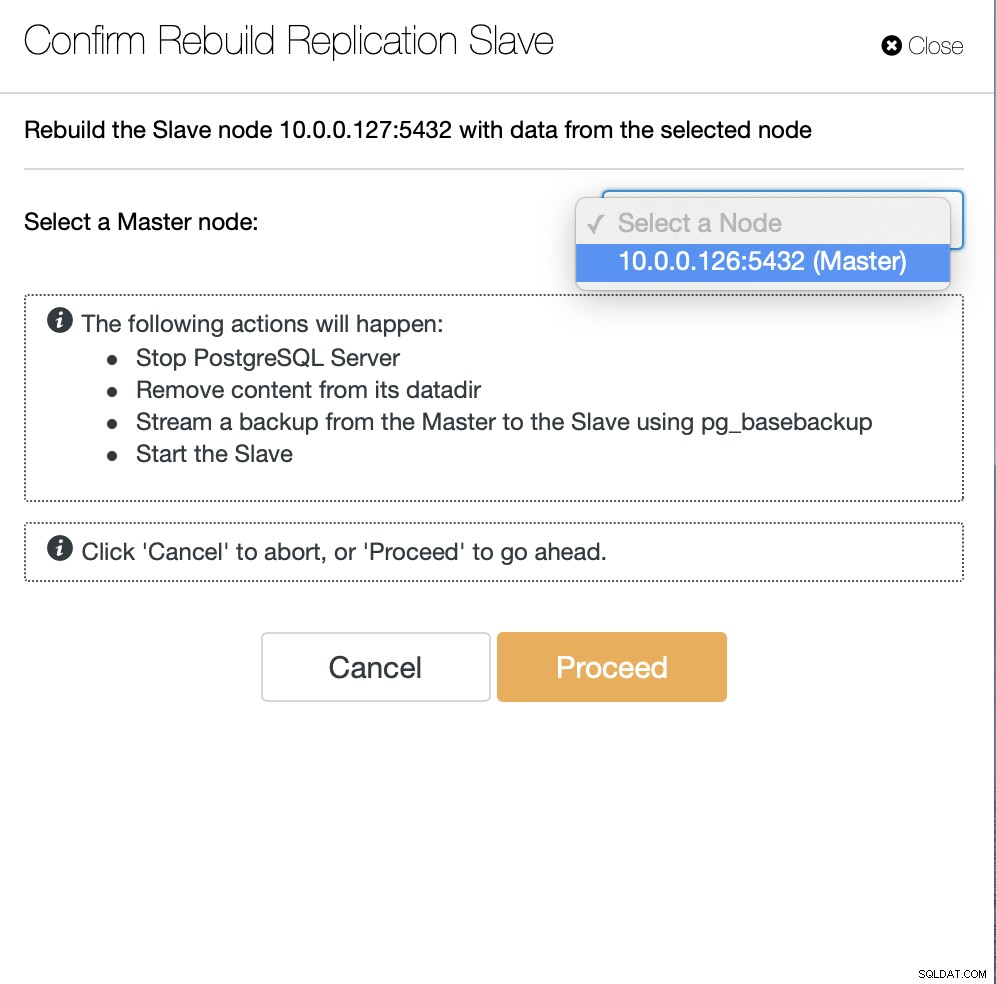
Närnäst måste vi välja noden att bygga om slav från och det är Allt. ClusterControl kommer att använda pg_basebackup för att konfigurera replikeringsslaven och konfigurera replikeringen så snart data överförs.
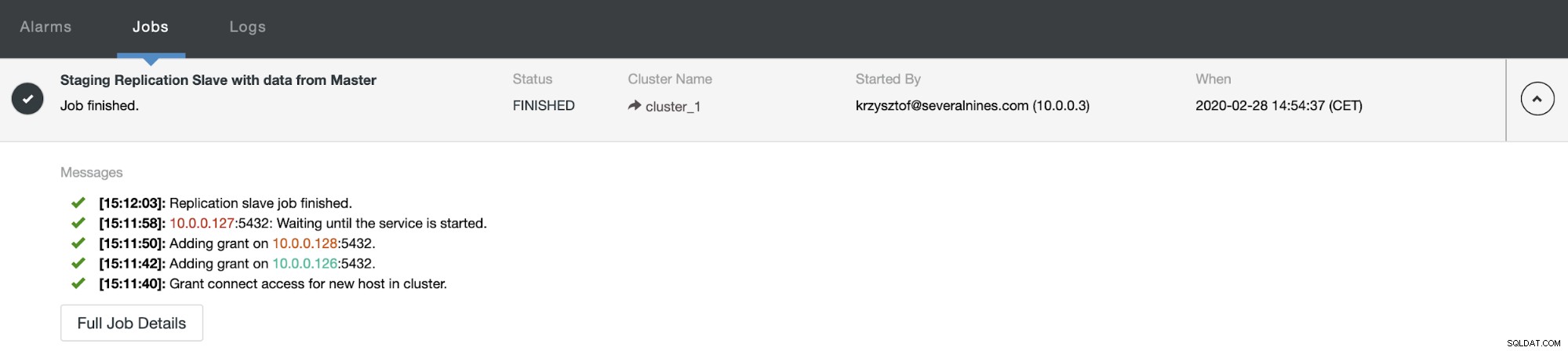
Efter en tid slutförs jobbet och slaven är tillbaka i replikeringskedjan:
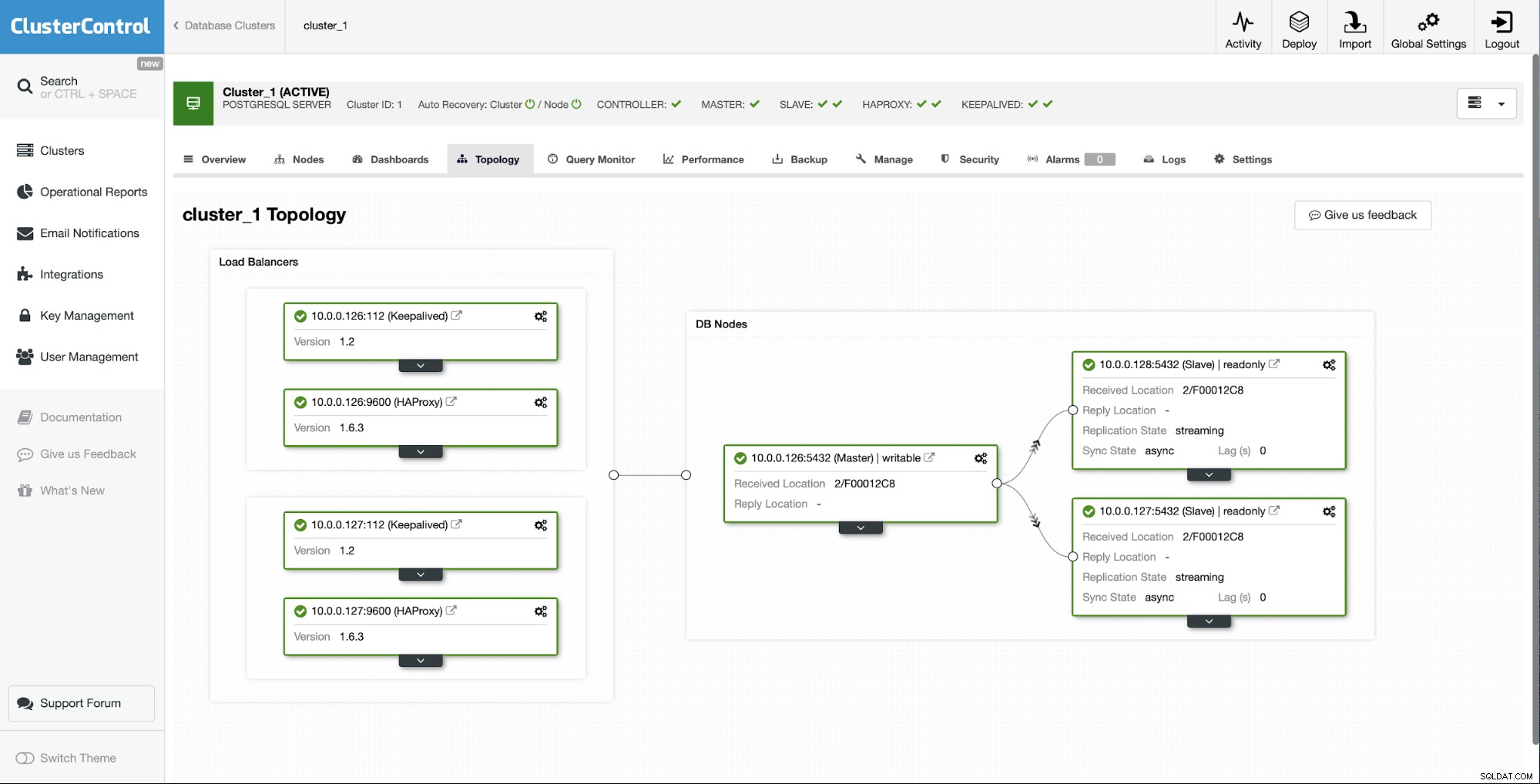
Som du kan se, med bara ett par klick, tack vare ClusterControl, lyckades vi bygga om vår misslyckade slav och föra tillbaka den till klustret.