Det är mycket lätt att bevisa att följande två uttryck ger exakt samma resultat:den första dagen i innevarande månad.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); Och de tar ungefär lika lång tid att beräkna:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
På mitt system tog båda batcherna cirka 175 sekunder att slutföra.
Så varför skulle du föredra den ena metoden framför den andra? När en av dem verkligen bråkar med kardinalitetsuppskattningar .
Som en snabb primer, låt oss jämföra dessa två värden:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Observera att de faktiska värdena som representeras här kommer att ändras, beroende på när du läser det här inlägget – "idag" som refereras i kommentaren är den 5 september 2013, dagen då detta inlägg skrevs. I oktober 2013, till exempel, kommer resultatet att vara 2013-10-01 och 1786-04-01 .)
Med det ur vägen, låt mig visa dig vad jag menar...
En repro
Låt oss skapa en mycket enkel tabell, med bara en klustrad DATE kolumn och ladda 15 000 rader med värdet 1786-05-01 och 50 rader med värdet 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
Och låt oss sedan titta på de faktiska planerna för dessa två frågor:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
De grafiska planerna ser rätt ut:
Grafisk plan för DATEDIFF(MONTH, 0, GETDATE()) fråga
Grafisk plan för DATEDIFF(MONTH, GETDATE(), 0) fråga
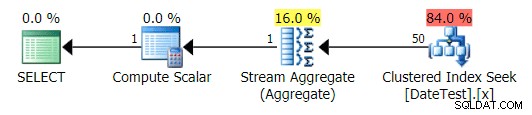
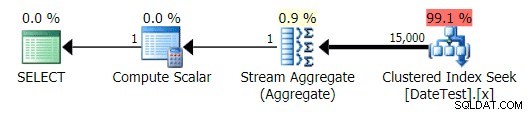
Men de uppskattade kostnaderna är ur spel – notera hur mycket högre de uppskattade kostnaderna är för den första frågan, som bara returnerar 50 rader, jämfört med den andra frågan, som returnerar 15 000 rader!

Utdragsrutnät som visar beräknade kostnader
Och fliken Top Operations visar att den första frågan (som letar efter 2013-09-01 ) uppskattade att den skulle hitta 15 000 rader, när den i själva verket bara hittade 50; den andra frågan visar motsatsen:den förväntas hitta 50 rader som matchar 1786-05-01 , men hittade 15 000. Baserat på felaktiga kardinalitetsuppskattningar som denna, är jag säker på att du kan föreställa dig vilken typ av drastisk effekt detta kan ha på mer komplexa frågor mot mycket större datamängder.
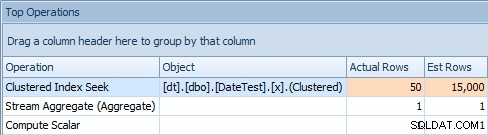
Översta operationsfliken för första frågan [DATEDIFF(MONTH, 0, GETDATE())]
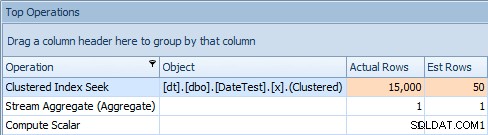
Översta operationsfliken för den andra frågan [DATEDIFF(MONTH, 0, GETDATE())]
En något annorlunda variant av frågan, med användning av ett annat uttryck för att beräkna början av månaden (anspelad i början av inlägget), uppvisar inte detta symptom:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
Planen är mycket lik fråga 1 ovan, och om du inte tittade närmare skulle du tro att dessa planer är likvärdiga:
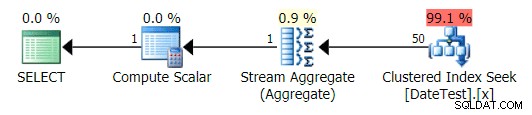
Grafisk plan för icke-DATEDIFF-fråga
När du tittar på fliken Top Operations här ser du dock att uppskattningen är pang på:
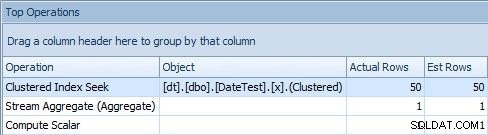
Översta Fliken Operations som visar korrekta uppskattningar
För denna specifika datastorlek och fråga är nettoprestandapåverkan (främst varaktighet och läsningar) i stort sett irrelevant. Och det är viktigt att notera att frågorna i sig fortfarande returnerar korrekt data; det är bara att uppskattningarna är fel (och kan leda till en sämre plan än jag har visat här). Som sagt, om du härleder konstanter med DATEDIFF i dina frågor på det här sättet borde du verkligen testa denna påverkan i din miljö.
Så varför händer detta?
Enkelt uttryckt har SQL Server en DATEDIFF bugg där det byter ut det andra och det tredje argumentet vid utvärdering av uttrycket för kardinalitetsuppskattning. Detta verkar involvera konstant vikning, åtminstone perifert; det finns mycket mer information om konstant vikning i denna Books Online-artikel, men tyvärr avslöjar inte artikeln någon information om just denna bugg.
Det finns en åtgärd – eller finns det?
Det finns en kunskapsbasartikel (KB #2481274) som påstår sig lösa problemet, men den har några egna problem:
- KB-artikeln hävdar att problemet har åtgärdats i olika servicepack eller kumulativa uppdateringar för SQL Server 2005, 2008 och 2008 R2. Symptomet är dock fortfarande närvarande i grenar som inte uttryckligen nämns där, även om de har sett många ytterligare CUs sedan artikeln publicerades. Jag kan fortfarande återskapa det här problemet på SQL Server 2008 SP3 CU #8 (10.0.5828) och SQL Server 2012 SP1 CU #5 (11.0.3373).
- Den försummar att nämna att du, för att dra nytta av korrigeringen, måste aktivera spårningsflagga 4199 (och "dra nytta" av alla andra sätt som specifik spårningsflagga kan påverka optimeraren). Det faktum att denna spårningsflagga krävs för fixen nämns i ett relaterat Connect-objekt, #630583, men denna information har inte kommit tillbaka till KB-artikeln. Varken KB-artikeln eller Connect-objektet ger någon insikt i orsaken (att argumenten till
DATEDIFFhar bytts ut under utvärderingen). På plussidan, kör ovanstående frågor med spårningsflaggan på (medOPTION (QUERYTRACEON 4199)) ger planer som inte har fel uppskattning.
- Det föreslår att du använder dynamisk SQL för att komma runt problemet. I mina tester använder jag ett annat uttryck (som det ovan som inte använder
DATEDIFF) övervann problemet i moderna versioner av både SQL Server 2008 och SQL Server 2012. Att rekommendera dynamisk SQL här är onödigt komplext och förmodligen överdrivet, med tanke på att ett annat uttryck skulle kunna lösa problemet. Men om du skulle använda dynamisk SQL, skulle jag göra det så här istället för som de rekommenderar i KB-artikeln, viktigast av allt för att minimera SQL-injektionsrisker:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(Och du kan lägga till
OPTION (RECOMPILE)där, beroende på hur du vill att SQL Server ska hantera parametersniffning.)Detta leder till samma plan som den tidigare frågan som inte använder
DATEDIFF, med korrekta uppskattningar och 99,1 % av kostnaden i den klustrade indexsökningen.Ett annat tillvägagångssätt som kan fresta dig (och med dig, jag menar mig, när jag först började undersöka) är att använda en variabel för att beräkna värdet i förväg:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
Problemet med detta tillvägagångssätt är att med en variabel kommer du att sluta med en stabil plan, men kardinaliteten kommer att baseras på en gissning (och typen av gissning kommer att bero på närvaron eller frånvaron av statistik) . I det här fallet är här de uppskattade kontra faktiska:
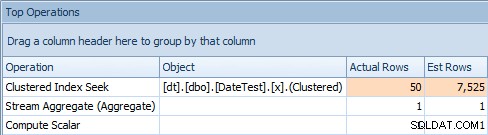
Översta operationsfliken för fråga som använder en variabelDetta är helt klart inte rätt; det verkar som att SQL Server har gissat att variabeln skulle matcha 50 % av raderna i tabellen.
SQL Server 2014
Jag hittade ett lite annorlunda problem i SQL Server 2014. De två första frågorna är fixade (genom ändringar av kardinalitetsuppskattaren eller andra korrigeringar), vilket betyder att DATEDIFF argument ändras inte längre. Jippie!
En regression verkar dock ha introducerats för lösningen av att använda ett annat uttryck – nu lider det av en felaktig uppskattning (baserat på samma 50 % gissning som att använda en variabel). Det här är frågorna jag körde:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Här är ett utdragsrutnät som jämför de uppskattade kostnaderna och faktiska körtidsmått:
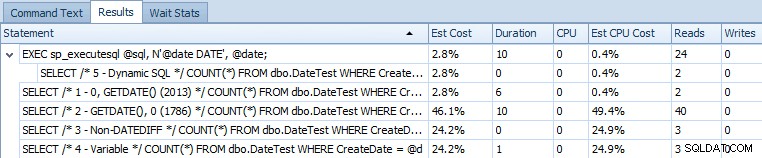
Uppskattade kostnader för de 5 exemplaren av frågorna på SQL Server 2014
Och det här är deras uppskattade och faktiska radantal (sammansatt med Photoshop):

Uppskattade och faktiska radantal för de 5 frågorna på SQL Server 2014
Det framgår av denna utgång att uttrycket som tidigare löste problemet nu har infört ett annat. Jag är inte säker på om detta är ett symptom på att köra i en CTP (t.ex. något som kommer att fixas) eller om detta verkligen är en regression.
I detta fall har spårningsflagga 4199 (ensamt) ingen effekt; den nya kardinalitetskalkylatorn gör gissningar och är helt enkelt inte korrekt. Huruvida det leder till ett verkligt prestandaproblem beror mycket på många andra faktorer utanför ramen för detta inlägg.
Om du stöter på det här problemet kan du – åtminstone i nuvarande CTP:er – återställa det gamla beteendet med OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . Spårningsflagga 9481 inaktiverar den nya kardinalitetsuppskattaren, som beskrivs i dessa utgåvor (som säkerligen kommer att försvinna eller åtminstone flytta någon gång). Detta återställer i sin tur de korrekta uppskattningarna för icke-DATEDIFF version av frågan, men löser tyvärr fortfarande inte problemet där en gissning görs baserad på en variabel (och med enbart TF9481, utan TF4199, tvingar de två första frågorna att gå tillbaka till det gamla argumentbytesbeteendet).
Slutsats
Jag ska erkänna att detta var en stor överraskning för mig. Kudos till Martin Smith och t-clausen.dk för att de höll ut och övertygade mig om att detta var en verklig och inte en inbillad fråga. Också ett stort tack till Paul White (@SQL_Kiwi) som hjälpte mig att hålla mitt förstånd och påminde mig om saker jag inte borde säga. :-)
Eftersom jag var omedveten om denna bugg, var jag övertygad om att den bättre frågeplanen skapades helt enkelt genom att ändra frågetexten alls, inte på grund av den specifika förändringen. Som det visar sig, ibland en ändring av en fråga som du skulle anta kommer inte att göra någon skillnad, faktiskt. Så jag rekommenderar att om du har några liknande frågemönster i din miljö, testar du dem och ser till att uppskattningar av kardinalitet kommer ut korrekt. Och notera att du testar dem igen när du uppgraderar.