Det finns två kompletterande färdigheter som är mycket användbara vid sökning av frågor. En är förmågan att läsa och tolka genomförandeplaner. Det andra är att veta lite om hur frågeoptimeraren fungerar för att översätta SQL-text till en exekveringsplan. Att sätta ihop de två sakerna kan hjälpa oss att upptäcka tidpunkter då en förväntad optimering inte tillämpades, vilket resulterar i en genomförandeplan som inte är så effektiv som den skulle kunna vara. Bristen på dokumentation kring exakt vilka optimeringar SQL Server kan tillämpa (och under vilka omständigheter) gör att mycket av detta beror på erfarenhet.
Ett exempel
Exempelfrågan för den här artikeln är baserad på en fråga som ställdes av SQL Server MVP Fabiano Amorim för några månader sedan, baserat på ett verkligt problem som han stötte på. Schemat och testfrågan nedan är en förenkling av den verkliga situationen, men den behåller alla viktiga funktioner.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Testa 1 – 10 000 rader, SQL Server 2005+
De specifika tabelldata spelar egentligen ingen roll för dessa tester. Följande frågor laddar helt enkelt 10 000 rader från en taltabell till var och en av de tre testtabellerna:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Med datan inläst är exekveringsplanen som skapats för testfrågan:
SELECT MAX(c1) FROM dbo.V1;
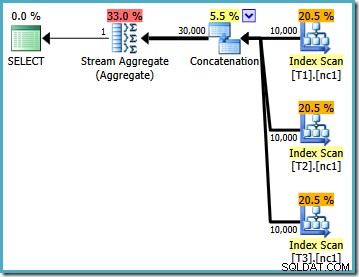
Den här exekveringsplanen är en ganska direkt implementering av den logiska SQL-frågan (efter att vyreferensen V1 har utökats). Optimeraren ser frågan efter vyexpansion, nästan som om frågan hade skrivits ut i sin helhet:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Genom att jämföra den utökade texten med exekveringsplanen är det tydligt att frågeoptimerarens implementering är direkt. Det finns en Index Scan för varje läsning av bastabellerna, en sammanfogningsoperator för att implementera UNION ALL , och ett Stream Aggregate för den sista MAX aggregat.
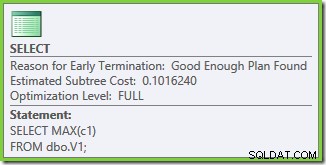
Exekveringsplanens egenskaper visar att kostnadsbaserad optimering påbörjades (optimeringsnivån är FULL ), men att det avslutades tidigt eftersom en "tillräckligt bra" plan hittades. Den uppskattade kostnaden för den valda planen är 0,1016240 magiska optimeringsenheter.
Testa 2 – 50 000 rader, SQL Server 2008 och 2008 R2
Kör följande skript för att återställa testmiljön så att den körs med 50 000 rader:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
Exekveringsplanen för detta test beror på vilken version av SQL Server du kör. I SQL Server 2008 och 2008 R2 får vi följande plan:
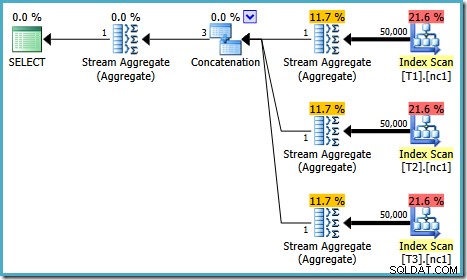
Planegenskaperna visar att kostnadsbaserad optimering ändå avslutades tidigt av samma anledning som tidigare. Den beräknade kostnaden är högre än tidigare på 0,41375 enheter men det förväntas på grund av bastabellernas högre kardinalitet.
Testa 3 – 50 000 rader, SQL Server 2005 och 2012
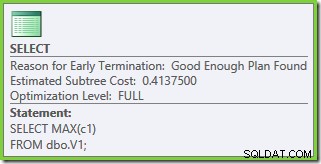
Samma fråga som kördes 2005 eller 2012 ger en annan exekveringsplan:
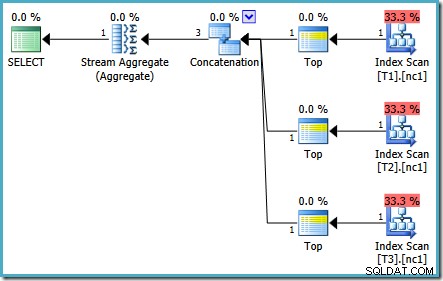
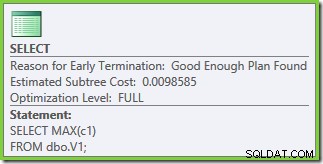
Optimeringen avslutades tidigt igen, men den beräknade plankostnaden för 50 000 rader per bastabell är nere på 0,0098585 (från 0,41375 på SQL Server 2008 och 2008 R2).
Förklaring
Som du kanske vet delar SQL Server-frågeoptimeraren upp optimeringsarbetet i flera steg, med senare steg som lägger till fler optimeringstekniker och ger mer tid. Optimeringsstadierna är:
- Trivial plan
- Kostnadsbaserad optimering
- Transaktionsbearbetning (sök 0)
- Snabbplan (sökning 1)
- Snabbplan med parallellitet aktiverad
- Fullständig optimering (sök 2)
Inget av testerna som utförs här kvalificerar sig för en trivial plan eftersom aggregatet och fackföreningarna har flera implementeringsmöjligheter, vilket kräver ett kostnadsbaserat beslut.
Transaktionsbearbetning
Transaktionsbearbetningssteget (TP) kräver att en fråga innehåller minst tre tabellreferenser, annars hoppar kostnadsbaserad optimering över detta steg och går direkt vidare till Snabbplan. TP-steget är inriktat på billiga navigationsfrågor som är typiska för OLTP-arbetsbelastningar. Den försöker ett begränsat antal optimeringstekniker och är begränsad till att hitta planer med Nested Loop Joins (såvida inte en Hash Join behövs för att generera en giltig plan).
I vissa avseenden är det förvånande att testfrågan kvalificerar sig för ett steg som syftar till att hitta OLTP-planer. Även om frågan innehåller de tre tabellreferenserna som krävs, innehåller den inga kopplingar. Kravet med tre tabeller är bara en heuristik, så jag kommer inte att arbeta med poängen.
Vilka optimeringssteg kördes?
Det finns ett antal metoder, den dokumenterade är att jämföra innehållet i sys.dm_exec_query_optimizer_info före och efter kompilering. Det här är bra, men det registrerar instansomfattande information så du måste vara försiktig så att din är den enda frågekompileringen som sker mellan ögonblicksbilder.
Ett odokumenterat (men någorlunda välkänt) alternativ som fungerar på alla versioner av SQL Server som för närvarande stöds är att aktivera spårningsflaggor 8675 och 3604 under kompilering av frågan.
Test 1
Detta test producerar spårningsflagga 8675-utdata som liknar följande:

Den uppskattade kostnaden på 0,101624 efter TP-steget är tillräckligt låg för att optimeraren inte ska fortsätta leta efter billigare planer. Den enkla plan vi slutar med är ganska rimlig med tanke på bastabellernas relativt låga kardinalitet, även om den inte är riktigt optimal.
Test 2
Med 50 000 rader i varje bastabell avslöjar spårningsflaggan olika information:

Den här gången är den beräknade kostnaden efter TP-steget 0,428735 (fler rader =högre kostnad). Detta är tillräckligt för att uppmuntra optimeraren till snabbplansstadiet. Med fler tillgängliga optimeringstekniker hittar det här steget en plan med en kostnad på 0,41375 . Detta representerar ingen enorm förbättring jämfört med test 1-planen, men det är lägre än standardkostnadströskeln för parallellitet och inte tillräckligt för att gå in i Full Optimization, så återigen slutar optimeringen tidigt.
Test 3
För körning av SQL Server 2005 och 2012 är spårningsflaggan:

Det finns mindre skillnader i antalet körda uppgifter mellan versioner, men den viktiga skillnaden är att på SQL Server 2005 och 2012 hittar snabbplaneringsstadiet en plan som endast kostar 0,0098543 enheter. Det här är planen som innehåller de bästa operatörerna istället för de tre Stream Aggregates under operatören Concatenation som visas i SQL Server 2008 och 2008 R2-planerna.
Buggar och odokumenterade korrigeringar
SQL Server 2008 och 2008 R2 innehåller en regressionsbugg (jämfört med 2005) som fixades under spårningsflagga 4199, men inte dokumenterad så vitt jag kan säga. Det finns dokumentation för TF 4199 som listar fixar som gjorts tillgängliga under separata spårningsflaggor innan de omfattas av 4199, men som den Knowledge Base-artikeln säger:
Denna ena spårningsflagga kan användas för att aktivera alla korrigeringar som tidigare gjordes för frågeprocessorn under många spårningsflaggor. Dessutom kommer alla framtida frågeprocessorfixar att kontrolleras genom att använda denna spårningsflagga.
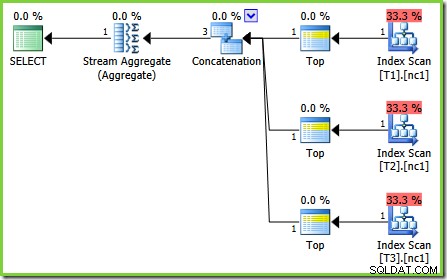
Felet i det här fallet är en av dessa "framtida frågeprocessorfixar". En speciell optimeringsregel, ScalarGbAggToTop , tillämpas inte på de nya aggregaten som visas i test 2-planen. Med spårningsflagga 4199 aktiverad på lämpliga versioner av SQL Server 2008 och 2008 R2 är buggen fixad och den optimala planen från test 3 erhålls:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Slutsats
När du vet att optimeraren kan omvandla en skalär MIN eller MAX samlas till en TOP (1) på en beställd ström verkar planen som visas i test 2 märklig. De skalära aggregaten ovanför en indexskanning (som kan ge ordning om du uppmanas att göra det) framstår som en missad optimering som normalt skulle tillämpas.
Det här är poängen jag gjorde i introduktionen:när du väl får en känsla för vad optimeraren kan göra, kan den hjälpa dig att känna igen fall där något har gått fel.
Svaret kommer inte alltid att vara att aktivera spårningsflagga 4199, eftersom du kan stöta på problem som ännu inte har åtgärdats. Du kanske inte heller vill att de andra QP-fixarna som täcks av spårningsflaggan ska gälla i ett visst fall – optimeringsfixar gör inte alltid saker bättre. Om de gjorde det skulle det inte finnas något behov av att skydda mot olyckliga planregressioner med denna flagga.
Lösningen i andra fall kan vara att formulera SQL-frågan med en annan syntax, att dela upp frågan i mer optimeringsvänliga bitar, eller något helt annat. Vad svaret än visar sig vara, lönar det sig fortfarande att känna till lite om optimizers interna så att du kan känna igen att det var ett problem från början :)