I mitt förra inlägg såg vi hur en fråga med ett skalärt aggregat kunde omvandlas av optimeraren till en mer effektiv form. Som en påminnelse, här är schemat igen:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Planeringsval
Med 10 000 rader i var och en av bastabellerna kommer optimeraren med en enkel plan som beräknar det maximala genom att läsa in alla 30 000 rader till ett aggregat:
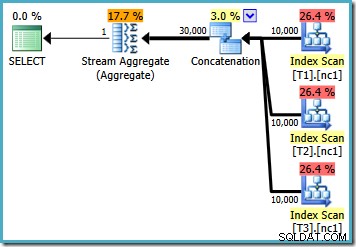
Med 50 000 rader i varje tabell lägger optimeraren lite mer tid på problemet och hittar en smartare plan. Den läser bara den översta raden (i fallande ordning) från varje index och beräknar sedan det maximala från bara dessa 3 rader:
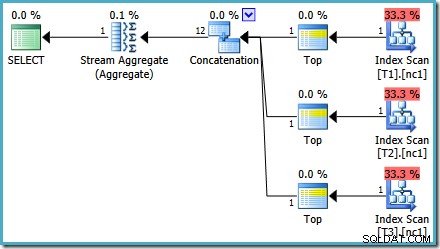
En optimeringsbugg
Du kanske märker något lite konstigt med den uppskattade planen. Konkateneringsoperatorn läser en rad från tre tabeller och producerar på något sätt tolv rader! Detta är ett fel som orsakas av en bugg i kardinalitetsuppskattningen som jag rapporterade i maj 2011. Det är fortfarande inte fixat från och med SQL Server 2014 CTP 1 (även om den nya kardinalitetsuppskattaren används) men jag hoppas att det kommer att åtgärdas för slutlig version.
För att se hur felet uppstår, kom ihåg att ett av planalternativen som optimeraren överväger för fallet med 50 000 rader har partiella aggregat under operatören Sammankoppling:
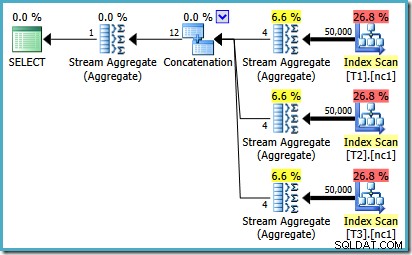
Det är kardinalitetsuppskattningen för dessa partiella MAX aggregat som är felet. De uppskattar fyra rader där resultatet garanterat blir en rad. Du kan se ett annat nummer än fyra – det beror på hur många logiska processorer som är tillgängliga för optimeraren när planen kompileras (se fellänken ovan för mer information).
Optimeraren ersätter senare de partiella aggregaten med Top (1) operatorer, som räknar om kardinalitetsuppskattningen korrekt. Tyvärr återspeglar Sammankopplingsoperatorn fortfarande uppskattningarna för de ersatta partiella aggregaten (3 * 4 =12). Som ett resultat slutar vi med en sammanlänkning som läser 3 rader och ger 12.
Använder TOP istället för MAX
Om man tittar igen på planen med 50 000 rader verkar det som att den största förbättringen som optimeraren hittat är att använda Top (1) operatorer istället för att läsa alla rader och beräkna det maximala värdet med brute force. Vad händer om vi försöker något liknande och skriver om frågan med hjälp av Top explicit?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Utförandeplanen för den nya frågan är:
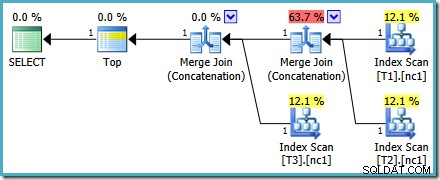
Denna plan skiljer sig ganska mycket från den som optimeraren har valt för MAX fråga. Den har tre ordnade indexskanningar, två sammanfogningar som körs i sammanlänkningsläge och en enda toppoperatör. Den här nya frågeplanen har några intressanta funktioner som är värda att undersöka lite i detalj.
Plananalys
Den första raden (i fallande indexordning) läses från varje tabells icke-klustrade index, och en Merge Join som fungerar i sammanlänkningsläge används. Även om operatören Merge Join inte utför en koppling i normal mening, är denna operatörs bearbetningsalgoritm lätt att anpassa för att sammanfoga dess indata istället för att tillämpa kopplingskriterier.
Fördelen med att använda denna operatör i den nya planen är att Merge Concatenation bevarar sorteringsordningen över dess indata. Däremot läser en vanlig sammanlänkningsoperator från sina ingångar i sekvens. Diagrammet nedan illustrerar skillnaden (klicka för att expandera):
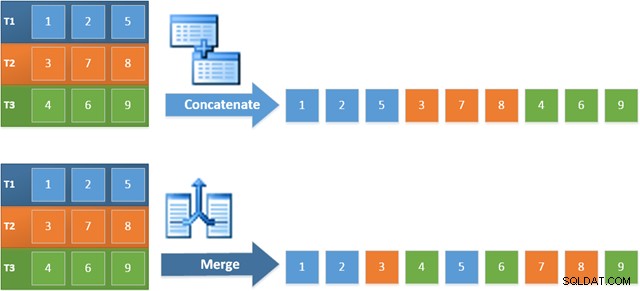
Det ordningsbevarande beteendet hos Merge Concatenation innebär att den första raden som produceras av den sammanfogade operatorn längst till vänster i den nya planen garanterat är raden med det högsta värdet i kolumn c1 över alla tre tabellerna. Mer specifikt fungerar planen enligt följande:
- En rad läses från varje tabell (i index fallande ordning); och
- Varje sammanslagning utför ett test för att se vilken av dess inmatningsrader som har det högsta värdet
Detta verkar vara en mycket effektiv strategi, så det kan tyckas konstigt att optimerarens MAX planen har en beräknad kostnad på mindre än hälften av den nya planen. Till stor del är anledningen att orderbevarande sammanfogning antas vara dyrare än en enkel sammanfogning. Optimeraren inser inte att varje sammanslagning bara kan se maximalt en rad och överskattar dess kostnad som ett resultat.
Fler kostnadsproblem
Strängt taget jämför vi inte äpplen med äpplen här, eftersom de två planerna är för olika frågor. Att jämföra kostnader som det är i allmänhet inte en giltig sak att göra, även om SSMS gör precis det genom att visa kostnadsprocent för olika uttalanden i en batch. Men jag avviker.
Om du tittar på den nya planen i SSMS istället för SQL Sentry Plan Explorer kommer du att se något sånt här:
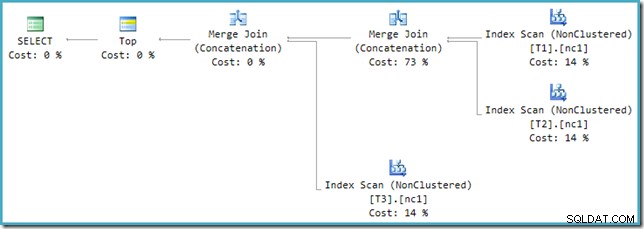
En av Merge Join Concatenation-operatörerna har en uppskattad kostnad på 73 % medan den andra (fungerar på exakt samma antal rader) visas som att den inte kostar något alls. Ett annat tecken på att något är fel här är att operatörens kostnadsprocent i denna plan inte uppgår till 100 %.
Optimerare kontra Execution Engine
Problemet ligger i en inkompatibilitet mellan optimeraren och exekveringsmotorn. I optimeraren kan Union och Union All ha 2 eller fler ingångar. I exekveringsmotorn är det bara sammanfogningsoperatören som kan acceptera 2 eller fler ingångar; Merge Join kräver exakt två ingångar, även när de är konfigurerade att utföra en sammanlänkning snarare än en sammanfogning.
För att lösa denna inkompatibilitet tillämpas en omskrivning efter optimering för att översätta optimerarens utdataträd till en form som exekveringsmotorn kan hantera. När en Union eller Union All med fler än två ingångar implementeras med Merge, behövs en kedja av operatörer. Med tre ingångar till Union All i detta fall behövs två sammanslagningsförbund:
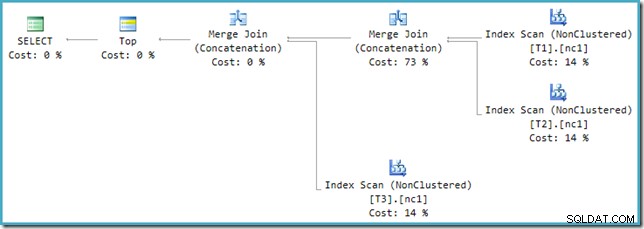
Vi kan se optimerarens utdataträd (med tre ingångar till en fysisk sammanslagningsunion) med hjälp av spårningsflagga 8607:
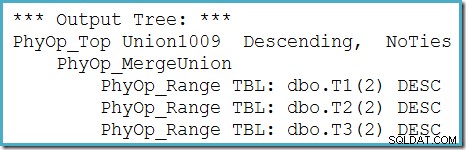
En ofullständig korrigering
Tyvärr är omskrivningen efter optimering inte perfekt implementerad. Det gör en viss röra av kostnadssiffrorna. Om man avrundar problem åsido, adderar plankostnaderna upp till 114 % med de extra 14 % som kommer från input till den extra Merge Join Concatenation som genereras av omskrivningen:
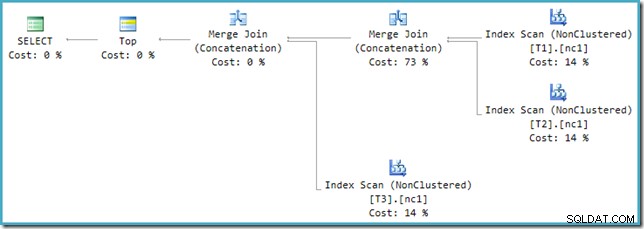
Merge längst till höger i denna plan är den ursprungliga operatören i optimerarens utdataträd. Den tilldelas hela kostnaden för Union All-verksamheten. Den andra sammanslagningen läggs till av omskrivningen och får en noll kostnad.
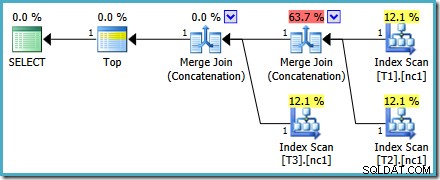
Oavsett hur vi väljer att se på det (och det finns olika problem som påverkar vanlig sammankoppling) ser siffrorna udda ut. Plan Explorer gör sitt bästa för att komma runt den trasiga informationen i XML-planen genom att åtminstone se till att siffrorna summerar till 100 %:
Detta specifika kostnadsproblem är åtgärdat i SQL Server 2014 CTP 1:
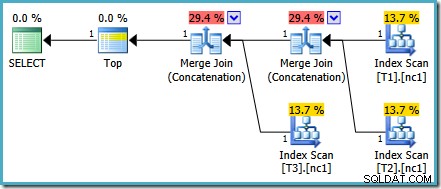
Kostnaderna för sammanfogningen är nu jämnt fördelade mellan de två operatörerna, och procentsatserna summerar till 100 %. Eftersom den underliggande XML-filen har fixats, lyckas SSMS också visa samma siffror.
Vilken plan är bättre?
Om vi skriver frågan med MAX , måste vi lita på att optimeraren väljer att utföra det extra arbete som krävs för att hitta en effektiv plan. Om optimeraren hittar en plan som verkar tillräckligt bra tidigt, kan den producera en relativt ineffektiv plan som läser varje rad från var och en av bastabellerna:
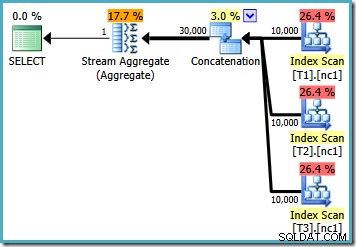
Om du kör SQL Server 2008 eller SQL Server 2008 R2, kommer optimeraren fortfarande att välja en ineffektiv plan oavsett antalet rader i bastabellerna. Följande plan producerades på SQL Server 2008 R2 med 50 000 rader:
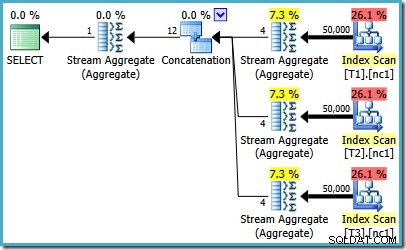
Även med 50 miljoner rader i varje tabell, lägger 2008 och 2008 års R2-optimerare bara till parallellitet, den introducerar inte de bästa operatorerna:
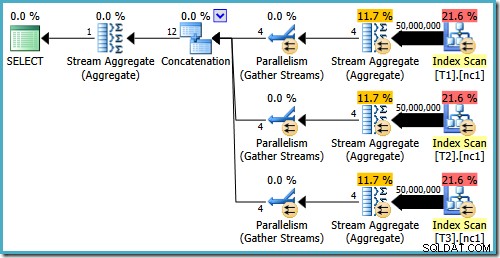
Som nämnts i mitt tidigare inlägg krävs spårningsflagga 4199 för att få SQL Server 2008 och 2008 R2 att producera planen med Top-operatörer. SQL Server 2005 och 2012 och framåt kräver inte spårningsflaggan:
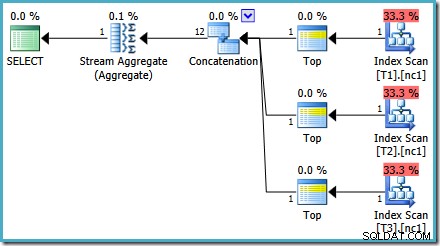
TOPP med BESTÄLLNING AV
När vi väl förstår vad som händer i de tidigare exekveringsplanerna kan vi göra ett medvetet (och informerat) val att skriva om frågan med en explicit TOPP med BESTÄLLNING AV:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Den resulterande exekveringsplanen kan ha kostnadsprocenter som ser udda ut i vissa versioner av SQL Server, men den underliggande planen är sund. Omskrivningen efter optimering som gör att siffrorna ser udda ut tillämpas efter att frågeoptimeringen är klar, så vi kan vara säkra på att optimerarens planval inte påverkades av det här problemet.
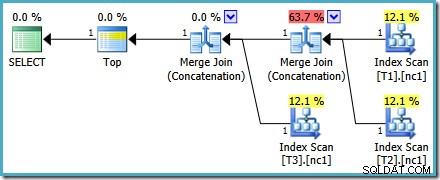
Denna plan ändras inte beroende på antalet rader i bastabellen och kräver inga spårningsflaggor för att generera. En liten extra fördel är att denna plan hittas av optimeraren under den första fasen av kostnadsbaserad optimering (sök 0):
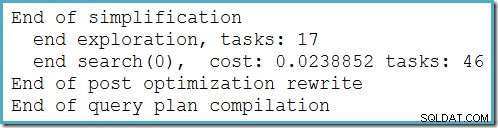
Den bästa planen vald av optimeraren för MAX fråga krävs för två steg av kostnadsbaserad optimering (sök 0 och sök 1).
Det finns en liten semantisk skillnad mellan TOP fråga och den ursprungliga MAX form som jag bör nämna. Om ingen av tabellerna innehåller en rad skulle den ursprungliga frågan producera en enda NULL resultat. Ersättningen TOP (1) fråga producerar ingen utdata alls under samma omständigheter. Denna skillnad är inte ofta viktig i verkliga frågor, men det är något att vara medveten om. Vi kan replikera beteendet hos TOP med MAX i SQL Server 2008 och framåt genom att lägga till en tom uppsättning GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Denna ändring påverkar inte exekveringsplanerna som genereras för MAX fråga på ett sätt som är synligt för slutanvändare.
MAX med sammanfogning
Med tanke på framgången med Merge Join Concatenation i TOP (1) exekveringsplan är det naturligt att undra om samma optimala plan skulle kunna genereras för den ursprungliga MAX fråga om vi tvingar optimeraren att använda Merge Concatenation istället för vanlig sammanfogning för UNION ALL operation.
Det finns ett frågetips för detta ändamål – MERGE UNION – men tyvärr fungerar det bara korrekt i SQL Server 2012 och framåt. I tidigare versioner, UNION ledtråd påverkar bara UNION frågor, inte UNION ALL . I SQL Server 2012 och framåt kan vi prova detta:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Vi belönas med en plan som innehåller Merge Concatenation. Tyvärr är det inte riktigt allt vi kan ha hoppats på:
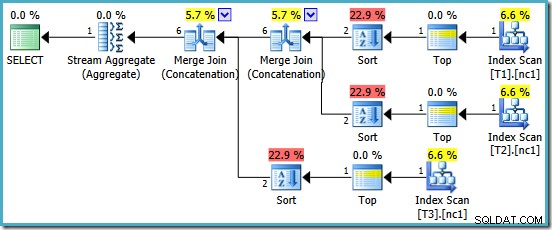
De intressanta aktörerna i denna plan är sorterna. Lägg märke till uppskattningen av 1-rads ingångskardinalitet och 4-radsuppskattningen på utgången. Orsaken borde vara bekant för dig vid det här laget:det är samma partiella aggregerade kardinalitetsuppskattningsfel som vi diskuterade tidigare.
Förekomsten av sorterna avslöjar ytterligare ett problem med de partiella aggregaten. De producerar inte bara en felaktig kardinalitetsuppskattning, de misslyckas också med att bevara indexordningen som skulle göra sortering onödig (Merge Concatenation kräver sorterade indata). De partiella aggregaten är skalära MAX aggregat, garanterat att producera en rad så frågan om beställning borde vara oklart ändå (det finns bara ett sätt att sortera en rad!)
Detta är synd, för utan dessa sorter skulle detta vara en anständig genomförandeplan. Om de partiella aggregaten implementerades korrekt, och MAX skriven med en GROUP BY () sats, kan vi till och med hoppas att optimeraren kunde upptäcka att de tre Tops och det slutliga Stream Aggregate kan ersättas av en enda slutlig Top-operatör, vilket ger exakt samma plan som den explicita TOP (1) fråga. Optimeraren innehåller inte den transformationen idag, och jag antar att den inte skulle vara användbar tillräckligt ofta för att göra det värt besväret i framtiden.
Slutord
Använder TOP kommer inte alltid att vara att föredra framför MIN eller MAX . I vissa fall kommer det att ge en betydligt mindre optimal plan. Poängen med det här inlägget är att förståelse för transformationerna som tillämpas av optimeraren kan föreslå sätt att skriva om den ursprungliga frågan som kan visa sig vara till hjälp.