I oktober förra året utmanade vi vår PyBites publik att skapa en webbapp för att bättre navigera i Daily Python Tips-flödet. I den här artikeln kommer jag att dela med mig av vad jag byggde och lärde mig på vägen.
I den här artikeln kommer du att lära dig:
- Hur man klonar projektets repo och ställer in appen.
- Hur man använder Twitter API via Tweepy-modulen för att ladda in tweets.
- Hur man använder SQLAlchemy för att lagra och hantera data (tips och hashtags).
- Hur man bygger en enkel webbapp med Bottle, ett mikrowebb-ramverk som liknar Flask.
- Hur man använder pytest-ramverket för att lägga till tester.
- Hur Better Code Hubs vägledning ledde till mer underhållbar kod.
Om du vill följa med, läsa koden i detalj (och eventuellt bidra) föreslår jag att du delar repan. Låt oss komma igång.
Projektinställning
För det första är namnrymder en tutande bra idé så låt oss göra vårt arbete i en virtuell miljö. Med Anaconda skapar jag det så här:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Skapa en produktions- och en testdatabas i Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
Vi behöver autentiseringsuppgifter för att ansluta till databasen och Twitter API (skapa en ny app först). Enligt bästa praxis bör konfigurationen lagras i miljön, inte koden. Sätt följande env-variabler i slutet av ~/virtualenvs/pytip/bin/activate , skriptet som hanterar aktivering/avaktivering av din virtuella miljö, och se till att uppdatera variablerna för din miljö:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
I avaktiveringsfunktionen för samma skript avaktiverar jag dem så att vi håller saker utanför skalets räckvidd när vi avaktiverar (lämnar) den virtuella miljön:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Nu är det ett bra tillfälle att aktivera den virtuella miljön:
$ source ~/virtualenvs/pytip/bin/activate
Klona repet och, med den virtuella miljön aktiverad, installera kraven:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Därefter importerar vi samlingen av tweets med:
$ python tasks/import_tweets.py
Kontrollera sedan att tabellerna skapades och att tweetarna lades till:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Låt oss nu köra testerna:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
Och slutligen kör Bottle-appen med:
$ python app.py
Bläddra till https://localhost:8080 och voilà:du bör se tipsen sorterade efter popularitet. Genom att klicka på en hashtaglänk till vänster, eller använda sökrutan, kan du enkelt filtrera dem. Här ser vi pandas tips till exempel:
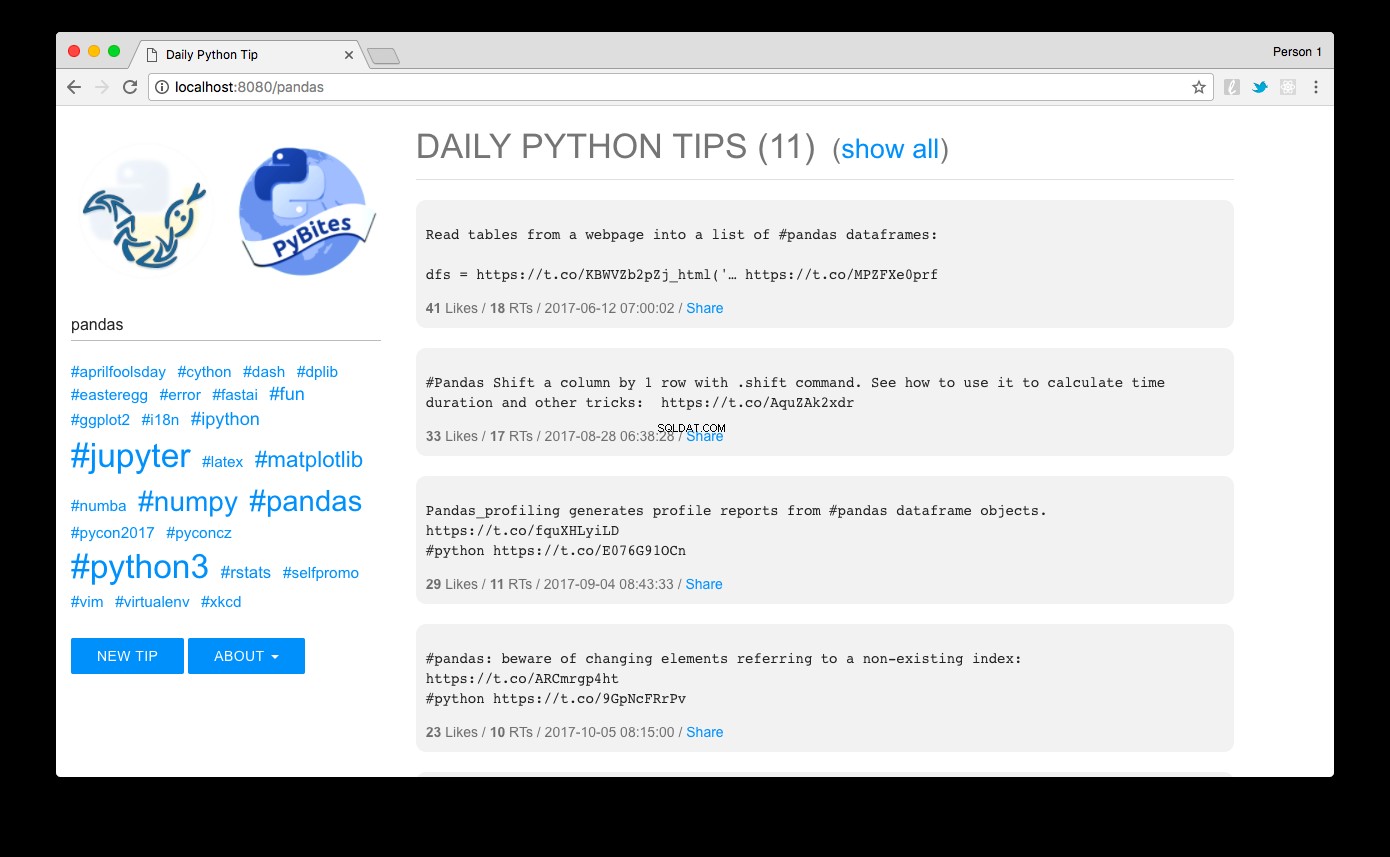
Designen jag gjorde med MUI - ett lätt CSS-ramverk som följer Googles riktlinjer för materialdesign.
Implementeringsdetaljer
DB och SQLAlchemy
Jag använde SQLAlchemy för att gränssnittet med DB för att undvika att behöva skriva mycket (redundant) SQL.
I tips/models.py , definierar vi våra modeller - Hashtag och Tip - att SQLAlchemy mappar till DB-tabeller:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
I tips/db.py , vi importerar dessa modeller, och nu är det enkelt att arbeta med DB, till exempel att gränssnittet med Hashtag modell:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
Och:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Fråga Twitter API
Vi måste hämta data från Twitter. För det skapade jag tasks/import_tweets.py . Jag paketerade detta under uppgifter eftersom det ska köras i ett dagligt cronjob för att leta efter nya tips och uppdatera statistik (antal likes och retweets) på befintliga tweets. För enkelhetens skull återskapar jag tabellerna dagligen. Om vi börjar lita på FK-relationer med andra tabeller bör vi definitivt välja uppdateringssatser framför delete+add.
Vi använde det här skriptet i Project Setup. Låt oss se vad den gör mer i detalj.
Först skapar vi ett API-sessionsobjekt som vi skickar till tweepy.Cursor. Den här funktionen hos API:t är riktigt trevlig:den hanterar sidnumrering, itererar genom tidslinjen. För mängden tips - 222 när jag skriver det här - är det riktigt snabbt. exclude_replies=True och include_rts=False argument är praktiska eftersom vi bara vill ha Daily Python Tipss egna tweets (inte re-tweets).
Att extrahera hashtags från tipsen kräver väldigt lite kod.
Först definierade jag ett regex för en tagg:
TAG = re.compile(r'#([a-z0-9]{3,})')
Sedan använde jag findall för att få alla taggar.
Jag skickade dem till collections.Counter som returnerar ett diktliknande objekt med taggarna som nycklar, och räknas som värden, ordnade i fallande ordning efter värden (vanligast). Jag uteslöt den alltför vanliga python-taggen som skulle förvränga resultaten.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Slutligen, import_* funktioner i tasks/import_tweets.py gör den faktiska importen av tweets och hashtags, anropa add_* DB-metoder för tips katalog/paket.
Skapa en enkel webbapp med Bottle
Med detta förarbete gjort är det förvånansvärt enkelt att skapa en webbapp (eller inte så överraskande om du använde Flask tidigare).
Först och främst träffa Bottle:
Bottle är ett snabbt, enkelt och lätt WSGI-mikrowebframework för Python. Den distribueras som en enda filmodul och har inga andra beroenden än Python Standard Library.
Trevlig. Den resulterande webbappen består av <30 LOC och kan hittas i app.py.
För denna enkla app är en enda metod med ett valfritt taggargument allt som krävs. I likhet med Flask, sköts routingen med dekoratörer. Om den anropas med en tagg filtrerar den tipsen på tagg, annars visar den alla. Vydekoratören definierar mallen som ska användas. Liksom Flask (och Django) returnerar vi ett dikt för användning i mallen.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
Enligt dokumentation, för att arbeta med statiska filer, lägger du till det här utdraget överst, efter importerna:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Slutligen vill vi se till att vi bara körs i felsökningsläge på localhost, därav APP_LOCATION env-variabel vi definierade i Project Setup:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Flaskmallar
Bottle levereras med en snabb, kraftfull och lättläst inbyggd mallmotor som heter SimpleTemplate.
I underkatalogen vyer definierade jag en header.tpl , index.tpl och footer.tpl . För taggmolnet använde jag en enkel inline CSS som ökade taggstorleken efter antal, se header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
I index.tpl vi går igenom tipsen:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Om du är bekant med Flask och Jinja2 borde detta se väldigt bekant ut. Att bädda in Python är ännu enklare, med mindre skrivning—(% ... vs {% ... %} ).
Alla css, bilder (och JS om vi skulle använda det) hamnar i den statiska undermappen.
Och det är allt som finns för att skapa en grundläggande webbapp med Bottle. När du väl har definierat datalagret korrekt är det ganska enkelt.
Lägg till tester med pytest
Låt oss nu göra det här projektet lite mer robust genom att lägga till några tester. Att testa DB krävde lite mer grävande i pytest-ramverket, men det slutade med att jag använde dekoratorn pytest.fixture för att sätta upp och riva en databas med några testtweets.
Istället för att anropa Twitter API, använde jag en del statisk data som tillhandahålls i tweets.json .Och istället för att använda live-DB, i tips/db.py , jag kontrollerar om pytest är anroparen (sys.argv[0] ). I så fall använder jag test-DB. Jag kommer förmodligen att refaktorera detta, eftersom Bottle stöder arbete med konfigurationsfiler.
Det var lättare att testa hashtaggen (test_get_hashtag_counter ) eftersom jag bara kunde lägga till några hashtags till en flerradssträng. Inga fixturer behövs.
Kodkvaliteten är viktig – Better Code Hub
Better Code Hub guidar dig i att skriva, ja, bättre kod. Innan provet skrevs fick projektet 7:
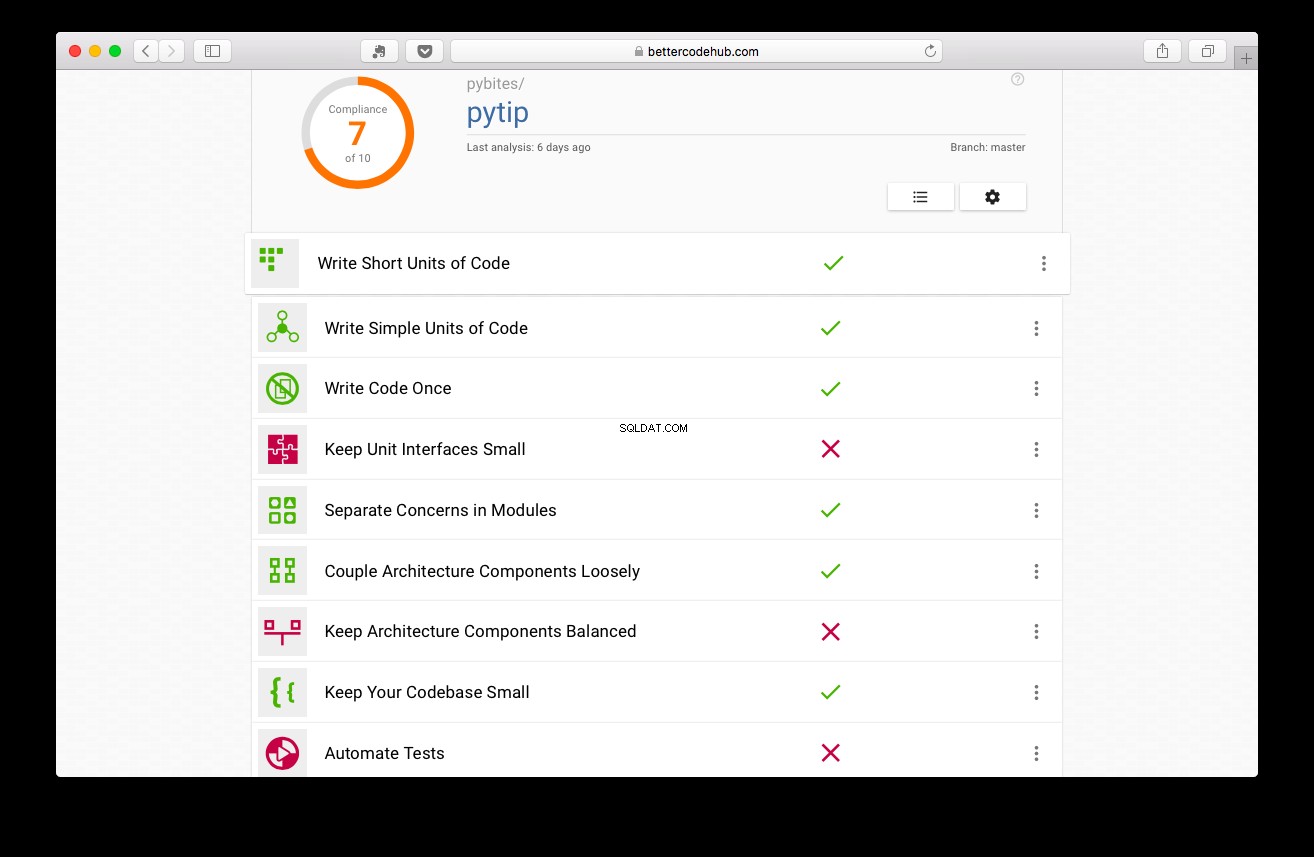
Inte illa, men vi kan göra bättre:
-
Jag slog den till 9 genom att göra koden mer modulär, ta bort DB-logiken från app.py (webbappen), lägga den i tipsmappen/-paketet (refactorings 1 och 2)
-
Sedan med testerna på plats fick projektet 10:
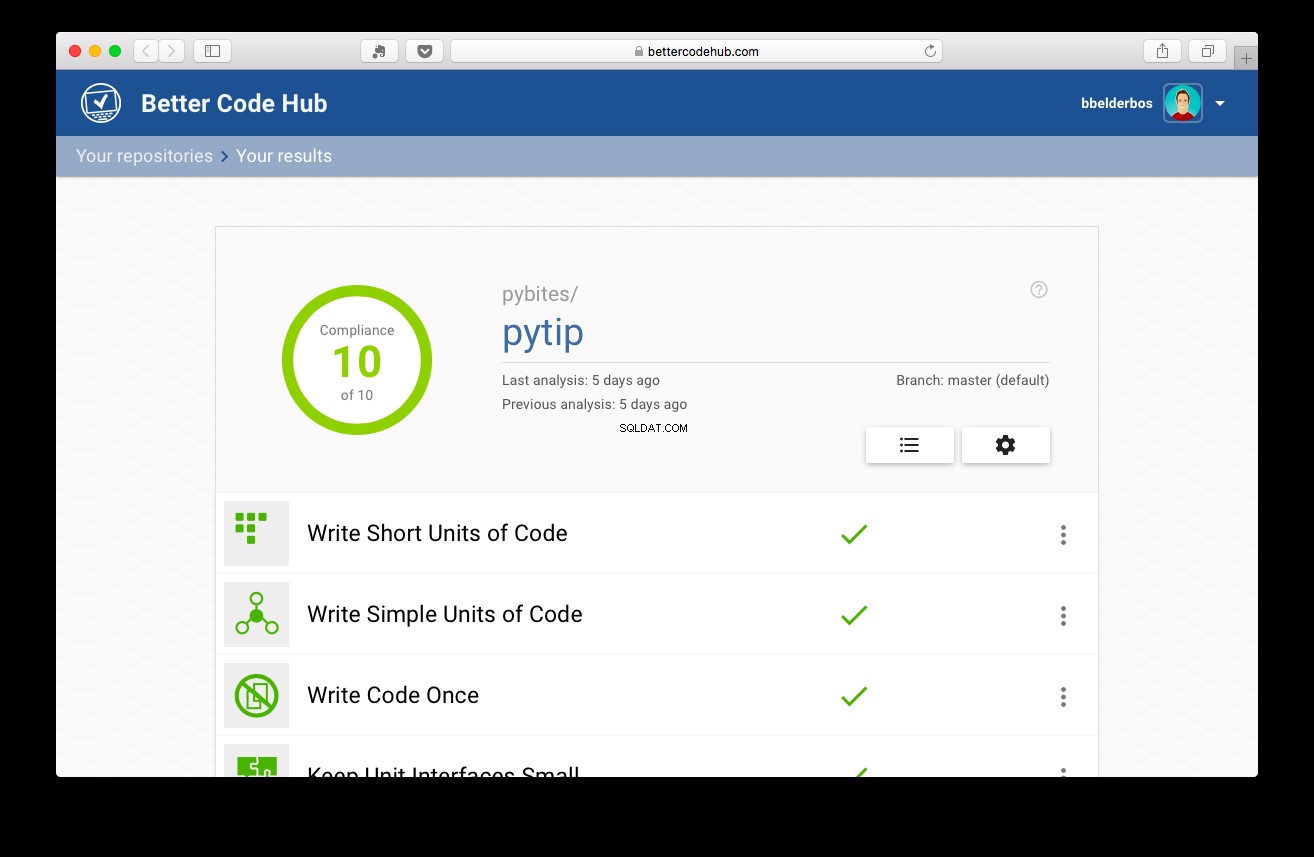
Slutsats och lärande
Vår Code Challenge #40 erbjöd några bra övningar:
- Jag byggde en användbar app som kan utökas (jag vill lägga till ett API).
- Jag använde några coola moduler värda att utforska:Tweepy, SQLAlchemy och Bottle.
- Jag lärde mig lite mer pytest eftersom jag behövde fixturer för att testa interaktion med DB.
- Framför allt, med att göra koden testbar, blev appen mer modulär vilket gjorde den lättare att underhålla. Better Code Hub var till stor hjälp i denna process.
- Jag distribuerade appen till Heroku med hjälp av vår steg-för-steg-guide.
Vi utmanar dig
Det bästa sättet att lära sig och förbättra dina kodningsfärdigheter är att öva. På PyBites befäste vi detta koncept genom att organisera Python-kodutmaningar. Kolla in vår växande kollektion, dela repet och få kodning!
Låt oss veta om du bygger något coolt genom att göra en Pull Request av ditt arbete. Vi har sett folk som verkligen sträcker sig igenom dessa utmaningar, och det gjorde vi också.
Lycka till med kodningen!