En återkommande händelse är per definition en händelse som återkommer med ett intervall; det kallas också en periodisk händelse. Det finns många applikationer som låter sina användare ställa in återkommande händelser. Hur hanterar ett databassystem återkommande händelser? I den här artikeln kommer vi att utforska ett sätt att hantera dem på.
Återkommande är inte lätt för ansökningar att hantera. Det kan bli en orkanuppgift, särskilt när det gäller att täcka alla möjliga återkommande scenarion – inklusive att skapa evenemang varannan vecka eller kvartalsvis eller tillåta omschemaläggning av alla framtida händelser.
Två sätt att hantera återkommande händelser
Jag kan tänka mig minst två sätt att hantera periodiska uppgifter i en datamodell. Innan vi diskuterar dem, låt oss snabbt gå igenom kraven för denna uppgift. I ett nötskal betyder effektiv förvaltning:
- Användare får skapa regelbundna och återkommande evenemang.
- Dagliga, veckovisa, varannan vecka, månadsvisa, kvartalsvisa, vartannat år och årliga evenemang kan skapas utan begränsningar för slutdatum.
- Användare kan schemalägga eller avbryta en instans av en händelse eller alla framtida instanser av en händelse.
Med tanke på dessa parametrar kommer två sätt att hantera återkommande händelser i datamodellen att tänka på. Vi kommer att kalla dem för det naiva och expertsättet.
Det naiva sättet: Lagra alla möjliga återkommande instanser av en händelse som separata rader i en tabell. I den här lösningen kräver vi bara en tabell, nämligen event . Den här tabellen har kolumner som event_title , startdatum , slutdatum , is_full_day_event , etc. startdatum och slutdatum kolumner är tidsstämpeldatatyper; på så sätt kan de ta emot händelser som inte varar hela dagen.
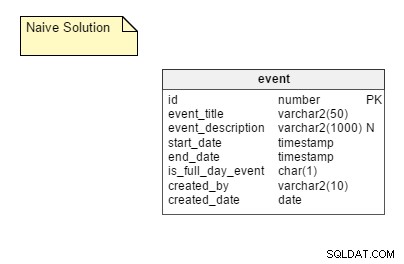
Proffsen: Detta är ett ganska okomplicerat tillvägagångssätt och det enklaste att implementera.
Nackdelarna: Det naiva sättet har några betydande nackdelar, inklusive:
- Behovet av att lagra alla möjliga instanser av en händelse. Om du tar hänsyn till en stor användarbas krävs en stor bit utrymme. Utrymmet är dock ganska billigt, så denna punkt har ingen större inverkan.
- En mycket rörig uppdateringsprocess. Anta att en händelse är omplanerad. I så fall måste någon uppdatera alla instanser av det. Ett stort antal DML-operationer måste utföras vid omläggning, vilket skapar en negativ inverkan på applikationsprestanda.
- Hantering av undantag. Alla undantag måste hanteras graciöst, speciellt om du måste gå tillbaka och redigera det ursprungliga mötet efter att ha gjort ett undantag. Anta till exempel att du flyttar den tredje instansen av en återkommande händelse framåt med en dag. Vad händer om du senare redigerar tidpunkten för den ursprungliga händelsen? Infogar du en annan händelse på den ursprungliga dagen och lämnar den du flyttade fram? Ta bort länken till undantaget? Försök att ändra det på lämpligt sätt?
Event_id– Den här kolumnen är hänvisad fråneventtabell, och den fungerar som den primära nyckeln i den här tabellen. Den visar det identifierande förhållandet mellanhändelseochrecurring_patterntabeller. Den här kolumnen säkerställer också att det finns maximalt ett återkommande mönster för varje händelse.Återkommande_typ-id– Den här kolumnen anger typen av återkommande, oavsett om det är dagligen, veckovis, månadsvis eller årligen.Max_antal_of_occurrances– Det finns tillfällen då vi inte vet det exakta slutdatumet för en händelse men vi vet hur många händelser (möten) som krävs för att slutföra det. Den här kolumnen lagrar ett godtyckligt nummer som definierar det logiska slutet för en händelse.Separation_count– Du kanske undrar hur en händelse varannan vecka eller två gånger om året kan konfigureras om det bara finns fyra möjliga värden av återfallstyp (dagligen, veckovis, månadsvis, årligen). Svaret ärseparation_countkolumn. Den här kolumnen anger intervallet (i dagar, veckor eller månader) innan nästa händelseinstans tillåts. Till exempel, om en händelse behöver konfigureras för varannan vecka, då separation_count =“1” för att uppfylla detta krav. Standardvärdet för denna kolumn är "0".- Det
recurring_type_idskulle vara "veckovis". separation_countskulle vara "1".veckodagenskulle vara "2".Vecka_i_månaden– Den här kolumnen är för händelser som är schemalagda för en viss vecka i månaden – dvs den första, andra, sista, näst sista, etc. Vi kan lagra dessa värden som 1,2,3, 4,.. (räknat från början av månaden) eller -1,-2,-3,... (räknat från slutet av månaden).Dag_i_månaden– Det finns fall då en händelse är schemalagd på en viss dag i månaden, säg den 25:e. Denna kolumn uppfyller detta krav. Somvecka_i_månad, kan den fyllas i med positiva siffror ( "7" för den 7:e dagen från början av månaden) eller negativa siffror ( "-7" för den sjunde dagen från slutet av månaden).- Det
recurring_type_idskulle vara "månadsvis". separation_countskulle vara "2".dagen_i_månadenskulle vara "11".- Alla återstående kolumner skulle vara null.
- Händelser som inträffar på helgdagar. När ett särskilt fall av en händelse inträffar på en allmän helgdag, bör den automatiskt flyttas till arbetsdagen omedelbart efter helgdagen? Eller ska det avbrytas automatiskt? Under vilka omständigheter skulle någon av dessa gälla?
- Konflikter mellan händelser. Vad händer om vissa händelser (som utesluter varandra) inträffar samma dag?
Expertens sätt: Lagra ett återkommande mönster och generera tidigare och framtida händelseförekomster programmatiskt. Denna lösning tar upp nackdelarna med den naiva lösningen. Vi kommer att förklara expertlösningen i detalj i den här artikeln.
Den föreslagna modellen
Skapa evenemang
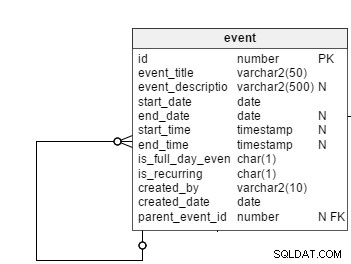
Alla schemalagda händelser, oavsett deras regelbundna eller återkommande karaktär, loggas i händelsen tabell. Alla händelser är inte återkommande händelser, så vi behöver en flaggkolumn, is_recurring , i den här tabellen för att explicit specificera återkommande händelser. event_title och event_description kolumner lagrar ämnet och en kort sammanfattning av händelser. Händelsebeskrivningar är valfria, vilket är anledningen till att den här kolumnen är nullbar.
Som deras namn antyder, start_date och slutdatum kolumner håller start- och slutdatum för händelser. Vid vanliga händelser lagrar dessa kolumner faktiska start- och slutdatum. Men de lagrar också datumen för de första och sista förekomsterna av periodiska händelser. Vi behåller end_date kolumnen som null, eftersom användare kan konfigurera återkommande händelser utan slutdatum. I det här fallet skulle framtida händelser fram till ett hypotetiskt slutdatum (säg ett år) visas i användargränssnittet.
is_full_date_event kolumn anger om en händelse är en heldagshändelse. I fallet med en heldagshändelse, start_time och sluttid kolumner skulle vara null; det är anledningen till att hålla båda dessa kolumner nullbara.
created_by och created_date kolumner lagrar vilken användare som skapade en händelse och datumet då händelsen skapades.
Därefter är det parent_event_id kolumn. Detta spelar en stor roll i vår datamodell. Jag kommer att förklara dess betydelse senare.
Hantera upprepningar
Nu kommer vi direkt till huvudproblemformuleringen:Vad händer om en återkommande händelse skapas i event tabell – det vill säga
Som förklarats tidigare kommer vi att lagra ett återkommande mönster för händelser så att vi kan konstruera alla dess framtida händelser. Låt oss börja med att skapa recurring_pattern tabell. Den här tabellen har följande kolumner:
Låt oss överväga betydelsen av de återstående kolumnerna i termer av de olika typerna av återkommande.
Dagliga återkommande
Behöver vi verkligen fånga ett mönster för en dagligt återkommande händelse? Nej, eftersom alla detaljer som krävs för att generera ett dagligt återkommande mönster redan är inloggade i händelsen bord.
Det enda scenariot som kräver ett mönster är när händelser är schemalagda för alternativa dagar eller vart X antal dagar. I det här fallet, separation_count kolumnen hjälper oss att förstå återkommande mönster och härleda ytterligare instanser.
Veckovis återkommande
Vi kräver bara en extra kolumn, day_of_week , för att lagra vilken veckodag detta evenemang kommer att äga rum. Om man antar att måndag är den första dagen i veckan och söndag är den sista, skulle möjliga värden vara 1,2,3,4,5,6 och 7. Lämpliga ändringar i koden som genererar enskilda händelser bör göras vid behov. Alla återstående kolumner skulle vara null för veckohändelser.
Låt oss ta en klassisk typ av veckohändelse:händelsen varannan vecka. I det här fallet säger vi att det händer varannan vecka på en tisdag, den andra dagen i veckan. Så:

Månatlig återkommande
Förutom day_of_week , kräver vi ytterligare två kolumner för att möta alla månatliga återkommande scenarion. I korthet är dessa kolumner:
Låt oss nu överväga ett mer komplicerat exempel - en kvartalshändelse. Anta att ett företag schemalägger en kvartalsvis resultatprognose för den 11 dagen i den första månaden i varje kvartal (vanligtvis januari, april, juli och oktober). Så i det här fallet:
I exemplet ovan antar vi att användaren skapar den kvartalsvisa resultatprognosen i januari. Observera att denna separationslogik börjar räknas från månaden, veckan eller dagen då händelsen skapas.
På liknande rader kan halvårshändelser loggas som månatliga händelser med en
Årliga återkommande är ganska okomplicerat. Vi har kolumner för särskilda veckodagar och månad, så vi behöver bara en extra kolumn för månaden på året. Vi har döpt den här kolumnen till
Låt oss nu komma till undantagen. Vad händer om en viss instans av en återkommande händelse ställs in eller omplaneras? Alla sådana instanser loggas separat i
Låt oss ta en titt på två kolumner,
Förutom dessa två kolumner fungerar alla återstående kolumner på samma sätt som i
Det finns applikationer som tillåter användare att schemalägga alla framtida instanser av en återkommande händelse. I sådana fall har vi två alternativ. Vi kan lagra alla framtida instanser i
Med denna lösning kan vi få alla tidigare förekomster av en händelse, även när dess återkommande mönster har ändrats.
Det finns några mer komplexa områden kring återkommande händelser som vi inte har diskuterat. Här är två:
Vilka förändringar behöver vi göra för att bygga in dessa förmågor? Berätta för oss dina åsikter i kommentarsektionen.separation_count av "5".
Årligt återkommande
månad_i_år .
Hantera undantag från återkommande händelser
event_instance_exception tabell. Is_rescheduled och is_cancelled . Dessa kolumner anger om den här instansen är omplanerad till något senare datum/tid eller avbryts helt. Varför har jag två separata kolumner för detta? Tja, tänk bara på evenemang som först schemalagts och sedan ställdes in helt. Detta händer, och vi har ett sätt att spela in det med dessa kolumner. händelsen bord.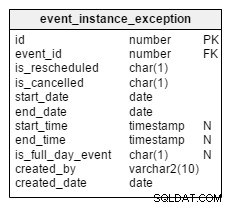
Varför länka två händelser med hjälp av
parent_event_id ?event_instance_exception (tips:inte en acceptabel lösning). Eller så kan vi skapa en ny händelse med nya datum-/tidsparametrar i händelse tabellen och länka den till dess tidigare händelse (den överordnade händelsen) med hjälp av id_parent_event kolumn. Hur förbättrar man hanteringen av återkommande händelser?