I allmänhet gillar folk inte att få oönskade e-postmeddelanden. Ändå prenumererar de ibland på nyhetsbrev för att få rabatt eller för att hålla sig uppdaterad med nya produkter. Den här artikeln kommer att presentera ett sätt att utforma en nyhetsbrevsdatabas.
Varför oroa sig för e-postmeddelanden från nyhetsbrev?
Prenumeranter på nyhetsbrev representerar en extremt värdefull grupp kunder – de är intresserade av våra produkter, de litar på oss och de lägger tid på att granska våra erbjudanden och kampanjer. Dessutom är att skicka e-post till kunder ett av de billigaste verktygen inom marknadsföring på nätet. Det måste dock göras försiktigt – data måste uppdateras dagligen (eftersom människor prenumererar och avslutar prenumerationen) och vara av hög kvalitet (vi vill inte skicka oönskade e-postmeddelanden, eftersom det påverkar varumärkets image negativt).
Så frågan uppstår om hur man hanterar denna process att få kvalitetsdata och uppdatera den dagligen. Det finns många alternativ ...
Och vinnaren är...
Kundanalys! Nuförtiden är den viktigaste faktorn för att ligga före konkurrenterna att hitta insikter från data och fatta affärsbeslut utifrån den. Skulle det inte vara bra att titta igenom historien om nyhetsbrevsutskick och analysera deras intensitet och effektivitet? För varje kund? Och sedan gå med inköpsdata, avslöja kundens intressen, förbereda individuella rekommendationer och skicka ut dessa med personliga e-postmeddelanden?
Ett sådant tillvägagångssätt skulle säkert öka vår konverteringsfrekvens (CR). Omvandlingsfrekvensen är en av de viktigaste nyckelprestandaindikatorerna för onlinemarknadsföring; den visar hur många som gör ett köp efter att ha sett en del av vårt reklammaterial (annonser, nyhetsbrev, etc). Ett högt CR innebär ökad affärseffektivitet.
Nu när vi förstår en del av marknadsföringen, låt oss gå in på datamodellen!
Låt oss börja modellera en nyhetsbrevsdatabas!
När vi gräver direkt in ser vi att de två huvudtabellerna i modellen är client och newsletter tabeller.
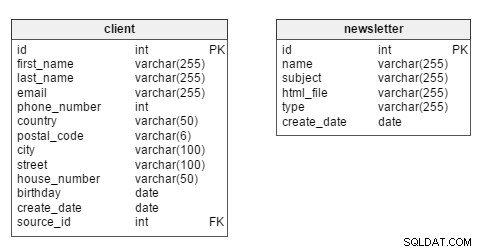
Eftersom vi mest kommer att vara intresserade av kundanalys, är client bordet ska stanna i mitten av modellen. I den här tabellen har varje klient sitt eget unika id . Vi lagrar även sådan information som klientens first_name och last_name , kontaktinformation (email , phone_number , gatuadress), birthday , create_date (när kundens post skrevs in i databasen) och deras source_id – dvs. om de är registrerade på vår webbplats eller om någon affärspartner har gett oss sina uppgifter.
newsletter Tabellen lagrar data om varje nyhetsbrev som skapas. Nyhetsbrev kan identifieras baserat på deras unika id . Var och en beskrivs av ett name (t.ex. "Ny damklädeskollektion – hösten 2016"), e-post subject ("De mest fashionabla kläderna för henne – köp nu!"), html_file (filen som innehåller HTML-koden för det specifika nyhetsbrevet), nyhetsbrev type (t.ex. "ny samling", "födelsedagsnyhetsbrev") och create_date .
Marknadsföringsmedgivanden
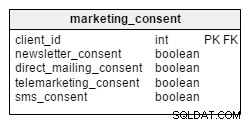
För att kunna skicka ut marknadsföringsinformation (per post, telefon, e-post eller SMS) behöver ett företag inhämta samtycke från sina kunder. I vår modell lagras samtycken i en separat tabell med namnet marketing_consent . Den sparar information om den aktuella uppsättningen marknadsföringsmedgivanden för alla våra kunder. Samtycken kodas som booleska variabler – TRUE (godkänner marknadskommunikation) eller FALSE (stämmer inte med).
Det är mycket viktigt att lagra information om när en kund tackat ja till att ta emot annonser via respektive kommunikationskanal. Det är också fördelaktigt att spela in när de dragit tillbaka sitt samtycke för varje kanal. För sådana ändamål, consent_change bord designades.
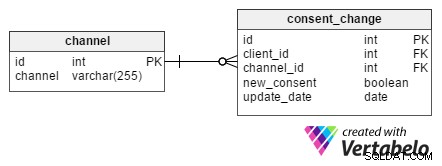
Varje ändring har ett unikt id och tilldelas en viss klient av deras client_id . När en klient begär att bli borttagen från e-postmeddelanden med nyhetsbrev, nyhetsbrevet id från channel tabellen kommer också att lagras i consent_change tabellens channel_id attribut. new_consent attribut är ett booleskt värde (TRUE eller FALSE) och representerar nya marknadsföringsmedgivanden.
update_date kolumnen innehåller datumet då en kund begärde en ändring. Denna struktur tillåter oss att extrahera en uppsättning samtycken för alla kunder en viss dag. Det är oerhört användbart om en kund klagar på att få ett e-postmeddelande efter att de redan har avslutat prenumerationen på vårt nyhetsbrev. Med denna information på fil kan vi kontrollera när avregistreringen ägde rum och förhoppningsvis bekräfta att detta gjordes efter att e-postnyhetsbrevet hade skickats.
Hålla ordning på utsändningar
Att designa en perfekt databasmodell för utskick av nyhetsbrev är inte lätt. Varför? Tja, uppenbarligen måste vi kunna identifiera varje enskilt nyhetsbrevsskapande (vilket betyder layout, grafik, produkter, länkar, etc). Vi vet också att en skapelse kan skickas flera gånger:chefer kan bestämma att en hink med e-post ska skickas på morgonen till hälften av kunderna och på kvällen till den andra hälften. Så det är avgörande att registrera vilka kunder som fått vilket nyhetsbrev och när. Det är därför denna del av modellen består av tre tabeller:
newslettertabell – som vi beskrev tidigare.newsletter_sendouttabell – som identifierar en enda utsändning. Till exempel julens nyhetsbrev (id =“2512”) skickades ut via e-post den 10 december kl. 18.00. Denna registerföring gör det möjligt för marknadsförare att skicka samma nyhetsbrev till olika grupper av kunder vid olika tidpunkter.sendout_receiverstabell – som samlar in data om mottagarna av varje utskick. Det kommer att finnas en post för varje e-postmeddelande från varje utskick. Varje rad har tre kolumner:id(identifierar händelsen med att skicka ett e-postmeddelande till en klient),client_id(identifierar klienter från vår databas) ochnl_sendout_id(identifierar ett nyhetsbrev som skickats ut).
Här är den kompletta nyhetsbrevsmodellen:
Några idéer om hur man kan förbättra den här modellen?
Ett möjligt sätt är att lägga till ett response tabell. Detta skulle lagra kundernas reaktioner – oavsett om de öppnade e-postmeddelandet, klickade på annonsen eller aldrig såg meddelandet eftersom det var markerat som spam. Var ska vi lägga till response tabell till vår modell och vilken relation ska tillämpas? Dela dina tankar i kommentarsfältet nedan.