Det har varit många diskussioner om In-Memory OLTP (funktionen tidigare känd som "Hekaton") och hur den kan hjälpa mycket specifika, högvolymer arbetsbelastningar. Mitt i en annan konversation råkade jag märka något i CREATE TYPE dokumentation för SQL Server 2014 som fick mig att tro att det kan finnas ett mer allmänt användningsfall:

Relativt tysta och oförutsedda tillägg till CREATE TYPE-dokumentationen
Baserat på syntaxdiagrammet verkar det som om tabellvärderade parametrar (TVP) kan minnesoptimeras, precis som permanenta tabeller kan. Och med det började hjulen genast snurra.
En sak jag har använt TVP till är att hjälpa kunder att eliminera dyra strängdelningsmetoder i T-SQL eller CLR (se bakgrund i tidigare inlägg här, här och här). I mina tester överträffade jag med en vanlig TVP motsvarande mönster med CLR- eller T-SQL-delningsfunktioner med en betydande marginal (25-50%). Jag undrade logiskt:Skulle det finnas någon prestandavinst från en minnesoptimerad TVP?
Det har funnits en viss oro för In-Memory OLTP i allmänhet, eftersom det finns många begränsningar och funktionsluckor, du behöver en separat filgrupp för minnesoptimerad data, du måste flytta hela tabeller till minnesoptimerade, och den bästa fördelen är vanligtvis uppnås genom att också skapa inbyggt kompilerade lagrade procedurer (som har sina egna begränsningar). Som jag ska visa, om du antar att din tabelltyp innehåller enkla datastrukturer (t.ex. representerar en uppsättning heltal eller strängar), eliminerar användningen av denna teknik bara för TVP:er en del av dessa frågor.
Testet
Du kommer fortfarande att behöva en minnesoptimerad filgrupp även om du inte ska skapa permanenta, minnesoptimerade tabeller. Så låt oss skapa en ny databas med lämplig struktur på plats:
SKAPA DATABAS xtp;GOALTER DATABAS xtp LÄGG TILL FILGROUP xtp INNEHÅLLER MEMORY_OPTIMIZED_DATA;GOALTER DATABAS xtp LÄGG TILL FIL (name='xtpmod', filnamn='c:\...\xtp.mod') TILL FILEGROUP; SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT =PÅ;GO
Nu kan vi skapa en vanlig tabelltyp, som vi skulle göra idag, och en minnesoptimerad tabelltyp med ett icke-klustrat hashindex och en bucket count som jag drog ur luften (mer information om beräkning av minneskrav och bucket count i den verkliga världen här):
ANVÄND xtp;GO CREATE TYPE dbo.ClassicTVP AS TABLE( Item INT PRIMARY KEY); CREATE TYPE dbo.InMemoryTVP AS TABLE( Item INT NOT NULL PRIMARY KEY ONCLUSTED HASH WITH (BUCKET_COUNT =256)) WITH (MEMORY_OPTIMIZED =ON);
Om du provar detta i en databas som inte har en minnesoptimerad filgrupp får du detta felmeddelande, precis som du skulle göra om du försökte skapa en normal minnesoptimerad tabell:
Msg 41337, Level 16, State 0, Rad 9MEMORY_OPTIMIZED_DATA filgruppen finns inte eller är tom. Minnesoptimerade tabeller kan inte skapas för en databas förrän den har en MEMORY_OPTIMIZED_DATA filgrupp som inte är tom.
För att testa en fråga mot en vanlig, icke-minnesoptimerad tabell, drog jag helt enkelt en del data till en ny tabell från exempeldatabasen AdventureWorks2012 med SELECT INTO för att ignorera alla dessa irriterande begränsningar, index och utökade egenskaper, skapade sedan ett klustrat index på kolumnen som jag visste att jag skulle söka på (ProductID ):
VÄLJ * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rader SKAPA UNIKT CLUSTERED INDEX p PÅ dbo.Products(ProductID);
Därefter skapade jag fyra lagrade procedurer:två för varje tabelltyp; var och en använder EXISTS och JOIN metoder (jag gillar vanligtvis att undersöka båda, även om jag föredrar EXISTS; senare kommer du att se varför jag inte ville begränsa mina tester till att bara EXISTS ). I det här fallet tilldelar jag bara en godtycklig rad till en variabel, så att jag kan observera höga antal exekveringar utan att ta itu med resultatuppsättningar och annan utdata och overhead:
-- Old-school TVP med EXISTS:CREATE PROCEDURE dbo.ClassicTVP_Exists @Classic dbo.ClassicTVP READONLYASBÖRJAN STÄLL IN NOCOUNT ON; DECLARE @name NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p WHERE EXISTS ( SELECT 1 FROM @Classic AS t WHERE t.Item =p.ProductID );ENDGO -- In-Memory TVP med EXISTS:CREATE PROCEDURE dbo.InMemoryTVP_Exists @InMemory dbo.InMemoryTVP READONLYASBÖRJA STÄLL IN NOCOUNT PÅ; DECLARE @name NVARCHAR(50); VÄLJ @name =p.Name FROM dbo.Products AS p WHERE EXISTS (VÄLJ 1 FROM @InMemory AS t WHERE t.Item =p.ProductID );ENDGO -- Old-school TVP med en JOIN:CREATE PROCEDURE dbo.ClassicTVP_Join @ Classic dbo.ClassicTVP LÄSONLYASBÖRJAN STÄLLA IN NOCOUNT PÅ; DECLARE @name NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p INNER JOIN @Classic AS t ON t.Item =p.ProductID;ENDGO -- In-Memory TVP med en JOIN:CREATE PROCEDUR dbo.InMemoryTVP_Join @InMemory dbo.InMemoryTVP READONLY STÄLL IN ANTALT PÅ; DECLARE @name NVARCHAR(50); VÄLJ @namn =p.Namn FRÅN dbo.Products AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;ENDGO
Därefter behövde jag simulera den typ av fråga som vanligtvis kommer mot denna typ av tabell och kräver ett TVP eller liknande mönster i första hand. Föreställ dig ett formulär med en rullgardinsmeny eller en uppsättning kryssrutor som innehåller en lista med produkter, och användaren kan välja de 20 eller 50 eller 200 som de vill jämföra, lista, vad har du. Värdena kommer inte att vara i en trevlig sammanhängande uppsättning; de kommer vanligtvis att vara utspridda överallt (om det var ett förutsägbart sammanhängande intervall skulle frågan vara mycket enklare:start- och slutvärden). Så jag valde bara 20 godtyckliga värden från tabellen (försökte hålla mig under, säg, 5% av tabellstorleken), ordnade slumpmässigt. Ett enkelt sätt att bygga en återanvändbar VALUES klausul som denna är som följer:
DECLARE @x VARCHAR(4000) =''; VÄLJ TOP (20) @x +='(' + RTRIM(ProduktID) + '),' FRÅN dbo.Produkter BESTÄLLS MED NEWID(); VÄLJ @x; Resultaten (dina kommer nästan säkert att variera):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735) ),(441),(409),(454),(780),(966),(988),(512),
Till skillnad från en direkt INSERT...SELECT , detta gör det ganska enkelt att manipulera den utdatan till ett återanvändbart uttalande för att fylla våra TVP:er upprepade gånger med samma värden och under flera iterationer av testning:
STÄLL IN NOCOUNT PÅ; DECLARE @ClassicTVP dbo.ClassicTVP;DECLARE @InMemoryTVP dbo.InMemoryTVP; INFOGA @ClassicTVP(Artikel) VÄRDEN (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Artikel) VÄRDEN (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP;EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Join @InMemoryTVP_Join @InMemoryTVP_Join @InMemoryTVP_JoinOm vi kör den här batchen med SQL Sentry Plan Explorer visar de resulterande planerna en stor skillnad:TVP i minnet kan använda en kapslad loop-join och 20 enrads klustrade indexsökningar, jämfört med en sammanfogning som matas 502 rader av en klustrad indexsökning för den klassiska TVP. Och i det här fallet, EXISTS och JOIN gav identiska planer. Detta kan tippa med ett mycket högre antal värden, men låt oss fortsätta med antagandet att antalet värden kommer att vara mindre än 5 % av tabellstorleken:
Planer för klassiska TVP och In-Memory TVP
Verktygstips för skannings-/sökoperatorer som lyfter fram stora skillnader – klassiskt till vänster, in- Minne till höger
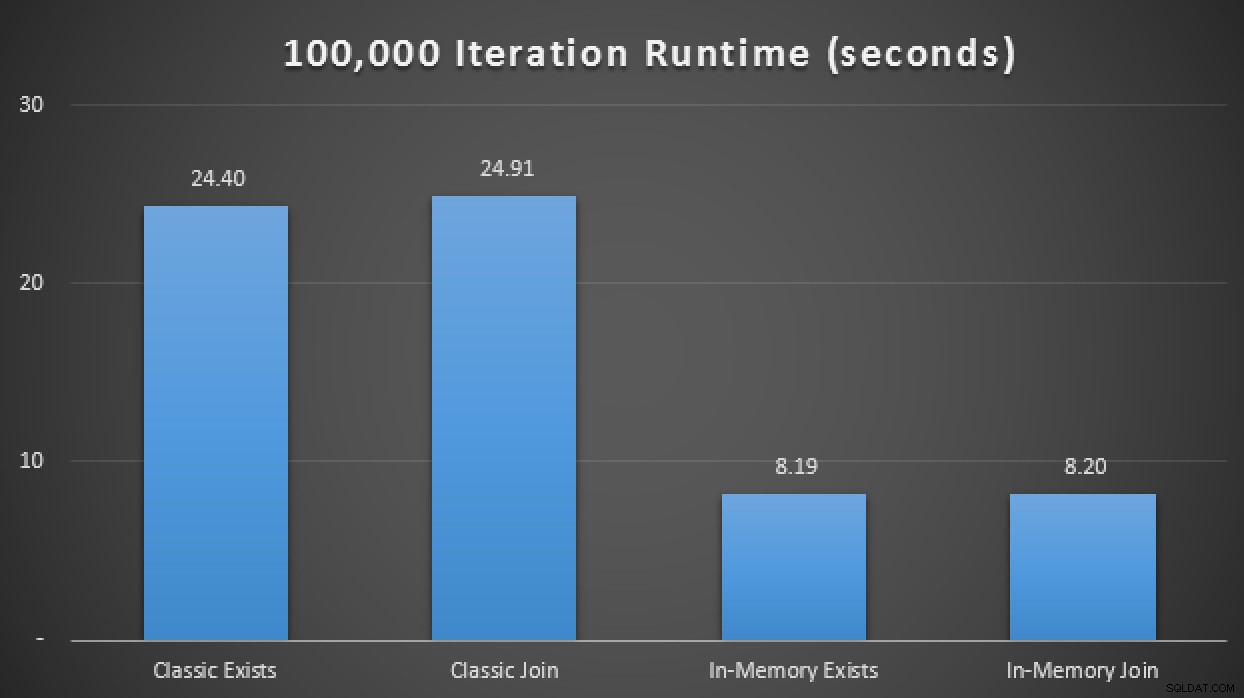
Vad betyder nu detta i skala? Låt oss stänga av alla showplan-samlingar och ändra testskriptet något för att köra varje procedur 100 000 gånger, och fånga upp kumulativ körtid manuellt:
DEKLARE @i TINYINT =1, @j INT =1; WHILE @i <=4BEGIN VÄLJ SYSDATETIME(); WHILE @j <=100000 BEGIN IF @i =1 BEGIN EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP; END IF @i =2 BÖRJA EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP; END IF @i =3 BÖRJA EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP; END IF @i =4 BÖRJA EXEC dbo.InMemoryTVP_Join @InMemory =@InMemoryTVP; END SET @j +=1; END SELECT @i +=1, @j =1;END SELECT SYSDATETIME();I resultaten, i genomsnitt över 10 körningar, ser vi att, åtminstone i detta begränsade testfall, att använda en minnesoptimerad tabelltyp gav en ungefär 3X förbättring av det utan tvekan mest kritiska prestandamåttet i OLTP (runtime duration):
Runtime-resultat som visar en 3X förbättring med In-Memory TVPs em>In-Memory + In-Memory + In-Memory:In-Memory Inception
Nu när vi har sett vad vi kan göra genom att helt enkelt ändra vår vanliga tabelltyp till en minnesoptimerad tabelltyp, låt oss se om vi kan pressa ut någon mer prestanda ur samma frågemönster när vi tillämpar trifecta:ett i minnet tabell, med en inbyggt kompilerad minnesoptimerad lagrad procedur, som accepterar en tabell i minnet som en tabellvärderad parameter.
Först måste vi skapa en ny kopia av tabellen och fylla i den från den lokala tabellen som vi redan skapat:
CREATE TABLE dbo.Products_InMemory( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, Product Number NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlagga BIT NULL, Color NVARCHAR(ALLINTStock NOT NULL) , ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL DaysToManufacture INT NOT NULL, Produktlinje NCHAR(2) NULL, [Klass] NCHAR(2) NULL, Stil NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, Se llStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMÄRNYCKEL INKLUSTERAD HASH (Produkt-ID) WITH (BUCKET 6)_COUNT) =2D-5 ME_6)_OPT =2, EMAIL, ANTAL_2. INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;Därefter skapar vi en inbyggt kompilerad lagrad procedur som tar vår befintliga minnesoptimerade tabelltyp som en TVP:
SKAPA PROCEDUR dbo.InMemoryProcedure @InMemory dbo.InMemoryTVP READONLYWITH NATIVE_COMPILATION, SCHEMABINDING, UTFÖR SOM ÄGARE SOM BÖRJA ATOMIC WITH (TRANSACTION ISOLATION LEVEL =SNAPSHOT,'us_english N'); DECLARE @Name NVARCHAR(50); SELECT @Name =Name FROM dbo.Products_InMemory AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;END GOEtt par varningar. Vi kan inte använda en vanlig, icke-minnesoptimerad tabelltyp som en parameter för en inbyggt kompilerad lagrad procedur. Om vi försöker får vi:
Msg 41323, Level 16, State 1, Procedure InMemoryProcedure
Tabelltypen 'dbo.ClassicTVP' är inte en minnesoptimerad tabelltyp och kan inte användas i en inbyggt kompilerad lagrad procedur.Dessutom kan vi inte använda
Msg 12311, Level 16, State 37, Procedure NativeCompiled_ExistsEXISTSmönster här heller; när vi försöker får vi:
Subqueries (frågor kapslade inuti en annan fråga) stöds inte med inbyggt kompilerade lagrade procedurer.Det finns många andra varningar och begränsningar med In-Memory OLTP och inbyggt kompilerade lagrade procedurer, jag ville bara dela med mig av ett par saker som uppenbarligen kan tyckas saknas i testningen.
Så genom att lägga till denna nya inbyggt kompilerade lagrade procedur till testmatrisen ovan, fann jag att den – återigen, i genomsnitt över 10 körningar – körde de 100 000 iterationerna på bara 1,25 sekunder. Detta representerar ungefär en 20X förbättring jämfört med vanliga TVP:er och en 6-7X förbättring jämfört med TVP i minnet med traditionella tabeller och procedurer:
Runtime-resultat som visar upp till 20X förbättring med In-Memory runt omSlutsats
Om du använder TVP:er nu, eller om du använder mönster som kan ersättas av TVP:er, måste du absolut överväga att lägga till minnesoptimerade TVP:er till dina testplaner, men kom ihåg att du kanske inte ser samma förbättringar i ditt scenario. (Och, naturligtvis, med tanke på att TVP:er i allmänhet har många varningar och begränsningar, och de är inte heller lämpliga för alla scenarier. Erland Sommarskog har en bra artikel om dagens TVP här.)
Faktum är att du kanske ser att det inte är någon skillnad i den lägre delen av volym och samtidighet – men testa i realistisk skala. Detta var ett väldigt enkelt och konstruerat test på en modern bärbar dator med en enda SSD, men när du pratar om verklig volym och/eller spinniga mekaniska diskar, kan dessa prestandaegenskaper väga mycket mer. Det kommer en uppföljning med några demonstrationer av större datastorlekar.