"Men det gick bra på vår utvecklingsserver!"
Hur många gånger hörde jag det när SQL-frågeprestandaproblem uppstod här och där? Jag sa det själv förr i tiden. Jag antog att en fråga som körs på mindre än en sekund skulle fungera bra i produktionsservrar. Men jag hade fel.
Kan du relatera till denna upplevelse? Om du fortfarande är i den här båten idag av någon anledning, är det här inlägget för dig. Det kommer att ge dig ett bättre mätvärde för att finjustera din SQL-frågeprestanda. Vi kommer att prata om tre av de mest kritiska siffrorna i STATISTICS IO.
Som ett exempel kommer vi att använda exempeldatabasen AdventureWorks.
Innan du börjar köra frågor nedan, aktivera STATISTICS IO. Så här gör du i ett frågefönster:
USE AdventureWorks
GO
SET STATISTICS IO ONNär du kör en fråga med STATISTICS IO PÅ kommer olika meddelanden att visas. Du kan se dessa på fliken Meddelanden i frågefönstret i SQL Server Management Studio (se figur 1):
Nu när vi är klara med det korta introt, låt oss gräva djupare.
1. Höga logiska läsningar
Den första punkten i vår lista är den vanligaste boven – höga logiska läsningar.
Logiska läsningar är antalet sidor som läses från datacachen. En sida är 8KB stor. Datacache, å andra sidan, hänvisar till RAM som används av SQL Server.
Logisk läsning är avgörande för prestandajustering. Denna faktor definierar hur mycket en SQL Server behöver för att producera den önskade resultatuppsättningen. Därför är det enda att komma ihåg:ju högre de logiska läsningarna är, desto längre tid behöver SQL-servern fungera. Det betyder att din fråga blir långsammare. Minska antalet logiska läsningar och du kommer att öka din frågeprestanda.
Men varför använda logiska läsningar istället för förfluten tid?
- Förfluten tid beror på andra saker som görs av servern, inte bara din fråga ensam.
- Förfluten tid kan ändras från utvecklingsserver till produktionsserver. Detta händer när båda servrarna har olika kapacitet och hårdvaru- och mjukvarukonfigurationer.
Om du förlitar dig på förfluten tid kommer du att säga, "Men det gick bra i vår utvecklingsserver!" förr eller senare.
Varför använda logiska läsningar istället för fysiska läsningar?
- Fysiska läsningar är antalet sidor som läses från diskar till datacache (i minnet). När sidorna som behövs i en fråga finns i datacachen, behöver du inte läsa om dem från diskar.
- När samma fråga körs igen kommer fysiska läsningar att vara noll.
Logiska läsningar är det logiska valet för att finjustera SQL-frågeprestanda.
För att se detta i praktiken, låt oss gå vidare till ett exempel.
Exempel på logiska läsningar
Anta att du behöver få listan över kunder med beställningar som skickades den 11 juli 2011. Du kommer på den här ganska enkla frågan nedan:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'Det är okomplicerat. Den här frågan kommer att ha följande utdata:

Sedan kontrollerar du STATISTICS IO-resultatet av denna fråga:

Utdata visar de logiska läsningarna av var och en av de fyra tabellerna som används i frågan. Totalt är summan av de logiska läsningarna 729. Du kan också se fysiska läsningar med en total summa av 21. Men försök att köra frågan igen, så blir den noll.
Ta en närmare titt på de logiska läsningarna av SalesOrderHeader . Undrar du varför den har 689 logiska läsningar? Du kanske tänkte inspektera nedanstående frågas genomförandeplan:
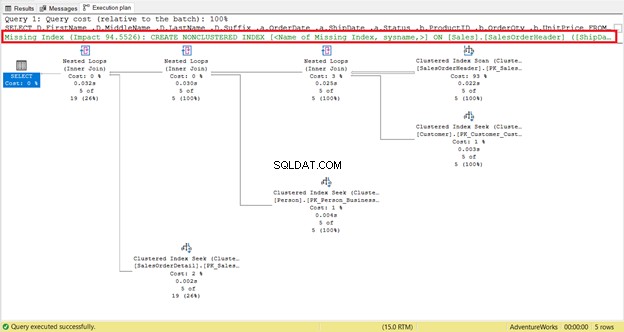
För det första finns det en indexsökning som skedde i SalesOrderHeader med en kostnad på 93 %. Vad kan hända? Anta att du har kontrollerat dess egenskaper:
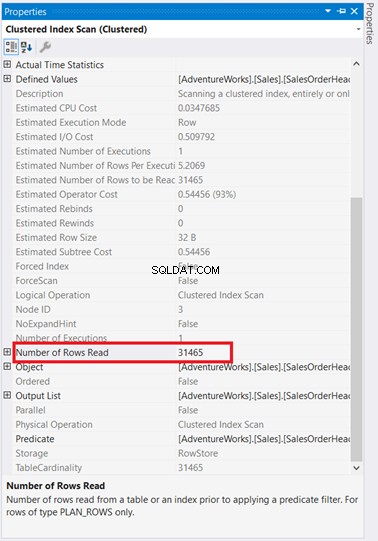
Oj! 31 465 rader lästa för endast 5 rader returnerade? Det är absurt!
Minska antalet logiska läsningar
Det är inte så svårt att minska de 31 465 raderna som läses. SQL Server har redan gett oss en ledtråd. Fortsätt till följande:
STEG 1:Följ SQL Servers rekommendation och lägg till det saknade indexet
Har du märkt att indexrekommendationen saknas i genomförandeplanen (Figur 4)? Kommer det att lösa problemet?
Det finns ett sätt att ta reda på:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Kör frågan igen och se ändringarna i STATISTICS IO logiska läsningar.

Som du kan se i STATISTICS IO (Figur 6), finns det en enorm minskning av logiska avläsningar från 689 till 17. De nya övergripande logiska avläsningarna är 57, vilket är en betydande förbättring från 729 logiska avläsningar. Men för att vara säker, låt oss inspektera genomförandeplanen igen.
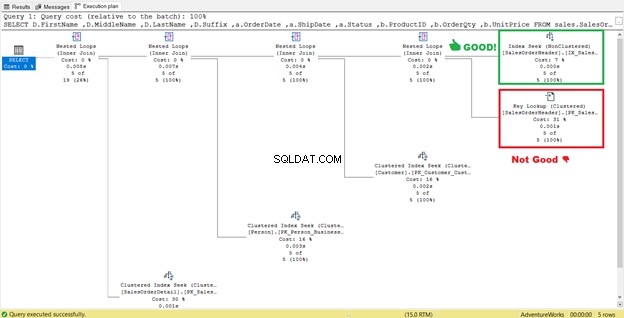
Det verkar som att det finns en förbättring i planen som resulterar i minskade logiska läsningar. Indexsökningen är nu en indexsökning. SQL Server behöver inte längre inspektera rad för rad för att få posterna med Shipdate=’07/11/2011′ . Men något lurar fortfarande i den planen, och det stämmer inte.
Du behöver steg 2.
STEG 2:Ändra indexet och lägg till i inkluderade kolumner:OrderDate, Status och CustomerID
Ser du den där Key Lookup-operatören i utförandeplanen (Figur 7)? Det betyder att det skapade icke-klustrade indexet inte räcker – frågeprocessorn måste använda det klustrade indexet igen.
Låt oss kontrollera dess egenskaper.
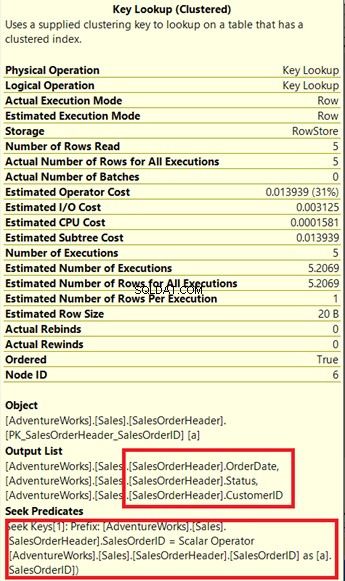
Notera den bifogade rutan under Utdatalista . Det händer att vi behöver OrderDate , Status och Kund-ID i resultatuppsättningen. För att få dessa värden använde frågeprocessorn det klustrade indexet (se Seek Predicates ) för att komma till bordet.
Vi måste ta bort nyckelsökningen. Lösningen är att inkludera OrderDate , Status och Kund-ID kolumner i indexet som skapats tidigare.
- Högerklicka på IX_SalesOrderHeader_ShipDate i SSMS.
- Välj Egenskaper .
- Klicka på Inkluderade kolumner flik.
- Lägg till Beställningsdatum , Status och Kund-ID .
- Klicka på OK .
När du har återskapat indexet kör du frågan igen. Kommer detta att ta bort Nyckelsökning och minska logiska läsningar?

Det fungerade! Från 17 logiska läsningar ner till 2 (Figur 9).
Och Nyckelsökning ?
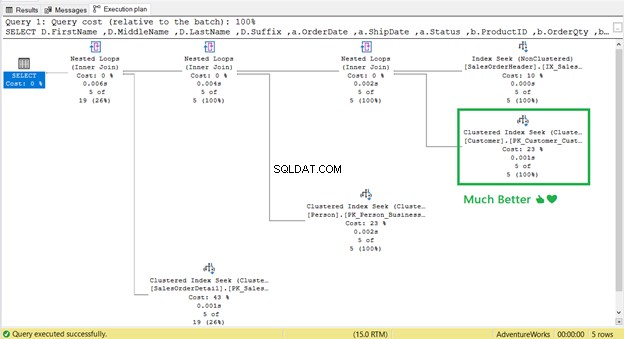
Det är borta! Klustrad indexsökning har ersatt Key Lookup.
The Takeaway
Så vad har vi lärt oss?
Ett av de primära sätten att minska logiska läsningar och förbättra SQL-frågeprestanda är att skapa ett lämpligt index. Men det finns en hake. I vårt exempel minskade det de logiska läsningarna. Ibland blir motsatsen rätt. Det kan också påverka prestanda för andra relaterade frågor.
Kontrollera därför alltid STATISTICS IO och exekveringsplanen efter att du har skapat indexet.
2. Hög lobb logisk läsning
Det är ungefär samma sak som punkt #1, men det kommer att behandla datatyper text , ntext , bild , varchar (max ), nvarchar (max ), varbinary (max ), eller columnstore indexsidor.
Låt oss hänvisa till ett exempel:generering av logiska läsningar.
Exempel på Lob Logical Reads
Anta att du vill visa en produkt med dess pris, färg, miniatyrbild och en större bild på en webbsida. Således kommer du med en första fråga som visas nedan:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorSedan kör du den och ser utdata som nedan:

Eftersom du är en så högpresterande kille (eller tjej), kollar du genast STATISTICS IO. Här är den:

Det känns som lite smuts i ögonen. 665 lob logiska läsningar? Du kan inte acceptera detta. För att inte tala om 194 logiska läsningar vardera från ProductPhoto och ProductProductPhoto tabeller. Du tror verkligen att den här frågan behöver några ändringar.
Reducera Lob Logical Reads
Den föregående frågan hade 97 rader returnerade. Alla 97 cyklar. Tycker du att det här är bra att visa på en webbsida?
Ett index kan hjälpa, men varför inte förenkla frågan först? På så sätt kan du vara selektiv med vad SQL Server kommer att returnera. Du kan minska lobens logiska läsningar.
- Lägg till ett filter för produktunderkategorin och låt kunden välja. Inkludera sedan detta i WHERE-satsen.
- Ta bort Produktunderkategorin eftersom du kommer att lägga till ett filter för produktunderkategorin.
- Ta bort LargePhoto kolumn. Fråga detta när användaren väljer en specifik produkt.
- Använd personsökning. Kunden kommer inte att kunna se alla 97 cyklar samtidigt.
Baserat på dessa operationer som beskrivs ovan ändrar vi frågan enligt följande:
- Ta bort Produktunderkategori och LargePhoto kolumner från resultatuppsättningen.
- Använd OFFSET och FETCH för att hantera personsökning i frågan. Fråga endast 10 produkter åt gången.
- Lägg till ProductSubcategoryID i WHERE-klausulen baserat på kundens val.
- Ta bort Produktunderkategorin kolumnen i ORDER BY-satsen.
Frågan kommer nu att likna denna:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Med ändringarna gjorda, kommer lob logiska läsningar att förbättras? STATISTICS IO rapporterar nu:

ProductPhoto Tabellen har nu 0 lob logiska läsningar – från 665 lob logiska läsningar ner till ingen. Det är en viss förbättring.
Hämtmat
Ett av sätten att minska loblogiska läsningar är att skriva om frågan för att förenkla den.
Ta bort onödiga kolumner och reducera de returnerade raderna till det minsta som krävs. Vid behov, använd OFFSET och FETCH för personsökning.
Kontrollera alltid STATISTICS IO för att säkerställa att frågeändringarna har förbättrat logiska läsningar och SQL-frågeprestanda.
3. Hög logisk arbetstabell/arbetsfil
Slutligen är det logisk läsning av Arbetsbar och Arbetsfil . Men vad är dessa tabeller? Varför visas de när du inte använder dem i din fråga?
Att ha arbetsbar och Arbetsfil visas i STATISTICS IO innebär att SQL Server behöver mycket mer arbete för att få önskat resultat. Den använder sig av tillfälliga tabeller i tempdb , nämligen Arbetsbord och Arbetsfiler . Det är inte nödvändigtvis skadligt att ha dem i STATISTICS IO-utgången, så länge logiska läsningar är noll och det inte orsakar problem för servern.
Dessa tabeller kan visas när det finns en ORDER BY, GROUP BY, CROSS JOIN eller DISTINCT, bland annat.
Exempel på logiska läsningar för arbetstabell/arbetsfil
Anta att du behöver fråga alla butiker utan försäljning av vissa produkter.
Du kommer först på följande:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDDenna fråga returnerade 3649 rader:
Låt oss kolla vad STATISTICS IO säger:

Det är värt att notera att Arbetstabellen logiska läsningar är 7128. De övergripande logiska läsningarna är 8853. Om du kontrollerar exekveringsplanen kommer du att se massor av parallellism, hash-matchningar, spolar och indexskanningar.
Reducera logiska läsningar för arbetsbord/arbetsfiler
Jag kunde inte konstruera en enda SELECT-sats med ett tillfredsställande resultat. Det enda valet är alltså att dela upp SELECT-satsen i flera frågor. Se nedan:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsDen är flera rader längre och den använder tillfälliga tabeller. Nu ska vi se vad STATISTICS IO avslöjar:
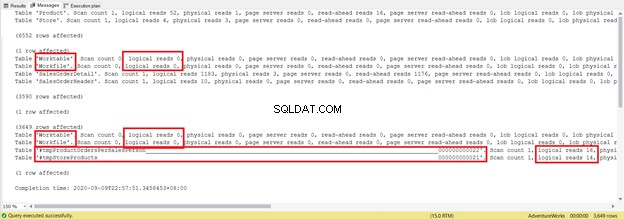
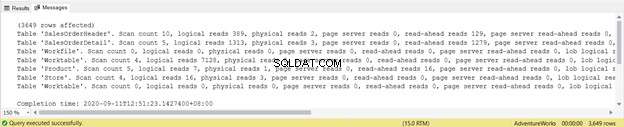
Försök att inte fokusera på denna statistiska rapportlängd – det är bara frustrerande. Lägg istället till logiska läsningar från varje tabell.
För totalt 1279 är det en betydande minskning, eftersom det var 8853 logiska läsningar från den enda SELECT-satsen.
Vi har inte lagt till något index i de tillfälliga tabellerna. Du kan behöva en om många fler poster läggs till i SalesOrderHeader och SalesOrderDetail . Men du förstår poängen.
Hämtmat
Ibland verkar 1 SELECT-sats bra. Men bakom kulisserna är det tvärtom. Arbetsbord och Arbetsfiler med hög logisk läsfördröjning din SQL-frågeprestanda.
Om du inte kan komma på ett annat sätt att rekonstruera frågan och indexen är oanvändbara, prova "dela och erövra"-metoden. Arbetsborden och Arbetsfiler kan fortfarande visas på fliken Meddelande i SSMS, men de logiska läsningarna kommer att vara noll. Därför blir det övergripande resultatet mindre logiska avläsningar.
Bottomline i SQL Query Performance and STATISTICS IO
Vad är grejen med dessa tre otäcka I/O-statistik?
Skillnaden i SQL-frågeprestanda blir som natt och dag om du uppmärksammar dessa siffror och sänker dem. Vi har bara presenterat några sätt att minska logiska läsningar som:
- skapa lämpliga index;
- förenkla frågor – ta bort onödiga kolumner och minimera resultatuppsättningen;
- dela upp en fråga i flera frågor.
Det finns mer som att uppdatera statistik, defragmentera index och ställa in rätt FILLFACTOR. Kan du lägga till mer till detta i kommentarsfältet?
Om du gillar det här inlägget, vänligen dela det med dina favorit sociala medier.