Virtuell IP-adress är en IP-adress som inte motsvarar ett verkligt fysiskt nätverksgränssnitt. Det flyter mellan flera nätverksgränssnitt och endast ett aktivt gränssnitt kommer att hålla IP-adressen för feltolerans och mobilitet. ClusterControl använder Keepalved för att tillhandahålla virtuell IP-adressintegration med databasbelastningsutjämnare för att eliminera varje enskild felpunkt (SPOF) på lastbalanseringsnivån.
I det här blogginlägget visar vi dig hur ClusterControl konfigurerar virtuell IP-adress och vad du kan förvänta dig när failover eller failback inträffar. Att förstå detta beteende är avgörande för att minimera eventuella serviceavbrott och förenkla underhållsåtgärder som behöver utföras ibland.
Krav
Det finns några krav för att köra Keepalived i ditt nätverk:
- IP-protokoll 112 (Virtual Router Redundancy Protocol - VRRP) måste stödjas i nätverket. Vissa nätverk inaktiverar stöd för VRRP, särskilt inter-VLAN-kommunikation. Kontrollera detta med nätverksadministratören.
- Om du använder multicast måste nätverket stödja multicast-begäran (använd ip a | grep -i multicast). Annars kan du använda unicast via unicast_src_ip och unicast_peer alternativ. Att använda multicast är användbart när du har en dynamisk miljö som en molnmiljö, eller när IP-tilldelning utförs via DHCP.
- En uppsättning VRRP-instanser måste använda ett unikt virtual_router_id värde, som inte kan delas mellan andra instanser. Annars kommer du att se falska paket och kommer sannolikt att bryta omkopplaren för master-backup.
- Om du kör i en molnmiljö som AWS behöver du förmodligen använda ett externt skript (tips:använd alternativet "notify") för att dissociera och associera den virtuella IP-adressen (elastisk IP) så att den känns igen och routbar av routern.
Distribuera Keepalived
För att installera Keepalved genom ClusterControl behöver du två eller flera lastbalanserare installerade av eller importerade till ClusterControl. För produktionsanvändning rekommenderar vi starkt att lastbalanseraren körs på en fristående värd och inte samlokaliseras med dina databasnoder.
När du har minst två lastbalanserare som hanteras av ClusterControl, för att installera Keepalived och aktivera virtuell IP-adress, gå bara till ClusterControl -> välj klustret -> Hantera -> Load Balancer -> Keepalived:
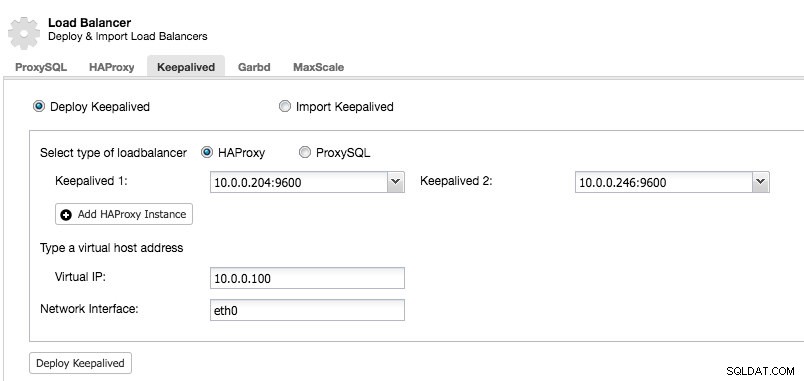
De flesta av fälten är självförklarande. Du kan distribuera en ny uppsättning Keepalved eller importera befintliga Keepalived-instanser. De viktiga fälten inkluderar den faktiska virtuella IP-adressen och nätverksgränssnittet där den virtuella IP-adressen kommer att finnas. Om värdarna använder två olika gränssnittsnamn, ange gränssnittsnamnet på Keepalved 1-värden och ändra sedan manuellt konfigurationsfilen på Keepalved 2 med ett korrekt gränssnittsnamn senare.
VRRP-instans
I skrivande stund installerar ClusterControl v1.5.1 Keepalived v1.3.5 (beroende på värdoperativsystemet) och följande är vad som är konfigurerat för VRRP-instansen:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl konfigurerar VRRP-instansen för att kommunicera via unicast. Med unicast måste vi definiera alla unicast-kamrater i de andra Keepalved-noderna. Det är mindre dynamiskt men fungerar för det mesta. Med multicast kan du ta bort dessa linjer (unicast_*) och lita på multicast IP-adress för värdupptäckt och peering. Det är enklare men det blockeras vanligtvis av nätverksadministratörer.
Nästa del är den virtuella IP-adressen. Du kan ange flera virtuella IP-adresser per VRRP-instans, separerade med en ny rad. Lastbalansering i HAProxy/ProxySQL och Keepalved samtidigt kräver också möjligheten att binda till en IP-adress som är icke-lokal, vilket innebär att den inte är tilldelad en enhet på det lokala systemet. Detta gör att en belastningsbalanseringsinstans som körs kan binda till en IP som inte är lokal för failover. Således konfigurerar ClusterControl också net.ipv4.ip_nonlocal_bind=1 inuti /etc/sysctl.conf.
Nästa direktiv är track_script , där du kan specificera skriptet till hälsokontrollprocessen som förklaras i nästa avsnitt.
Hälsokontroller
ClusterControl konfigurerar Keepalved för att utföra hälsokontroller genom att undersöka felkoden som returneras av track_script. I Keepalived-konfigurationsfilen, som som standard finns på /etc/keepalived/keepalived.conf, bör du se något i stil med detta:
track_script {
chk_proxysql
}Där den anropar chk_proxysql som innehåller:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}Kommandot "killall -0" returnerar exit-kod 0 om det finns en process som kallas "proxysql" som körs på värden. Annars skulle instansen behöva sänka sig själv och börja initiera failover som förklaras i nästa avsnitt. Notera att Keepalived också stöder Linux Virtual Server (LVS)-komponenter för att utföra hälsokontroller, där den också kan lastbalanserande TCP/IP-anslutningar, liknande HAProxy, men det ligger utanför det här blogginläggets omfattning.
Simulerande failover
För VRRP-komponenter använder Keepalved VRRP-protokoll (IP-protokoll 112) för att kommunicera mellan VRRP-instanser. Det högre prioritetsvärdet för en MASTER betyder att mastern alltid kommer att ha högre behörighet att hålla den virtuella IP-adressen, såvida du inte konfigurerar instansen med "nopreempt". Låt oss använda ett exempel för att bättre förklara failover- och failback-flödet. Tänk på följande diagram:
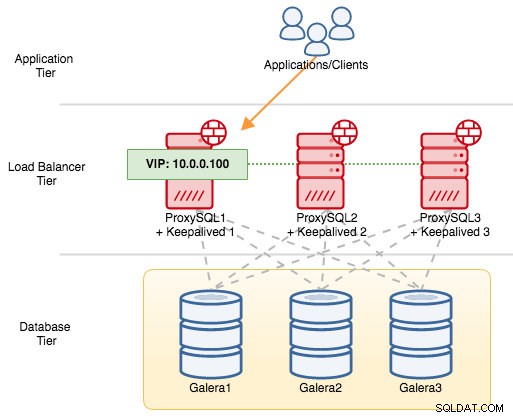
Det finns tre ProxySQL-instanser framför tre MySQL Galera-noder. Varje ProxySQL-värd är konfigurerad med Keepalved som MASTER med följande prioritetsnummer:
- ProxySQL1 - prioritet 101
- ProxySQL2 - prioritet 100
- ProxySQL3 - prioritet 99
När Keepalved startas som MASTER kommer den först att annonsera prioritetsnumret för medlemmarna och sedan associera sig med den virtuella IP-adressen. Till skillnad från BACKUP-instansen kommer den bara att observera annonsen och bara tilldela den virtuella IP-adressen när den har bekräftat att den kan upphöja sig till en MASTER.
Notera att om du dödar "proxysql"- eller "haproxy"-processen manuellt via kill-kommando, kommer systemd process manager som standard att försöka återställa processen som stoppas fult. Dessutom, om du har aktiverat automatisk återställning av ClusterControl, kommer ClusterControl alltid att försöka starta processen även om du utför en ren avstängning via systemd (systemctl stop proxysql). För att på bästa sätt simulera felet föreslår vi att användaren stänger av ClusterControls automatiska återställningsfunktion eller helt enkelt stänger av ProxySQL-servern för att bryta kommunikationen.
Om vi stänger av ProxySQL1 kommer den virtuella IP-adressen att misslyckas till nästa värd som har högre prioritet vid just den tidpunkten (som är ProxySQL2) :
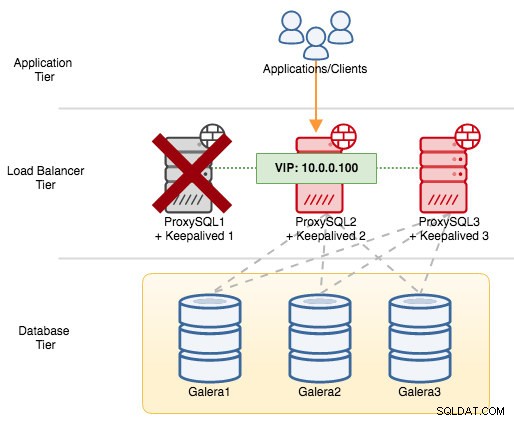
Du skulle se följande i sysloggen för den misslyckade noden:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.När du var på den sekundära noden hände följande:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.I det här fallet tog failover cirka 3 sekunder, med maximal failover-tid skulle vara intervall + advert_int . Bakom kulisserna har databasens slutpunkt ändrats och databastrafik dirigeras genom ProxySQL2 utan att applikationer märker det.
När ProxySQL1 kommer tillbaka online kommer den att tvinga fram ett nytt MASTER-val och ta över IP-adressen på grund av högre prioritet:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Samtidigt degraderar ProxySQL2 sig till BACKUP-läge och tar bort den virtuella IP-adressen från nätverksgränssnittet:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.Vid det här laget är ProxySQL1 tillbaka online och blir den aktiva lastbalanseraren som betjänar anslutningarna från applikationer och klienter. VRRP kommer normalt att föregripa en server med lägre prioritet när en server med högre prioritet kommer online. Om du vill att IP-adressen ska stanna på ProxySQL2 efter att ProxySQL1 är online igen, använd alternativet "nopreempt". Detta gör att maskinen med lägre prioritet kan behålla huvudrollen, även när en maskin med högre prioritet kommer tillbaka online. Men för att detta ska fungera måste det initiala tillståndet för denna post vara BACKUP. Annars kommer du att märka följande rad:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTEREftersom ClusterControl som standard konfigurerar alla noder som MASTER, måste du konfigurera följande konfigurationsalternativ för respektive VRRP-instans i enlighet med detta:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Starta om Keepalved-processen för att ladda dessa ändringar. Den virtuella IP-adressen kommer endast att misslyckas till ProxySQL1 eller ProxySQL3 (beroende på prioritet och vilken nod som är tillgänglig vid den tidpunkten) om hälsokontrollen misslyckas på ProxySQL2. I många fall räcker det att köra Keepalved på två värdar.