
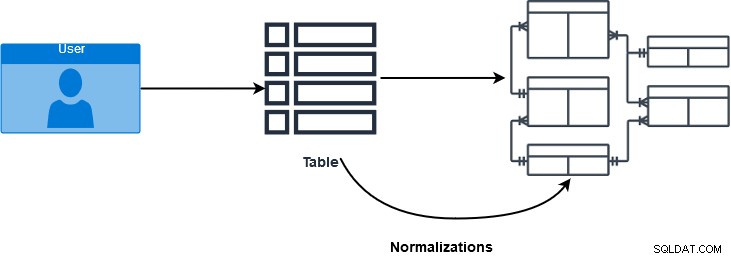
SQL JOIN är en klausul som används för att kombinera flera tabeller och hämta data baserat på ett gemensamt fält i relationsdatabaser. Databasproffs använder normaliseringar för att säkerställa och förbättra dataintegriteten. I de olika normaliseringsformerna fördelas data i flera logiska tabeller. Dessa tabeller använder referensrestriktioner – primärnyckel och främmande nycklar – för att framtvinga dataintegritet i SQL Server-tabeller. I bilden nedan får vi en glimt av databasnormaliseringsprocessen.
Förstå de olika SQL JOIN-typerna
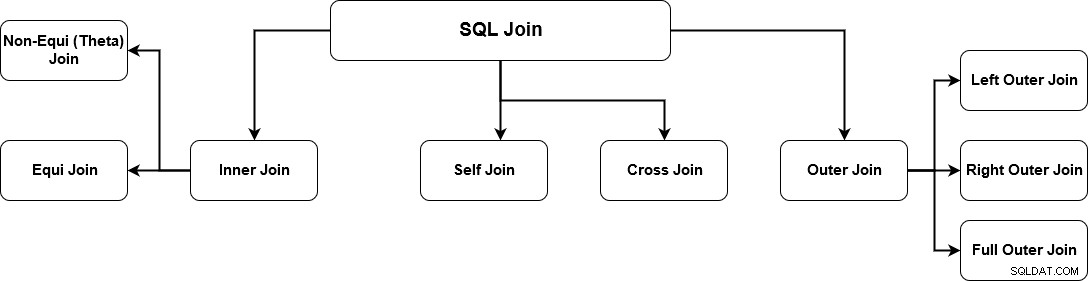
SQL JOIN genererar meningsfull data genom att kombinera flera relationstabeller. Dessa tabeller är relaterade med hjälp av en nyckel och har en-till-en- eller en-till-många-relationer. För att hämta rätt data måste du känna till datakraven och korrekta kopplingsmekanismer. SQL Server stöder flera kopplingar och varje metod har ett specifikt sätt att hämta data från flera tabeller. Bilden nedan anger vilka SQL Server-anslutningar som stöds.
SQL inre join
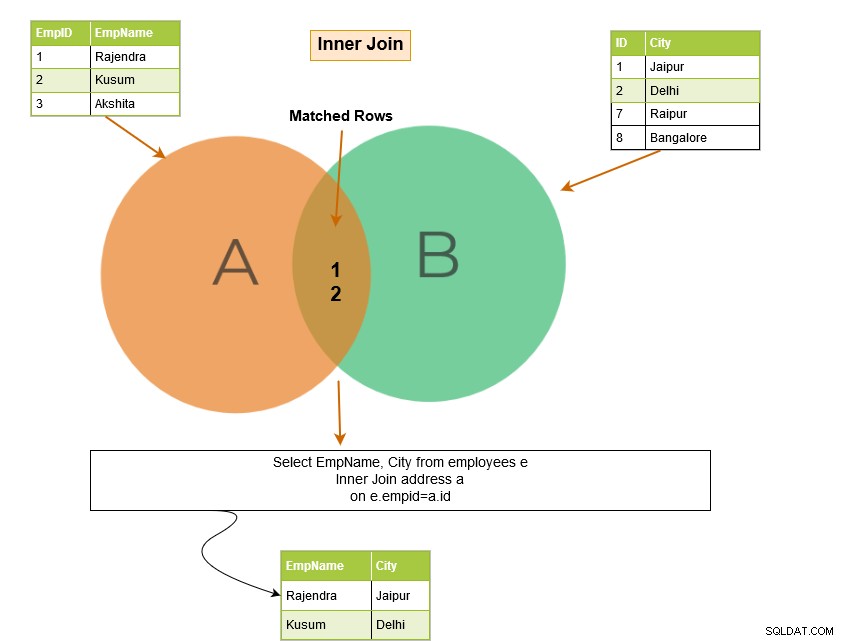
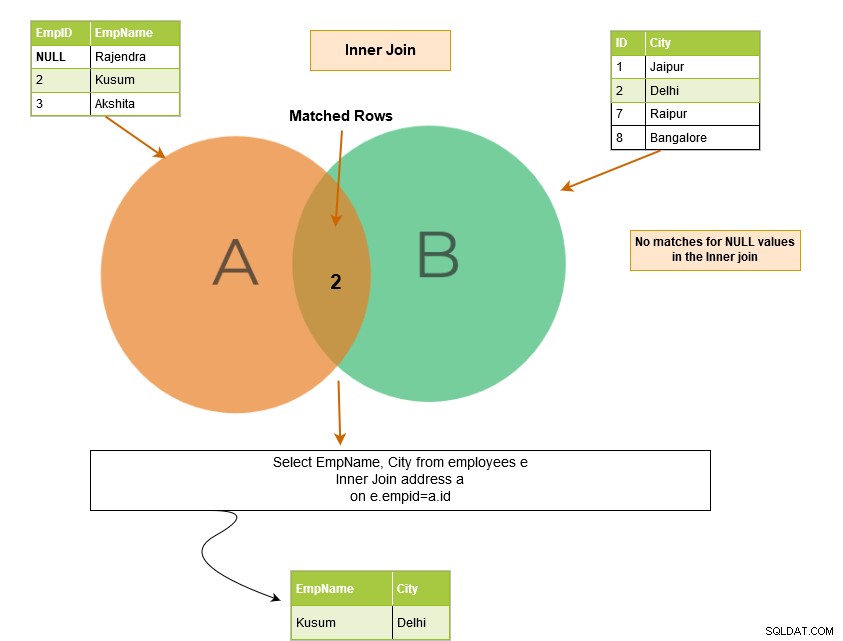
Den inre SQL-kopplingen inkluderar rader från tabellerna där kopplingsvillkoren är uppfyllda. Till exempel, i Venn-diagrammet nedan, returnerar inner join de matchande raderna från tabell A och tabell B.
Lägg märke till följande saker i exemplet nedan:
- Vi har två tabeller – [Anställda] och [Adress].
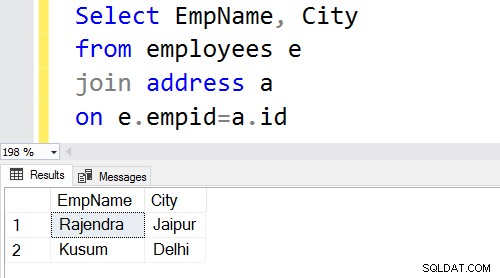
- SQL-frågan sammanfogas i kolumnerna [Anställda].[EmpID] och [Adress].[ID].
Frågeutgången returnerar anställdsposterna för EmpID som finns i båda tabellerna.
Den inre kopplingen returnerar matchande rader från båda tabellerna; därför är det också känt som Equi join. Om vi inte anger det inre nyckelordet, utför SQL Server den inre kopplingsoperationen.
I en annan typ av inre join, en theta join, använder vi inte likhetsoperatorn (=) i ON-satsen. Istället använder vi icke-likvärdiga operatorer som
VÄLJ * FRÅN Tabell1 T1, Tabell2 T2 VAR T1.Pris
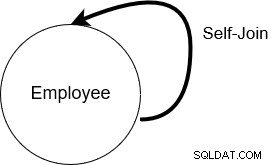
I en självanslutning förenar SQL Server tabellen med sig själv. Detta betyder att tabellnamnet förekommer två gånger i from-satsen.
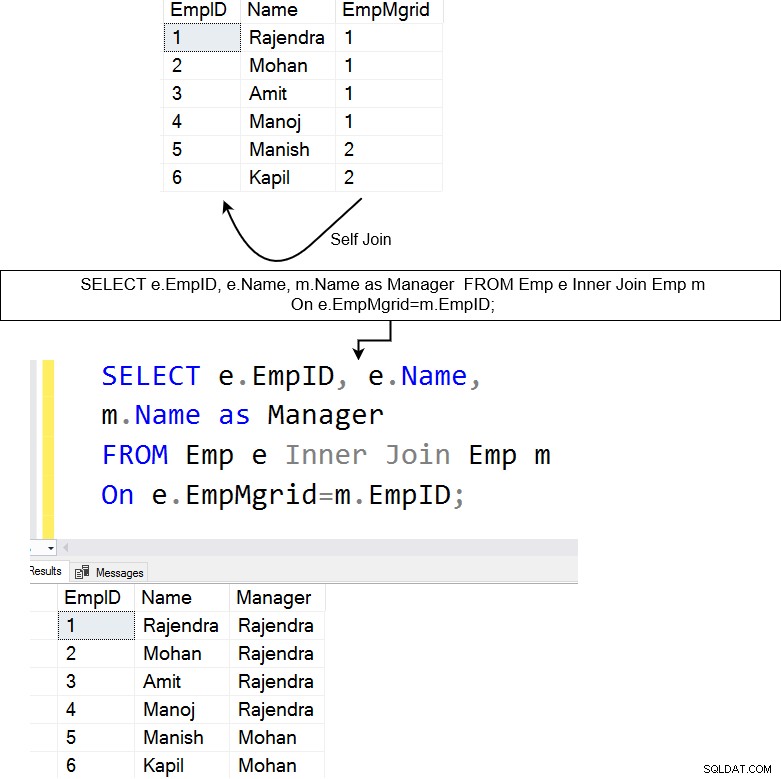
Nedan har vi en tabell [Emp] som har anställda såväl som deras chefers data. Självanslutningen är användbar för att söka efter hierarkisk data. I personaltabellen kan vi till exempel använda self-join för att lära oss varje anställd och deras rapporteringschefs namn.
Ovanstående fråga sätter en självkoppling på [Emp]-tabellen. Den förenar EmpMgrID-kolumnen med EmpID-kolumnen och returnerar de matchande raderna.
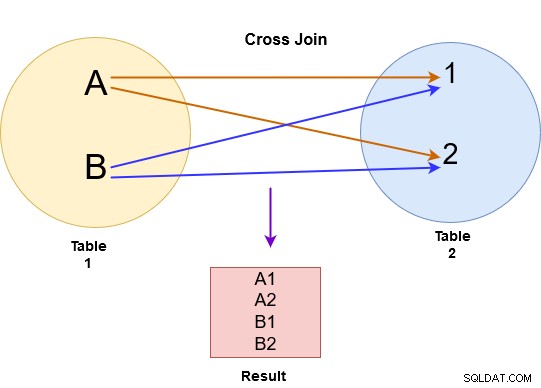
I korskopplingen returnerar SQL Server en kartesisk produkt från båda tabellerna. Till exempel, i bilden nedan utförde vi en korsfogning för tabell A och B.
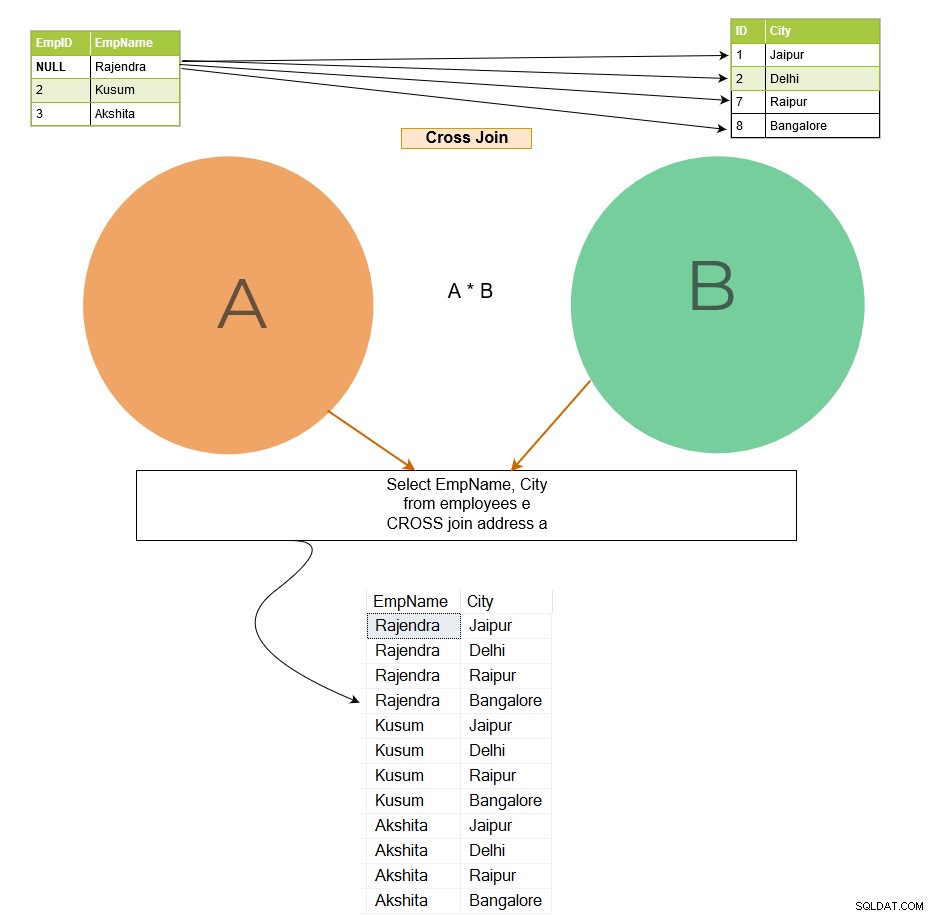
Korskopplingen förenar varje rad från tabell A till varje tillgänglig rad i tabell B. Därför är utdata också känd som en kartesisk produkt av båda tabellerna. Notera följande i bilden nedan:
I korsfogningsutgången förenas rad 1 i tabellen [Anställd] med alla rader i tabellen [Adress] och följer samma mönster för de återstående raderna.
Om den första tabellen har x antal rader och den andra tabellen har n antal rader, ger cross join x*n antal rader i utdata. Du bör undvika korskoppling på större tabeller eftersom det kan returnera ett stort antal poster och SQL Server kräver mycket datorkraft (CPU, minne och IO) för att hantera så omfattande data.
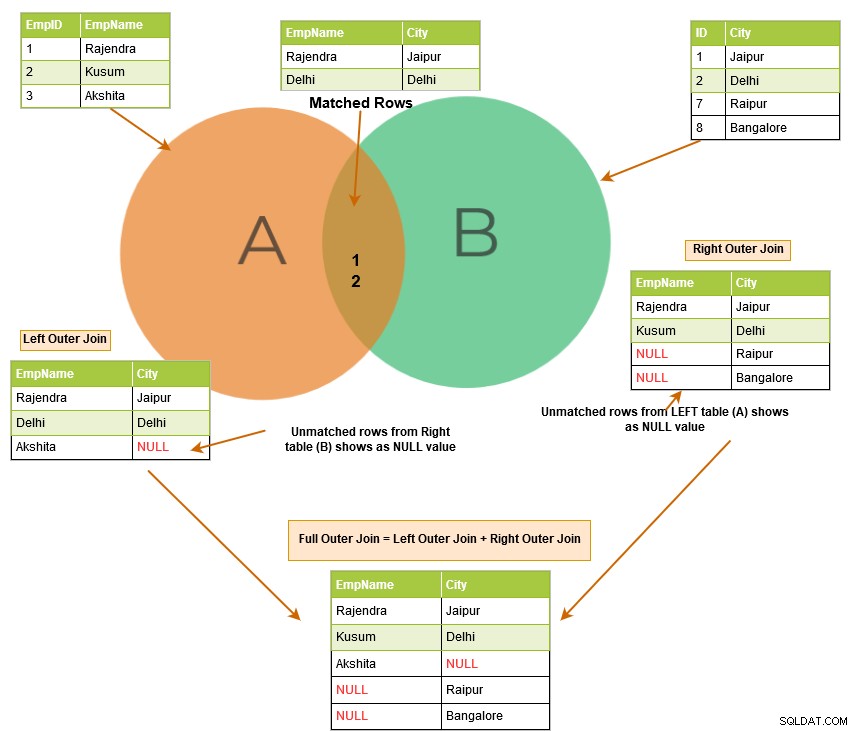
Som vi förklarade tidigare, returnerar den inre kopplingen de matchande raderna från båda tabellerna. När du använder en yttre SQL-koppling listar den inte bara de matchande raderna, utan den returnerar också de omatchade raderna från de andra tabellerna. Den omatchade raden beror på de vänstra, högra eller fullständiga sökorden.
Bilden nedan beskriver på hög nivå vänster, höger och fullständig yttre sammanfogning.
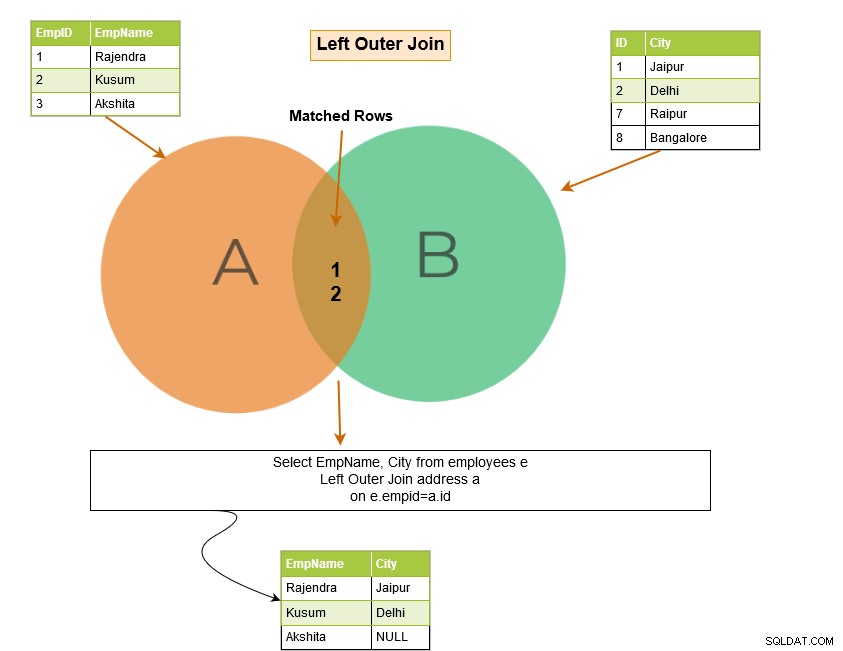
SQL left outer join returnerar de matchande raderna i båda tabellerna tillsammans med de omatchade raderna från den vänstra tabellen. Om en post från den vänstra tabellen inte har några matchade rader i den högra tabellen, visar den posten med NULL-värden.
I exemplet nedan returnerar den vänstra yttre kopplingen följande rader:
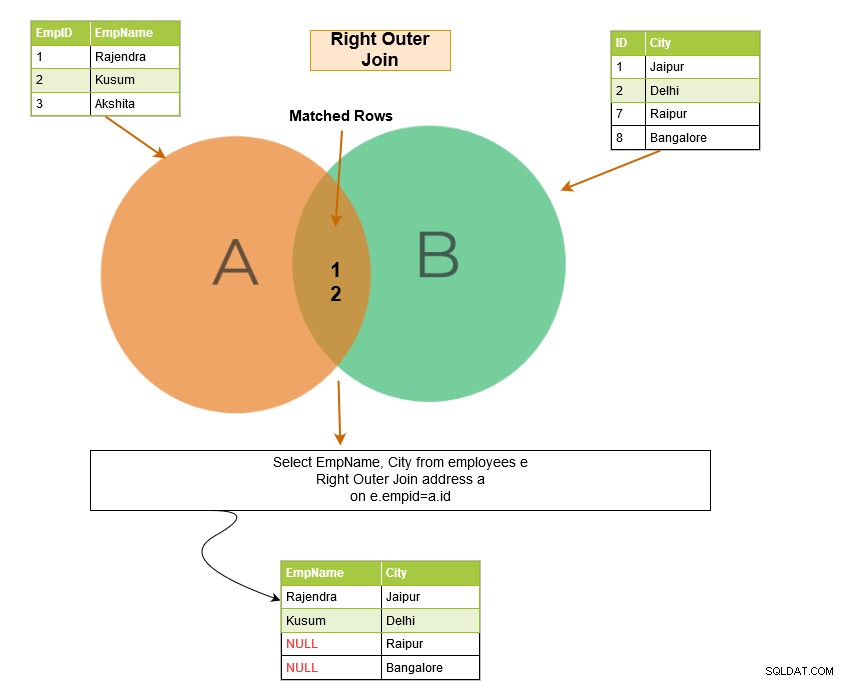
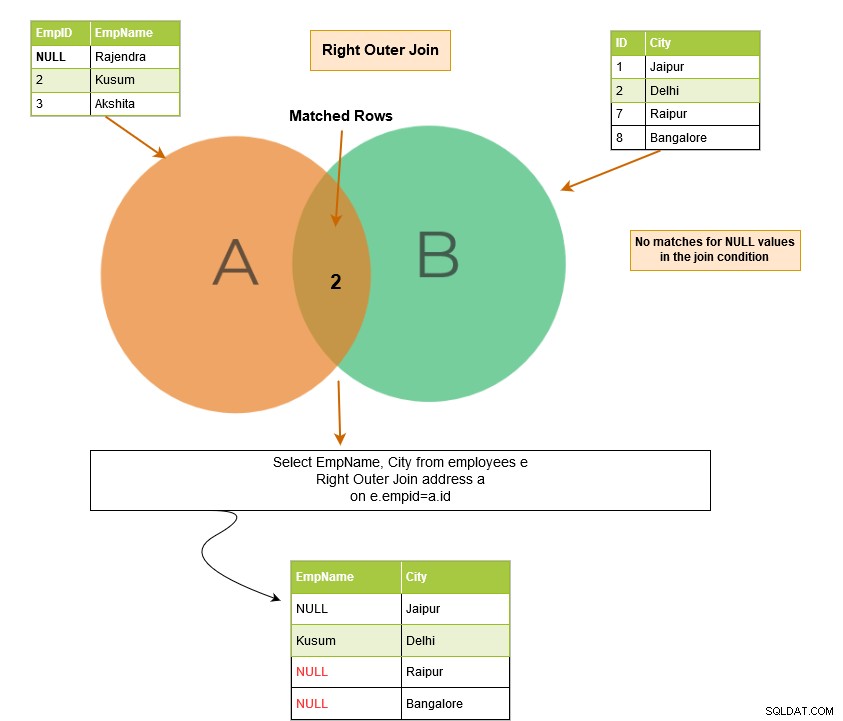
SQL right outer join returnerar de matchande raderna i båda tabellerna tillsammans med de omatchade raderna från den högra tabellen. Om en post från den högra tabellen inte har några matchade rader i den vänstra tabellen, visar den posten med NULL-värden.
I exemplet nedan har vi följande utdatarader:
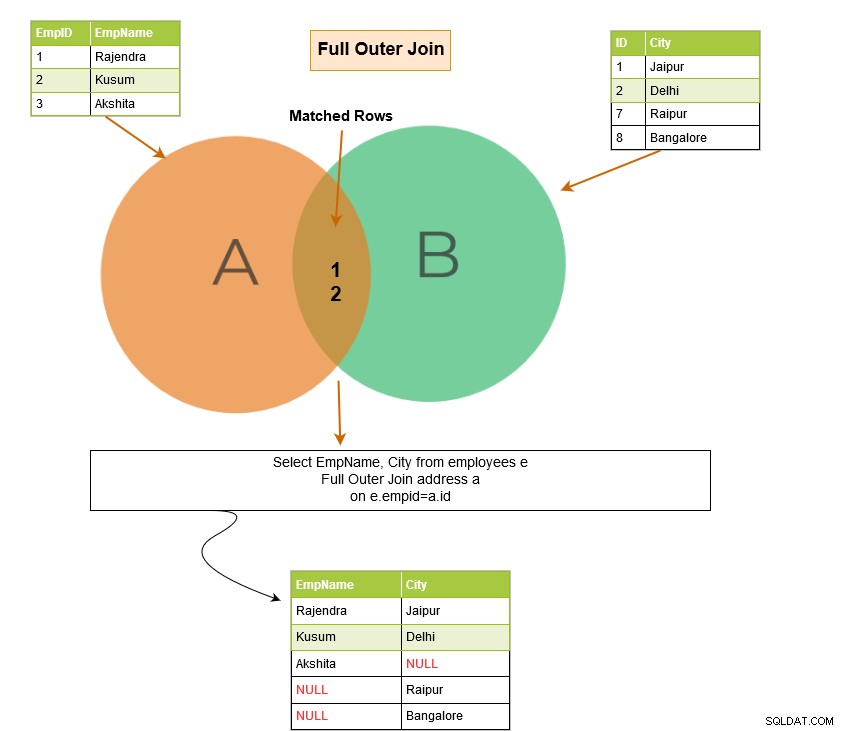
En fullständig yttre koppling returnerar följande rader i utgången:
I de föregående exemplen använder vi två tabeller i en SQL-fråga för att utföra joinoperationer. Oftast slår vi ihop flera tabeller och det returnerar relevant data.
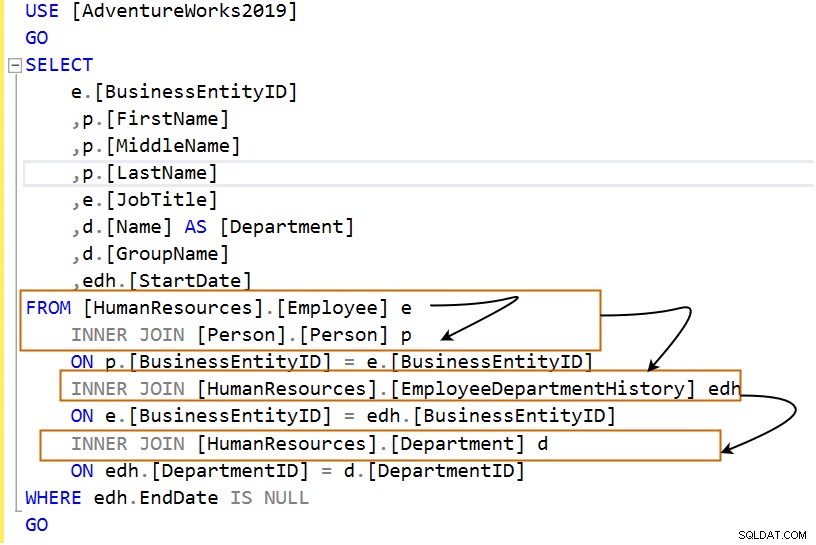
Frågan nedan använder flera inre kopplingar.
Låt oss analysera frågan i följande steg:
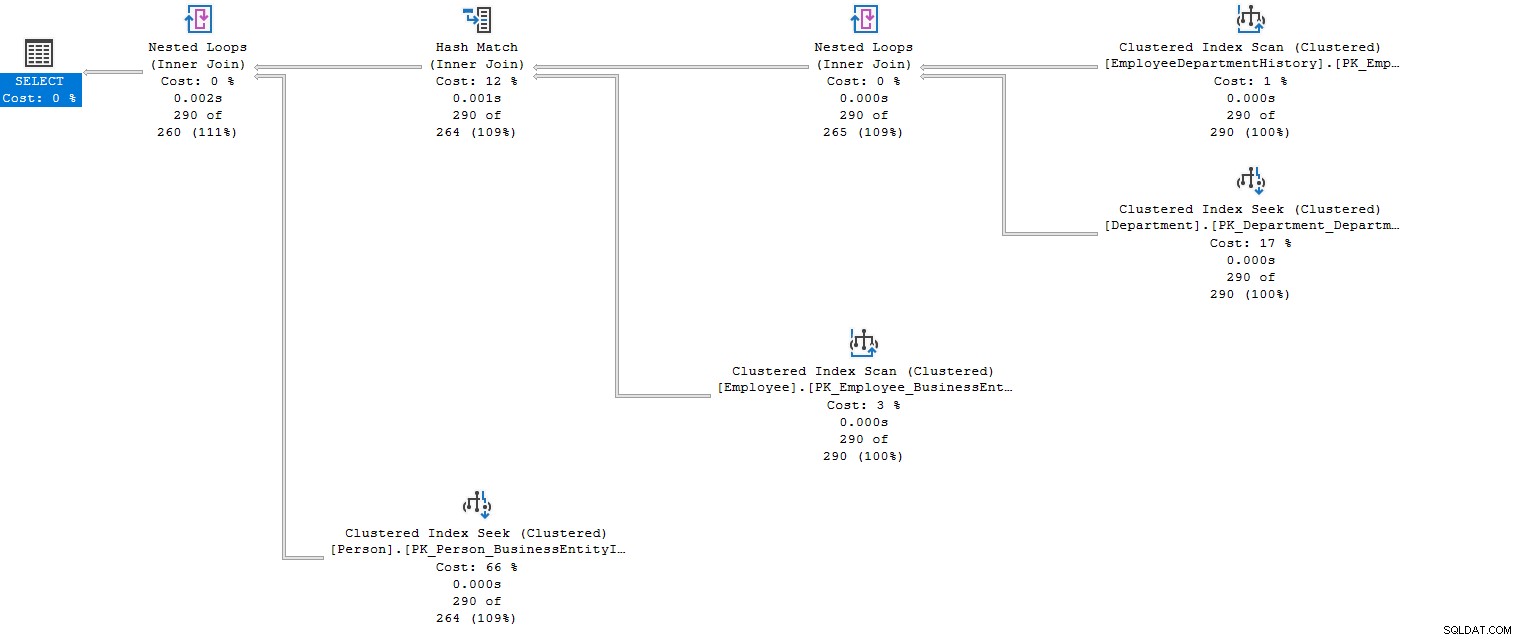
När du har kört frågan med flera kopplingar förbereder frågeoptimeraren exekveringsplanen. Den förbereder en kostnadsoptimerad exekveringsplan som uppfyller kopplingsvillkoren med resursanvändning – till exempel i den faktiska exekveringsplanen nedan kan vi titta på flera kapslade loopar (inre koppling) och hashmatchning (inre koppling) som kombinerar data från flera kopplingstabeller .
Anta att vi har NULL-värden i tabellkolumnerna och att vi sammanfogar tabellerna i dessa kolumner. Matchar SQL Server NULL-värden?
NULL-värdena matchar inte varandra. Därför kunde SQL Server inte returnera den matchande raden. I exemplet nedan har vi NULL i EmpID-kolumnen i tabellen [Anställda]. Därför returnerar den i utdata endast den matchande raden för [EmpID] 2.
Vi kan få denna NULL-rad i utgången i händelse av en yttre SQL-koppling eftersom den också returnerar de omatchade raderna.
I den här artikeln utforskade vi de olika SQL-anslutningstyperna. Här är några viktiga bästa metoder att komma ihåg och tillämpa när du använder SQL-kopplingar.SQL självanslutning
SQL cross join
SQL yttre koppling
Vänster yttre sammanfogning
Höger yttre sammanfogning
Fullständig yttre sammanfogning
SQL går samman med flera tabeller
USE [AdventureWorks2019]
GO
SELECT
e.[BusinessEntityID]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,e.[JobTitle]
,d.[Name] AS [Department]
,d.[GroupName]
,edh.[StartDate]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh
ON e.[BusinessEntityID] = edh.[BusinessEntityID]
INNER JOIN [HumanResources].[Department] d
ON edh.[DepartmentID] = d.[DepartmentID]
WHERE edh.EndDate IS NULL
GO
NULL-värden och SQL-kopplingar
SQL gå med i bästa praxis