Jag ser många råd där ute som säger något i stil med, "Ändra markören till en uppsättningsbaserad operation; det kommer att göra det snabbare." Även om det ofta kan vara fallet, är det inte alltid sant. Ett användningsfall jag ser där en markör upprepade gånger överträffar den typiska uppsättningsbaserade metoden är beräkningen av löpande totaler. Detta beror på att det uppsättningsbaserade tillvägagångssättet vanligtvis måste titta på en del av den underliggande data mer än en gång, vilket kan vara en exponentiellt dålig sak när data blir större; medan en markör – hur smärtsam det än låter – kan gå igenom varje rad/värde exakt en gång.
Det här är våra grundläggande alternativ i de vanligaste versionerna av SQL Server. I SQL Server 2012 har det dock gjorts flera förbättringar av fönsterfunktioner och OVER-klausulen, mestadels härrörande från flera bra förslag som lämnats in av andra MVP Itzik Ben-Gan (här är ett av hans förslag). Faktum är att Itzik har en ny MS-Press-bok som täcker alla dessa förbättringar mycket mer detaljerat, med titeln "Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions."
Så naturligtvis var jag nyfiken; skulle den nya fönsterfunktionen göra markör- och självanslutningsteknikerna föråldrade? Skulle de vara lättare att koda? Skulle de vara snabbare i alla fall? Vilka andra tillvägagångssätt kan vara giltiga?
Inställningen
För att göra några tester, låt oss skapa en databas:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO Och fyll sedan en tabell med 10 000 rader som vi kan använda för att utföra några löpande summor mot. Inget för komplicerat, bara en sammanfattningstabell med en rad för varje datum och en siffra som representerar hur många fortkörningsböter som utfärdats. Jag har inte fått en hastighetsböter på ett par år, så jag vet inte varför detta var mitt undermedvetna val för en förenklad datamodell, men där är den.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Förkortade resultat:
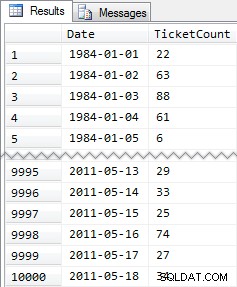
Så återigen, 10 000 rader med ganska enkel data – små INT-värden och en serie datum från 1984 till maj 2011.
Tillvägagångssätten
Nu är mitt uppdrag relativt enkelt och typiskt för många applikationer:returnera en resultatuppsättning som har alla 10 000 datum, tillsammans med den ackumulerade summan av alla hastighetsböter fram till och med det datumet. De flesta skulle först prova något liknande detta (vi kallar detta för "inre anslutningen " metod):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
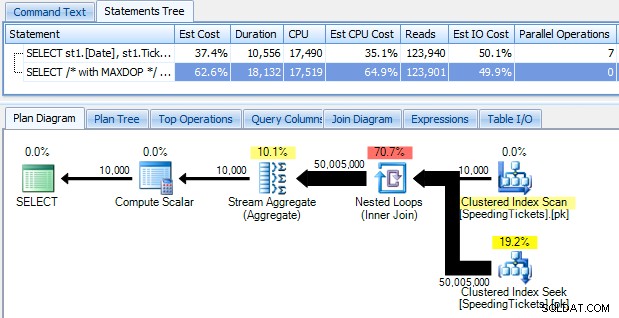
...och bli chockad när du upptäcker att det tar nästan 10 sekunder att köra. Låt oss snabbt undersöka varför genom att visa den grafiska exekveringsplanen med SQL Sentry Plan Explorer:

De stora feta pilarna bör ge en omedelbar indikation på vad som händer:den kapslade slingan läser en rad för den första sammanställningen, två rader för den andra, tre rader för den tredje, och vidare och vidare genom hela uppsättningen av 10 000 rader. Det betyder att vi bör se ungefär ((10000 * (10000 + 1)) / 2) rader bearbetade när hela uppsättningen korsas, och det verkar stämma överens med antalet rader som visas i planen.
Observera att att köra frågan utan parallellitet (med hjälp av frågetipset OPTION (MAXDOP 1)) gör planformen lite enklare, men hjälper inte alls i vare sig exekveringstid eller I/O; som visas i planen fördubblas faktiskt varaktigheten nästan, och läsningen minskar bara med en mycket liten procentandel. Jämfört med den tidigare planen:
Det finns många andra tillvägagångssätt som människor har försökt att få effektiva löpande summor. Ett exempel är "underfrågametoden " som bara använder en korrelerad underfråga på ungefär samma sätt som den inre kopplingsmetoden som beskrivs ovan:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Jämför dessa två planer:
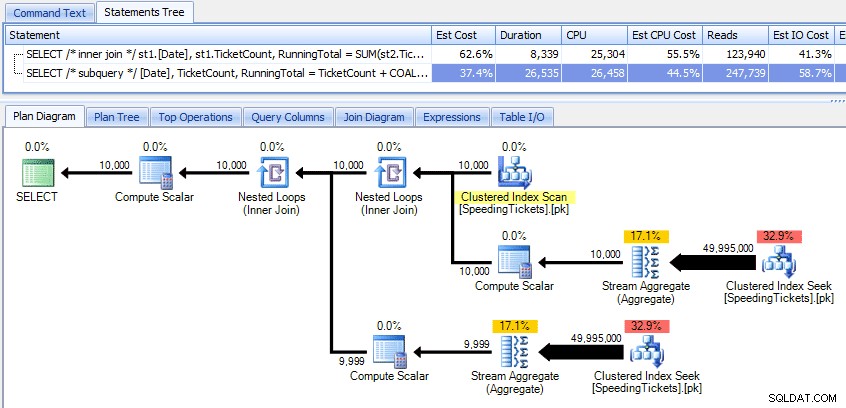
Så även om subquery-metoden verkar ha en mer effektiv övergripande plan, är den värre där det spelar roll:varaktighet och I/O. Vi kan se vad som bidrar till detta genom att gräva lite djupare i planerna. Genom att flytta till fliken Toppoperationer kan vi se att i metoden med inre join, klustrade indexsökningen exekveras 10 000 gånger, och alla andra operationer exekveras endast ett fåtal gånger. Flera operationer utförs dock 9 999 eller 10 000 gånger i subquery-metoden:
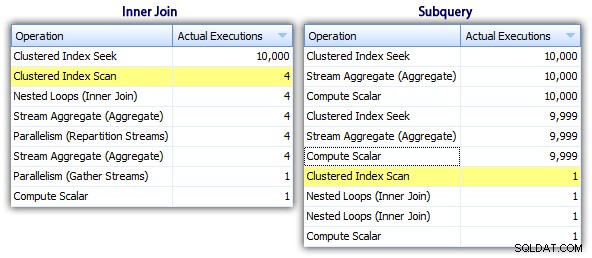
Så subquery-metoden verkar vara sämre, inte bättre. Nästa metod vi ska prova, jag kallar den "udda uppdateringen "-metoden. Det här är inte exakt garanterat att fungera, och jag skulle aldrig rekommendera det för produktionskod, men jag inkluderar det för fullständighetens skull. I grund och botten utnyttjar den knäppa uppdateringen det faktum att du under en uppdatering kan omdirigera uppdrag och matematik så att att variabeln ökar bakom kulisserna när varje rad uppdateras.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Jag upprepar att jag inte tror att det här tillvägagångssättet är säkert för produktion, oavsett vilket vittnesbörd du kommer att höra från folk som indikerar att det "aldrig misslyckas". Om inte beteende dokumenteras och garanteras försöker jag hålla mig borta från antaganden baserade på observerat beteende. Du vet aldrig när någon förändring av optimerarens beslutsväg (baserat på en statistikändring, dataändring, service pack, spårningsflagga, frågetips, vad har du) drastiskt kommer att förändra planen och potentiellt leda till en annan ordning. Om du verkligen gillar det här ointuitiva tillvägagångssättet kan du få dig själv att må lite bättre genom att använda frågealternativet FORCE ORDER (och detta kommer att försöka använda en beställd skanning av PK, eftersom det är det enda kvalificerade indexet på tabellvariabeln):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
För lite mer självförtroende till en något högre I/O-kostnad kan du ta tillbaka det ursprungliga bordet och se till att PK:n på basbordet används:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Personligen tror jag inte att det är så mycket mer garanterat, eftersom SET-delen av operationen potentiellt kan påverka optimeraren oberoende av resten av frågan. Återigen, jag rekommenderar inte detta tillvägagångssätt, jag inkluderar bara jämförelsen för fullständighetens skull. Här är planen från den här frågan:
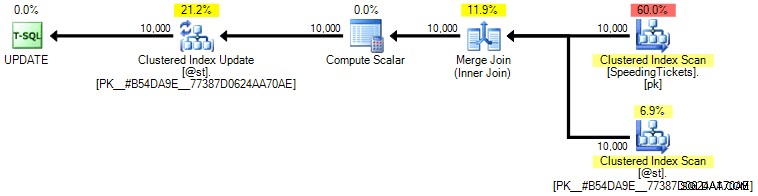
Baserat på antalet avrättningar som vi ser på fliken Top Operations (jag ska bespara dig skärmdumpen, det är 1 för varje operation), är det tydligt att även om vi utför en join för att må bättre av att beställa, är det udda uppdatering gör att de löpande summorna kan beräknas i ett enda pass av data. Jämför det med de tidigare frågorna är det mycket mer effektivt, även om det först dumpar data i en tabellvariabel och delas upp i flera operationer:

Detta för oss till en "rekursiv CTE "-metoden. Den här metoden använder datumvärdet och förlitar sig på antagandet att det inte finns några luckor. Eftersom vi fyllde i denna data ovan vet vi att det är en helt sammanhängande serie, men i många scenarier kan du inte göra det antagande. Så även om jag har inkluderat det för fullständighetens skull, kommer det här tillvägagångssättet inte alltid att vara giltigt. I vilket fall som helst använder detta en rekursiv CTE med det första (kända) datumet i tabellen som ankare och det rekursiva del bestäms genom att lägga till en dag (lägga till alternativet MAXRECURSION eftersom vi vet exakt hur många rader vi har):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Den här frågan fungerar ungefär lika effektivt som den knäppa uppdateringsmetoden. Vi kan jämföra det med underfrågan och metoderna för inre koppling:

Liksom den udda uppdateringsmetoden, skulle jag inte rekommendera denna CTE-metod i produktion om du inte absolut kan garantera att din nyckelkolumn inte har några luckor. Om du kan ha luckor i din data kan du konstruera något liknande med ROW_NUMBER(), men det kommer inte att vara effektivare än metoden för självkoppling ovan.
Och så har vi "markören " tillvägagångssätt:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; ...vilket är mycket mer kod, men i motsats till vad den allmänna uppfattningen kan antyda, returneras på 1 sekund. Vi kan se varför från några av plandetaljerna ovan:de flesta andra tillvägagångssätt slutar med att läsa samma data om och om igen, medan markörmetoden läser varje rad en gång och håller den löpande summan i en variabel istället för att beräkna summan över och om igen. Vi kan se detta genom att titta på uttalandena som fångas upp genom att generera en faktisk plan i Plan Explorer:
Vi kan se att över 20 000 uttalanden har samlats in, men om vi sorterar efter uppskattade eller faktiska rader fallande, finner vi att det bara finns två operationer som hanterar mer än en rad. Vilket är långt ifrån några av ovanstående metoder som orsakar exponentiella läsningar på grund av att man läser samma föregående rader om och om igen för varje ny rad.
Låt oss nu ta en titt på de nya fönsterförbättringarna i SQL Server 2012. I synnerhet kan vi nu beräkna SUM OVER() och specificera en uppsättning rader i förhållande till den aktuella raden. Så till exempel:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Dessa två frågor råkar ge samma svar, med korrekt löpande totalsummor. Men fungerar de exakt likadant? Planerna tyder på att de inte gör det. Versionen med ROWS har en extra operatör, ett 10 000-rads sekvensprojekt:
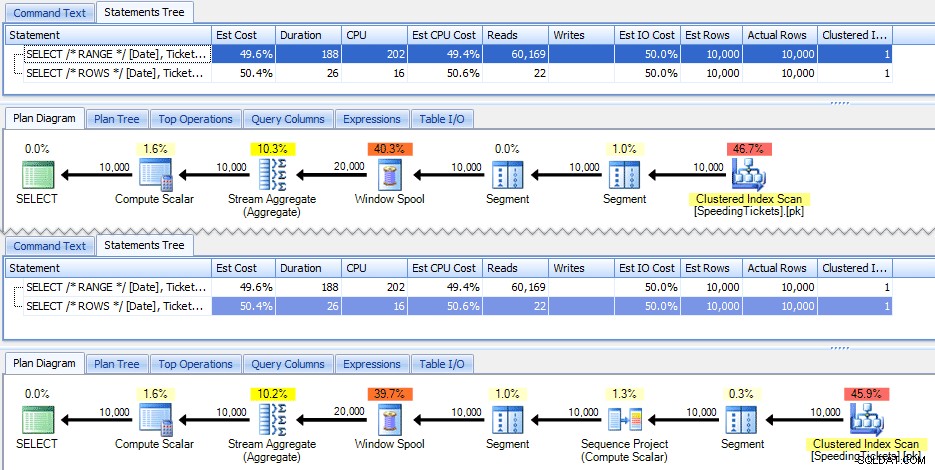
Och det är ungefär skillnaden i den grafiska planen. Men om du tittar lite närmare på faktiska körtidsmått ser du mindre skillnader i varaktighet och CPU, och en enorm skillnad i läsningar. Varför är detta? Tja, detta beror på att RANGE använder en spool på disken, medan ROWS använder en spool i minnet. Med små uppsättningar är skillnaden förmodligen försumbar, men kostnaden för spolen på disken kan säkert bli mer påtaglig när seten blir större. Jag vill inte förstöra slutet, men du kanske misstänker att en av dessa lösningar kommer att prestera bättre än den andra i ett mer grundligt test.
Dessutom ger följande version av frågan samma resultat, men fungerar som den långsammare RANGE-versionen ovan:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Så när du leker med de nya fönsterfunktionerna, bör du ha små godbitar som detta i åtanke:den förkortade versionen av en fråga, eller den som du råkar ha skrivit först, är inte nödvändigtvis den du vill ha att driva till produktion.
De faktiska testerna
För att kunna genomföra rättvisa tester skapade jag en lagrad procedur för varje tillvägagångssätt och mätte resultaten genom att fånga satser på en server där jag redan övervakade med SQL Sentry (om du inte använder vårt verktyg kan du samla SQL:BatchCompleted-händelser på liknande sätt med SQL Server Profiler).
Med "rättvisa tester" menar jag att till exempel den knäppa uppdateringsmetoden kräver en faktisk uppdatering till statisk data, vilket innebär att man ändrar det underliggande schemat eller använder en temporär tabell/tabellvariabel. Så jag strukturerade de lagrade procedurerna för att var och en skapa sin egen tabellvariabel, och antingen lagra resultaten där, eller lagra rådata där och sedan uppdatera resultatet. Det andra problemet jag ville eliminera var att returnera data till klienten – så att procedurerna har var och en en felsökningsparameter som anger om inga resultat ska returneras (standard), topp/botten 5 eller alla. I prestandatesterna ställde jag in det så att det inte gav några resultat, men validerade naturligtvis var och en för att säkerställa att de gav rätt resultat.
De lagrade procedurerna är alla modellerade på detta sätt (jag har bifogat ett skript som skapar databasen och de lagrade procedurerna, så jag inkluderar bara en mall här för korthetens skull):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO Och jag ringde dem i en grupp enligt följande:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Jag insåg snabbt att några av dessa anrop inte visades i Top SQL eftersom standardtröskeln är 5 sekunder. Jag ändrade det till 100 millisekunder (något du aldrig vill göra på ett produktionssystem!) enligt följande:
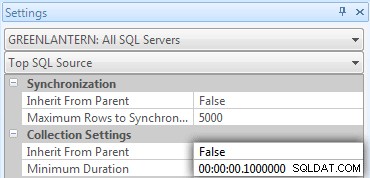
Jag upprepar:detta beteende accepteras inte för produktionssystem!
Jag upptäckte fortfarande att ett av kommandona ovan inte fångades av den övre SQL-tröskeln; det var Windowed_Rows-versionen. Så jag lade endast till följande till den batchen:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
Och nu fick jag tillbaka alla 7 raderna i Top SQL. Här är de sorterade efter CPU-användning fallande:
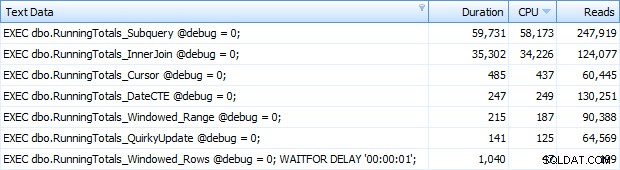
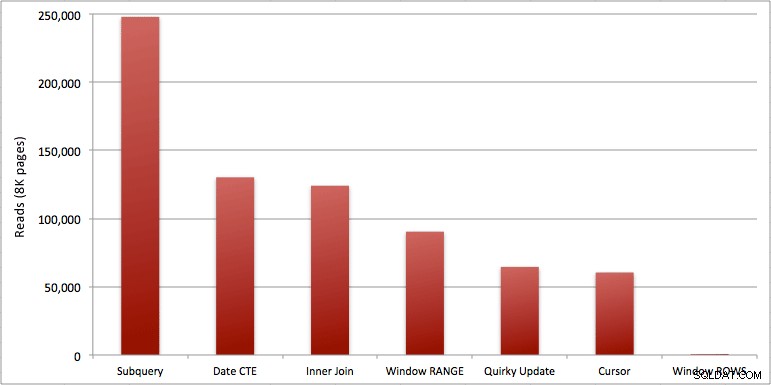
Du kan se den extra sekunden jag lade till i Windowed_Rows-batchen; det var inte fångat av den översta SQL-tröskeln eftersom den slutfördes på bara 40 millisekunder! Detta är helt klart vår bästa presterande och om vi har SQL Server 2012 tillgängligt borde det vara den metod vi använder. Markören är inte halvdålig heller, med tanke på prestandan eller andra problem med de återstående lösningarna. Att plotta varaktigheten på en graf är ganska meningslöst – två höjdpunkter och fem oskiljbara låga punkter. Men om I/O är din flaskhals, kanske du tycker att visualiseringen av läsningar är intressant:
Slutsats
Från dessa resultat kan vi dra några slutsatser:
- Fönsteraggregat i SQL Server 2012 gör prestandaproblem med körande totalberäkningar (och många andra problem med nästa rad(er)/föregående rad(er)) oroväckande effektivare. När jag såg det låga antalet läsningar trodde jag säkert att det var något slags misstag, att jag måste ha glömt att faktiskt utföra något arbete. Men nej, du får samma antal läsningar om din lagrade procedur bara utför ett vanligt SELECT från SpeedingTickets-tabellen. (Testa gärna detta själv med STATISTICS IO.)
- De problem jag påpekade tidigare om RANGE vs. ROWS ger något olika körtider (varaktighetsskillnad på cirka 6x – kom ihåg att ignorera den andra jag la till med WAITFOR), men lässkillnaderna är astronomiska på grund av spolen på disken. Om ditt fönsterade aggregat kan lösas med ROWS, undvik RANGE, men du bör testa att båda ger samma resultat (eller åtminstone att ROWS ger rätt svar). Du bör också notera att om du använder en liknande fråga och du inte anger RANGE eller ROWS, kommer planen att fungera som om du hade angett RANGE).
- Underfrågan och metoderna för inre koppling är relativt urusla. 35 sekunder till en minut för att generera dessa löpande summor? Och detta var på ett enda, magert bord utan att returnera resultat till kunden. Dessa jämförelser kan användas för att visa människor varför en rent set-baserad lösning inte alltid är det bästa svaret.
- Av de snabbare tillvägagångssätten, förutsatt att du ännu inte är redo för SQL Server 2012, och förutsatt att du ignorerar både den udda uppdateringsmetoden (stöds inte) och CTE-datummetoden (kan inte garantera en sammanhängande sekvens), utför bara markören acceptabelt. Den har den högsta varaktigheten av de "snabbare" lösningarna, men den minsta mängden läsningar.
Jag hoppas att dessa tester hjälper till att ge en bättre uppskattning för de fönsterförbättringar som Microsoft har lagt till i SQL Server 2012. Var noga med att tacka Itzik om du ser honom online eller personligen, eftersom han var drivkraften bakom dessa förändringar. Dessutom hoppas jag att detta hjälper till att öppna vissa sinnen där ute att en markör kanske inte alltid är den onda och fruktade lösningen som den ofta framställs vara.
(Som ett tillägg testade jag CLR-funktionen som erbjuds av Pavel Pawlowski, och prestandaegenskaperna var nästan identiska med SQL Server 2012-lösningen med ROWS. Läsningarna var identiska, CPU:n var 78 mot 47 och den totala varaktigheten var 73 istället för 40. Så om du inte kommer att flytta till SQL Server 2012 inom en snar framtid, kanske du vill lägga till Pavels lösning i dina tester.)
Bilagor:RunningTotals_Demo.sql.zip (2kb)