När 2014 slutar, startar jag en serie inlägg om proaktiva SQL Server-hälsokontroller, baserat på ett jag skrev tillbaka i början av detta år – Performance Issues:The First Encounter. I det inlägget diskuterade jag vad jag letar efter först när jag felsöker ett prestandaproblem i en obekant miljö. I den här inläggsserien vill jag prata om vad jag letar efter när jag checkar in hos mina långsiktiga kunder. Vi tillhandahåller en Remote DBA-tjänst, och en av våra vanliga uppgifter är en månatlig "mini" hälsorevision av deras miljö. Vi har övervakning på plats och vanligtvis arbetar jag med projekt, så jag är i miljön regelbundet. Men som ett extra steg för att se till att vi inte missar något går vi en gång i månaden igenom samma data som vi samlar in i vår vanliga hälsorevision och letar efter något utöver det vanliga. Det kan vara många saker, eller hur? ja! Så låt oss börja med rymden.
Oj, utrymme? Ja, rymden. Oroa dig inte, jag kommer till andra ämnen. ☺
Vad du ska kontrollera
Varför skulle jag börja med rymden? Eftersom det är något jag ofta ser försummat, och om du får slut på diskutrymme för dina databasfiler blir du extremt begränsad i vad du kan göra i din databas. Behöver du lägga till data men kan inte utöka filen eftersom disken är full? Tyvärr kan användare nu inte lägga till data. Tar inte loggbackup av någon anledning, så transaktionsloggen fyller upp enheten? Tyvärr, nu kan du inte ändra någon data. Utrymmet är kritiskt. Vi har jobb som övervakar ledigt utrymme på disken och i filerna, men jag verifierar fortfarande följande för varje granskning och jämför värdena med de från föregående månad:
- Storleken på varje loggfil
- Storleken på varje datafil
- Fritt utrymme i varje datafil
- Fritt utrymme på varje enhet med databasfiler
- Fritt utrymme på varje enhet med säkerhetskopior
Tillväxt av loggfiler
De flesta problem jag ser relaterade till diskutrymme är på grund av loggfiltillväxt. Tillväxten sker vanligtvis av en av två anledningar:
- Databasen är i FULL återställning och säkerhetskopior av transaktionsloggar tas inte av någon anledning
- Någon kör en enda, mycket stor transaktion som förbrukar allt befintligt loggutrymme, vilket tvingar filen att växa
Jag har också sett loggfilen växa som en del av indexunderhåll. För ombyggnader loggas varje allokering och för stora index kan det generera en betydande mängd loggar. Även med vanliga säkerhetskopior av transaktionsloggar kan loggen fortfarande växa snabbare än vad säkerhetskopiorna kan ske. För att hantera loggen måste du justera säkerhetskopieringsfrekvensen eller ändra din metodik för indexunderhåll.
Du måste avgöra varför loggfilen växte, vilket kan vara knepigt om du inte spårar den. Jag har ett jobb som körs varje timme för att ta bilder av loggfilstorlek och användning:
USE [Baselines];
GO
IF (NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'SQLskills_TrackLogSpace'))
BEGIN
CREATE TABLE [dbo].[SQLskills_TrackLogSpace](
[DatabaseName] [VARCHAR](250) NULL,
[LogSizeMB] [DECIMAL](38, 0) NULL,
[LogSpaceUsed] [DECIMAL](38, 0) NULL,
[LogStatus] [TINYINT] NULL,
[CaptureDate] [DATETIME2](7) NULL
) ON [PRIMARY];
ALTER TABLE [dbo].[SQLskills_TrackLogSpace] ADD DEFAULT (SYSDATETIME()) FOR [CaptureDate];
END
CREATE TABLE #LogSpace_Temp (
DatabaseName VARCHAR(100),
LogSizeMB DECIMAL(10,2),
LogSpaceUsed DECIMAL(10,2),
LogStatus VARCHAR(1)
);
INSERT INTO #LogSpace_Temp EXEC('dbcc sqlperf(logspace)');
INSERT INTO Baselines.dbo.SQLskills_TrackLogSpace
(DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus)
SELECT DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus
FROM #LogSpace_Temp;
DROP TABLE #LogSpace_Temp; Jag använder den här informationen för att avgöra när loggfilen började växa, och jag börjar titta igenom loggarna och jobbhistoriken för att se vilken ytterligare information jag kan hitta. Loggtillväxten bör vara statisk – loggen bör vara av lämplig storlek och hanteras genom säkerhetskopior (om den körs i FULL återställning), och om filen behöver vara större måste jag förstå varför och ändra storlek på den därefter.
Om du hanterar det här problemet, och du inte redan proaktivt spårade filtillväxthändelser, kanske du fortfarande kan ta reda på vad som hände. Auto-tillväxt-händelser fångas upp av SQL Server; SQL Sentrys Aaron Bertrand bloggade om detta redan 2007, där han visar hur man upptäcker när dessa händelser hände (så länge de var tillräckligt färska för att fortfarande existera i standardspåret).
Storlek och ledigt utrymme i datafiler
Du har antagligen redan hört att dina datafiler bör vara förstorade så att de inte behöver växa automatiskt. Om du följer denna vägledning har du förmodligen inte upplevt händelsen där datafilen växer oväntat. Men om du inte hanterar dina datafiler, har du förmodligen tillväxt som sker regelbundet – oavsett om du inser det eller inte (särskilt med standardtillväxtinställningarna på 10 % och 1 MB).
Det finns ett knep att förbestämma datafiler – du vill inte göra en databas för stor, för kom ihåg att om du ska återställa till, säg en dev- eller QA-miljö, har filerna samma storlek, även om de är inte full av data. Men du vill fortfarande hantera tillväxten manuellt. Jag tycker att DBA:er har det svårast med nya databaser. Affärsanvändarna har ingen aning om tillväxthastigheter och hur mycket data som läggs till, och den databasen är lite av en lös kanon i din miljö. Du måste vara mycket uppmärksam på dessa filer tills du har koll på storlek och förväntad tillväxt. Jag använder en fråga som ger information om storlek och ledigt utrymme:
SELECT
[file_id] AS [File ID],
[type] AS [File Type],
substring([physical_name],1,1) AS [Drive],
[name] AS [Logical Name],
[physical_name] AS [Physical Name],
CAST([size] as DECIMAL(38,0))/128. AS [File Size MB],
CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128. AS [Space Used MB],
(CAST([size] AS DECIMAL(38,0))/128) - (CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128.) AS [Free Space],
[max_size] AS [Max Size],
[is_percent_growth] AS [Percent Growth Enabled],
[growth] AS [Growth Rate],
SYSDATETIME() AS [Current Date]
FROM sys.database_files; Varje månad kontrollerar jag storleken på datafilerna och utrymmet som används, och bestämmer sedan om storleken behöver utökas. Jag övervakar också standardspåret för tillväxthändelser, eftersom detta talar om för mig exakt när tillväxt inträffar. Med undantag för nya databaser kan jag alltid ligga före den automatiska filtillväxten och hantera det manuellt. Ok, nästan alltid. Precis innan semestern förra året blev jag meddelad av en kunds IT-avdelning om lite ledigt utrymme på en enhet (håll den tanken för nästa avsnitt). Nu baseras meddelandet på ett tröskelvärde på mindre än 20 % gratis. Den här enheten var över 1 TB, så det var cirka 150 GB ledigt när jag kontrollerade enheten. Det var inte en nödsituation ännu, men jag behövde förstå var utrymmet hade tagit vägen.
När jag kontrollerade databasfilerna för en databas kunde jag se att de var fulla – och föregående månad hade varje fil över 50 GB ledigt. Jag grävde sedan i tabellstorlekar och upptäckte att i en tabell hade över 270 miljoner rader lagts till under de senaste 16 dagarna – totalt över 100 GB data. Det visade sig att det hade skett en kodändring och den nya koden loggade mer information än tänkt. Vi satte snabbt upp ett jobb för att rensa raderna och återställa det lediga utrymmet i filerna (och de fixade koden). Jag kunde dock inte återställa diskutrymme - jag skulle behöva krympa filerna, och det var inte ett alternativ. Jag var sedan tvungen att bestämma hur mycket utrymme som fanns kvar på disken och bestämma om det var en mängd jag var bekväm med eller inte. Min komfortnivå är beroende av att jag vet hur mycket data som läggs till per månad – den typiska tillväxttakten. Och jag vet bara hur mycket data som läggs till eftersom jag övervakar filanvändning och kan uppskatta hur mycket utrymme som kommer att behövas för den här månaden, för i år och för de kommande två åren.
Drive Space
Jag nämnde tidigare att vi har jobb för att övervaka ledigt utrymme på disken. Detta baseras på en procentsats, inte ett fast belopp. Min allmänna tumregel har varit att skicka meddelanden när mindre än 10% av disken är ledig, men för vissa enheter kan du behöva ställa in det högre. Till exempel, med en 1 TB-enhet får jag ett meddelande när det är mindre än 100 GB ledigt. Med en 100 GB-enhet får jag ett meddelande när det är mindre än 10 GB ledigt. Med en 20 GB-enhet ... ja, du ser vart jag är på väg med detta. Den tröskeln måste varna dig innan det uppstår ett problem. Om jag bara har 10 GB ledigt på en enhet som är värd för en loggfil, kanske jag inte har tillräckligt med tid att reagera innan det dyker upp som ett problem för användarna – beroende på hur ofta jag kontrollerar det lediga utrymmet och vad problemet är. är.
Det är väldigt enkelt att använda xp_fixeddrives för att kontrollera ledigt utrymme, men jag skulle inte rekommendera detta eftersom det är odokumenterat och användningen av utökade lagrade procedurer i allmänhet har blivit utfasade. Den rapporterar inte heller den totala storleken på varje enhet och kanske inte rapporterar om alla enhetstyper som dina databaser kan använda. Så länge du kör SQL Server 2008R2 SP1 eller högre kan du använda den mycket bekvämare sys.dm_os_volume_stats för att få den information du behöver, åtminstone om de enheter där databasfiler finns:
SELECT DISTINCT vs.volume_mount_point AS [Drive], vs.logical_volume_name AS [Drive Name], vs.total_bytes/1024/1024 AS [Drive Size MB], vs.available_bytes/1024/1024 AS [Drive Free Space MB] FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) AS vs ORDER BY vs.volume_mount_point;
Jag ser ofta problem med diskutrymme på volymer som är värd för tempdb. Jag har tappat räkningen på de gånger jag har haft kunder med oförklarlig tempdb-tillväxt. Ibland är det bara några GB; senast var det 200GB. Tempdb är ett knepigt odjur – det finns ingen formel att följa när man dimensionerar den, och alltför ofta placeras den på en enhet med lite ledigt utrymme som inte kan hantera den galna händelsen som orsakas av nybörjarutvecklaren eller DBA. Om du vill ändra storlek på tempdb-datafilerna måste du köra din arbetsbelastning under en "normal" konjunkturcykel för att avgöra hur mycket den använder tempdb och sedan storleksanpassa den därefter.
Jag hörde nyligen ett förslag på ett sätt att undvika att få ont om utrymme på en enhet:skapa en databas utan data och storleksanpassa filerna så att de förbrukar hur mycket utrymme du vill "avsätta". Sedan, om du stöter på ett problem, släpp bara databasen och viola, du har ledigt utrymme igen. Personligen tror jag att detta skapar alla slags andra problem och skulle inte rekommendera det. Men om du har lagringsadministratörer som inte gillar att se hundratals oanvända GB på en enhet, skulle detta vara ett sätt att få en enhet att "se full". Det påminner mig om något jag har hört en god vän till mig säga:"Om jag inte kan arbeta med dig, kommer jag att arbeta runt dig."
Säkerhetskopiering
En av de primära uppgifterna för en DBA är att skydda data. Säkerhetskopiering är en metod som används för att skydda den, och som sådan är de enheter som håller dessa säkerhetskopior en integrerad del av en DBA:s liv. Förmodligen håller du en eller flera säkerhetskopior online, för att återställa omedelbart om det behövs. Din SLA- och DR-körbok hjälper dig att diktera hur många säkerhetskopior du håller online, och du måste se till att du har det utrymmet tillgängligt. Jag förespråkar att du inte heller tar bort gamla säkerhetskopior förrän den nuvarande säkerhetskopieringen har slutförts framgångsrikt. Det är alldeles för lätt att falla i fällan att ta bort gamla säkerhetskopior och sedan köra den nuvarande säkerhetskopian. Men vad händer om den nuvarande säkerhetskopieringen misslyckas? Och vad händer om du använder komprimering? Vänta lite... komprimerade säkerhetskopior är mindre eller hur? De är mindre, i slutändan. Men visste du att .bak-filstorleken vanligtvis börjar större än slutstorleken? Du kan använda spårningsflagga 3042 för att ändra detta beteende, men du bör tänka att med säkerhetskopior behöver du gott om utrymme. Om din säkerhetskopia är 100 GB, och du har 3 dagars värde online, behöver du 300 GB för de 3 dagarna av säkerhetskopior, och sedan förmodligen en hälsosam mängd (2X nuvarande databasstorlek) ledig för nästa säkerhetskopiering. Ja, det betyder att du vid varje given tidpunkt kommer att ha mycket mer än 100 GB ledigt på den här enheten. Det är ok. Det är bättre än att raderingsjobbet lyckas, och säkerhetskopieringsjobbet misslyckas, och tre dagar senare får reda på att du inte har några säkerhetskopior alls (jag hade det hänt med en kund på mitt tidigare jobb).
De flesta databaser blir bara större med tiden, vilket gör att säkerhetskopiorna också blir större. Glöm inte att regelbundet kontrollera storleken på säkerhetskopiorna och tilldela ytterligare utrymme efter behov – att ha en "200 GB gratis" policy för en databas som har vuxit till 350 GB kommer inte att vara till stor hjälp. Om utrymmeskraven ändras, se till att ändra eventuella tillhörande varningar också.
Använda Performance Advisor
Det finns flera frågor som ingår i det här inlägget som du kan använda för att övervaka utrymme, om du behöver rulla din egen process. Men om du råkar ha SQL Sentry Performance Advisor i din miljö blir detta mycket enklare med anpassade villkor. Det finns flera lagervillkor inkluderade som standard, men du kan också skapa dina egna.
Inom SQL Sentry-klienten öppnar du Navigatorn, högerklickar på Delade grupper (Global) och väljer Lägg till anpassat villkor → SQL Sentry. Ange ett namn och en beskrivning för villkoret, lägg sedan till en numerisk jämförelse och ändra typen till Repository Query. Ange frågan:
SELECT MIN(FreeSpace*100.0/Size) FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk;
Ändra lika med är mindre än och ställ in ett explicit värde på 10. Ändra slutligen standardutvärderingsfrekvensen till något som är mindre frekvent än var tionde sekund. En gång om dagen eller en gång var 12:e timme är förmodligen ett bra värde – du ska inte behöva kolla ledigt utrymme oftare än en gång om dagen, men du kan kolla det så ofta du vill. Skärmdumpen nedan visar den slutliga konfigurationen:
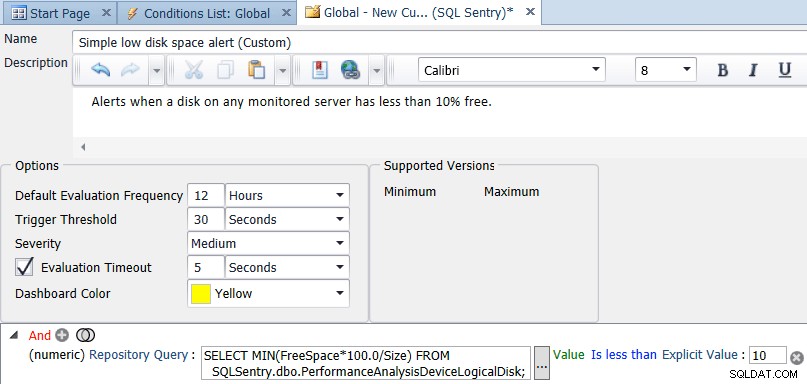
När du klickar på spara för villkoret kommer du att tillfrågas om du vill tilldela åtgärder för det anpassade villkoret. Alternativet att skicka till varningskanaler är valt som standard, men du kanske vill utföra andra uppgifter, som exekvera ett jobb – säg att kopiera gamla säkerhetskopior till en annan plats (om det är enheten med lite utrymme).
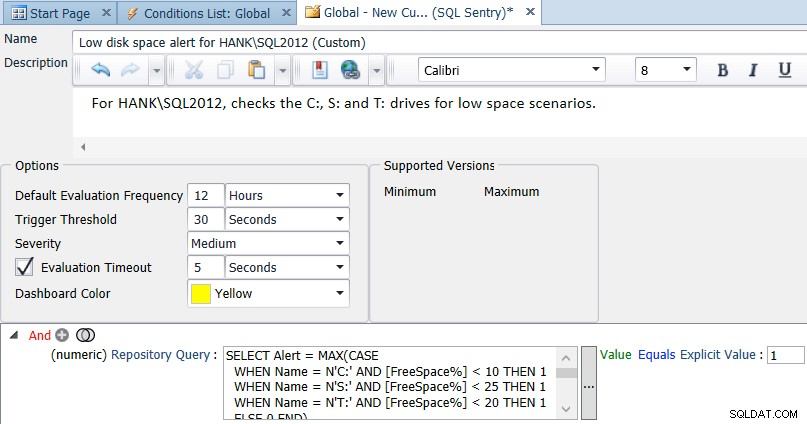
Som jag nämnde tidigare är en standard på 10% ledigt utrymme för alla enheter förmodligen inte lämpligt för varje enhet i din miljö. Du kan anpassa frågan för olika instanser och enheter, till exempel:
SELECT Alert = MAX(CASE WHEN Name = N'C:' AND [FreeSpace%] < 10 THEN 1 WHEN Name = N'S:' AND [FreeSpace%] < 25 THEN 1 WHEN Name = N'T:' AND [FreeSpace%] < 20 THEN 1 ELSE 0 END) FROM ( SELECT d.Name, d.FreeSpace * 100.0/d.Size AS [FreeSpace%] FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk AS d INNER JOIN SQLSentry.dbo.EventSourceConnection AS c ON d.DeviceID = c.DeviceID WHERE c.ObjectName = N'HANK\SQL2012' -- replace with your server/instance ) AS s;
Du kan ändra och utöka den här frågan efter behov för din miljö och sedan ändra jämförelsen i villkoret i enlighet därmed (i princip utvärdera till sant om resultatet någonsin är 1):
Om du vill se Performance Advisor i aktion, ladda ner en testversion.
Observera att för båda dessa tillstånd kommer du bara att varnas en gång, även om flera enheter faller under din tröskel. I komplexa miljöer kanske du vill luta dig mot ett större antal mer specifika villkor för att ge mer flexibel och anpassad varning, snarare än färre "catch-all"-villkor.
Sammanfattning
Det finns många kritiska komponenter i en SQL Server-miljö, och diskutrymme är ett som måste övervakas och underhållas proaktivt. Med bara lite planering är detta enkelt att göra, och det lindrar många okända och reaktiva problemlösningar. Oavsett om du använder dina egna skript eller ett verktyg från tredje part, att se till att det finns gott om ledigt utrymme för databasfiler och säkerhetskopior är ett problem som är lätt att lösa och väl värt ansträngningen.