Kevin Kline (@kekline) och jag höll nyligen ett webbseminarium för justering av frågor (tja, ett i en serie faktiskt), och en av sakerna som kom upp är folks tendens att skapa något saknat index som SQL Server säger till dem kommer att vara en bra sak™ . De kan lära sig om dessa saknade index från Database Engine Tuning Advisor (DTA), de saknade index-DMV:erna eller en exekveringsplan som visas i Management Studio eller Plan Explorer (som alla bara vidarebefordrar information från exakt samma plats):
Problemet med att bara blint skapa detta index är att SQL Server har beslutat att det är användbart för en viss fråga (eller handfull frågor), men ignorerar helt och ensidigt resten av arbetsbelastningen. Som vi alla vet är index inte "gratis" – du betalar för index både i rålagring och underhåll som krävs för DML-operationer. Det är inte meningsfullt, i en skrivtung arbetsbelastning, att lägga till ett index som hjälper till att göra en enskild fråga lite mer effektiv, särskilt om den frågan inte körs ofta. Det kan vara mycket viktigt i dessa fall att förstå din totala arbetsbelastning och hitta en bra balans mellan att göra dina frågor effektiva och att inte betala för mycket för det när det gäller indexupprätthållande.
Så en idé jag hade var att "massh up" information från de saknade index-DMV:erna, indexanvändningsstatistiken DMV och information om frågeplaner, för att avgöra vilken typ av saldo som finns för närvarande och hur det kan gå att lägga till indexet totalt sett.
Saknade index
Först kan vi ta en titt på de saknade indexen som SQL Server för närvarande föreslår:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
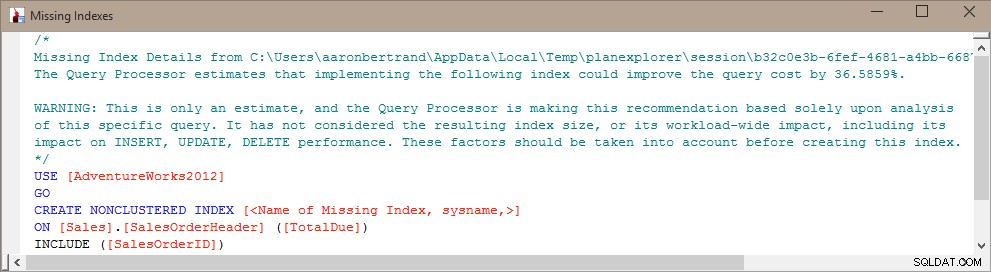
Detta visar tabell(er) och kolumn(er) som skulle ha varit användbara i ett index, hur många kompileringar/sökningar/skanningar som skulle ha använts och när den senaste händelsen inträffade för varje potentiellt index. Du kan också inkludera kolumner som s.avg_total_user_cost och s.avg_user_impact om du vill använda de siffrorna för att prioritera.
Planera verksamheten
Låt oss sedan ta en titt på operationerna som används i alla planer vi har cachelagrat mot objekten som har identifierats av våra saknade index.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; En vän på dba.SE, Mikael Eriksson, föreslog följande två frågor som, på ett större system, kommer att fungera mycket bättre än XML / UNION-frågan som jag satte ihop ovan, så du kan experimentera med dem först. Hans slutkommentar var att han "inte överraskande fick reda på att mindre XML är bra för prestanda. :)" Verkligen.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Nu i #planops tabell har du ett gäng värden för plan_handle så att du kan gå och undersöka var och en av de individuella planerna i spel mot de objekt som har identifierats som saknade något användbart register. Vi kommer inte att använda det för det just nu, men du kan enkelt korshänvisa detta med:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Nu kan du klicka på någon av utdataplanerna för att se vad de för närvarande gör mot dina objekt. Observera att vissa av planerna kommer att upprepas, eftersom en plan kan ha flera operatörer som refererar till olika index på samma tabell.
Indexa användningsstatistik
Låt oss sedan ta en titt på indexanvändningsstatistik, så att vi kan se hur mycket faktisk aktivitet som för närvarande körs mot våra kandidattabeller (och särskilt uppdateringar).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Bli inte orolig om väldigt få eller inga planer i cachen visar uppdateringar för ett visst index, även om indexanvändningsstatistiken visar att dessa index har uppdaterats. Detta betyder bara att uppdateringsplanerna för närvarande inte finns i cacheminnet, vilket kan bero på olika anledningar – det kan till exempel vara en mycket lästung arbetsbelastning och de har åldrats, eller så är de alla singel- använda och optimize for ad hoc workloads är aktiverad.
Lägg ihop allt
Följande fråga visar dig, för varje föreslaget saknat index, antalet läsningar ett index kan ha hjälpt, antalet skrivningar och läsningar som för närvarande har fångats mot de befintliga indexen, förhållandet mellan dessa, antalet planer som är associerade med det objektet, och det totala antalet användningar räknas för dessa planer:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Om ditt skriv:läs-förhållande till dessa index redan är> 1 (eller> 10!), tror jag att det ger anledning till paus innan du blint skapar ett index som bara kan öka detta förhållande. Antalet potential_read_ops visas kan dock kompensera för det när antalet blir större. Om potential_read_ops antalet är mycket litet, du vill förmodligen ignorera rekommendationen helt innan du ens bryr dig om att undersöka de andra mätvärdena – så du kan lägga till en WHERE klausul för att filtrera bort några av dessa rekommendationer.
Ett par anteckningar:
- Detta är läs- och skrivoperationer, inte individuellt mätta läsningar och skrivningar på 8K sidor.
- Förhållandet och jämförelserna är till stor del pedagogiska; det kan mycket väl vara så att 10 000 000 skrivoperationer alla påverkade en enda rad, medan 10 läsoperationer kunde ha haft betydligt större effekt. Detta är bara menat som en grov riktlinje och förutsätter att läs- och skrivoperationer vägs ungefär lika mycket.
- Du kan också använda små variationer på några av dessa frågor för att ta reda på – utanför de saknade indexen som SQL Server rekommenderar – hur många av dina nuvarande index som är slösaktiga. Det finns gott om idéer om detta online, inklusive detta inlägg av Paul Randal (@PaulRandal).
Jag hoppas att det ger några idéer för att få mer insikt i ditt systems beteende innan du bestämmer dig för att lägga till ett index som något verktyg sa åt dig att skapa. Jag kunde ha skapat detta som en stor fråga, men jag tror att de enskilda delarna kommer att ge dig några kaninhål att undersöka, om du så önskar.
Övriga anteckningar
Du kanske också vill utöka detta för att fånga aktuell storleksstatistik, tabellens bredd och antalet aktuella rader (liksom alla förutsägelser om framtida tillväxt); detta kan ge dig en god uppfattning om hur mycket utrymme ett nytt index kommer att ta upp, vilket kan vara ett problem beroende på din miljö. Jag kanske kommer att behandla detta i ett framtida inlägg.
Naturligtvis måste du komma ihåg att dessa mätvärden bara är så användbara som din drifttid kräver. DMV:erna rensas ut efter en omstart (och ibland i andra, mindre störande scenarier), så om du tror att denna information kommer att vara användbar under en längre tidsperiod kan det vara något du vill överväga att ta periodiska ögonblicksbilder.