Fördröjd hållbarhet är en sena men intressant funktion i SQL Server 2014; hissens högnivåhöjd för funktionen är helt enkelt:
- "Byt hållbarhet för prestanda."
Lite bakgrund först. Som standard använder SQL Server en Write-ahead-logg (WAL), vilket innebär att ändringar skrivs till loggen innan de tillåts begås. I system där transaktionsloggskrivningar blir flaskhalsen och där det finns en måttlig tolerans för dataförlust , har du nu möjlighet att tillfälligt avbryta kravet att vänta på loggspolning och bekräftelse. Detta råkar bokstavligen ta D ur ACID, åtminstone för en liten del av data (mer om detta senare).
Du har typ redan gjort det här uppoffringen nu. I fullt återställningsläge finns det alltid en viss risk för dataförlust, det mäts bara i termer av tid snarare än storlek. Om du till exempel säkerhetskopierar transaktionsloggen var femte minut, kan du förlora upp till knappt fem minuters data om något katastrofalt inträffade. Jag pratar inte om enkel failover här, men låt oss säga att servern bokstavligen tar eld eller att någon snubblar över nätsladden – databasen kan mycket väl vara omöjlig att återställa och du kan behöva gå tillbaka till tidpunkten för den senaste loggbackupen . Och det förutsätter att du till och med testar dina säkerhetskopior genom att återställa dem någonstans – i händelse av ett kritiskt fel kanske du inte har den återställningspunkt du tror att du har. Vi tenderar att inte tänka på det här scenariot, naturligtvis, eftersom vi aldrig förväntar oss dåliga saker™ att hända.
Så fungerar det
Fördröjd hållbarhet gör att skrivtransaktioner kan fortsätta köras som om loggen hade spolats till disken; i verkligheten har skrivningarna till disken grupperats och skjutits upp för att hanteras i bakgrunden. Affären är optimistisk; det förutsätter att loggen töms kommer hända. Systemet använder en 60KB bit loggbuffert och försöker spola loggen till disken när detta 60KB block är fullt (senast – det kan och kommer ofta att hända innan det). Du kan ställa in det här alternativet på databasnivå, på individuell transaktionsnivå eller – i fallet med inbyggda kompilerade procedurer i In-Memory OLTP – på procedurnivå. Databasinställningen vinner i händelse av en konflikt; till exempel, om databasen är inställd på inaktiverad, kommer försök att utföra en transaktion med det fördröjda alternativet att helt enkelt ignoreras, utan något felmeddelande. Dessutom är vissa transaktioner alltid helt hållbara, oavsett databasinställningar eller commit-inställningar; till exempel systemtransaktioner, transaktioner över databaser och operationer som involverar FileTable, Change Tracking, Change Data Capture och Replikering.
På databasnivå kan du använda:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Om du ställer in den på ALLOWED , betyder detta att varje enskild transaktion kan använda fördröjd hållbarhet; FORCED innebär att alla transaktioner som kan använda fördröjd hållbarhet kommer (undantagen ovan är fortfarande relevanta i detta fall). Du kommer förmodligen att vilja använda ALLOWED snarare än FORCED – men det senare kan vara användbart i fallet med en befintlig applikation där du vill använda detta alternativ genomgående och även minimera mängden kod som måste röras. En viktig sak att notera om ALLOWED är att fullt varaktiga transaktioner kan behöva vänta längre, eftersom de kommer att tvinga bort alla försenade varaktiga transaktioner först.
På transaktionsnivå kan du säga:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
Och i en inbyggt OLTP-kompilerad procedur i minnet kan du lägga till följande alternativ till BEGIN ATOMIC blockera:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
En vanlig fråga handlar om vad som händer med låsnings- och isoleringssemantik. Ingenting förändras, egentligen. Låsning och blockering sker fortfarande, och transaktioner begås på samma sätt och med samma regler. Den enda skillnaden är att, genom att tillåta commit att ske utan att vänta på att loggen ska spolas till disken, släpps alla relaterade lås så mycket tidigare.
När du bör använda den
Förutom fördelen du får av att låta transaktionerna fortsätta utan att vänta på att loggskrivningen ska ske, får du också färre loggskrivningar av större storlekar. Detta kan fungera mycket bra om ditt system har en hög andel transaktioner som faktiskt är mindre än 60KB, och särskilt när loggdisken är långsam (även om jag hittade liknande fördelar på SSD och traditionell hårddisk). Det fungerar inte så bra om dina transaktioner för det mesta är större än 60KB, om de vanligtvis är långvariga eller om du har hög genomströmning och hög samtidighet. Vad som kan hända här är att du kan fylla hela loggbufferten innan spolningen avslutas, vilket bara innebär att du överför dina väntetider till en annan resurs och i slutändan inte förbättrar den upplevda prestandan av användarna av applikationen.
Med andra ord, om din transaktionslogg för närvarande inte är en flaskhals, aktivera inte den här funktionen. Hur kan du se om din transaktionslogg för närvarande är en flaskhals? Den första indikatorn skulle vara hög WRITELOG väntar, särskilt när den är kopplad till PAGEIOLATCH_** . Paul Randal (@PaulRandal) har en fantastisk serie i fyra delar om att identifiera transaktionsloggproblem, samt konfigurera för optimal prestanda:
- Trimmar transaktionsloggen fett
- Trimmar mer transaktionsloggfett
- Konfigurationsproblem för transaktionslogg
- Övervakning av transaktionslogg
Se även det här blogginlägget från Kimberly Tripp (@KimberlyLTripp), 8 steg till bättre transaktionslogggenomströmning och SQL CAT-teamets blogginlägg, Diagnosing Transaction Log Performance Issues and Limits of the Log Manager.
Denna undersökning kan leda dig till slutsatsen att fördröjd hållbarhet är värt att titta närmare på; det kanske inte. Att testa din arbetsbelastning är det mest pålitliga sättet att veta säkert. Liksom många andra tillägg i de senaste versionerna av SQL Server (*hosta* Hekaton ), den här funktionen är INTE utformad för att förbättra varje enskild arbetsbelastning – och som nämnts ovan kan den faktiskt göra vissa arbetsbelastningar värre. Se det här blogginlägget av Simon Harvey för några andra frågor du bör ställa dig själv om din arbetsbelastning för att avgöra om det är möjligt att offra lite hållbarhet för att uppnå bättre prestanda.
Potential för dataförlust
Jag kommer att nämna detta flera gånger och lägga till betoning varje gång jag gör det:Du måste vara tolerant mot dataförlust . Under en välpresterande skiva är det maximala du kan förvänta dig att förlora i en katastrof – eller till och med en planerad och graciös avstängning – upp till ett helt block (60KB). Men i fallet där ditt I/O-undersystem inte kan hänga med, är det möjligt att du kan förlora så mycket som hela loggbufferten (~7MB).
För att förtydliga, från dokumentationen (min betoning):
För fördröjd hållbarhet, finns det ingen skillnad mellan en oväntad avstängning och en förväntad avstängning/omstart av SQL Server . Liksom katastrofala händelser, bör du planera för dataförlust . I en planerad avstängning/omstart kan vissa transaktioner som inte har skrivits till disken först sparas på disken, men du bör inte planera på det. Planera som om en avstängning/omstart, oavsett om den är planerad eller oplanerad, förlorar data på samma sätt som en katastrofal händelse.Så det är mycket viktigt att du väger din dataförlustrisk med ditt behov av att lindra problem med transaktionsloggprestanda. Om du driver en bank eller något som har att göra med pengar kan det vara mycket säkrare och mer lämpligt för dig att flytta din logg till en snabbare disk än att kasta tärningen med den här funktionen. Om du försöker förbättra svarstiden i din Web Gamerz Chat Room-applikation kanske risken är mindre allvarlig.
Du kan kontrollera detta beteende till viss del för att minimera risken för dataförlust. Du kan tvinga alla försenade varaktiga transaktioner att spolas till disken på ett av två sätt:
- Begå alla helt hållbara transaktioner.
- Ring
sys.sp_flush_logmanuellt.
Detta gör att du kan återgå till att kontrollera dataförlust i termer av tid, snarare än storlek; du kan till exempel schemalägga spolningen var 5:e sekund. Men du kommer att vilja hitta din sweet spot här; spolning för ofta kan kompensera fördelen med fördröjd hållbarhet i första hand. Hur som helst, måste du fortfarande vara tolerant mot dataförlust , även om det bara är värt
Du skulle kunna tro att CHECKPOINT kan hjälpa här, men den här operationen garanterar faktiskt inte tekniskt att loggen kommer att tömmas till disken.
Interaktion med HA/DR
Du kanske undrar hur Delayed Durablity fungerar med HA/DR-funktioner som loggsändning, replikering och tillgänglighetsgrupper. Med de flesta av dessa fungerar det oförändrat. Loggsändning och replikering kommer att spela upp loggposterna som har härdats, så samma risk för dataförlust finns där. Med AG:er i asynkront läge väntar vi inte på den sekundära bekräftelsen i alla fall, så den kommer att bete sig på samma sätt som idag. Med synkron kan vi dock inte commitera på den primära förrän transaktionen är committerad och härdad till fjärrloggen. Även i det scenariot kan vi ha en viss fördel lokalt genom att inte behöva vänta på att den lokala loggen ska skrivas, vi måste fortfarande vänta på fjärraktiviteten. Så i det scenariot finns det mindre fördelar, och potentiellt ingen; utom kanske i det sällsynta scenariot där den primära loggskivan är riktigt långsam och den sekundära loggskivan är riktigt snabb. Jag misstänker att samma villkor gäller för synk/asynkronspegling, men du kommer inte att få något officiellt åtagande från mig om hur en glänsande ny funktion fungerar med en föråldrad. :-)
Prestandaobservationer
Det här skulle inte vara mycket av ett inlägg här om jag inte visade några faktiska prestationsobservationer. Jag satte upp 8 databaser för att testa effekterna av två olika arbetsbelastningsmönster med följande attribut:
- Återställningsmodell:enkel vs. full
- Loggplats:SSD vs HDD
- Hållbarhet:fördröjd kontra helt hållbar
Jag är verkligen, verkligen, verkligen lat effektiv om sånt här. Eftersom jag vill undvika att upprepa samma operationer inom varje databas skapade jag följande tabell tillfälligt i model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Sedan byggde jag en uppsättning dynamiska SQL-kommandon för att bygga dessa 8 databaser, istället för att skapa databaserna individuellt och sedan smutskasta med inställningarna:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Kör gärna den här koden själv (med EXEC). fortfarande kommenterade) för att se att detta skulle skapa 4 databaser med fördröjd hållbarhet AV (två i FULL återställning, två i SIMPLE, en av varje med logga på långsam disk och en av varje med logga på SSD). Upprepa det mönstret för 4 databaser med fördröjd hållbarhet FORCED – jag gjorde detta för att förenkla koden i testet, snarare än för att återspegla vad jag skulle göra i verkligheten (där jag förmodligen skulle vilja behandla vissa transaktioner som kritiska, och vissa som, Tja, mindre än kritiskt).
För förnuftskontroll körde jag följande fråga för att säkerställa att databaserna hade rätt matris med attribut:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Resultat:
| namn | återställningsmodell | delayed_durability | log_disk |
|---|---|---|---|
| dd1 | FULLT | TVÅNGAD | SSD |
| dd2 | ENKEL | TVÅNGAD | SSD |
| dd3 | FULLT | TVÅNGAD | Hårddisk |
| dd4 | ENKEL | TVÅNGAD | Hårddisk |
| dd5 | FULLT | INAKTIVERAD | SSD |
| dd6 | ENKEL | INAKTIVERAD | SSD |
| dd7 | FULLT | INAKTIVERAD | Hårddisk |
| dd8 | ENKEL | INAKTIVERAD | Hårddisk |
Relevant konfiguration av de 8 testdatabaserna
Jag körde också testet rent flera gånger för att säkerställa att en 1 GB datafil och 1 GB loggfil skulle räcka för att köra hela uppsättningen av arbetsbelastningar utan att införa några autogrowth-händelser i ekvationen. Som en bästa praxis går jag rutinmässigt ut för att säkerställa att kundernas system har tillräckligt med tilldelat utrymme (och korrekta varningar inbyggda) så att ingen tillväxthändelse någonsin inträffar vid en oväntad tidpunkt. I den verkliga världen vet jag att detta inte alltid händer, men det är idealiskt.
Jag konfigurerade systemet för att övervakas med SQL Sentry – detta skulle tillåta mig att enkelt visa de flesta prestandamått som jag ville lyfta fram. Men jag skapade också en tillfällig tabell för att lagra batch-statistik inklusive varaktighet och mycket specifik utdata från sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Detta skulle tillåta mig att registrera start- och sluttid för varje enskild batch och mäta delta i DMV mellan starttid och sluttid (endast tillförlitligt i det här fallet eftersom jag vet att jag är den enda användaren på systemet).
Många små transaktioner
Det första testet jag ville göra var många små transaktioner. För varje databas ville jag sluta med 500 000 separata partier av en enda inlaga vardera:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Kom ihåg att jag försöker vara lat effektiv om sånt här. Så för att generera koden för alla 8 databaser körde jag detta:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Jag körde det här testet och tittade sedan på #Metrics tabell med följande fråga:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Detta gav följande resultat (och jag bekräftade genom flera tester att resultaten var konsekventa):
| databas | skriver | byte | bytes/skriv | io_stall_ms | starttid | sluttid | varaktighet (sekunder) |
|---|---|---|---|---|---|---|---|
| dd1 | 8 068 | 261 894 656 | 32 460,91 | 6 232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8 072 | 261 682 688 | 32 418,56 | 2 740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8 246 | 262 254 592 | 31 803,85 | 3 996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8 055 | 261 688 320 | 32 487,68 | 4 231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500 012 | 526 448 640 | 1 052,87 | 35 593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500 014 | 525 870 080 | 1 051,71 | 35 435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500 015 | 526 120 448 | 1 052,20 | 50 857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500 017 | 525 886 976 | 1 051,73 | 49 680 | 133 |
Små transaktioner:Varaktighet och resultat från sys.dm_io_virtual_file_stats
Definitivt några intressanta observationer här:
- Antalet individuella skrivoperationer var mycket litet för databaserna med fördröjd hållbarhet (~60X för traditionella).
- Totalt antal skrivna bytes halverades med fördröjd hållbarhet (jag antar att alla skrivningar i det traditionella fallet innehöll mycket slöseri med utrymme).
- Antalet byte per skrivning var mycket högre för fördröjd hållbarhet. Detta var inte alltför överraskande, eftersom hela syftet med funktionen är att bunta samman skrivningar i större omgångar.
- Den totala varaktigheten av I/O-stopp var flyktig, men ungefär en storleksordning lägre för fördröjd hållbarhet. Båsen under helt hållbara transaktioner var mycket mer känsliga för typen av disk.
- Om något inte har övertygat dig hittills är kolumnen varaktighet mycket talande. Helt hållbara partier som tar två minuter eller mer halveras nästan.
Kolumnerna för start/sluttid gjorde det möjligt för mig att fokusera på Performance Advisor-instrumentpanelen för den exakta perioden då dessa transaktioner ägde rum, där vi kan dra många ytterligare visuella indikatorer:
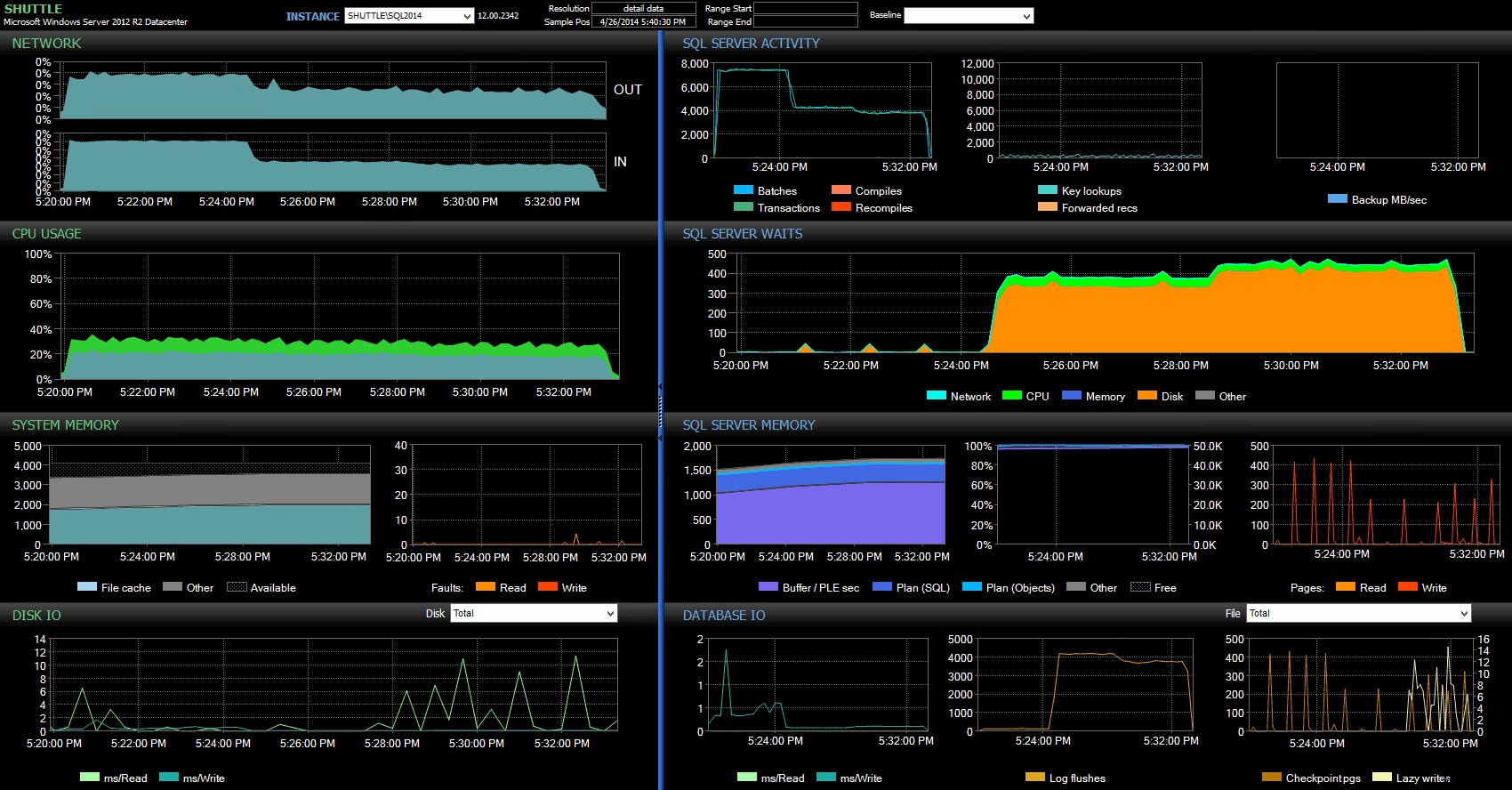
SQL Sentry-instrumentpanel – klicka för att förstora
Ytterligare observationer här:
- På flera diagram kan du tydligt se exakt när den icke-fördröjda hållbarhetsdelen av partiet tog över (~17:24:32).
- Det finns ingen observerbar påverkan på CPU eller minne när du använder fördröjd hållbarhet.
- Du kan se en enorm påverkan på batcher/transaktioner per sekund i det första diagrammet under SQL Server Activity.
- SQL Server väntar går igenom taket när de fullt hållbara transaktionerna startade. Dessa bestod nästan uteslutande av
WRITELOGväntar, med ett litet antalPAGEIOLOATCH_EXochPAGEIOLATCH_UPväntar på bra mått. - Det totala antalet loggspolningar under operationerna med fördröjd hållbarhet var ganska litet (låga 100 s/sek), medan detta hoppade till över 4 000/sek för det traditionella beteendet (och något lägre under testets varaktighet på hårddisken).
Färre, större transaktioner
Till nästa test ville jag se vad som skulle hända om vi utförde färre operationer, men såg till att varje påstående påverkade en större mängd data. Jag ville att denna batch skulle köras mot varje databas:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Så återigen använde jag den lata metoden för att producera 8 kopior av detta skript, en per databas:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Jag körde den här batchen och ändrade sedan frågan mot #Metrics ovan för att titta på det andra testet istället för det första. Resultaten:
| databas | skriver | byte | bytes/skriv | io_stall_ms | starttid | sluttid | varaktighet (sekunder) |
|---|---|---|---|---|---|---|---|
| dd1 | 20 970 | 1 271 911 936 | 60 653,88 | 12 577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20 997 | 1 272 145 408 | 60 587,00 | 14 698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20 973 | 1 272 982 016 | 60 696.22 | 12 085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20 958 | 1 272 064 512 | 60 695,89 | 11 795 | 143 | ||
| dd5 | 30 138 | 1 282 231 808 | 42 545,35 | 7 402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30 138 | 1 282 260 992 | 42 546.31 | 7 806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30 129 | 1 281 575 424 | 42 536,27 | 9 888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30 130 | 1 281 449 472 | 42 530,68 | 11 452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Större transaktioner:Varaktighet och resultat från sys.dm_io_virtual_file_stats
Den här gången är effekten av fördröjd hållbarhet mycket mindre märkbar. Vi ser ett något mindre antal skrivoperationer, med ett något större antal byte per skrivning, med det totala antalet byte skrivna nästan identiska. I det här fallet ser vi faktiskt att I/O-stallen är högre för fördröjd hållbarhet, och detta förklarar sannolikt det faktum att varaktigheterna också var nästan identiska.
Från Performance Advisor-instrumentpanelen har vi några likheter med det tidigare testet, och några skarpa skillnader också:
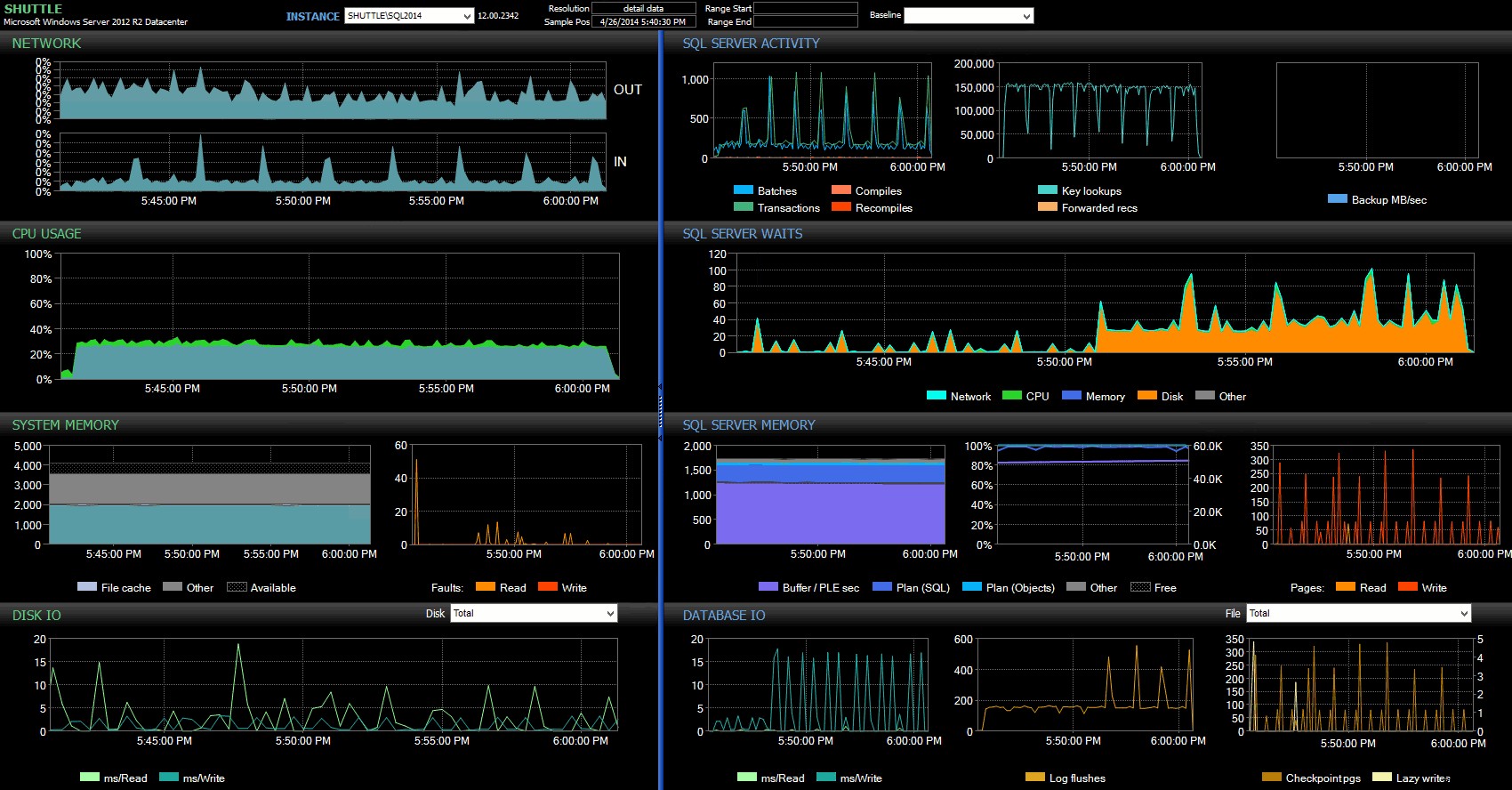
SQL Sentry-instrumentpanel – klicka för att förstora
En av de stora skillnaderna att påpeka här är att statistiken för delta i väntan inte är riktigt lika uttalad som med föregående test – det finns fortfarande en mycket högre frekvens av WRITELOG väntar på de fullt hållbara partierna, men inte i närheten av de nivåer som setts med de mindre transaktionerna. En annan sak du kan se direkt är att den tidigare observerade effekten på batcher och transaktioner per sekund inte längre är närvarande. Och slutligen, även om det finns fler loggar med helt hållbara transaktioner än vid försening, är denna skillnad mycket mindre uttalad än med de mindre transaktionerna.
Slutsats
Det bör vara tydligt att det finns vissa typer av arbetsbelastning som kan dra stor nytta av fördröjd hållbarhet – givetvis förutsatt att du har en tolerans för dataförlust . Den här funktionen är inte begränsad till In-Memory OLTP, är tillgänglig på alla utgåvor av SQL Server 2014 och kan implementeras med få eller inga kodändringar. Det kan säkert vara en kraftfull teknik om din arbetsbelastning kan stödja den. Men återigen, du måste testa din arbetsbelastning för att vara säker på att den kommer att dra nytta av den här funktionen, och även starkt överväga om detta ökar din exponering för risken för dataförlust.
För övrigt kan detta tyckas för SQL Server-publiken som en fräsch ny idé, men i sanning introducerade Oracle detta som "Asynchronous Commit" 2006 (se COMMIT WRITE ... NOWAIT som dokumenterats här och bloggat om 2007). Och själva idén har funnits i nästan 3 decennier; se Hal Berensons korta krönika om dess historia.
Nästa gång
En idé som jag har slagit runt är att försöka förbättra prestandan för tempdb genom att tvinga dit fördröjd hållbarhet. En speciell egenskap för tempdb som gör den till en så frestande kandidat är att den är övergående av naturen – allt i tempdb är designad, uttryckligen, för att kunna kastas i kölvattnet av en mängd olika systemhändelser. Jag säger detta nu utan att ha någon aning om det finns en arbetsbelastningsform där detta kommer att fungera bra; men jag planerar att prova det, och om jag hittar något intressant kan du vara säker på att jag kommer att skriva om det här.