Det finns en regressionsbugg i SQL Server 2012 och SQL Server 2014, där du kan uppleva dataförlust eller korruption . Detta borde vara ett relativt sällsynt scenario (Phil Brammer har en enkel repro i Connect #795134), men dataförlust är dataförlust, och jag är inte beredd att spela. Korrigeringen beskrivs i KB #2969896:FIX:Dataförlust i klustrade index uppstår när du kör onlinebyggindex i SQL Server 2012.
Alla behöver inte oroa sig för denna fråga. Om du inte kör Enterprise (eller motsvarande) Edition, kan du inte utföra parallella eller online-ombyggnader i första hand (och det finns förmodligen en del på Enterprise som inte bygger om eller inte bygger om online). Om du har instansomfattande MAXDOP satt till 1, kan de inte gå parallellt om du inte åsidosätter det på satsnivån. Men om du är på 2012 eller 2014 och kör en adekvat utgåva, och dina online-ombyggnader kan gå parallellt, är du sårbar för detta problem.
Som jag antydde ovan kunde detta problem manifestera sig i SQL Server 2012 RTM, Service Pack 1 och till och med Service Pack 2, som släpptes den 10 juni. Felet fixades inte förrän långt efter att SP2-koden frysts, så SP2 gör det. inkludera inte denna korrigering eller någon av korrigeringarna från SP1 CU #10 eller #11. Jag bloggade om detta här. RTM-grenen saknar officiellt stöd, så du kommer inte att se en fix där. Problemet kan också uppstå i SQL Server 2014.
Det finns nu kumulativa uppdateringar tillgängliga för SQL Server 2012 Service Pack 1 &2 samt SQL Server 2014. En snabb sammanfattning av alternativen jag rekommenderar:
Om din gren / @@VERSION är...
| ...du borde... | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| Gör ingenting; du har redan korrigeringen. | |||||
| |||||
| Gör ingenting; du har redan korrigeringen. | |||||
| SQL Server 2014 RTM |
| ||||
| Gör ingenting; du har redan korrigeringen. | |||||
| * Om du installerar SP1-snabbkorrigeringen eller kumulativ uppdatering #11 och sedan installerar SP2 kommer du att ångra dessa ändringar, inklusive denna fix. | |||||
Lösningar för snabbkorrigeringen/CU-averse
Eftersom alla berörda grenar (nåja, förutom 2012 RTM) har en snabbkorrigering på begäran och/eller en kumulativ uppdatering som åtgärdar problemet, är det enkla svaret att bara installera den relevanta uppdateringen. Men du kan vara i ett scenario där din företagspolicy eller testcykler hindrar dig från att distribuera dessa uppdateringar snabbt, eller kanske någonsin. Så vilka andra alternativ har du?
- Du kan sluta utföra ombyggnader tills det finns ett nytt service pack tillgängligt för din filial (kanske kan du bara hålla fast vid
REORGANIZEtills vidare). Tyvärr, om du är i ett "service pack only"-företag, är dina alternativ mycket begränsade:du kan kämpa hårdare för att ändra den policyn, eller så kan du vänta på SQL Server 2012 Service Pack 3 (vilket kan ta lång tid, eller kanske kom helt enkelt aldrig – se FAQ #21 här) eller SQL Server 2014 Service Pack 1 (som vi förmodligen inte kommer att se innan 2015 rullar runt). - Du kan ställa in den instansomfattande
max degree of parallelismtill 1, men detta kan ha en negativ effekt på resten av din arbetsbelastning – tänk på saker som flertrådad DBCC, parallella frågor mot eller mellan partitionerade tabeller och andra operationer där du kanske vill minska parallelliteten men inte eliminera den helt. Den här inställningen kommer inte heller att påverka en online-ombyggnad med till exempel en explicitMAXDOP = 8hårdkodad i kommandot, eftersom detta kommer att åsidosättasp_configureinställning.
- Du kan lägga till
WITH (MAXDOP = 1)alternativet manuellt till alla dina återuppbyggnadskommandon. (Obs:du behöver inte göra detta för XML-index, eftersom de i sig körs entrådade, men jag skulle bara tillämpa det på alla ombyggnader för konsekvens och för att undvika onödig villkorlig logik.)
- Du kan ställa in dina indexunderhållsjobb så att de körs som en specifik inloggning och sedan använda Resource Governor för att skapa en arbetsbelastningsgrupp som begränsar inloggningens
MAX_DOPtill 1, oavsett vad de gör. Jag har ett exempel på detta i vitboken från 2008 som jag skrev tillsammans med Boris Baryshnikov, Using the Resource Governor, i avsnittet med rubriken "Limiting Parallelism for Intensive Background Jobs."
- Om du använder Ola Hallengrens indexunderhållslösning kan du lägga till
@MaxDopparameter till dina anrop tilldbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Om du använder SQL Sentry Fragmentation Manager kan du diktera nivån för
MAXDOPatt använda under Inställningar – och du kan göra det här i hela företaget, per instans, per databas eller till och med per enskilt index (i det här fallet vill du antagligen ställa in detta per instans, för alla instanser utan en tillgänglig fix):
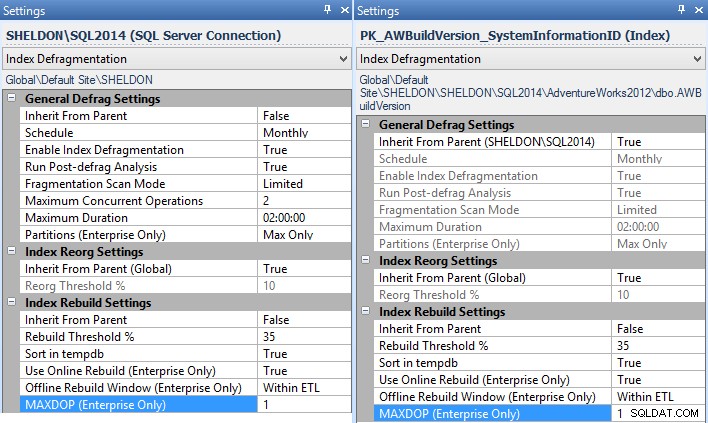
Fragmentation Manager-inställningar för instansen (vänster) och ett individuellt index (höger). - Om du använder underhållsplaner för dina indexombyggnader, måste du ändra dem för att använda Execute T-SQL Statement Tasks, och skriv ditt
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);kommandon manuellt (så kan lika gärna byta till en automatiserad lösning). Se, Index Rebuild Task har inte en exponerad egenskap förMAXDOP, även om det har begärts flera gånger (senast 2012, av Alberto Morillo, och så långt tillbaka som 2006, av Linchi Shea). Och titta bara på alla dessa andra användbara egenskaper de avslöjar, somAdvSortInTempdb,ObjectTypeSelectionochTaskAllowesDatbaseSelection[sic!]:
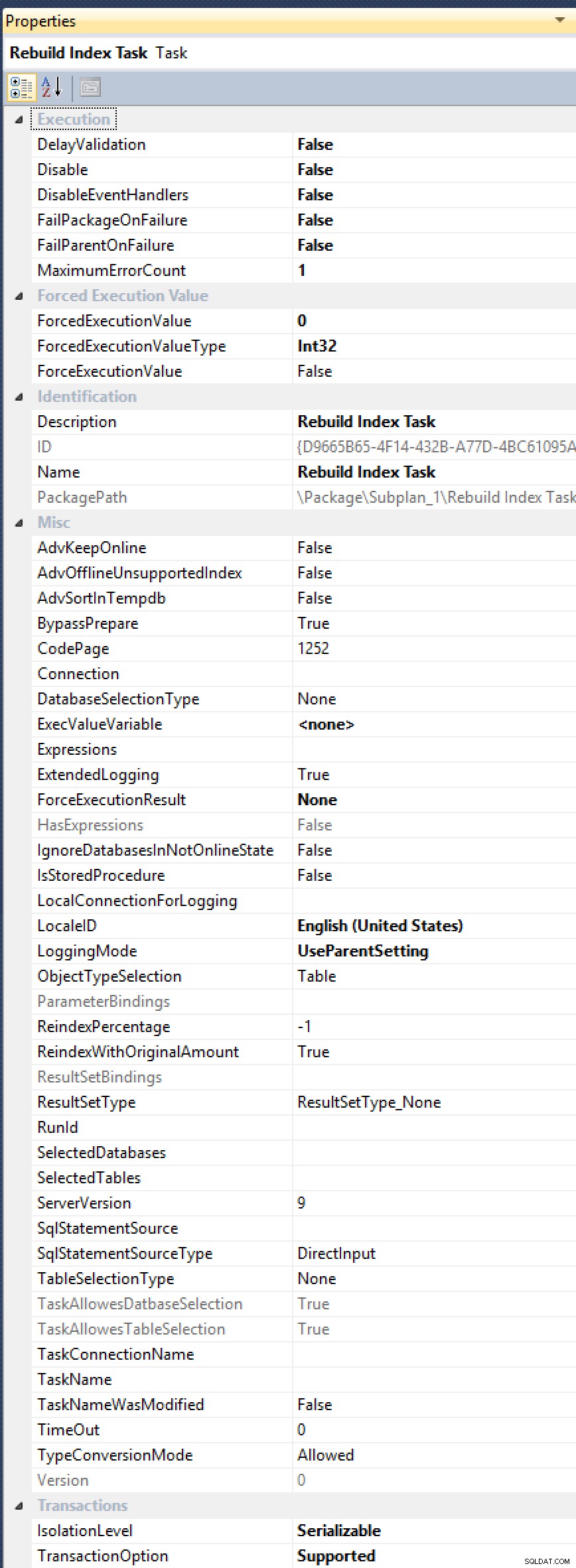
Alla dessa alternativ, men fortfarande inget botemedel mot MAXDOP.