Svaret blir givetvis "det beror på" men baserat på att testa detta mål...
Förutsatt att
- 1 miljon produkter
producthar ett klustrat index påproduct_id- De flesta (om inte alla) produkter har motsvarande information i
product_codetabell - Ideala index som finns på
product_codeför båda frågorna.
PIVOT versionen behöver helst ett index product_code(product_id, type) INCLUDE (code) medan JOIN version behöver helst ett index product_code(type,product_id) INCLUDE (code)
Om dessa finns på plats anger du planerna nedan
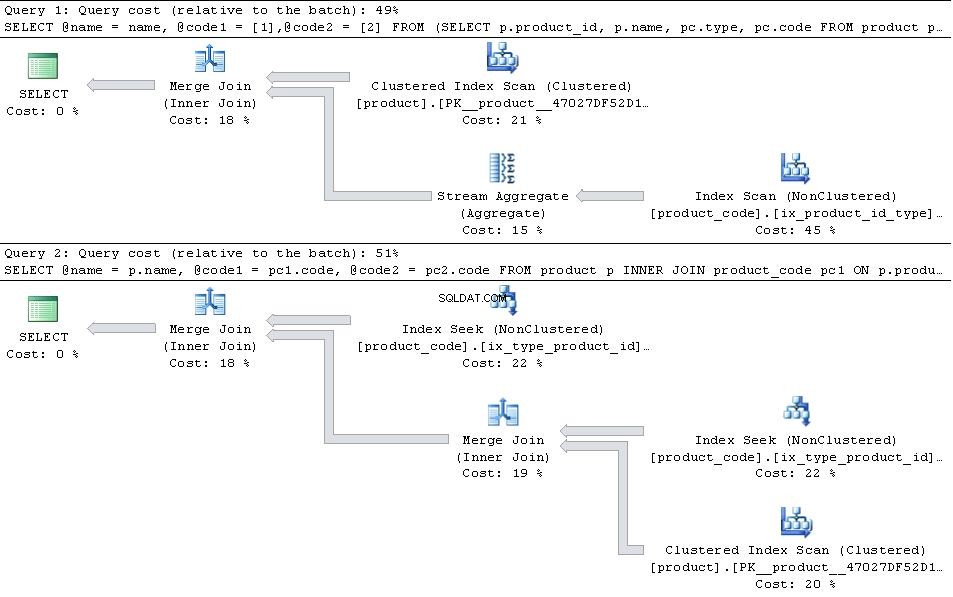
sedan JOIN versionen är mer effektiv.
I det fall type 1 och type 2 är de enda types i tabellen sedan PIVOT versionen har en aning fördel när det gäller antal läsningar eftersom den inte behöver söka in product_code två gånger men det vägs mer än upp av den extra omkostnaden för strömaggregatoperatören
PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
GÅ MED
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Om det finns ytterligare type andra poster än 1 och 2 JOIN version kommer att öka sin fördel eftersom den bara slår samman sammanfogningar på de relevanta avsnitten av type,product_id index medan PIVOT planen använder product_id, type och så skulle behöva skanna över den ytterligare type rader som är blandade med 1 och 2 rader.