SQL Server ger oss olika lösningar för att replikera eller arkivera en eller flera databastabeller till en annan databas, eller samma databas med olika namn. Som SQL Server-utvecklare eller databasadministratör kan du ställas inför situationer när du behöver kontrollera att data i dessa två tabeller är identiska, och om, av misstag, data inte replikeras mellan dessa två tabeller, måste du synkronisera data mellan borden. Dessutom, om du får ett felmeddelande som bryter datasynkroniseringen eller replikeringsprocessen, på grund av schemaskillnader mellan käll- och måltabellerna, måste du hitta ett enkelt och snabbt sätt att identifiera schemaskillnaderna, ÄNDRA tabellerna för att göra schemat identiskt på båda sidor och återuppta datasynkroniseringsprocessen.
I andra situationer behöver du ett enkelt sätt att få svaret JA eller NEJ, om data och schema för två tabeller är identiska eller inte. I den här artikeln kommer vi att gå igenom de olika sätten att jämföra data och schema mellan två tabeller. De tillhandahållna metoderna i den här artikeln kommer att jämföra tabeller som finns i olika databaser, vilket är det mer komplicerade scenariot, och kan också enkelt användas för att jämföra tabellerna i samma databas med olika namn.
Innan vi beskriver de olika metoderna och verktygen som kan användas för att jämföra tabellernas data och scheman, kommer vi att förbereda vår demomiljö genom att skapa två nya databaser och skapa en tabell i varje databas, med en liten datatypsskillnad mellan dessa två tabeller, som visas i satserna CREATE DATABASE och CREATE TABLE T-SQL nedan:
CREATE DATABASE TESTDB CREATE DATABASE TESTDB2 CREATE TABLE TESTDB.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address VARCHAR (500) ) GO CREATE TABLE TESTDB2.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address NVARCHAR (400) ) GO
Efter att ha skapat databaserna och tabellerna kommer vi att fylla de två tabellerna med fem identiska rader och sedan infoga ytterligare en ny post endast i den första tabellen, som visas i INSERT INTO T-SQL-satserna nedan:
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('DDD','EEE','FFF')
GO Nu är testmiljön redo att börja beskriva metoderna för jämförelse av data och scheman.
Jämför tabelldata med en LEFT JOIN
Nyckelordet LEFT JOIN T-SQL används för att hämta data från två tabeller, genom att returnera alla poster från den vänstra tabellen och endast de matchade posterna från den högra tabellen och NULL-värdena från den högra tabellen när det inte finns någon matchning mellan de två tabellerna.
För datajämförelseändamål kan nyckelordet LEFT JOIN användas för att jämföra två tabeller, baserat på den gemensamma unika kolumnen som ID-kolumnen i vårt fall, som i SELECT-satsen nedan:
SELECT * FROM TESTDB.dbo.FirstComTable F LEFT JOIN TESTDB2.dbo.FirstComTable S ON F.ID =S.ID
Den föregående frågan kommer att returnera de vanliga fem raderna som finns i de två tabellerna, utöver raden som finns i den första tabellen och som saknas i den andra, genom att visa NULL-värden till höger om resultatet, som visas nedan:
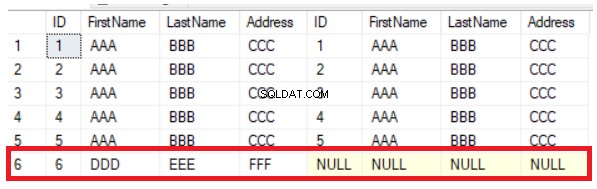
Du kan enkelt härleda från det föregående resultatet att den sjätte kolumnen som finns i den första tabellen saknas från den andra tabellen. För att synkronisera raderna mellan tabellerna måste du infoga den nya posten i den andra tabellen manuellt. LEFT JOIN-metoden är till hjälp för att verifiera de nya raderna men hjälper inte vid uppdatering av kolumnvärdena. Om du ändrar värdet för adresskolumnen på den 5:e raden kommer metoden LEFT JOIN inte att upptäcka den ändringen, vilket tydligt visas nedan:
Jämför tabelldata med UTOM Klausul
EXCEPT-satsen returnerar raderna från den första frågan (vänsterfrågan) som inte returneras från den andra frågan (högerfrågan). Med andra ord kommer EXCEPT-satsen att returnera skillnaden mellan två SELECT-satser eller tabeller, vilket hjälper oss att enkelt jämföra data i dessa tabeller.
EXCEPT-satsen kan användas för att jämföra data i de tidigare skapade tabellerna, genom att ta skillnaden mellan SELECT *-frågan från den första tabellen och SELECT *-frågan från den andra tabellen, med hjälp av T-SQL-satserna nedan:
SELECT * FROM TESTDB.dbo.FirstComTable F EXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
Resultatet av den föregående frågan blir raden som är tillgänglig i den första tabellen och inte tillgänglig i den andra, som visas nedan:
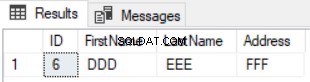
Att använda EXCEPT-satsen för att jämföra två tabeller är bättre än LEFT JOIN-satsen eftersom de uppdaterade posterna fångas i dataskillnadsresultatet. Antag att vi uppdaterade adressen för rad nummer 5 i den andra tabellen och kontrollerade skillnaden med EXCEPT-satsen igen, du kommer att se att rad nummer 5 kommer att returneras med skillnadsresultatet som visas nedan:
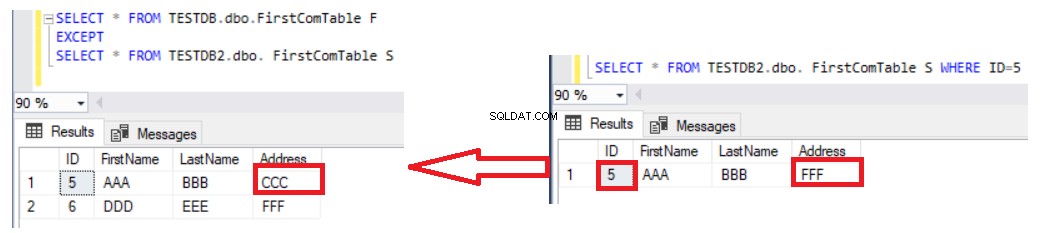
Den enda nackdelen med att använda EXCEPT-satsen för att jämföra data i två tabeller är att du måste synkronisera data manuellt genom att skriva en INSERT-sats för de saknade posterna i den andra tabellen. Tänk på att de två tabellerna som jämförs är nyckeltabeller för att få rätt resultat, med en unik nyckel som används för jämförelse. Om vi tar bort den unika ID-kolumnen från SELECT-satsen på båda EXCEPT-satssidorna och listar resten av icke-nyckelkolumner, som i satsen nedan:
SELECT FirstName, LastName, Address FROM TESTDB.dbo. FirstComTable F EXCEPT SELECT FirstName, LastName, Address FROM TESTDB2.dbo. FirstComTable S
Resultatet kommer att visa att endast de nya posterna returneras, och de uppdaterade kommer inte att listas, som visas i resultatet nedan:
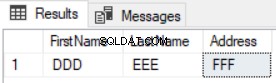
Jämför tabelldata med en UNION ALL … GROUP BY
UNION ALL-satsen kan också användas för att jämföra data i två tabeller, baserat på en unik nyckelkolumn. För att använda UNION ALL-satsen för att returnera skillnaden mellan två tabeller måste du lista kolumnerna som ska jämföras i SELECT-satsen och använda dessa kolumner i GROUP BY-satsen, som visas i T-SQL-frågan nedan:
SELECT DISTINCT *
FROM
(
SELECT * FROM
( SELECT * FROM TESTDB.dbo. FirstComTable
UNION ALL
SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls
GROUP BY ID,FirstName, LastName, Address
HAVING COUNT(*)<2) Diff Och bara raden som finns i den första tabellen och som saknas från den andra tabellen kommer att returneras enligt nedan:
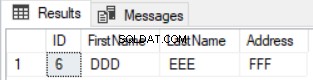
Den tidigare frågan kommer också att fungera bra vid uppdatering av poster men på ett annat sätt. Det kommer att returnera de nyligen infogade posterna utöver de uppdaterade kolumnerna från båda tabellerna, som i fallet med rad nummer 5, som visas nedan:
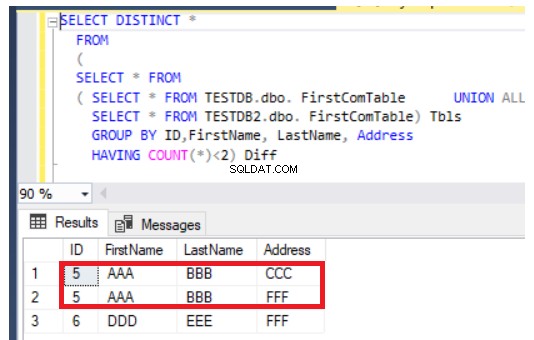
Jämför tabelldata med SQL Server-dataverktyg
SQL Server Data Tools, även känd som SSDT, byggda över Microsoft Visual Studio kan enkelt användas för att jämföra data i två tabeller med samma namn, baserat på en unik nyckelkolumn, värd i två olika databaser och synkronisera data i dessa tabeller , eller generera ett synkroniseringsskript som ska användas senare.
Från det öppnade SSDT-fönstret, klicka på Verktyg-menyn -> SQL Server-lista och väljNy datajämförelse alternativ, som visas nedan:
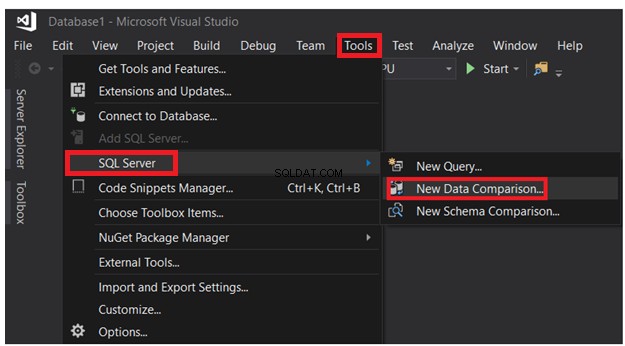
I det visade anslutningsfönstret kan du välja bland de tidigare anslutna sessionerna, eller fylla fönstret Anslutningsegenskaper med SQL Server-namnet, autentiseringsuppgifter och databasnamnet och klicka sedan på Anslut , som visas nedan:

I den visade guiden Ny datajämförelse, ange käll- och måldatabasernas namn och de jämförelsealternativ som används i tabelljämförelseprocessen och klicka sedan på Nästa , som visas nedan:
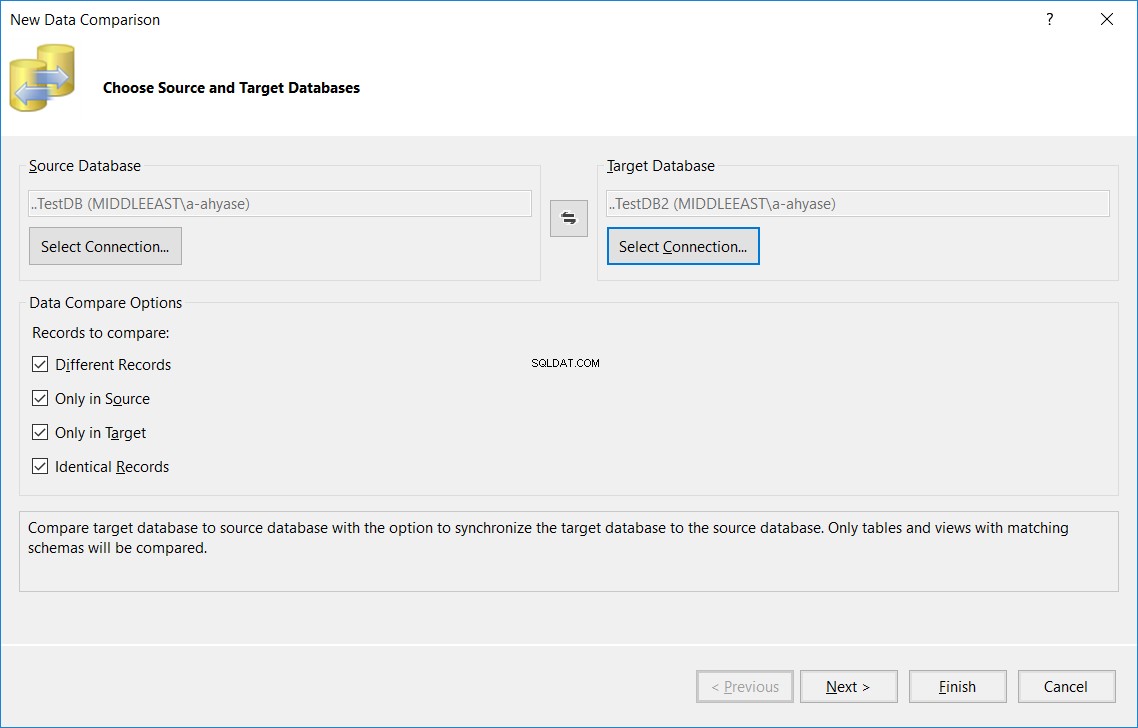
I nästa fönster, ange namnet på tabellen, som ska vara samma namn i käll- och måldatabaserna, som ska jämföras i båda databaserna och klicka påSlutför , enligt nedan:
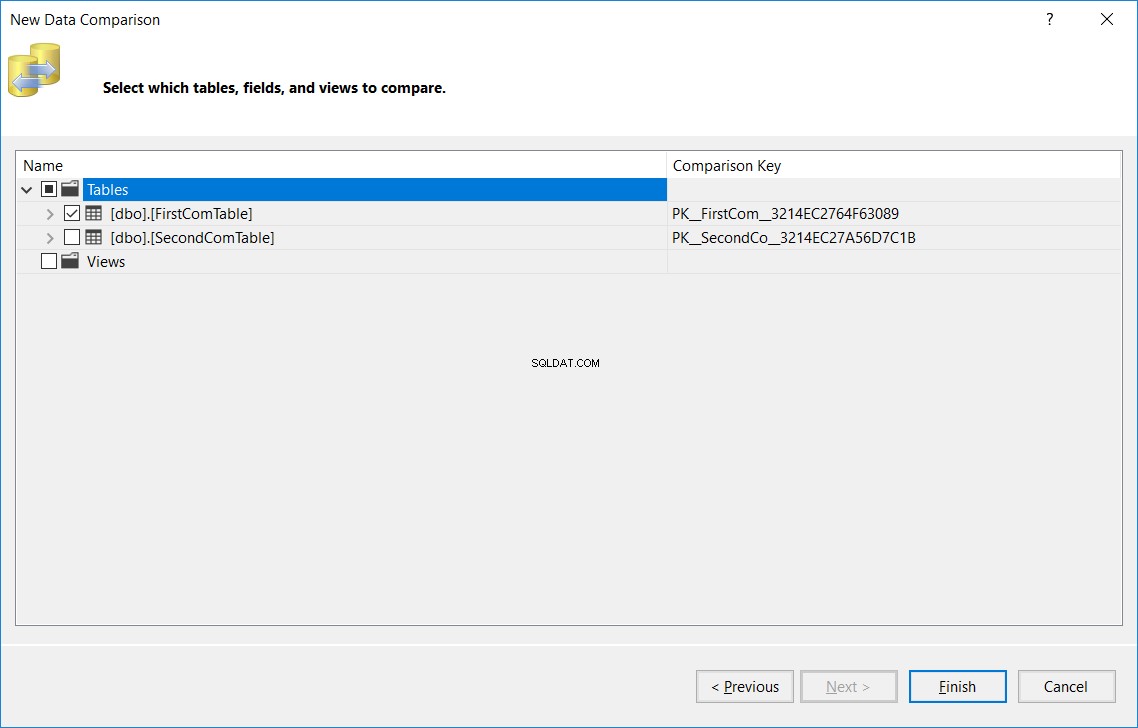
Det visade resultatet kommer att visa dig antalet poster som finns i källan och missade från målet, hittade i målet och missade från källan, antalet uppdaterade poster med samma nyckel och olika kolumnvärden (Olika poster) och slutligen antalet identiska poster som finns i båda tabellerna, som visas nedan:
Klicka på tabellnamnet i föregående resultat, du kommer att hitta en detaljerad vy av dessa fynd, som visas nedan:

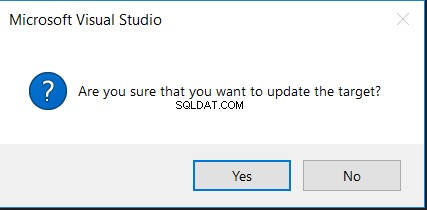
Du kan använda samma verktyg för att generera ett skript för att synkronisera käll- och måltabellerna eller uppdatera måltabellen direkt med de saknade eller olika ändringarna, enligt nedan:
Om du klickar på alternativet Generate Script kommer en INSERT-sats med den saknade kolumnen i måltabellen att visas, som visas nedan:
BEGIN TRANSACTION
BEGIN TRANSACTION SET IDENTITY_INSERT [dbo].[FirstComTable] ON INSERT INTO [dbo].[FirstComTable] ([ID], [FirstName], [LastName], [Address]) VALUES (6, N'DDD', N'EEE', N'FFF') SET IDENTITY_INSERT [dbo].[FirstComTable] OFF COMMIT TRANSACTION
Om du väljer alternativet Uppdatera mål kommer du först att be dig om din bekräftelse för att utföra ändringen, som i meddelandet nedan:
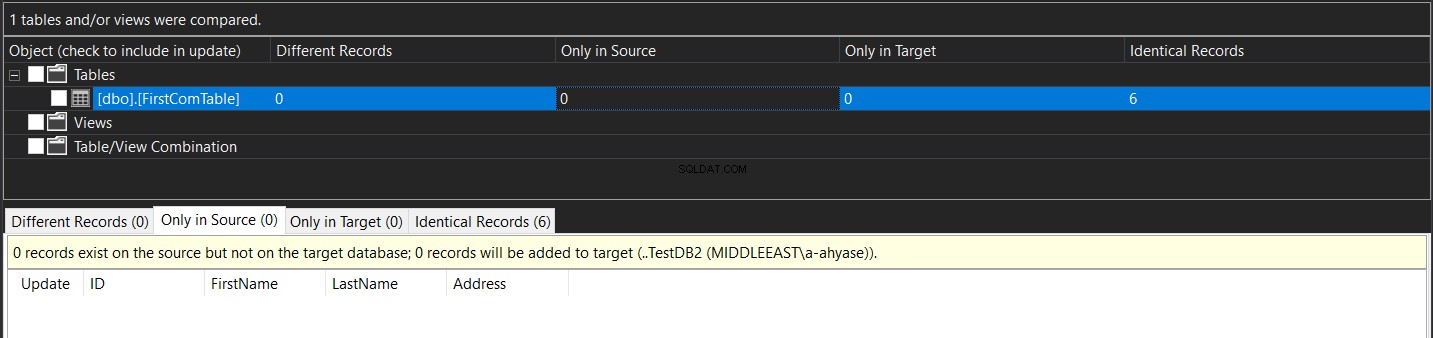
Efter synkroniseringen kommer du att se att data i de två tabellerna är identiska, som visas nedan:
Jämför tabelldata med hjälp av tredjepartsverktyget "dbForge Studio for SQL Server"
I SQL Server-världen kan du hitta ett stort antal tredjepartsverktyg som gör livet enkelt för databasadministratörer och utvecklare. Ett av dessa verktyg, som gör databasadministrationen till en bit av kakan, är dbForge Studio för SQL Server, som ger oss enkla sätt att utföra databasadministration och utvecklingsuppgifter. Det här verktyget kan också hjälpa oss att jämföra data i databastabellerna och synkronisera dessa tabeller.
På menyn Jämförelse väljer du Ny datajämförelse alternativ, som visas nedan:
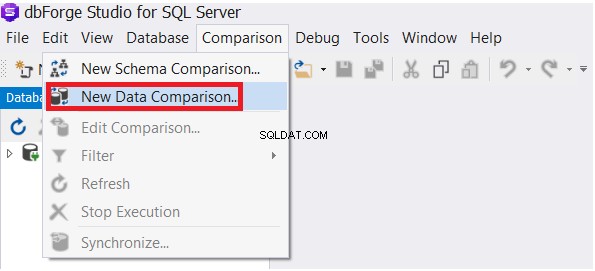
Ange källan och måldatabasen i guiden Ny datajämförelse och klicka sedan på Nästa :
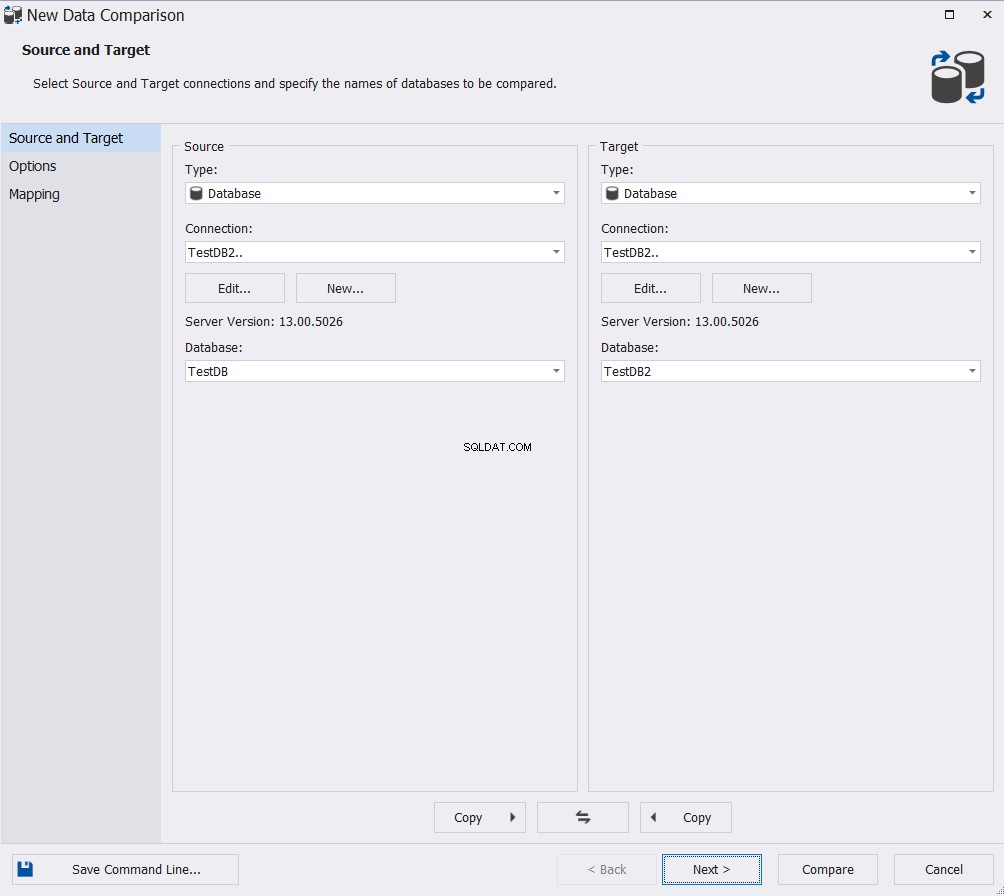
Välj lämpliga alternativ från det stora utbudet av tillgängliga kart- och jämförelsealternativ och klicka på Nästa :
Ange namnet på den eller de tabeller som ska delta i datajämförelseprocessen. Guiden kommer att visa ett varningsmeddelande om det finns några schemaskillnader mellan käll- och måldatabaserna. Klicka på Jämför för att fortsätta:
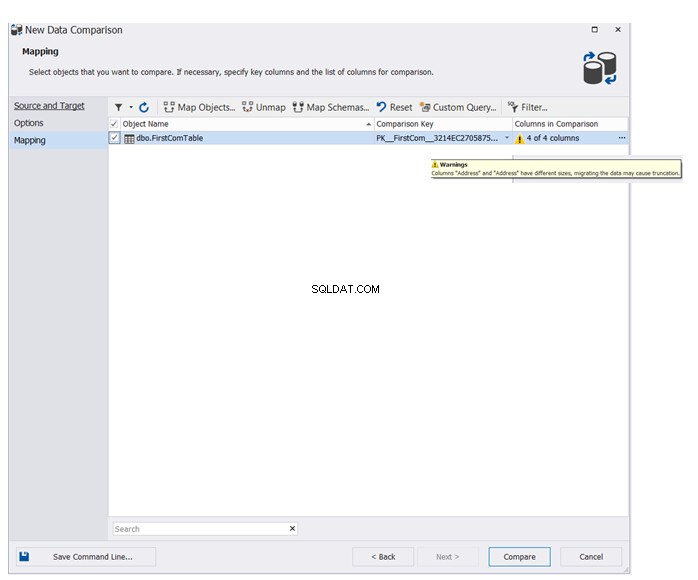
Det slutliga resultatet kommer att visa dig i detalj, dataskillnaderna mellan käll- och måltabellerna, med möjligheten att klicka  för att synkronisera käll- och måltabellerna, som visas nedan:
för att synkronisera käll- och måltabellerna, som visas nedan:
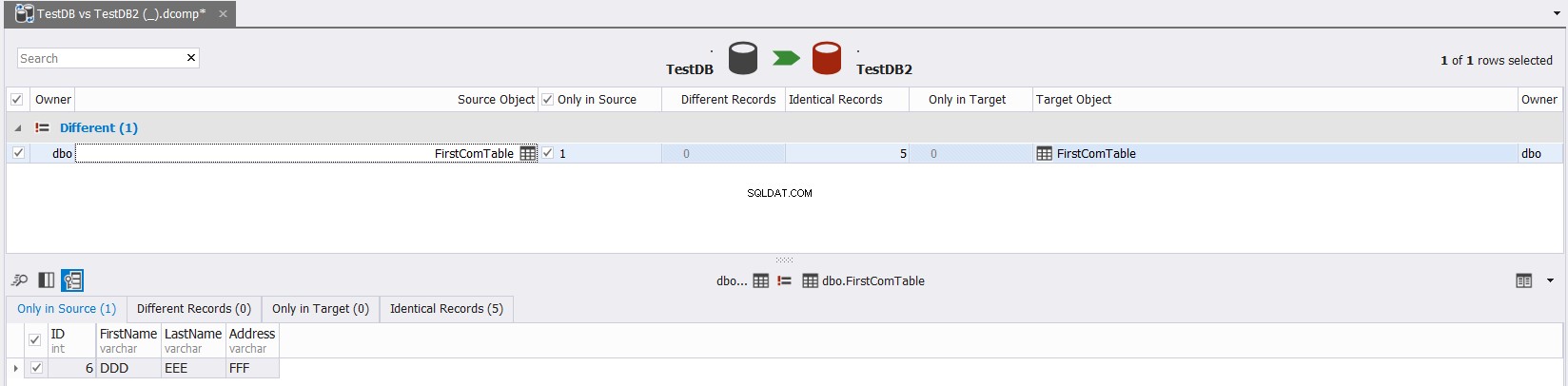
Jämför tabellschema med sys.columns
Som nämndes i början av den här artikeln, för att replikera eller arkivera en tabell, måste du se till att schemat för käll- och måltabellerna är identiska. SQL Server ger oss olika sätt att jämföra schemat för tabellerna i samma databas eller olika databaser. Den första metoden är att fråga systemkatalogvyn sys.columns, som returnerar en rad för varje kolumn i ett objekt som har en kolumn, med egenskaperna för varje kolumn.
För att jämföra schemat för tabeller som finns i olika databaser, måste du ge sys.columns tabellnamnet under den aktuella databasen, utan att kunna tillhandahålla en tabell som finns i en annan databas. För att uppnå det kommer vi att fråga sys.columns två gånger, spara resultatet av varje fråga i en tillfällig tabell och slutligen jämföra resultatet av dessa två frågor med kommandot EXCEPT T-SQL, som visas tydligt nedan:
USE TESTDB SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DBSchema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable') GO USE TestDB2 GO SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable '); GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Resultatet kommer att visa oss att adresskolumnens definition är olika i dessa två tabeller, utan specifik information om den exakta skillnaden, som visas nedan:

Jämför tabellschema med INFORMATION_SCHEMA.COLUMNS
Systemvyn INFORMATION_SCHEMA.COLUMNS kan också användas för att jämföra schemat för olika tabeller genom att ange tabellnamnet. Återigen, för att jämföra två tabeller som finns i olika databaser, kommer vi att fråga INFORMATION_SCHEMA.COLUMNS två gånger, behålla resultatet av varje fråga i en tillfällig tabell och slutligen jämföra resultatet av dessa två frågor med kommandot EXCEPT T-SQL, som visas tydligt nedan:
USE TestDB SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DBSchema FROM [INFORMATION_SCHEMA].[COLUMNS] SC1 WHERE SC1.TABLE_NAME='FirstComTable' GO USE TestDB2 SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DB2Schema FROM [INFORMATION_SCHEMA].[COLUMNS] SC2 WHERE SC2.TABLE_NAME='FirstComTable' GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Och resultatet kommer att på något sätt likna det föregående, vilket visar att adresskolumndefinitionen är annorlunda i dessa två tabeller, utan specifik information om den exakta skillnaden, som visas nedan:

Jämför tabellschema med dm_exec_describe_first_result_set
Tabellscheman kan också jämföras genom att fråga den dynamiska hanteringsfunktionen dm_exec_describe_first_result_set, som tar en Transact-SQL-sats som en parameter och beskriver metadata för den första resultatuppsättningen för satsen.
För att jämföra schemat för två tabeller måste du ansluta dm_exec_describe_first_result_set DMF med sig själv och tillhandahålla SELECT-satsen från varje tabell som en parameter, som i T-SQL-frågan nedan:
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name , FT.max_length , ST.max_length , FT.precision , ST.precision , FT.scale , ST.scale , FT.is_nullable , ST.is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FT LEFT OUTER JOIN sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB2.DBO.FirstComTable', NULL, 0) ST ON FT.Name =ST.Name GO
Resultatet blir tydligare den här gången, eftersom du kan jämföra skillnaden mellan de två tabellerna, det vill säga storleken och typen av adresskolumnen, som visas nedan:

Jämför tabellschema med SQL Server-dataverktyg
SQL Server Data Tools kan också användas för att jämföra schemat för tabeller som finns i olika databaser. Under Verktyg-menyn väljer du Ny schemajämförelse alternativ från SQL Server-alternativlistan, som visas nedan:
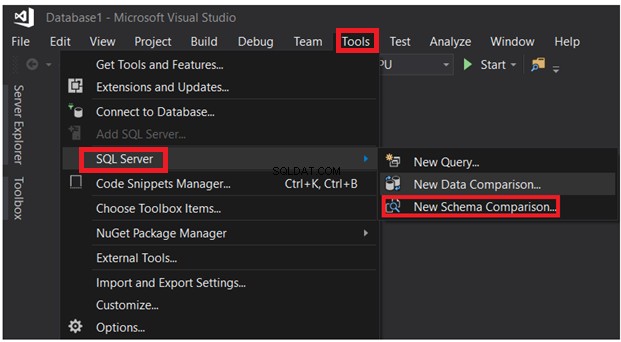
När du har angett anslutningsparametrarna klickar du på knappen Jämför:

Jämförelseresultatet kommer att visa dig, specifikt, schemaskillnaden mellan de två tabellerna i form av CREATE TABLE T-SQL-kommandon, skuggade som i ögonblicksbilden nedan:
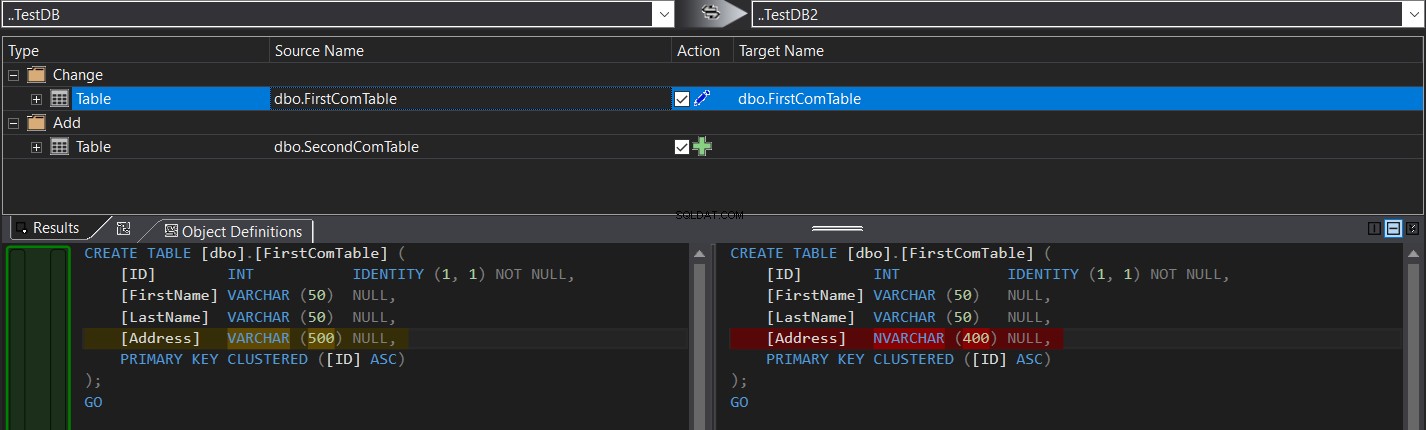
Du kan enkelt klicka  för att synkronisera tabellschemat eller klicka på
för att synkronisera tabellschemat eller klicka på  för att skripta ändringen och utföra den senare, som visas nedan:
för att skripta ändringen och utföra den senare, som visas nedan:
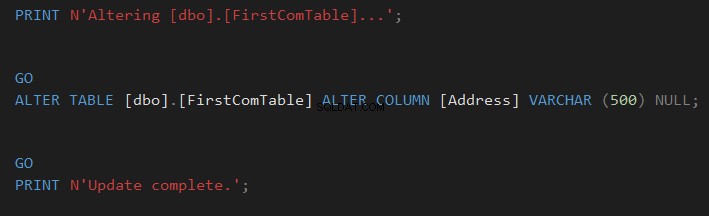
Jämför tabellschema med dbForge Studio för SQL Server tredjepartsverktyg
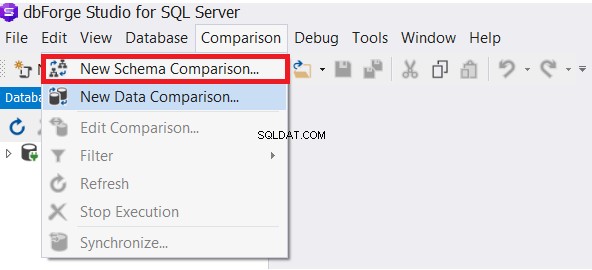
Verktyget dbForge Studio för SQL Server ger oss möjligheten att jämföra schemat för de olika databastabellerna. På menyn Jämförelse väljer duNy schemajämförelse alternativ, enligt nedan:
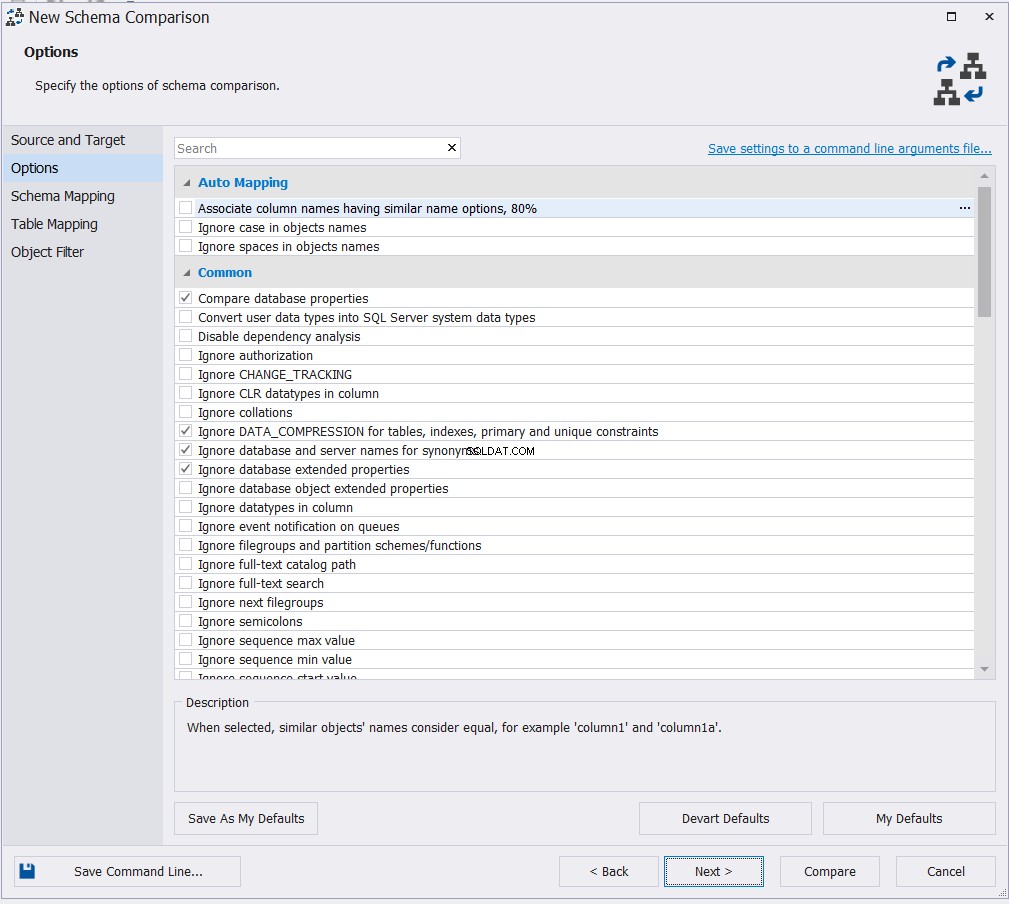
När du har angett anslutningsegenskaperna för både käll- och måldatabaserna väljer du lämpligt mappningsalternativ från de tillgängliga alternativen och klickar på Nästa :
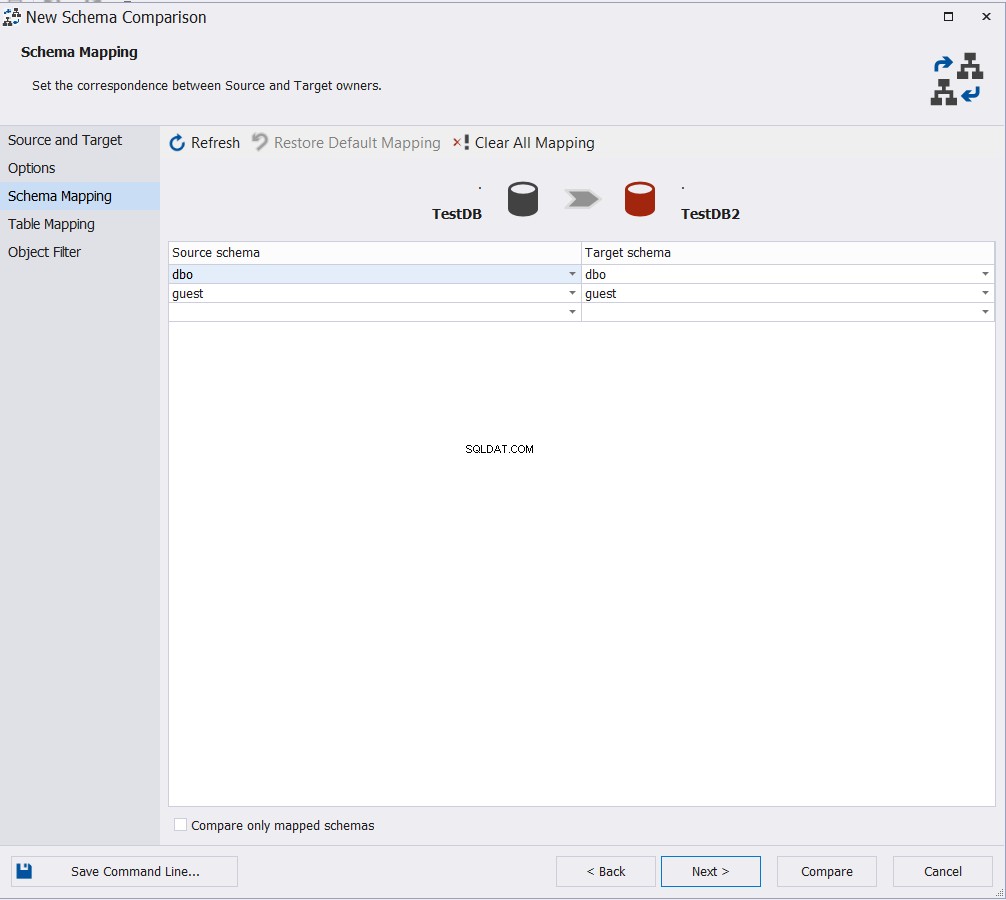
Välj de scheman som du vill jämföra dess objekt och klicka på Nästa :
Ange den eller de tabeller som ska delta i schemajämförelseprocessen och klicka på Jämför , om du vill hoppa över att ändra standardinställningarna i objektfilterfönstret, enligt nedan:
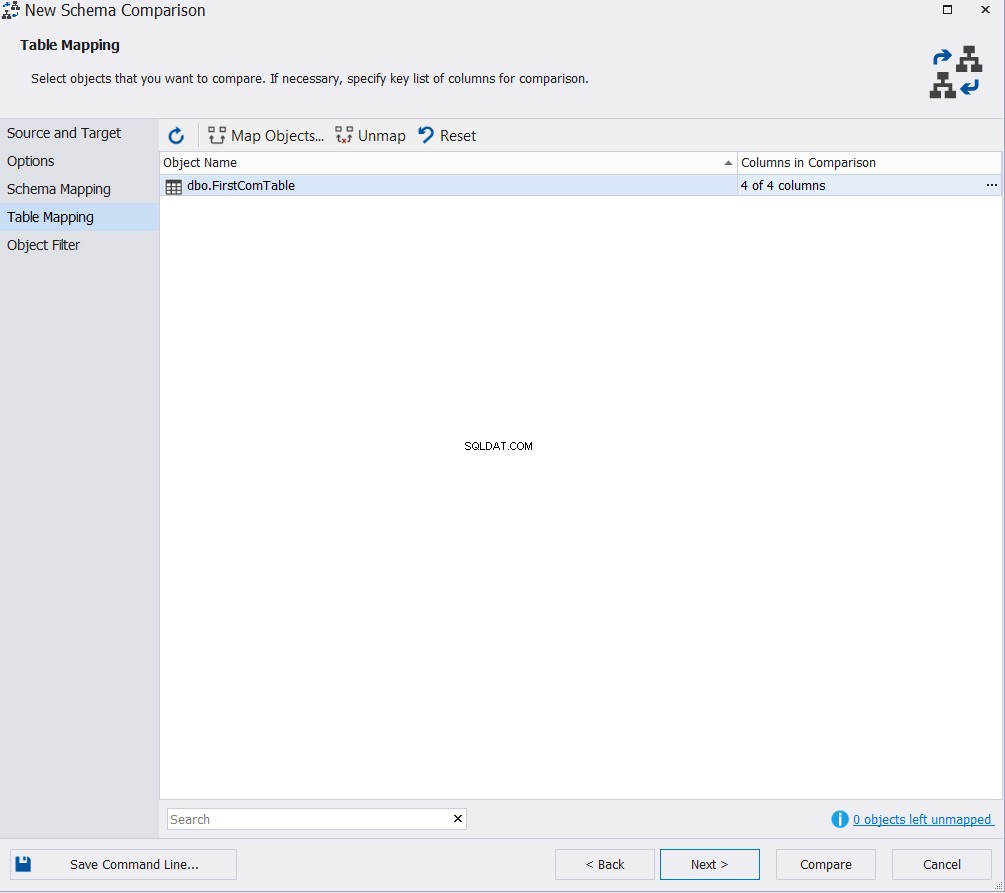
Det visade jämförelseresultatet kommer att visa dig skillnaden mellan de två tabellschemat, genom att exakt markera den del av datatypen som skiljer sig mellan de två kolumnerna, med möjligheten att specificera vilken åtgärd som ska göras för att synkronisera de två tabellerna, som visas nedan :
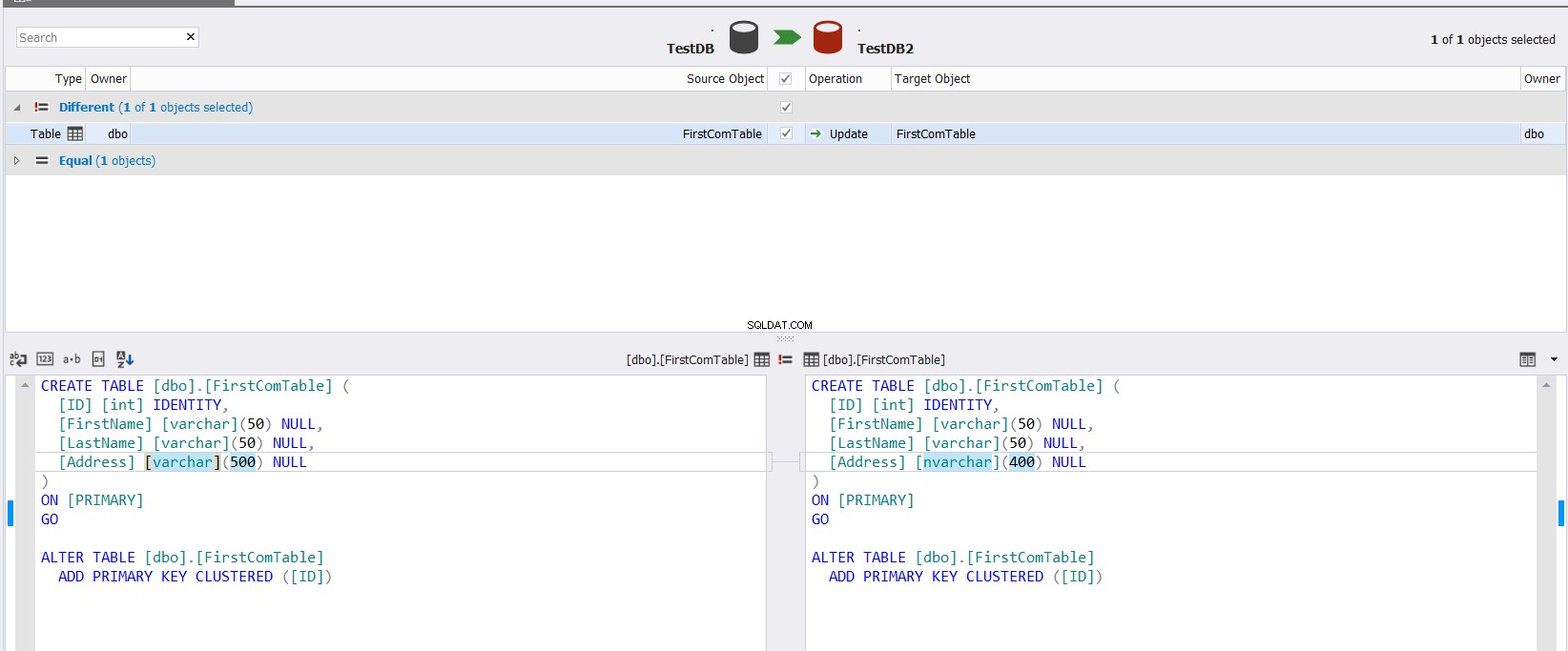
Om du ordnar att synkronisera schemat för de två tabellerna, klicka på knappen och ange i guiden Schemasynkronisering om du lyckas utföra ändringen direkt på måltabellen, eller bara skripta den för att användas i framtiden, enligt nedan:
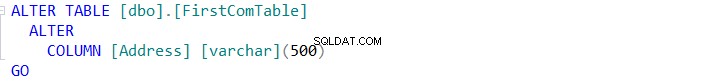
Användbara länkar:
- Ange operatörer – EXCEPT och INTERSECT (Transact-SQL)
- Ställ in operatörer – UNION (Transact-SQL)
- Ladda ner SQL Server Data Tools (SSDT)
- Jämför och synkronisera data i en eller flera tabeller med data i en referensdatabas
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Systeminformationsschemavyer (Transact-SQL)
Användbara verktyg:
dbForge Schema Compare för SQL Server – pålitligt verktyg som sparar tid och ansträngning när du jämför och synkroniserar databaser på SQL Server.
dbForge Data Compare för SQL Server – kraftfullt SQL-jämförelseverktyg som kan arbeta med big data.