Grupperad sammanlänkning är ett vanligt problem i SQL Server, utan direkta och avsiktliga funktioner som stödjer det (som XMLAGG i Oracle, STRING_AGG eller ARRAY_TO_STRING(ARRAY_AGG()) i PostgreSQL och GROUP_CONCAT i MySQL). Det har begärts, men har inte lyckats ännu, vilket framgår av dessa Connect-objekt:
- Anslut #247118:SQL behöver version av MySQL group_Concat-funktionen (uppskjuten)
- Anslut nr
** UPPDATERING januari 2017 ** :STRING_AGG() kommer att finnas i SQL Server 2017; läs om det här, här och här.
Vad är grupperad sammanlänkning?
För oinitierade är grupperad sammanlänkning när du vill ta flera rader med data och komprimera dem till en enda sträng (vanligtvis med avgränsare som kommatecken, tabbar eller mellanslag). Vissa kanske kallar detta en "horisontell sammanfogning". Ett snabbt visuellt exempel som visar hur vi skulle komprimera en lista över husdjur som tillhör varje familjemedlem, från den normaliserade källan till den "tillplattade" utdata:
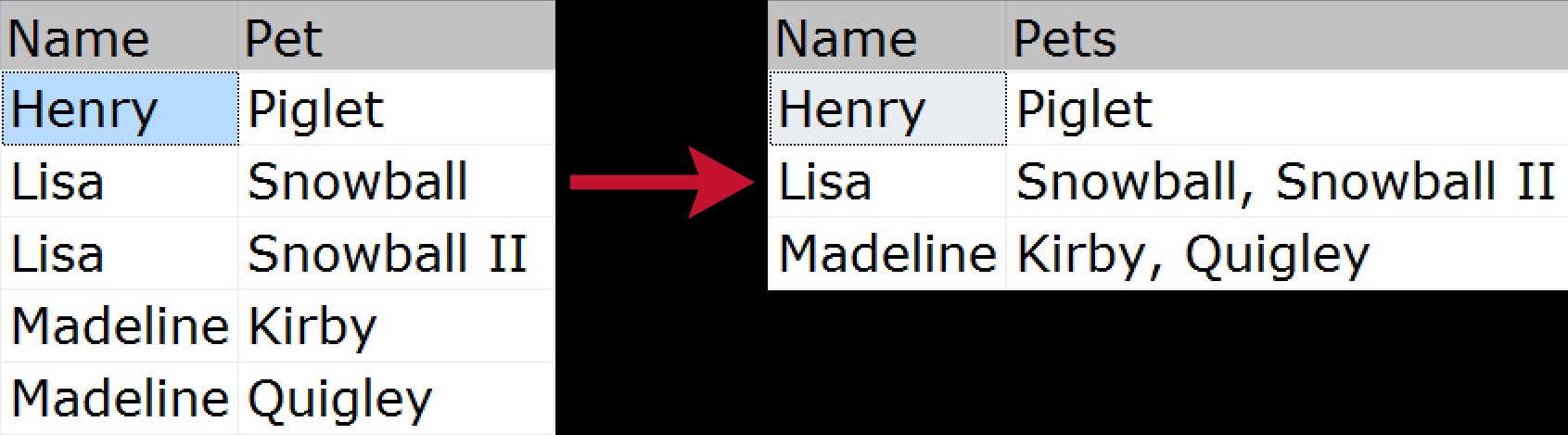
Det har funnits många sätt att lösa detta problem genom åren; här är bara några, baserat på följande exempeldata:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Jag kommer inte att visa en uttömmande lista över alla grupperade sammanlänkningsmetoder som någonsin har tänkts ut, eftersom jag vill fokusera på några aspekter av min rekommenderade metod, men jag vill peka ut några av de vanligare:
Skalär UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Obs:det finns en anledning till att vi inte gör det här:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Med DISTINCT , funktionen körs för varje enskild rad, sedan tas dubbletter bort; med GROUP BY , dubbletter tas bort först.
Common Language Runtime (CLR)
Detta använder GROUP_CONCAT_S funktion finns på https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
Rekursiv CTE
Det finns flera varianter på denna rekursion; den här drar ut en uppsättning distinkta namn som ankare:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Markör
Inte mycket att säga här; markörer är vanligtvis inte det optimala tillvägagångssättet, men detta kan vara ditt enda val om du har fastnat på SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Konstig uppdatering
Vissa människor *älskar* detta tillvägagångssätt; Jag förstår inte alls attraktionen.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; FÖR XML-SÖG
Ganska enkelt min föredragna metod, åtminstone delvis eftersom det är det enda sättet att *garantera* beställning utan att använda en markör eller CLR. Som sagt, det här är en väldigt rå version som inte klarar av ett par andra inneboende problem som jag kommer att diskutera vidare om:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Jag har sett många människor felaktigt anta att den nya CONCAT() funktion som introducerades i SQL Server 2012 var svaret på dessa funktionsförfrågningar. Den funktionen är endast avsedd att fungera mot kolumner eller variabler i en enda rad; den kan inte användas för att sammanfoga värden över rader.
Mer om FOR XML PATH
FOR XML PATH('') i sig är inte tillräckligt bra – det har kända problem med XML-berättigande. Om du till exempel uppdaterar ett av husdjursnamnen till att inkludera en HTML-parentes eller et-tecken:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Dessa översätts till XML-säkra enheter någonstans längs vägen:
Qui>gle&y
Så jag använder alltid PATH, TYPE).value() , enligt följande:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Jag använder också alltid NVARCHAR , eftersom du aldrig vet när någon underliggande kolumn kommer att innehålla Unicode (eller senare ändras för att göra det).
Du kan se följande varianter inuti .value() , eller till och med andra:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Dessa är utbytbara, alla representerar i slutändan samma sträng; prestationsskillnaderna mellan dem (mer nedan) var försumbara och möjligen helt obestämda.
Ett annat problem du kan stöta på är vissa ASCII-tecken som inte är möjliga att representera i XML; till exempel om strängen innehåller tecknet 0x001A (CHAR(26) ), får du detta felmeddelande:
FOR XML kunde inte serialisera data för noden 'NoName' eftersom den innehåller ett tecken (0x001A) som inte är tillåtet i XML. För att hämta denna data med FOR XML, konvertera den till binär, varbinär eller bilddatatyp och använd BINARY BASE64-direktivet.
Det här verkar ganska komplicerat för mig, men förhoppningsvis behöver du inte oroa dig för det eftersom du inte lagrar data som denna eller åtminstone inte försöker använda den i grupperad sammanlänkning. Om du är det kan du behöva falla tillbaka till en av de andra metoderna.
Prestanda
Ovanstående exempeldata gör det enkelt att bevisa att dessa metoder alla gör vad vi förväntar oss, men det är svårt att jämföra dem på ett meningsfullt sätt. Så jag fyllde tabellen med en mycket större uppsättning:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
För mig var detta 575 objekt, med totalt 7 080 rader; det bredaste föremålet hade 142 kolumner. Nu igen, visserligen, jag ville inte jämföra varje enskilt tillvägagångssätt som uttänks i historien om SQL Server; bara de få höjdpunkterna jag postade ovan. Här var resultaten:
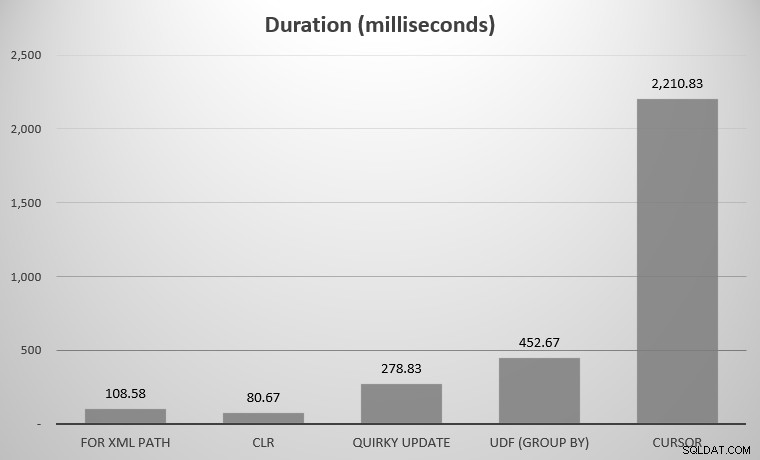
Du kanske märker att ett par utmanare saknas; UDF med DISTINCT och den rekursiva CTE var så utanför listorna att de skulle skeva skalan. Här är resultaten av alla sju tillvägagångssätten i tabellform:
| Tillvägagångssätt | Längd (millisekunder) |
|---|---|
| FÖR XML PATH | 108.58 |
| CLR | 80.67 |
| Konstig uppdatering | 278,83 |
| UDF (GROUP BY) | 452.67 |
| UDF (DISTINCT) | 5 893,67 |
| Markör | 2 210,83 |
| Rekursiv CTE | 70 240,58 |
Genomsnittlig varaktighet, i millisekunder, för alla tillvägagångssätt
Observera också att varianterna av FOR XML PATH testades oberoende men visade mycket små skillnader så jag kombinerade dem bara för genomsnittet. Om du verkligen vill veta, .[1] notation fungerade snabbast i mina tester; YMMV.
Slutsats
Om du inte är i en butik där CLR är en vägspärr på något sätt, och särskilt om du inte bara har att göra med enkla namn eller andra strängar, bör du definitivt överväga CodePlex-projektet. Försök inte uppfinna hjulet igen, försök inte ointuitiva trick och hacks för att CROSS APPLY eller andra konstruktioner fungerar bara lite snabbare än icke-CLR-metoderna ovan. Ta bara det som fungerar och koppla in det. Och fan, eftersom du får källkoden också kan du förbättra den eller utöka den om du vill.
Om CLR är ett problem, FOR XML PATH är förmodligen ditt bästa alternativ, men du måste fortfarande se upp för knepiga karaktärer. Om du har fastnat på SQL Server 2000 är ditt enda möjliga alternativ UDF (eller liknande kod som inte är inslagen i en UDF).
Nästa gång
Ett par saker jag vill utforska i ett uppföljande inlägg:att ta bort dubbletter från listan, ordna listan efter något annat än själva värdet, fall där det kan vara smärtsamt att lägga in någon av dessa metoder i en UDF, och praktiska användningsfall för den här funktionen.