
I en tidigare artikel undersökte vi SQL Server-indexkrav och prestandaöverväganden. När det kommer till databasprestanda är prestandajustering utan tvekan en av de viktigaste och mest komplexa funktionerna. Den består av många olika områden som SQL-frågeoptimering, indexjustering och systemresursjustering, som alla måste utföras korrekt för att snabbt kunna hämta data.
Det finns flera viktiga områden att tänka på när det kommer till SQL Server-index, eftersom de kan ha en betydande inverkan på både din prestandajustering och den övergripande databasprestanda. Nedan finns några detaljer om var och en och de viktiga roller de spelar.
Bästa praxis för SQL Server-index
1. Förstå hur databasdesign påverkar SQL Server-index
Indexeringskraven varierar mellan online-transaktionsbehandling (OLTP) och online analytical processing (OLAP)-databaser.
I en OLTP-databas utför användare ofta läs-skrivoperationer, infogar nya data och modifierar befintliga data. De använder språkfrågor för datamanipulation (Infoga, Uppdatera, Delete) tillsammans med Select-satser för datahämtning och modifieringar. För OLTP-databaser är det bäst att skapa index i den valda kolumnen i en tabell. Flera index kan ha en negativ inverkan på prestanda och stressa systemresurserna. Istället rekommenderas det att skapa det minsta antalet index som kan uppfylla dina indexeringskrav. I OLAP-databaser å andra sidan använder du mest Select-satser för att hämta data för ytterligare analytiska ändamål. I det här fallet kan du lägga till fler index med flera nyckelkolumner per index. Du kan också utnyttja kolumnlagerindex för snabbare datahämtning i datalagerfrågor
2. Skapa index för dina krav på arbetsbelastning
När du skapar en ny tabell i din databas, lägg inte bara till index blint. Ibland lägger utvecklare ett klustrade index och några icke-klustrade index på det utan att leta efter frågorna som använder dessa index. Det kan finnas ett index som inte uppfyller kravet på frågeoptimeraren; därför bör du korrekt analysera din arbetsbelastning och SQL-frågor (lagrade procedurer, funktioner, vyer och ad-hoc-frågor). Du kan fånga arbetsbelastningen med SQL-profiler, utökade händelser och dynamiska hanteringsvyer och sedan skapa index för att optimera resurskrävande frågor.
3. Skapa index för de mest använda och mest använda frågorna
Det är viktigt att gruppera arbetsbelastningar för de mest använda frågorna i ditt system. Genom att skapa de bästa indexen för dessa frågor kommer det att belasta ditt system så lite som möjligt.
4. Tillämpa bästa praxis för SQL Server-indexnyckelkolumnen
Eftersom du kan ha flera kolumner i en tabell följer här några överväganden för indexnyckelkolumner.
- Kolumner med text, bild, ntext, varchar(max), nvarchar(max) och varbinary(max) kan inte användas i indexnyckelkolumnerna.
- Det rekommenderas att använda en heltalsdatatyp i indexnyckelkolumnen. Den har ett lågt utrymmesbehov och fungerar effektivt. På grund av detta vill du skapa den primära nyckelkolumnen, vanligtvis på en heltalsdatatyp.
- Du kan bara använda XML-datatyp i ett XML-index.
- Du bör överväga att skapa en primärnyckel för kolumnen med unika värden. Om en tabell inte har några unika värdekolumner kan du definiera en identitetskolumn för en heltalsdatatyp. En primärnyckel skapar också ett klustrat index för radfördelningen.
- Du kan betrakta en kolumn med värdena Unique och Not NULL som en användbar indexnyckelkandidat.
- Du bör bygga ett index baserat på predikaten i Where-satsen. Du kan till exempel överväga kolumner som används i Where-satsen, SQL ansluter, som, sortera efter, gruppera efter predikat och så vidare.
- Du bör sammanfoga tabeller på ett sätt som minskar antalet rader för resten av frågan. Detta hjälper frågeoptimeraren att förbereda exekveringsplanen med minimala systemresurser.
- Om du använder flera kolumner för en indexnyckel är det också viktigt att överväga deras placering i indexnyckeln.
- Du bör också överväga att använda inkluderade kolumner i dina index.
5. Analysera datafördelningen för dina SQL Server-indexkolumner
Du bör undersöka datadistributionen i SQL Server-indexnyckelkolumnerna. En kolumn med icke-unika värden kan orsaka en fördröjning vid hämtning av data och resultera i en långvarig transaktion. Du kan analysera datadistribution med hjälp av histogrammet i statistik.
6. Använd datasorteringsordning
Du bör också överväga datasorteringskraven i dina frågor och index. Som standard sorterar SQL Server data i stigande ordning i ett index. Anta att du skapar ett index i stigande ordning, men dina frågor använder Order By-satsen för att sortera data i fallande ordning.
Titta till exempel på den faktiska exekveringsplanen för följande fråga.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
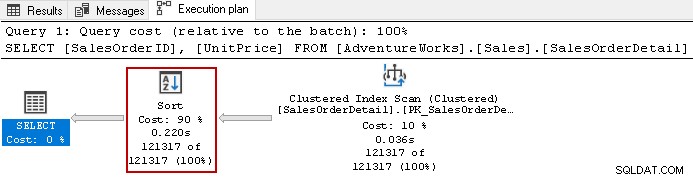
Den använder den kostsamma sorteringsoperatören med en total kostnad på 90 % i denna fråga. Vi bestämde oss för att bygga ett icke-klustrat index på [UnitPrice] och [SalesOrderID]. Den använder en standardsorteringsordning för båda kolumnerna i indexet.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Vi körde om Select-satsen och frågeoptimeraren använder fortfarande sorteringsoperatorn. Den kan använda det icke-klustrade indexet men sorterar data för att förbereda resultatet.
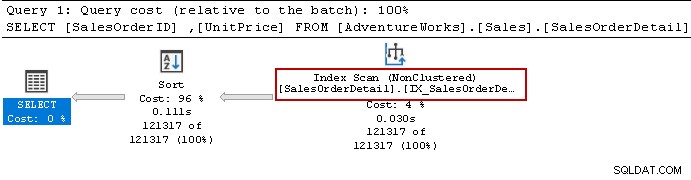
Låt oss återskapa indexet med hjälp av följande fråga. Den här gången sorterar den data i fallande ordning för [Enhetspris] i indexdefinitionen.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
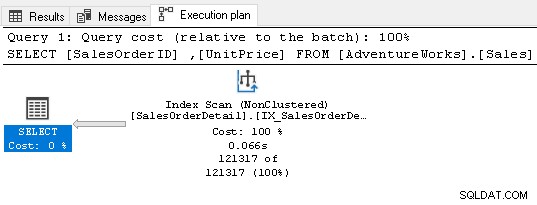
Det kräver ingen sortsoperator nu eftersom indexet uppfyller frågekraven.
7. Använd främmande nycklar för ditt SQL Server-index
Du bör skapa ett index på kolumnerna för främmande nycklar. Det är tillrådligt att skapa ett klustrat index på den främmande nyckeln för att förbättra frågeprestanda.
8. Var uppmärksam på SQL Server-indexlagringsöverväganden
Indexlagring är också en användbar aspekt att tänka på. SQL Server skapar alla index på samma filgrupp i tabellen. Du kan överväga en separat filgrupp för index och separera den fysiska filen på en separat disk. Detta kommer att öka IO-prestanda och genomströmning.
På samma sätt kan du använda tabellpartitionering för att segregera data över flera diskar och filgrupper. Du kan designa partitionerade index för dessa tabellpartitioner för att förbättra samtidig dataåtkomst.
Ett annat alternativ är att definiera FILLFACTOR när du skapar eller bygger om ett index. En FILLFACTOR definierar det lediga utrymmet på bladnodens datasidor. Det är användbart för ytterligare infogning av data. Om din data är statisk och inte ändras ofta, kan du överväga ett högt värde på FILLFACTOR. Å andra sidan, för data som ändras ofta, kan du lämna tillräckligt med utrymme för nya datainfogningar.
9. Hitta saknade index
Ibland får du information om ett saknat SQL Server-index i frågeexekveringsplanen. Du kan också köra de dynamiska hanteringsvyerna för att hitta dessa saknade index. Du bör inte blint skapa dessa index. Det är bara ett förslag på frågeoptimerare, men det tar inte hänsyn till det befintliga indexet eller dina arbetsbelastningskrav. Det kan också inkludera flera kolumner i indexdefinitionen, så granska dessa förslag innan du implementerar det.
10. Skapa alltid ett klustrat index före ett icke-klustrat index
Som en allmän riktlinje bör du skapa ett klustrat index innan du bygger icke-klustrade index. Om en tabell inte har ett index, består ett icke-klustrat index av radidentifierare. När du väl har skapat ett klustrade index måste SQL Server bygga om dessa icke-klustrade index så att de kan peka på den klustrade indexnyckeln istället för radidentifierarna.
11. Övervaka indexunderhåll och uppdatera statistik
Nedan finns flera underhållsområden att övervaka när det kommer till SQL Server-index.
- Ta bort indexfragmentering :Du bör regelbundet granska interna och externa fragmentering, särskilt för de höga transaktionstabellerna. Dina frågor kan svara långsamt även om du har korrekta index för dina arbetsbelastningar. Ett kraftigt fragmenterat index kan försämra prestandan eftersom det kräver ytterligare IO. Du kan utföra en omorganisering eller bygga om ett index baserat på dess fragmenteringsvärden. Vanligtvis bör du bygga om indexet om det har en fragmentering som är större än 30 % och omorganisera det om det har mindre än 30 % fragmentering.
- Ta bort oanvända index: Du bör alltid granska de oanvända (lediga) indexen i din databas eftersom frågeoptimeraren måste ta hänsyn till dem för varje fråga. Ett oanvänt index förbrukar också lagring och ökar underhållskostnaderna.
- Uppdatera statistik: Du bör uppdatera statistiken regelbundet även om du har ställt in statistiken för automatisk uppdatering i din databaskonfiguration. Frågeoptimeraren kan förbereda en dålig exekveringsplan om indexstatistiken inte uppdateras. Du kan schemalägga ett agentjobb för att uppdatera SQL Server-statistik med en fullständig genomsökning efter kontorstid.
Du kan hänvisa till SQL-indexunderhåll för ytterligare insikter om detta ämne.
Tillämpa bästa praxis för SQL Server-index
Även om det inte alltid finns ett enkelt sätt att designa ett optimalt SQL Server-index, kommer att tillämpa rekommendationerna som anges i det här inlägget hjälpa dig att navigera i de olika indexeringskraven du kommer att stöta på med varje databastyp och dess arbetsbelastning. Dessa bästa metoder hjälper dig att optimera dina index för att förbättra databasprestanda och säkerställa en smidigare prestandajustering under vägen.