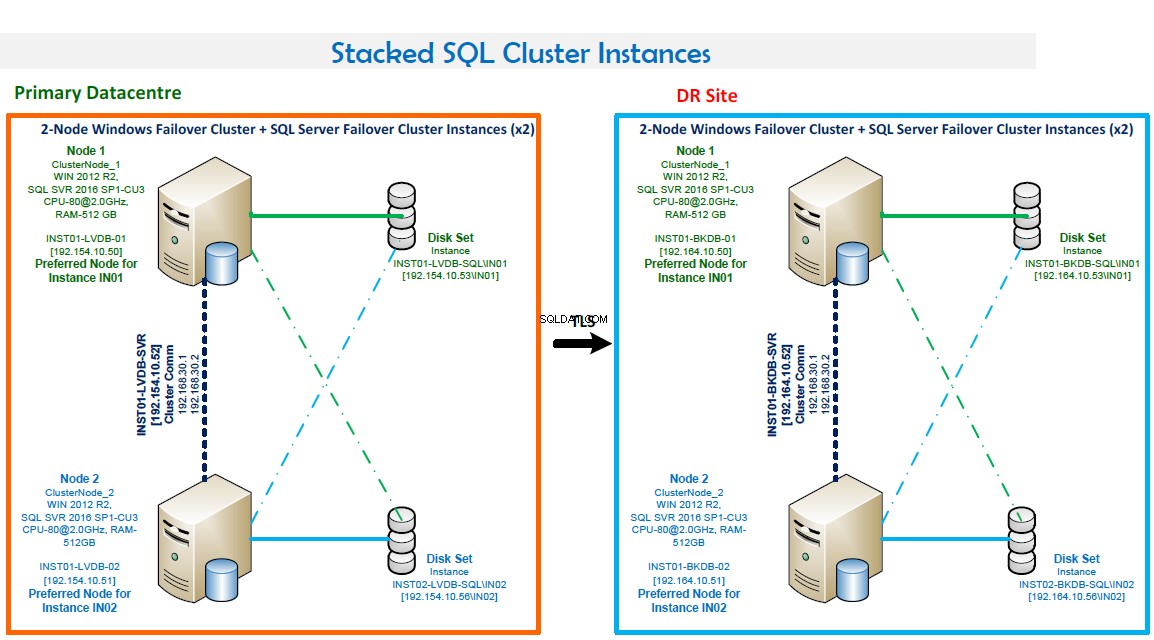
ANMÄRKNINGAR:
- Windows Failover-kluster som består av två noder.
- Två SQL Server Failover-klusterinstanser. Denna konfiguration optimerar hårdvaran. IN01 är att föredra på Nod1 och IN02 är att föredra på Nod2.
- Portnummer:IN01 lyssnar på port 1435 och IN02 lyssnar på port 1436.
- Hög tillgänglighet. Båda noderna backar upp varandra. Failover är automatiskt vid fel.
- Kvorumläge är Nod- och Diskmajoritet.
- Säkerhetskopiera LAN på plats och rutinmässig säkerhetskopiering konfigurerad med Veritas
Introduktion
Det är inte ovanligt att utvecklare och projektledare kräver en ny instans av SQL Server för varje ny applikation eller tjänst. Medan teknologier som virtualisering och moln har gjort det enkelt att skapa nya instanser, gör vissa urgamla tekniker inbyggda i SQL Server det möjligt att uppnå låga omloppstider när det finns behov av att tillhandahålla en ny databas för en ny tjänst eller applikation. Detta tillstånd kan skapas av en DBA som kan designa och distribuera ett stort SQL Server-kluster som kan stödja de flesta SQL Server-databaser som krävs av organisationen. Det finns ytterligare fördelar med denna typ av konsolidering såsom lägre licenskostnader, bättre styrning och enkel administration. I artikeln kommer vi att lyfta fram några överväganden som vi har haft möjlighet att uppleva när vi använder klustring och stapling som ett sätt att konsolidera SQL Server-databaser.
Klustring
Windows Server Failover Clustering är en mycket välkänd High Availability Solution som har överlevt många versioner av Windows Server och som Microsoft avser att fortsätta investera i och förbättra. SQL Server Failover Cluster-instanser förlitar sig på WSFC. Både Standard och Enterprise Editions av SQL Server stöder SQL Server Failover Cluster Instances men Standard Edition är begränsad till endast två noder. Att konsolidera databaser på en enda SQL Server FCI ger fördelarna som:
- HA som standard — Alla databaser som distribueras på en klustrad SQL Server-instans är högst tillgängliga som standard! När en klustrad instans väl har byggts tas nya distributioner om hand vad gäller HA i förväg.
- Enkel administration – Färre DBA:er kan lägga tid på att konfigurera, övervaka och vid behov felsöka EN klustrad instans som stöder många applikationer. Korrekt, dokumentering av instansen görs också mycket enklare när man har att göra med en stor miljö. Att konfigurera en Enterprise Backup-lösning för att hantera alla databaser i din miljö underlättas av att du bara behöver göra den här konfigurationen en när du använder konsoliderade instanser.
- Efterlevnad – Sådana nyckelkrav som patchning och till och med härdning kan göras en gång med minimal stilleståndstid på ett stort antal databaser i en enda administrativ ansträngning. I vår butik har vi använt Transaction Log Shipping mellan klustrade instanser vid två datacenter för att säkerställa att databaser är skyddade från risken för katastrofer.
- Standardisering – Att upprätthålla sådana standarder som namnkonventioner, åtkomsthantering, Windows-autentisering, revision och policybaserad hantering är mycket enklare när man arbetar med bara en eller två miljöer beroende på storleken på din butik
Anteckning 1: Extrahera information om din instans
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Stackning
SQL Server stöder upp till femtio enstaka instanser på en server och upp till 25 Failover Cluster Instances på ett Windows Server Failover Cluster. Olika versioner av SQL Server kan staplas på samma miljö för att ge en robust miljö som stöder olika applikationer. I en sådan konfiguration kan uppgradering av databaser ta formen av att helt enkelt marknadsföra dem från en SQL Server-instans till nästa version i samma kluster tills hårdvaran åldras. En viktig faktor att ha i åtanke när du staplar SQL Server är att du måste allokera minne till varje instans på ett sådant sätt att den totala mängden minne som allokeras inte överstiger det tillgängliga minnet i operativsystemet. Den andra punkten i den här riktningen är att säkerställa att SQL Server-tjänstkontot för varje instans måste ha minnesrättigheterna för låssidorna. Att tilldela låssidor i minnet säkerställer att när SQL Server skaffar minne, försöker operativsystemet inte återställa sådant minne när andra processer på servern behöver minne. Att konfigurera ett definierat SQL Server-tjänstkonto, konfigurera MAX_SERVER_MEMORY och att låsa sidor i minnet är en viktig trio när du staplar SQL Server-instanser.
Microsoft tar ut några tusen dollar per par CPU-kärnor. Genom att stapla SQL Server-instanser kan du dra nytta av den här licensmodellen genom att låta instanser dela samma uppsättning processorer (som svettas av tillgången). Vi har redan nämnt att du kan stapla olika versioner av SQL Server och därmed ta hand om äldre applikationer som fortfarande kör versioner äldre än SQL Server 2016 till exempel. När du använder olika versioner av SQL Server kan du överväga att använda Processor Affinity som beskrivs av Glen Berry i den här artikeln. Processor Affinity kan också användas för att styra hur CPU-resurser delas mellan instanser precis som du kontrollerar minnet. Stacking tar också upp säkerhetsproblem för applikationer som måste använda SA-kontot till exempel eller konfigurationsproblem för applikationer som kräver en dedikerad instans, eller sådana alternativ är en specifik kollation. Oro för prestandan för den delade TempDB är en annan anledning till att du kanske vill stapla istället för att samla alla databaser på en klustrad instans.
Det är värt att notera att värdet av klustring som belysts tidigare sträcker sig ännu längre med stapling. Till exempel, när du patchar en SQL Server-instans med flera FCI:er kan alla FCI:er korrigeras på en gång.
Pekar på notering
När du använder klustring kommer vissa konventioner att göra administration och hantering av miljön lite lättare och svettas tillgångarna bättre. Vi ska kort beröra några av dem:
- Aktuella klientverktyg — Du kan upptäcka att du får ovanliga fel när du försöker hantera en SQL Server 2016-instans med SQL Server Management Studio 2012. Felen talar inte specifikt om för dig att problemet är klientverktygets version. Vi har vanligtvis SQL Server Management Studio 17.3-instans på klienten som vi vill använda för att ansluta till våra instanser.
- Namnkonventioner — En namnkonvention gör det enkelt för dig att vara säker på vilken instans du arbetar med när som helst. Genom att använda alias kan du ytterligare minska bördan av att komma ihåg långa instansnamn på slutanvändare som behöver åtkomst till databasen.
- Önskad nod – Att ställa in en föredragen nod för varje SQL Server-roll i Failover Cluster Manager är en bra idé, ett bra sätt att se till att processorkraften för alla dina klusternoder utnyttjas. I vår butik, efter att ha ställt in föredragna noder, konfigurerade vi rollen att misslyckas mellan 0500 HRS och 0600 HRS om det skulle inträffa en oavsiktlig failover.
- Transaktionsloggsändning – När du konfigurerar Disaster Recovery för FCI:er är det vettigt att identifiera alla UNC-sökvägar med hjälp av virtuella namn, inte namnen eller IP-adressen för klusternoderna. Detta säkerställer att saker och ting fortsätter att fungera korrekt om en failover inträffar. Det är också mycket viktigt att se till att SQL Server Agent-kontona på båda platserna har full kontroll över dessa vägar.
Anteckning 2: Konfigurera övervakning för transaktionsloggsändning med e-post
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Diskenheter
En bieffekt av att stapla SQL Server-instanser och tillhandahålla flera databaser är tendensen att få slut på enhetsbokstäver. Vi kringgick detta problem genom att konfigurera volymmonteringspunkter. Varje disk som tilldelats en klusterroll är konfigurerad som en monteringspunkt med en enhetsbeteckning som endast behövs för en eller två enheter per instans. En viktig punkt att notera när du använder volymmonteringspunkter på ett kluster är att i framtiden när du behöver lägga till fler monteringspunkter för att utföra liknande underhållsuppgifter, kommer det att vara nödvändigt att sätta BÅDE den primära enheten som äger enhetsbeteckningen och monteringen punkt i underhållsläge på klustret.
I vårt fall hittade vi namnet på varje volymmonteringspunkt baserat på den klusterroll som den tilldelades. Med så många enheter att hantera skulle du definitivt behöva utarbeta ett sätt för både dig och lagringsadministratören att identifiera en unik disk så att det till exempel inte skulle vara mycket krångel att hålla diskarna på lagringsnivå.
Anteckning 3: Övervaka användningen av diskutrymme när du använder volymmonteringspunkter
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Databasdistribution
I vårt fall var vår strategi att se till att nya databaser följde vår standard. Äldre databaser hanterades med lite mer försiktighet eftersom vi liksom konsoliderade och uppgraderade samtidigt. Database Migration Assistant hjälpte till att berätta för oss vilka databaser som definitivt inte skulle vara kompatibla med vår heliga SQL Server 2016-instans och vi lämnade dem i fred (vissa med kompatibilitetsnivåer är så låga som 100). Varje distribuerad databas bör ha sina egna volymer för data och loggfiler beroende på dess storlek. Att använda separata volymer för varje databas är ytterligare ett steg mot att ha en mycket välorganiserad miljö, vilket är viktigt med tanke på den potentiella komplexiteten i denna konsoliderade miljö. Det sista uttalandet innebär också att när du tillåter ett program att skapa sina egna databaser måste du som DBA flytta datafilerna efter att distributionen är klar eftersom programmet kommer att använda samma filplatser som används av modelldatabasen.
Anteckning 4: Flytta användardatabaser
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Åtkomsthantering
Du kommer att hålla med om att vi i vår konsoliderade miljö skulle kunna ha en mycket lång lista med objekt på servernivå som inloggningar. Användning av Windows-grupper hjälper till att förkorta den här listan och förenkla åtkomsthanteringen för varje klustrad instans. Vanligtvis behöver du grupper skapade på Active Directory för applikationsadministratörer som behöver åtkomst, applikationstjänstkonton, företagsanvändare som behöver dra rapporter och naturligtvis databasadministratörer. En viktig fördel med att använda Windows-grupper är att åtkomst kan beviljas eller återkallas helt enkelt genom att hantera medlemskapet i dessa grupper direkt i Active Directory.
Det är förmodligen uppenbart vid det här laget att denna fördel inom området för åtkomsthantering endast är möjlig med Windows-autentisering. SQL Server-inloggningar kan inte hanteras i grupper.
Anteckning 5: Inkomstinloggningar, databasanvändare och deras roller
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Slutsats
Vi har på en mycket hög nivå undersökt de fördelar som kan uppnås genom att klustra och stapla SQL Server-instanser som ett sätt att uppnå konsolidering, kostnadsoptimering och enkel hantering. Om du finner dig själv kapabel att köpa stor hårdvara kan du utforska det här alternativet och dra nytta av fördelarna som vi har beskrivit ovan.