Att säkerställa en smidig drift av dina produktionsdatabaser är inte en trivial uppgift, och det finns ett antal verktyg och verktyg som hjälper dig med jobbet. Det finns verktyg tillgängliga för övervakning av hälsa, serverprestanda, analys av frågor, distributioner, hantering av failover, uppgraderingar och listan fortsätter. ClusterControl som en hanterings- och övervakningsplattform för din databasinfrastruktur utmärker sig med sin förmåga att hantera hela livscykeln från driftsättning till övervakning, löpande hantering och skalning.
Även om ClusterControl erbjuder viktiga funktioner som automatisk databas-failover, kryptering under transport/i vila, backuphantering, punkt-i-tid återställning, Prometheus-integration, databasskalning, kan dessa hittas i andra företagshanterings-/övervakningsverktyg på marknaden. Det finns dock vissa funktioner som du inte hittar så lätt. I det här blogginlägget kommer vi att presentera 9 funktioner som du inte hittar i några andra hanterings- och övervakningsverktyg på marknaden (när detta skrivs).
Verifiering av säkerhetskopiering
Alla säkerhetskopior är bokstavligen inte en säkerhetskopia förrän du vet att den kan återställas - genom att verkligen verifiera att den kan återställas. ClusterControl låter en säkerhetskopia verifieras efter att säkerhetskopian har tagits genom att snurra en ny server och testa återställning. Att verifiera en säkerhetskopia är en kritisk process för att se till att du uppfyller din policy för återställningspunktsmål (RPO) i händelse av en katastrofåterställning. Verifieringsprocessen kommer att utföra återställningen på en ny fristående värd (där ClusterControl kommer att installera nödvändiga databaspaket innan återställning) eller på en server som är dedikerad för säkerhetskopiering.
För att konfigurera säkerhetskopiering, välj helt enkelt en befintlig säkerhetskopia och klicka på Återställ. Det kommer att finnas ett alternativ att återställa och verifiera:
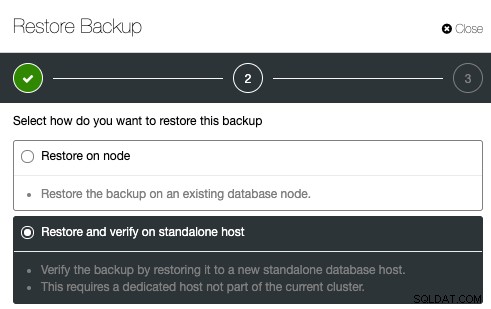
Ange sedan helt enkelt IP-adressen för den server som du vill återställa och verifiera:
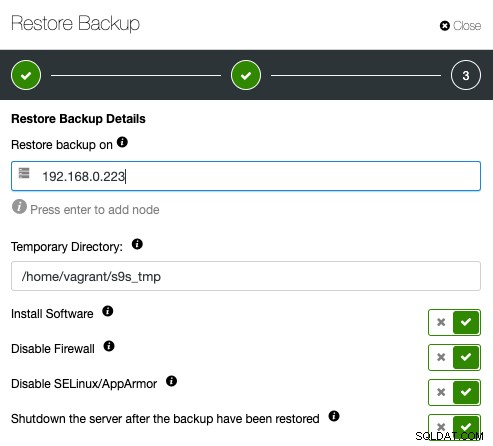
Se till att den angivna värden är tillgänglig via lösenordslös SSH i förväg. Du har också en handfull alternativ under för provisioneringsprocessen. Du kan också stänga av verifieringsservern efter återställning för att spara kostnader och resurser efter att säkerhetskopian har verifierats. ClusterControl kommer att leta efter utgångskoden för återställningsprocessen och observera återställningsloggen för att kontrollera om verifieringen misslyckas eller lyckas.
Förenkla ProxySQL-hanteringen genom ett GUI
Många håller med om att ett grafiskt användargränssnitt är effektivare och mindre benäget att göra mänskliga fel när man konfigurerar ett system. ProxySQL är en del av det kritiska databaslagret (även om det sitter ovanpå det) och måste vara tillräckligt synligt för DBA:s ögon för att upptäcka vanliga problem och problem. ClusterControl tillhandahåller ett omfattande grafiskt användargränssnitt för ProxySQL.
ProxySQL-instanser kan distribueras på nya värdar, eller befintliga kan importeras till ClusterControl. ClusterControl kan konfigurera ProxySQL för att integreras med en virtuell IP-adress (tillhandahålls av Keepalved) för åtkomst till en enda slutpunkt till databasservrarna. Det ger också övervakningsinsikt till de viktigaste ProxySQL-komponenterna som Queries Backend, Slow Queries, Top Queries, Query Hits och en massa annan övervakningsstatistik. Följande är en skärmdump som visar hur man lägger till en ny frågeregel:
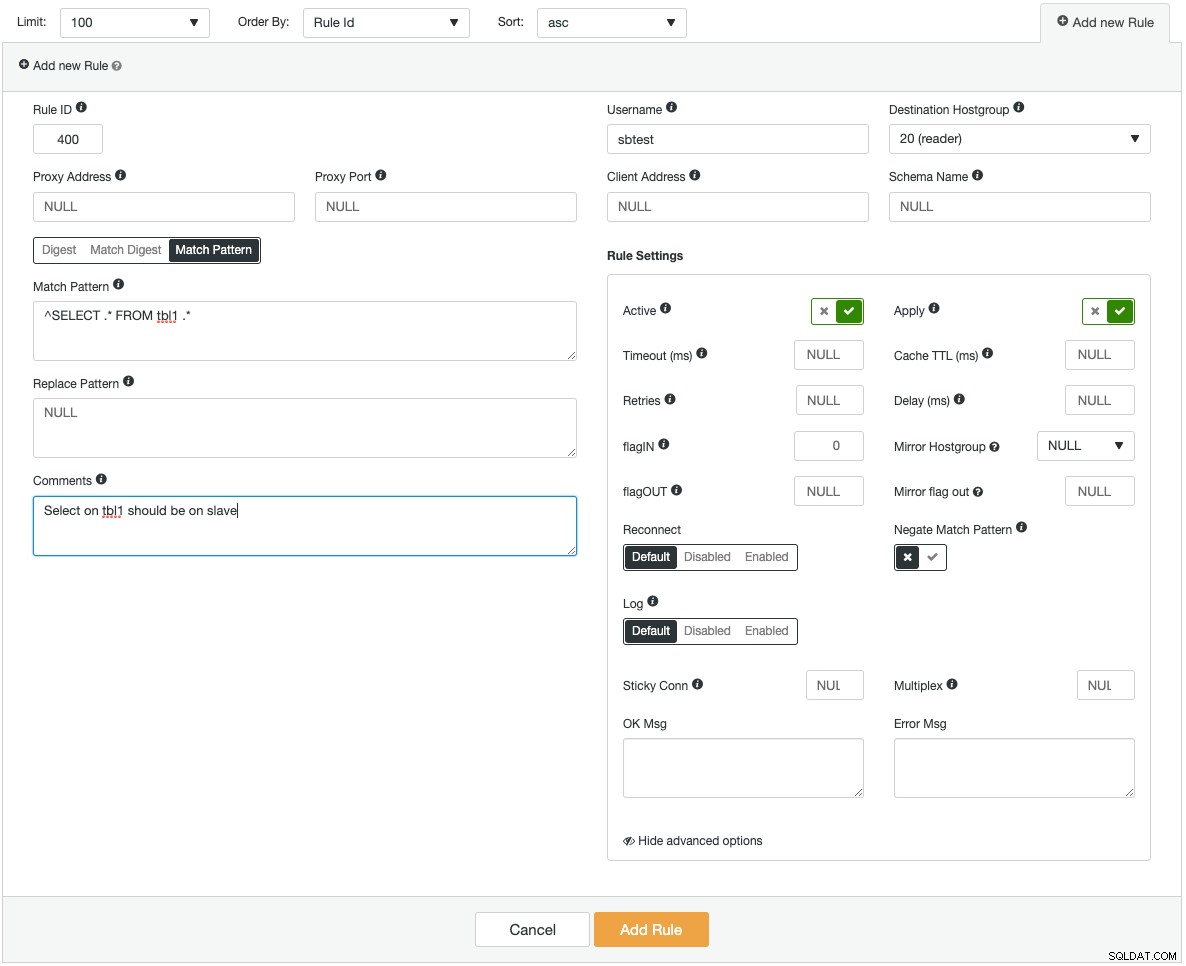
Om du lade till en mycket komplex frågeregel skulle du vara mer bekväm att göra det via det grafiska användargränssnittet. Varje fält har ett verktygstips som hjälper dig när du fyller i frågeregelformuläret. När du lägger till eller modifierar någon ProxySQL-konfiguration, kommer ClusterControl att se till att ändringarna görs i runtime och sparas på disken för beständighet.
ClusterControl 1.7.4 stöder nu både ProxySQL 1.x och ProxySQL 2.x.
Driftsrapporter
Driftsrapporter är en uppsättning sammanfattande rapporter om din databasinfrastruktur som kan genereras direkt eller kan schemaläggas för att skickas till olika mottagare. Dessa rapporter består av olika kontroller och tar upp olika dagliga DBA-uppgifter. Tanken bakom ClusterControls verksamhetsrapportering är att lägga all den mest relevanta informationen i ett enda dokument som snabbt kan analyseras för att få en tydlig förståelse av statusen för databaserna och dess processer.
Med ClusterControl kan du schemalägga miljörapporter för flera kluster som daglig systemrapport, paketuppgraderingsrapport, schemaändringsrapport samt säkerhetskopior och tillgänglighet. Dessa rapporter hjälper dig att hålla din miljö säker och funktionsduglig. Du kommer också att se rekommendationer om hur man åtgärdar luckor. Rapporter kan riktas till SysOps, DevOps eller till och med chefer som vill få regelbundna statusuppdateringar om ett givet systems hälsa.
Följande är ett exempel på en daglig driftsrapport som skickas till din brevlåda angående tillgänglighet:
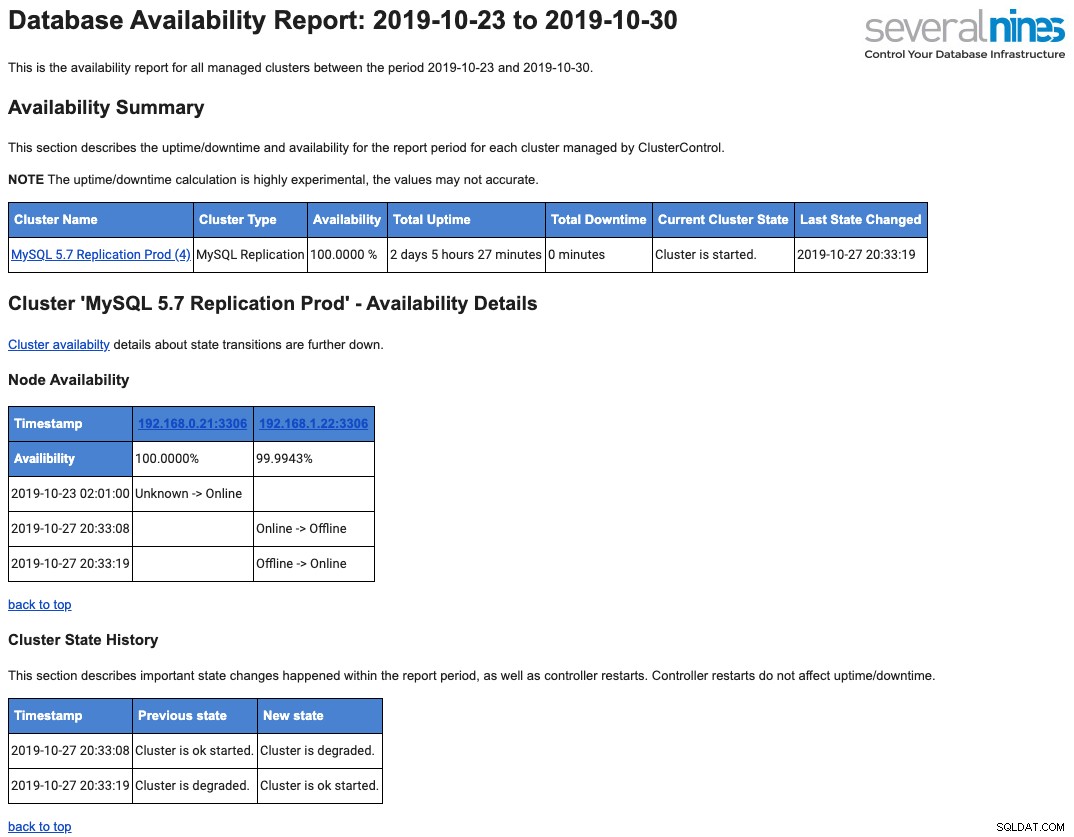
Vi har behandlat detta i detalj i det här blogginlägget, En översikt över databasoperativa rapportering i ClusterControl.
Synkronisera om en slav via säkerhetskopiering
ClusterControl tillåter iscensättning av en slav (oavsett om det är en ny slav eller en trasig slav) via den senaste fullständiga eller inkrementella säkerhetskopian. Det låter inte särskilt spännande, men den här funktionen är enorm om du har stora datamängder på 100 GB och uppåt. Vanlig praxis vid omsynkronisering av en slav är att streama en säkerhetskopia av den nuvarande mastern, vilket kommer att ta lite tid beroende på databasens storlek. Detta kommer att lägga till en extra börda för mastern, vilket kan äventyra masterns prestanda.
För att synkronisera om en slav via säkerhetskopiering, välj slavnoden under sidan Noder och gå till Nodåtgärder -> Bygg om replikeringsslav -> Bygg om från en säkerhetskopia. Endast PITR-kompatibel säkerhetskopia kommer att listas i rullgardinsmenyn:
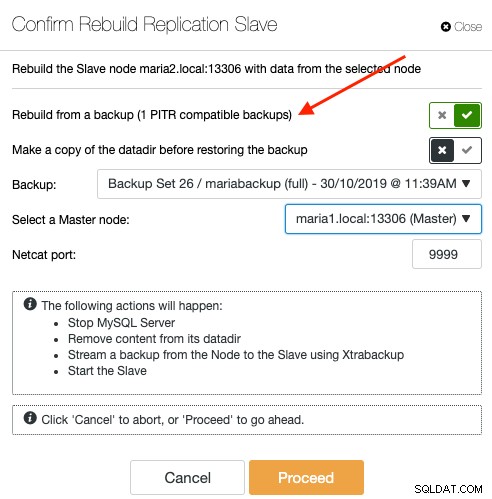
Omsynkronisering av en slav från en säkerhetskopia kommer inte att medföra någon extra overhead till mastern, där ClusterControl extraherar och strömmar säkerhetskopian från backuplagringsplatsen till slaven och så småningom konfigurerar replikeringslänken mellan slaven till mastern. Slaven kommer senare ikapp mastern när replikeringslänken har upprättats. Mastern är orörd under hela processen, och du kan övervaka hela framstegen under Aktivitet -> Jobb.
Bootstrap ett Galera-kluster
Galera Cluster är ett mycket populärt när man implementerar hög tillgänglighet för MySQL eller MariaDB, men fel hanteringskommandon kan leda till katastrofala konsekvenser. Ta en titt på det här blogginlägget om hur man bootstrap ett Galera Cluster under olika förhållanden. Detta illustrerar att bootstrapping av ett Galera Cluster har många variabler och måste utföras med extrem försiktighet. Annars kan du förlora data eller orsaka en splittrad hjärna. ClusterControl förstår databastopologin och vet exakt vad man ska göra för att starta ett databaskluster ordentligt. För att starta ett kluster via ClusterControl, klicka på Cluster Actions -> Bootstrap Cluster:
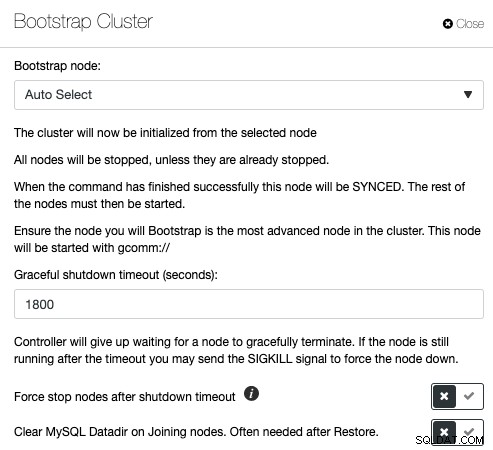
Du kommer att ha möjlighet att låta ClusterControl välja rätt bootstrap-nod automatiskt, eller utföra en initial bootstrap där du väljer en av databasnoderna från listan för att bli referensnod och raderar MySQL-datafilen på joinernoderna för att tvinga SST från den bootstrappade noden. Om bootstrapping-processen misslyckas, kommer ClusterControl att hämta MySQL-felloggen.
Om du vill utföra en manuell bootstrap kan du också använda "Hitta mest avancerade nod"-funktionen och utföra klusterbootstrap-operationen på den mest avancerade noden som rapporterats av ClusterControl.
Centraliserad konfiguration och loggning
ClusterControl hämtar ett antal viktiga konfigurations- och loggningsfiler och visar dem i en trädstruktur inom ClusterControl. En centraliserad vy av dessa filer är nyckeln för att effektivt förstå och felsöka distribuerade databasinställningar. Det traditionella sättet att tailing/greppa dessa filer är sedan länge borta med ClusterControl. Följande skärmdump visar ClusterControls konfigurationsfilhanterare som listade alla relaterade konfigurationsfiler för detta kluster i en enda vy (med syntaxmarkering, naturligtvis):
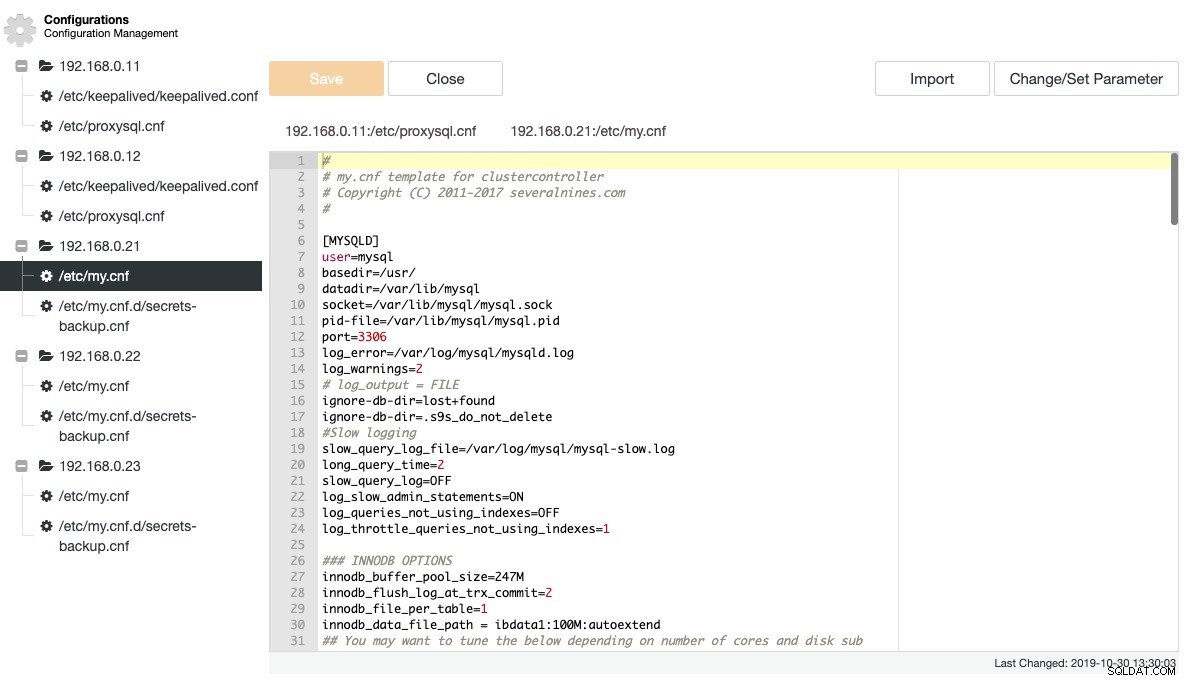
ClusterControl eliminerar repetitiviteten när man ändrar ett konfigurationsalternativ för ett databaskluster. Ändring av ett konfigurationsalternativ på flera noder kan utföras via ett enda gränssnitt och kommer att tillämpas på databasnoden i enlighet med detta. När du klickar på "Ändra/Ange parameter" kan du välja de databasinstanser som du vill ändra och ange konfigurationsgrupp, parameter och värde:
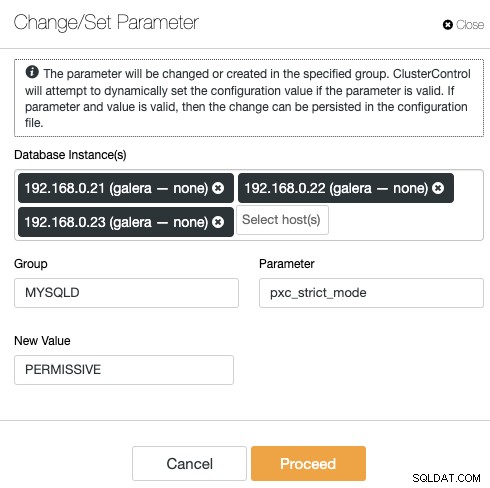
Du kan lägga till en ny parameter i konfigurationsfilen eller ändra en befintlig parameter . Parametern kommer att tillämpas på de valda databasnodernas körtid och i konfigurationsfilen om alternativet klarar variabelvalideringsprocessen. En viss variabel kan kräva omstart av servern, vilket sedan kommer att meddelas av ClusterControl.
Databasklusterkloning
Med ClusterControl kan du snabbt klona ett befintligt MySQL Galera-kluster så att du har en exakt kopia av datamängden på det andra klustret. ClusterControl utför kloningsoperationen online, utan någon låsning eller att det befintliga klustret försvinner. Det är som en klusterskalningsoperation förutom att båda klustren är oberoende av varandra efter att synkroniseringen är klar. Det klonade klustret behöver inte nödvändigtvis ha samma klusterstorlek som det befintliga. Vi skulle kunna börja med ett "en-nodskluster" och skala ut det med fler databasnoder i ett senare skede.
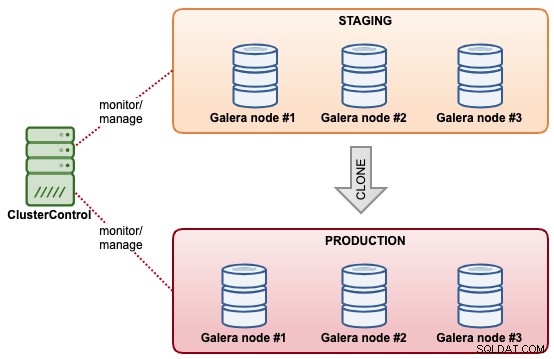
En annan liknande funktion som erbjuds av ClusterControl är "Skapa kluster från säkerhetskopia". Den här funktionen introducerades i ClusterControl 1.7.1, specifikt för Galera Cluster och PostgreSQL-kluster där man kan skapa ett nytt kluster från den befintliga säkerhetskopian. I motsats till klusterkloning ger den här operationen inte ytterligare belastning på källklustret med kompromissen att det klonade klustret inte kommer att vara i samma tillstånd som källklustret.
Vi har behandlat detta ämne i detalj i det här blogginlägget, Hur man skapar en klon av ditt MySQL- eller PostgreSQL-databaskluster.
Återställ fysisk säkerhetskopia
De flesta databashanteringsverktyg tillåter säkerhetskopiering av en databas, och endast en handfull av dem stöder endast databasåterställning av logisk säkerhetskopia. ClusterControl stöder fullständig återställning inte bara för logiska säkerhetskopior, utan även fysiska säkerhetskopior, oavsett om det är en fullständig eller inkrementell säkerhetskopia. Att återställa en fysisk säkerhetskopia kräver ett antal kritiska steg (särskilt inkrementella säkerhetskopior) som i princip innebär att förbereda en säkerhetskopia, kopiera förberedda data till datakatalogen, tilldela korrekt behörighet/äganderätt och starta upp noden i rätt ordning för att bibehålla datakonsistens över alla medlemmar i klustret. ClusterControl utför alla dessa operationer automatiskt.
Du kan också återställa en fysisk säkerhetskopia till en annan nod som inte är en del av ett kluster. I ClusterControl kallas alternativet för detta "Create Cluster from Backup". Du kan börja med ett "ennodskluster" för att testa återställningsprocessen på en annan server eller för att kopiera ut ditt databaskluster till en annan plats.
ClusterControl stöder också återställning av en extern säkerhetskopia, en säkerhetskopia som inte har tagits via ClusterControl. Du behöver bara ladda upp säkerhetskopian till ClusterControl-servern och ange den fysiska sökvägen till säkerhetskopian när du återställer. ClusterControl tar hand om resten.
Kluster-till-klusterreplikering
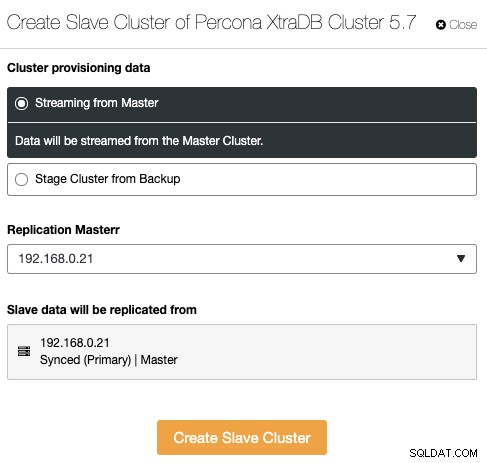
Detta är en ny funktion som introduceras i ClusterControl 1.7.4. ClusterControl kan nu hantera och övervaka kluster-klusterreplikering, vilket i princip utökar den asynkrona databasreplikeringen mellan flera klusteruppsättningar på flera geografiska platser. Ett kluster kan ställas in som ett masterkluster (aktivt kluster som bearbetar läsningar/skrivningar) och slavklustret kan ställas in som ett skrivskyddat kluster (standby-kluster som också kan bearbeta läsningar). ClusterControl stöder asynkron kluster-klusterreplikering för Galera Cluster (binär logg måste vara aktiverad) och även master-slav-replikering för PostgreSQL Streaming-replikering.
För att skapa ett nytt kluster replikat från ett annat kluster, gå till Cluster Actions -> Create Slave Cluster:
Resultatet av ovanstående implementering presenteras tydligt på instrumentpanelen Databas Cluster List :
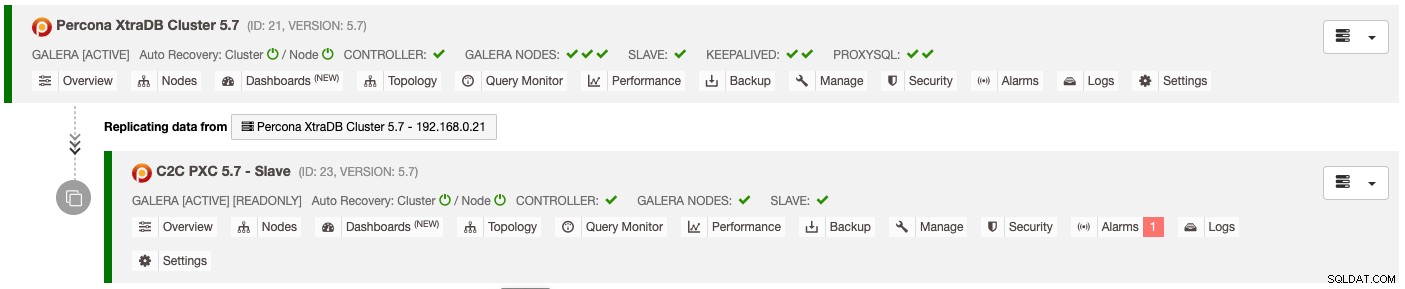
Slavklustret konfigureras automatiskt som skrivskyddat, replikerar från det primära klustret och fungerar som ett standby-kluster. Om en katastrof inträffar i det primära klustret och du vill aktivera den sekundära webbplatsen väljer du helt enkelt menyn "Inaktivera skrivskyddad" under rullgardinsmenyn Noder -> Nodåtgärder för att marknadsföra den som ett aktivt kluster.