ClusterControl är programmerad med ett antal återställningsalgoritmer för att automatiskt svara på olika typer av vanliga fel som påverkar dina databassystem. Den förstår olika typer av databastopologier och databasrelaterad processhantering för att hjälpa dig att avgöra det bästa sättet att återställa klustret. På ett sätt förbättrar ClusterControl din databastillgänglighet.
Vissa topologihanterare täcker bara klusteråterställning som MHA, Orchestrator och mysqlfailover men du måste hantera nodåterställningen själv. ClusterControl stöder återställning på både kluster- och nodnivå.
Konfigurationsalternativ
Det finns två återställningskomponenter som stöds av ClusterControl, nämligen:
- Kluster – Försök att återställa ett kluster till ett operativt tillstånd
- Nod - Försök att återställa en nod till ett operativt tillstånd
Dessa två komponenter är de viktigaste för att säkerställa att tjänstens tillgänglighet är så hög som möjligt. Om du redan har en topologihanterare ovanpå ClusterControl kan du inaktivera automatisk återställningsfunktion och låta annan topologihanterare hantera det åt dig. Du har alla möjligheter med ClusterControl.
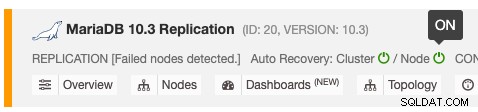
Den automatiska återställningsfunktionen kan aktiveras och inaktiveras med en enkel växling PÅ/AV, och den fungerar för kluster- eller nodåterställning. De gröna ikonerna betyder aktiverad och röda ikoner betyder inaktiverad. Följande skärmdump visar var du kan hitta den i databasklusterlistan:
Det finns 3 ClusterControl-parametrar som kan användas för att kontrollera återställningsbeteendet. Alla parametrar är förinställda på true (inställd med booleskt heltal 0 eller 1):
- enable_autorecovery - Aktivera kluster- och nodåterställning. Denna parameter är superuppsättningen av enable_cluster_recovery och enable_node_recovery. Om den är inställd på 0 kommer delmängdsparametrarna att stängas av.
- enable_cluster_recovery - ClusterControl utför klusteråterställning om den är aktiverad.
- enable_node_recovery - ClusterControl utför nodåterställning om den är aktiverad.
Klusteråterställning täcker återställningsförsök för att få upp hela klustertopologin. Till exempel måste en master-slav-replikering ha minst en master vid varje given tidpunkt, oavsett antalet tillgängliga slav(ar). ClusterControl försöker korrigera topologin minst en gång för replikeringskluster, men oändligt för multimasterreplikering som NDB Cluster och Galera Cluster.
Nodåterställning täcker nodåterställningsproblem som om en nod stoppades utan kunskap om ClusterControl, t.ex. via systemstoppkommando från SSH-konsolen eller dödades av OOM-processen.
Nodåterställning
ClusterControl kan återställa en databasnod i händelse av intermittent fel genom att övervaka processen och anslutningen till databasnoderna. För processen fungerar den på samma sätt som systemd, där den kommer att se till att MySQL-tjänsten startas och körs om du inte avsiktligt stoppade den via ClusterControl UI.
Om noden kommer tillbaka online kommer ClusterControl att upprätta en anslutning tillbaka till databasnoden och utföra nödvändiga åtgärder. Följande är vad ClusterControl skulle göra för att återställa en nod:
- Den väntar på att systemd/chkconfig/init startar de övervakade tjänsterna/processerna i 30 sekunder
- Om de övervakade tjänsterna/processerna fortfarande är nere kommer ClusterControl att försöka starta databastjänsten automatiskt.
- Om ClusterControl inte kan återställa de övervakade tjänsterna/processerna kommer ett larm att utlösas.
Observera att om en databasavstängning initieras av användaren kommer ClusterControl inte att försöka återställa den specifika noden. Det förväntar sig att användaren ska starta det igen via ClusterControl UI genom att gå till Node -> Nodåtgärder -> Starta nod eller använda OS-kommandot uttryckligen.
Återställningen inkluderar alla databasrelaterade tjänster som ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus exportörer och garbd. Särskild uppmärksamhet till Prometheus-exportörer där ClusterControl använder ett program som kallas "daemon" för att demonisera exportprocessen. ClusterControl kommer att försöka ansluta till exportörens lyssningsport för hälsokontroll och verifiering. Därför rekommenderas det att öppna exportportarna från ClusterControl och Prometheus-servern för att säkerställa att inget falsklarm under återställningen.
Klusteråterställning
ClusterControl förstår databastopologin och följer bästa praxis för att utföra återställningen. För ett databaskluster som kommer med inbyggd feltolerans som Galera Cluster, NDB Cluster och MongoDB Replicaset, kommer failover-processen att utföras automatiskt av databasservern via kvorumberäkning, hjärtslag och rollbyte (om någon). ClusterControl övervakar processen och gör nödvändiga justeringar av visualiseringen som att reflektera ändringarna under Topologivyn och justera övervaknings- och hanteringskomponenten för den nya rollen, t.ex. ny primär nod i en replikuppsättning.
För databastekniker som inte har inbyggd feltolerans med automatisk återställning som MySQL/MariaDB-replikering och PostgreSQL/TimescaleDB Streaming Replication, kommer ClusterControl att utföra återställningsprocedurerna genom att följa de bästa metoderna som tillhandahålls av databasleverantör. Om återställningen misslyckas krävs ingripande från användaren och du får givetvis ett larmmeddelande om detta.
I en blandad/hybrid topologi, till exempel en asynkron slav som är kopplad till ett Galera Cluster eller NDB Cluster, kommer noden att återställas av ClusterControl om klusteråterställning är aktiverad.
Klusteråterställning gäller inte för fristående MySQL-server. Det rekommenderas dock att aktivera både nod- och klusteråterställning för denna klustertyp i ClusterControl-gränssnittet.
MySQL/MariaDB-replikering
ClusterControl stöder återställning av följande MySQL/MariaDB-replikeringsinställningar:
- Master-slave med MySQL GTID
- Master-slave med MariaDB GTID
- Master-slave med utan GTID (både MySQL och MariaDB)
- Master-master med MySQL GTID
- Master-master med MariaDB GTID
- Asynkron slav kopplad till ett Galera-kluster
ClusterControl kommer att respektera följande parametrar när klusteråterställning utförs:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
För mer information om varje parameter, se dokumentationssidan.
ClusterControl följer följande regler vid övervakning och hantering av en master-slave-replikering:
- Alla noder kommer att startas med read_only=ON och super_read_only=ON (oavsett dess roll).
- Endast en master (read_only=OFF) tillåts att fungera vid varje given tidpunkt.
- Förlita dig på MySQL-variabeln report_host för att kartlägga topologin.
- Om det finns två eller flera noder som har read_only=AV åt gången, kommer ClusterControl automatiskt att sätta read_only=ON på båda masterna, för att skydda dem mot oavsiktliga skrivningar. Användarens ingripande krävs för att välja den faktiska mastern genom att inaktivera skrivskyddet. Gå till Noder -> Nodåtgärder -> Inaktivera skrivskyddad.
Om den aktiva mastern går ner, kommer ClusterControl att försöka utföra master-failoveren i följande ordning:
- Efter 3 sekunders otillgänglighet kommer ClusterControl att larma.
- Kontrollera slavtillgängligheten, minst en av slavarna måste vara nåbar av ClusterControl.
- Välj slaven som en kandidat för att bli en mästare.
- ClusterControl beräknar sannolikheten för felaktiga transaktioner om GTID är aktiverat.
- Om ingen felaktig transaktion upptäcks, kommer den utvalde att befordras som ny master.
- Skapa och bevilja replikeringsanvändare som ska användas av slavar.
- Ändra mästare för alla slavar som pekade på den gamla mästaren till den nyligen befordrade mästaren.
- Starta slav och aktivera skrivskyddad.
- Spola loggar på alla noder.
- Om slavkampanjen misslyckas kommer ClusterControl att avbryta återställningsjobbet. Användaringripande eller en omstart av cmon-tjänsten krävs för att utlösa återställningsjobbet igen.
- När den gamla mastern är tillgänglig igen kommer den att startas som skrivskyddad och kommer inte att ingå i replikeringen. Användarens ingripande krävs.
Samtidigt kommer följande larm att utlösas:
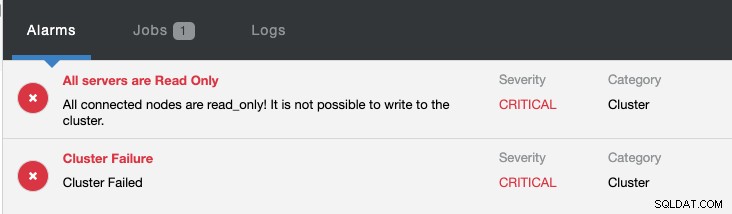
Kolla in Introduktion till Failover för MySQL-replikering - 101-bloggen och Automatic Failover för MySQL-replikering - Nytt i ClusterControl 1.4 för att få ytterligare information om hur du konfigurerar och hanterar MySQL-replikeringsfel med ClusterControl.
PostgreSQL/TimescaleDB Streaming Replication
ClusterControl stöder återställning av följande PostgreSQL-replikeringsinställningar:
- PostgreSQL Streaming Replication
- TimescaleDB Streaming Replication
ClusterControl kommer att respektera följande parametrar när klusteråterställning utförs:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
För mer information om varje parameter, se dokumentationssidan.
ClusterControl följer följande regler för att hantera och övervaka en PostgreSQL-strömningsreplikeringsinställning:
- wal_level är inställd på "replik" (eller "hot_standby" beroende på PostgreSQL-versionen).
- Variable archive_mode är inställd på PÅ på mastern.
- Sätt filen recovery.conf på slavnoderna, vilket förvandlar noden till ett varmt standbyläge med skrivskyddat aktiverat.
Om den aktiva mastern går ner, kommer ClusterControl att försöka utföra klusteråterställningen i följande ordning:
- Efter 10 sekunders oåtkomlighet av mastern kommer ClusterControl att larma.
- Efter 10 sekunders graciös väntan timeout kommer ClusterControl att initiera master failover-jobbet.
- Sampla replayLocation och receiveLocation på alla tillgängliga noder för att bestämma den mest avancerade noden.
- Marknadsför den mest avancerade noden som den nya mastern.
- Stoppa slavar.
- Verifiera synkroniseringstillståndet med pg_rewind.
- Startar om slavar med den nya mastern.
- Om slavkampanjen misslyckas kommer ClusterControl att avbryta återställningsjobbet. Användaringripande eller en omstart av cmon-tjänsten krävs för att utlösa återställningsjobbet igen.
- När den gamla mastern är tillgänglig igen, kommer den att tvingas stängas av och kommer inte att vara en del av replikeringen. Användarens ingripande krävs. Se längre ner.
När den gamla mastern kommer online igen, om PostgreSQL-tjänsten körs, tvingar ClusterControl att stänga av PostgreSQL-tjänsten. Detta för att skydda servern från oavsiktliga skrivningar, eftersom den skulle startas utan en återställningsfil (recovery.conf), vilket betyder att den skulle vara skrivbar. Du bör förvänta dig att följande rader kommer att visas i postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL startades efter att servern var online igen runt 05:06:10 men ClusterControl utför en snabb avstängning 17 sekunder efter det runt 05:06:27. Om det här är något du inte vill att det ska vara, kan du tillfälligt inaktivera nodåterställning för det här klustret.
Kolla in Automatisk failover av Postgres-replikering och failover för PostgreSQL-replikering 101 för att få mer information om hur du konfigurerar och hanterar PostgreSQL-replikeringsfel med ClusterControl.
Slutsats
ClusterControls automatiska återställning förstår databasklustertopologin och kan återställa ett nedåtgående eller degraderat kluster till ett fullt fungerande kluster vilket kommer att förbättra databastjänstens drifttid avsevärt. Prova ClusterControl nu och uppnå dina nior i SLA och databastillgänglighet. Kan du inte dina nior? Kolla in den här coola nior-kalkylatorn.