I de två föregående blogginläggen täckte vi både distribution av de fyra typerna av klustring/replikering (MySQL/Galera, MySQL-replikering, MongoDB &PostgreSQL) och hantering/övervakning av dina befintliga databaser och kluster. Så efter att ha läst dessa två första blogginlägg kunde du lägga till dina 20 befintliga replikeringsinställningar till ClusterControl, utöka dem och dessutom distribuera två nya Galera-kluster samtidigt som du gjorde massor av andra saker. Eller så kanske du har distribuerat MongoDB- och/eller PostgreSQL-system. Så nu, hur håller du dem friska?
Det är precis vad det här blogginlägget handlar om:hur man utnyttjar ClusterControls prestandaövervakning och rådgivares funktionalitet för att hålla dina MySQL-, MongoDB- och/eller PostgreSQL-databaser och -kluster friska. Så hur görs detta i ClusterControl?
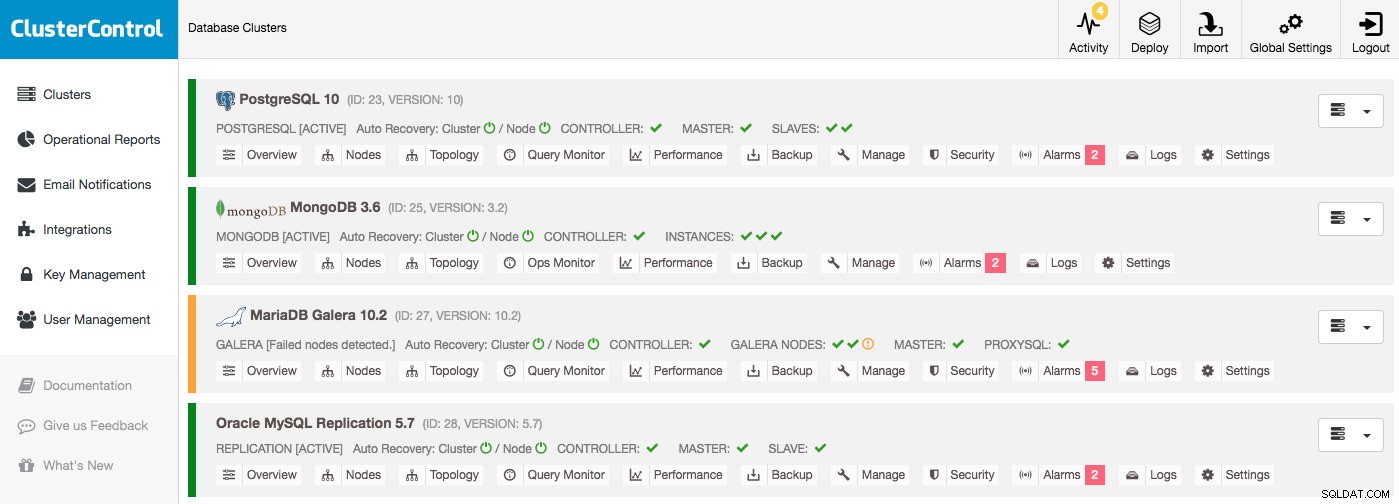
Databasklusterlista
Den viktigaste informationen finns redan i klusterlistan:så länge det inte finns några larm och inga värdar visas nere fungerar allt bra. Ett larm går om ett visst villkor är uppfyllt, t.ex. värd byter och gör dig uppmärksam på problemet du bör undersöka. Det betyder att larm inte bara utlöses under ett avbrott utan också för att du ska kunna hantera dina databaser proaktivt.
Anta att du skulle logga in på ClusterControl och se en klusterlista som denna, du kommer definitivt att ha något att undersöka:en nod är nere i Galera-klustret till exempel och varje kluster har olika larm:
När du klickar på ett av larmen kommer du till en detaljerad sida om alla larm i klustret. Larmdetaljerna kommer att förklara problemet och i de flesta fall även ge råd om åtgärder för att lösa problemet.
Du kan ställa in dina egna larm genom att skapa anpassade uttryck, men det har förkastats till förmån för vår nya Developer Studio som låter dig skriva anpassade Javascript och exekvera dessa som rådgivare. Vi återkommer till det här ämnet senare i det här inlägget.
Klusteröversikt - Dashboards
När vi öppnar klusteröversikten kan vi direkt se de viktigaste prestandamåtten för klustret på flikarna. Den här översikten kan skilja sig per klustertyp, eftersom Galera till exempel har andra prestandamått att titta på än traditionella MySQL, PostgreSQL eller MongoDB.
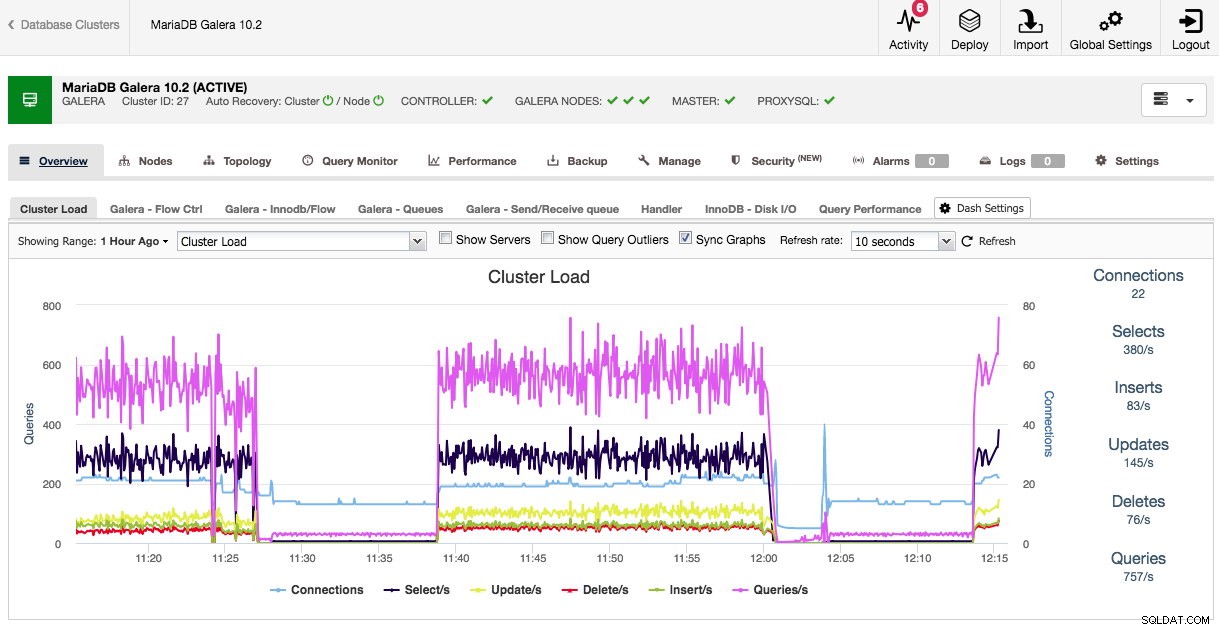
Både standardöversikten och de förvalda flikarna är anpassningsbara. Genom att klicka på Översikt -> Dash Settings du får en dialogruta som låter dig definiera instrumentpanelen:
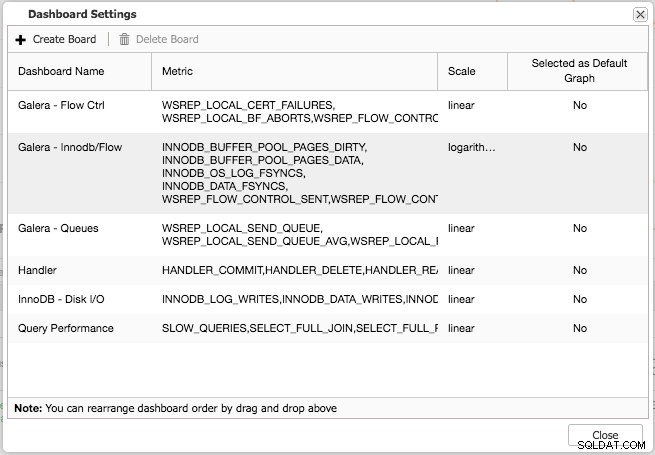
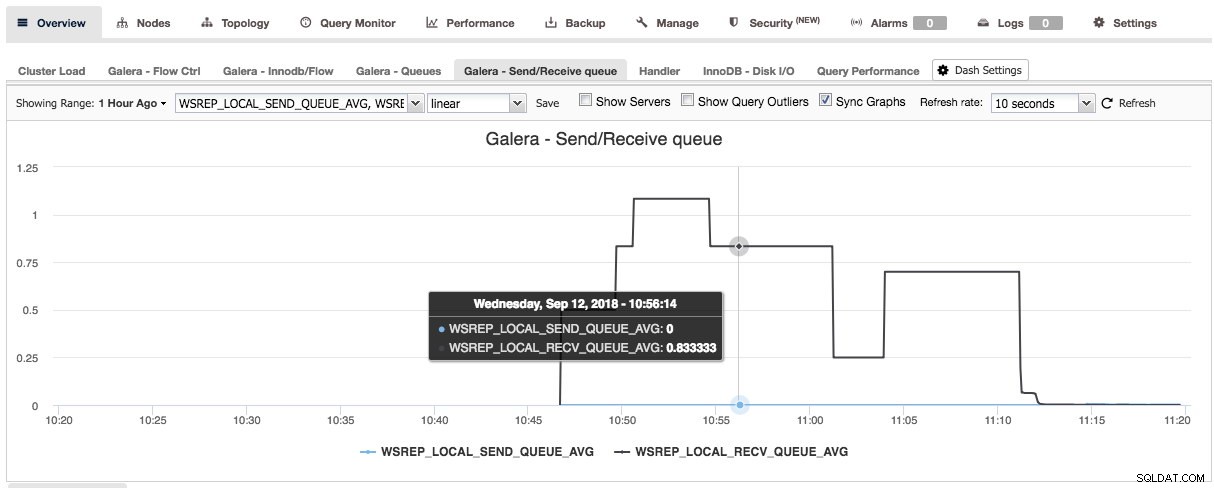
Genom att trycka på plustecknet kan du lägga till och definiera dina egna mätvärden för att plotta instrumentpanelen. I vårt fall kommer vi att definiera en ny instrumentpanel med Galera-specifika sändnings- och mottagningskön:
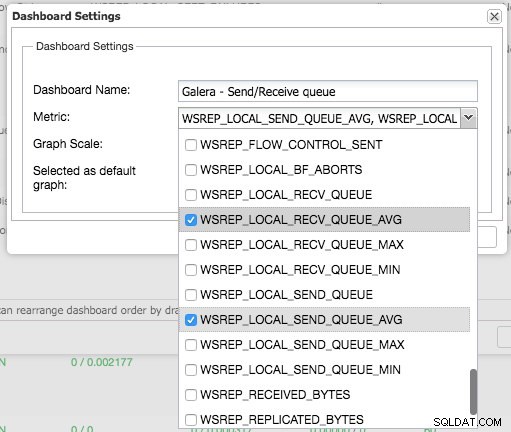
Den här nya instrumentpanelen borde ge oss god insikt i den genomsnittliga kölängden för vårt Galera-kluster.
När du har tryckt på spara blir den nya instrumentpanelen tillgänglig för detta kluster:
På samma sätt kan du göra detta för PostgreSQL också, till exempel kan vi övervaka de delade blocken som träffar kontra block som läses:
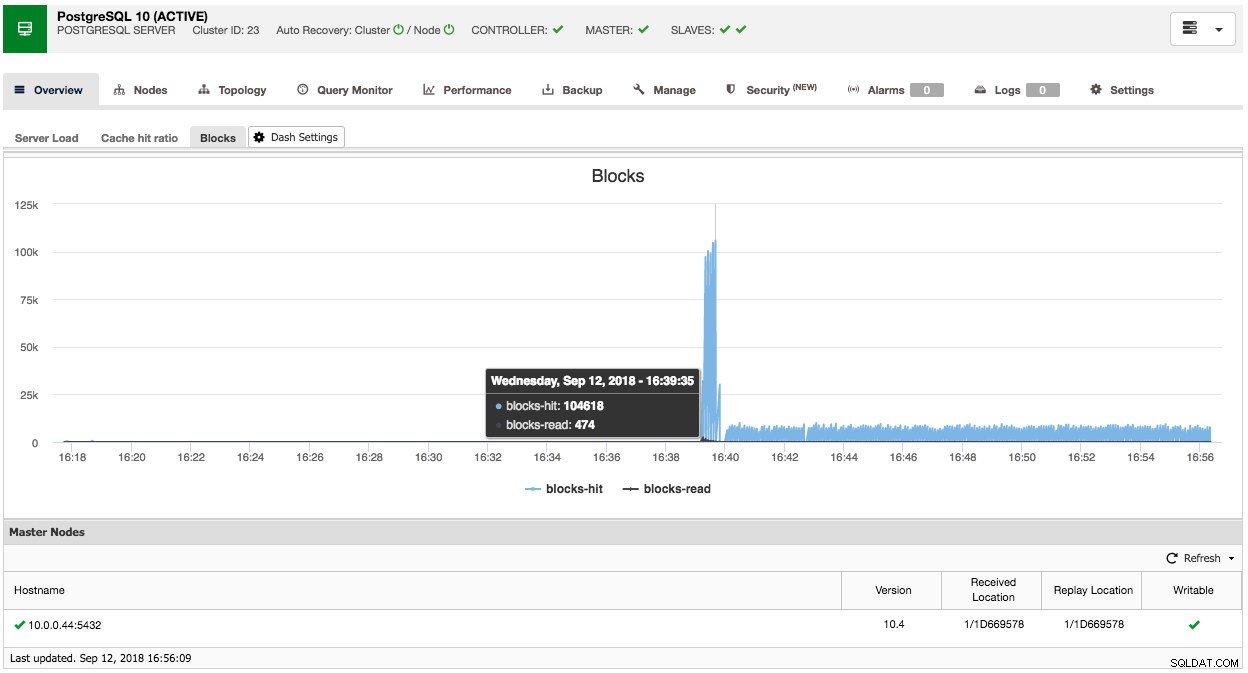
Så som du kan se är det relativt enkelt att anpassa din egen (standard) instrumentpanel.
Klusteröversikt - Query Monitor
Fliken Query Monitor är tillgänglig för både MySQL- och PostgreSQL-baserade inställningar och består av tre instrumentpaneler:Top Queries, Running Queries och Query Outliers.
I instrumentpanelen Running Queries hittar du alla aktuella frågor som körs. Detta är i princip motsvarigheten till SHOW FULL PROCESSLIST-satsen i MySQL-databasen.
Top Queries och Query Outliers är båda beroende av input från den långsamma frågeloggen eller Performance Schema. Att använda Performance Schema rekommenderas alltid och kommer att användas automatiskt om det är aktiverat. Annars kommer ClusterControl att använda MySQL långsamma frågelogg för att fånga de pågående frågorna. För att förhindra att ClusterControl blir för påträngande och att den långsamma frågeloggen blir för stor, kommer ClusterControl att ta prov på den långsamma frågeloggen genom att slå på och av den. Denna loop är som standard inställd på 1 sekunds fångst och long_query_time är inställd på 0,5 sekunder. Om du vill ändra dessa inställningar för ditt kluster kan du ändra detta via Inställningar -> Query Monitor .
Top Queries kommer, som namnet säger, att visa de vanligaste frågorna som samplades. Du kan sortera dem i olika kolumner:till exempel frekvens, genomsnittlig körningstid, total körningstid eller standardavvikelsetid:
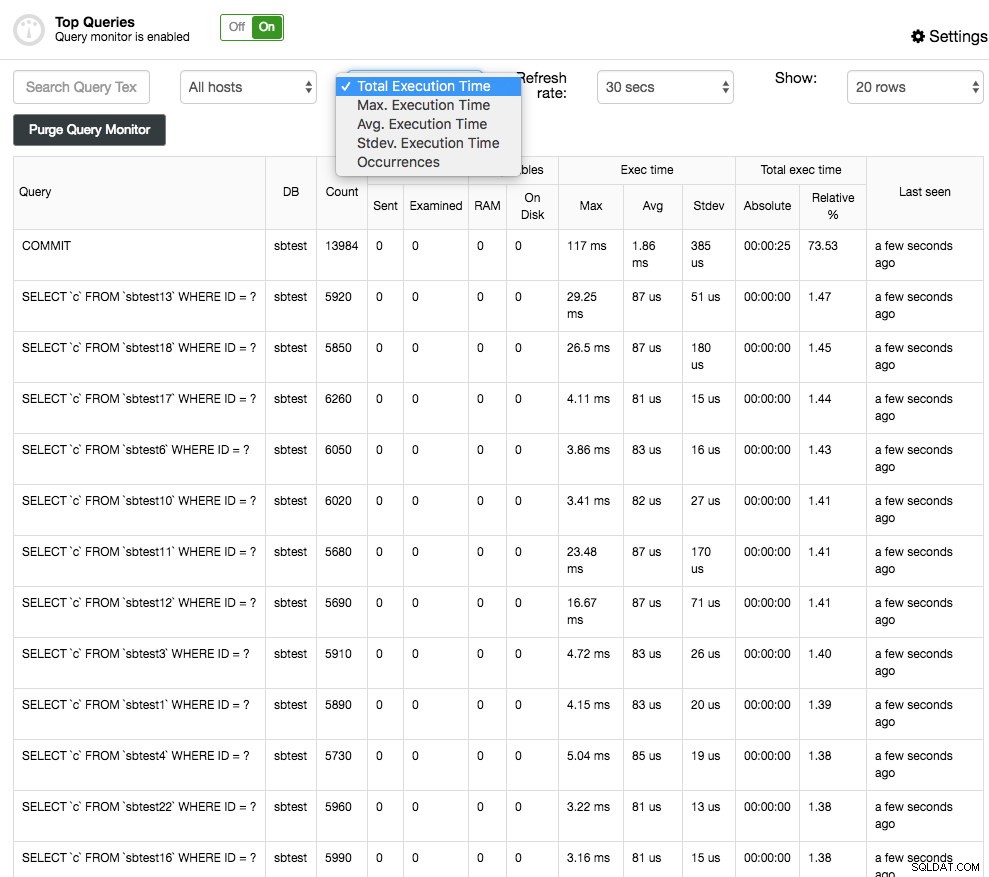
Du kan få mer information om frågan genom att välja den och detta kommer att presentera frågeexekveringsplanen (om tillgänglig) och optimeringstips/rådgivningar. Query Outliers liknar Top Queries men låter dig sedan filtrera frågorna per värd och jämföra dem i tid.
Klusteröversikt - Verksamhet
I likhet med PostgreSQL- och MySQL-systemen har MongoDB-klustren operationsöversikten och liknar MySQL:s Running Queries. Den här översikten liknar att utfärda kommandot db.currentOp() inom MongoDB.
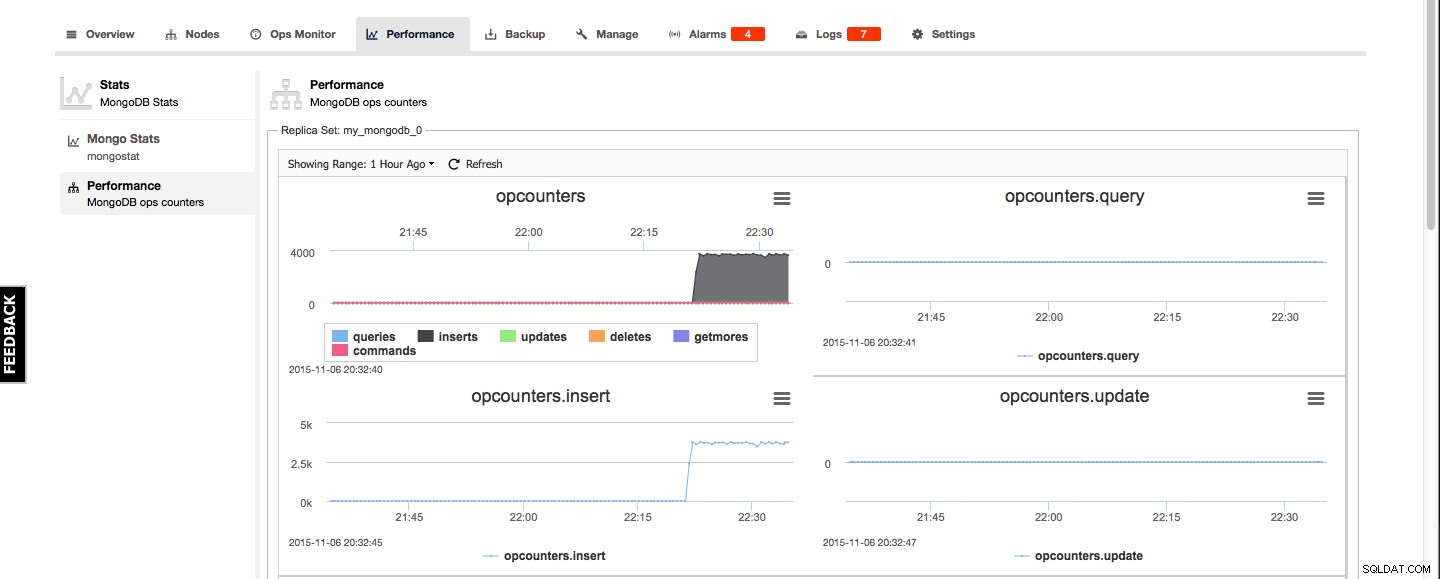
Klusteröversikt – prestanda
MySQL/Galera
Prestandafliken är förmodligen det bästa stället att hitta den övergripande prestandan och hälsan för dina kluster. För MySQL och Galera består den av en översiktssida, rådgivarna, status-/variabelöversikter, Schema Analyzer och transaktionsloggen.
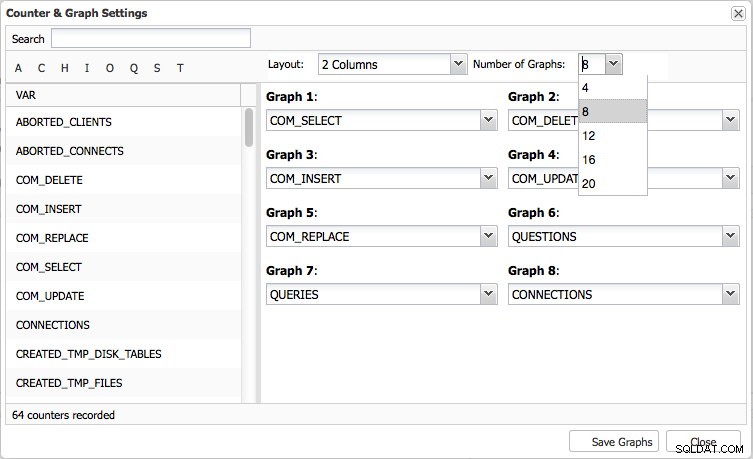
Översiktssidan ger dig en graföversikt över de viktigaste mätvärdena i ditt kluster. Detta är uppenbarligen olika per klustertyp. Åtta mätvärden har ställts in som standard, men du kan enkelt ställa in dina egna - upp till 20 grafer om det behövs:
Rådgivarna är en av nyckelfunktionerna i ClusterControl:Rådgivarna är skriptkontroller som kan köras på begäran. Rådgivarna kan utvärdera nästan alla kända fakta om värden och/eller klustret och ge sin åsikt om värdens och/eller klustrets hälsa och kan till och med ge råd om hur man löser problem eller förbättrar dina värdar!
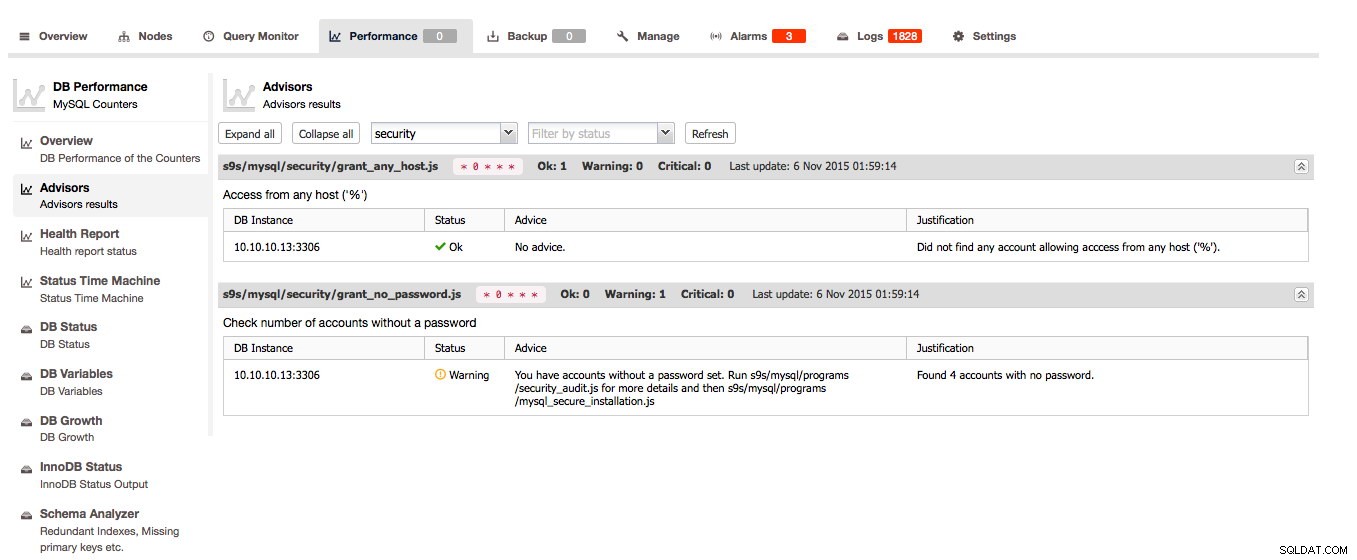
Det bästa är ännu att komma:du kan skapa dina egna checkar i Developer Studio (ClusterControl -> Hantera -> Developer Studio ), kör dem med jämna mellanrum och använd dem igen i avsnittet Rådgivare. Vi bloggade om den här nya funktionen tidigare i år.
Vi kommer att hoppa över status/variabler översikten av MySQL och Galera eftersom detta är användbart som referens men inte för det här blogginlägget:det är tillräckligt bra att du vet att det finns här.
Anta nu att din databas växer men du vill veta hur snabbt den växte under den senaste veckan. Du kan faktiskt hålla reda på tillväxten av både data och indexstorlekar direkt från ClusterControl:
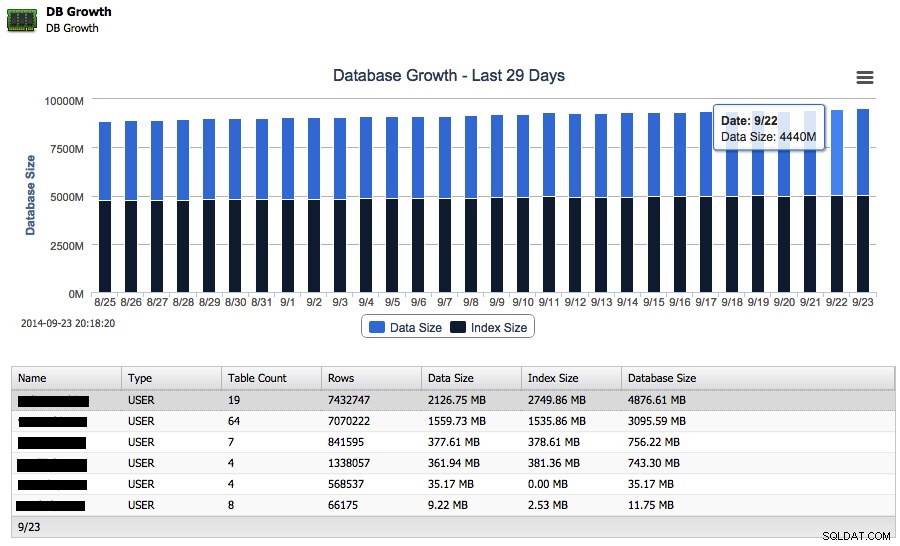
Och bredvid den totala tillväxten på disk kan den också rapportera tillbaka de 25 största schemana.
En annan viktig funktion är Schema Analyzer inom ClusterControl:
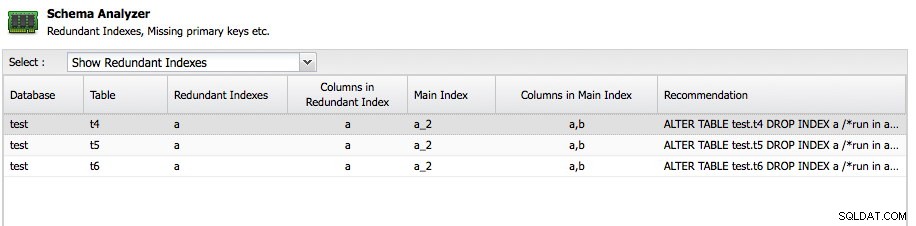
ClusterControl kommer att analysera dina scheman och leta efter redundanta index, MyISAM-tabeller och tabeller utan en primärnyckel. Naturligtvis är det helt upp till dig att behålla en tabell utan en primärnyckel eftersom någon applikation kan ha skapat det på detta sätt, men det är åtminstone bra att få råd här gratis. Schema Analyzer rekommenderar till och med den nödvändiga ALTER-satsen för att åtgärda problemet.
PostgreSQL
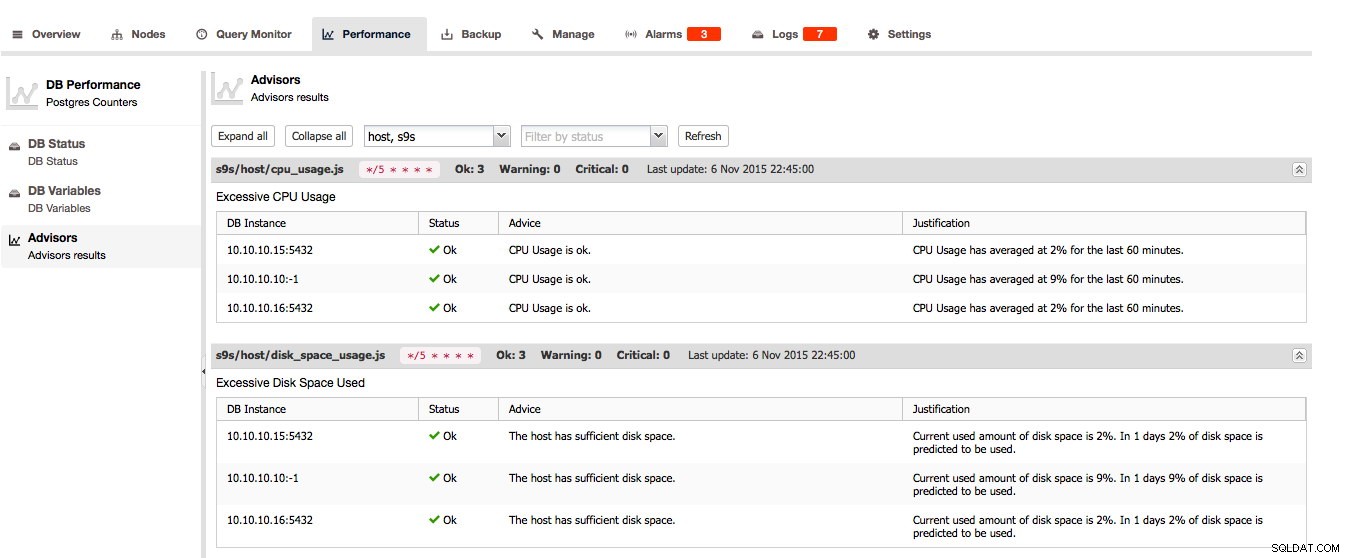
För PostgreSQL finns rådgivarna, DB-status och DB-variabler här:
MongoDB
För MongoDB finns Mongostatistik och prestationsöversikt under fliken Prestanda. Mongostatistiken är en översikt över produktionen av mongostat och prestandaöversikten ger en bra grafisk översikt över MongoDB-mottagarna:
Sluta tankar
Vi visade dig hur du håller ögonen på de viktigaste övervaknings- och hälsokontrollfunktionerna i ClusterControl. Uppenbarligen är detta bara början på resan eftersom vi snart kommer att starta ytterligare en bloggserie om Developer Studios funktioner och hur du kan göra de flesta av dina egna kontroller. Tänk också på att vårt stöd för MongoDB och PostgreSQL inte är lika omfattande som vårt MySQL-verktyg, men vi förbättrar kontinuerligt detta.
Du kan fråga dig själv varför vi har hoppat över prestandaövervakningen och hälsokontrollerna för HAProxy, ProxySQL och MaxScale. Vi gjorde det medvetet eftersom bloggserien endast omfattade distributioner av kluster hittills och inte distributionen av HA-komponenter. Så det är ämnet vi ska ta upp nästa gång.