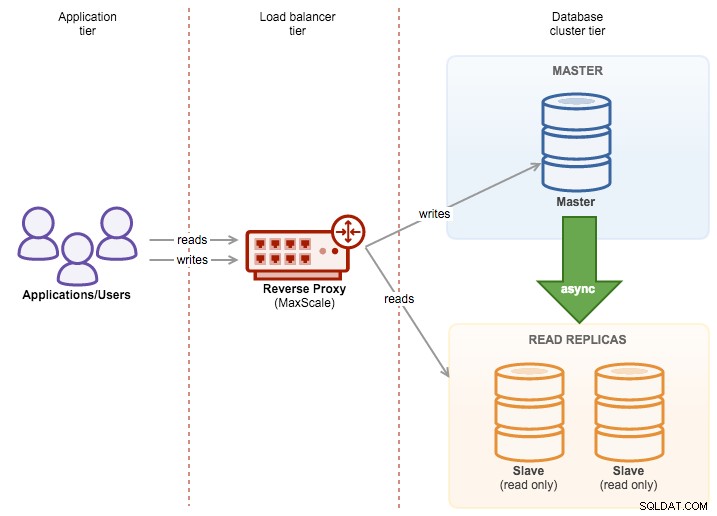
ClusterControl är ett utmärkt verktyg för att distribuera och hantera databaser kluster - om du är i MySQL kan du enkelt distribuera kluster baserade på både traditionell MySQL master-slave replikering, Galera Cluster eller MySQL NDB Cluster. För att uppnå hög tillgänglighet räcker det dock inte att distribuera ett kluster. Noder kan (och kommer med största sannolikhet) att gå ner, och ditt system måste kunna anpassa sig till dessa förändringar.
Denna anpassning kan ske på olika nivåer. Du kan implementera någon form av logik i applikationen - den skulle kontrollera tillståndet för klusternoder och dirigera trafik till de som är tillgängliga vid det givna ögonblicket. Du kan också bygga ett proxylager som kommer att implementera hög tillgänglighet i ditt system. I det här blogginlägget vill vi dela med oss av några tips om hur du kan uppnå det med ClusterControl.
Distribuera HAProxy med hjälp av ClusterControl
HAProxy är standarden – en av de mest populära proxyservrar som används i samband med MySQL (men inte bara, förstås). ClusterControl stöder distribution och övervakning av HAProxy-noder. Det hjälper också till att implementera hög tillgänglighet för själva proxyn med keepalived.
Implementeringen är ganska enkel - du måste välja eller fylla i IP-adressen till en värd där HAProxy ska installeras, välja port, belastningsbalanseringspolicy, bestämma om ClusterControl ska använda befintligt arkiv eller den senaste källkoden för att distribuera HAProxy. Du kan också välja vilka backend-noder du vill ha med i proxykonfigurationen och om de ska vara aktiva eller backup.
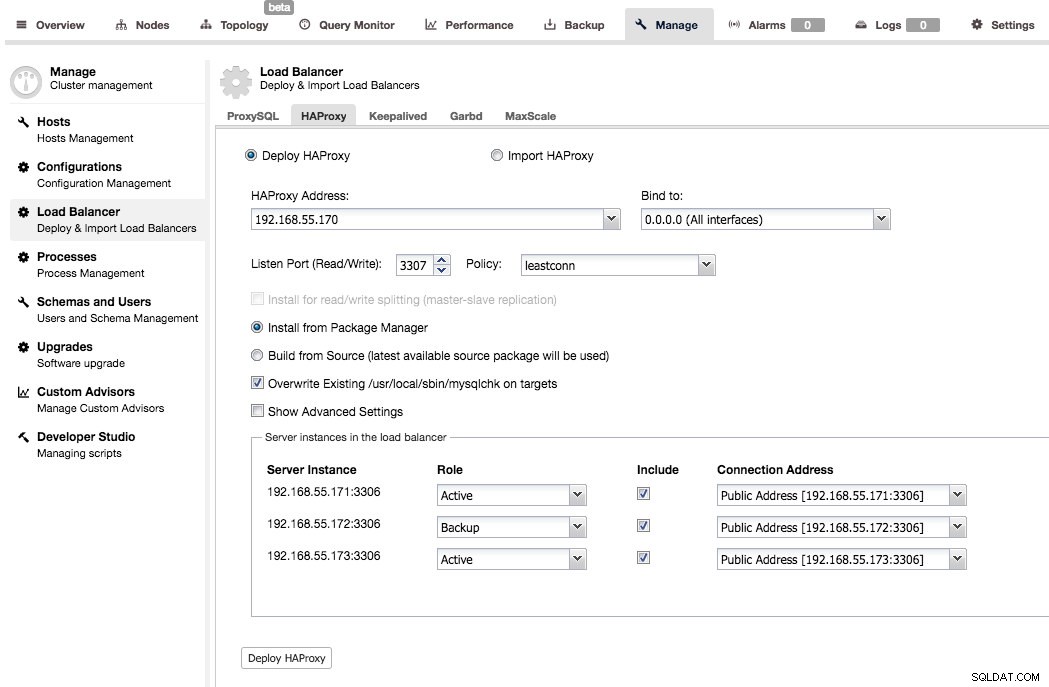
Som standard kommer HAProxy-instansen som distribueras av ClusterControl att fungera på MySQL Cluster (NDB), Galera Cluster, PostgreSQL streaming replikering och MySQL Replication. För master-slave replikering kan ClusterControl konfigurera två lyssnare, en för skrivskyddad och en annan för läs-skriv. Applikationer måste sedan skicka läsningar och skrivningar till respektive portar. För multimasterreplikering kommer ClusterControl att ställa in standard TCP-lastbalansering baserad på minsta anslutningsbalanseringsalgoritm (t.ex. för Galera Cluster där alla noder är skrivbara).
Keepalved används för att lägga till hög tillgänglighet till proxylagret. När du har minst två HAProxy-noder i ditt system kan du installera Keepalved från ClusterControl UI.
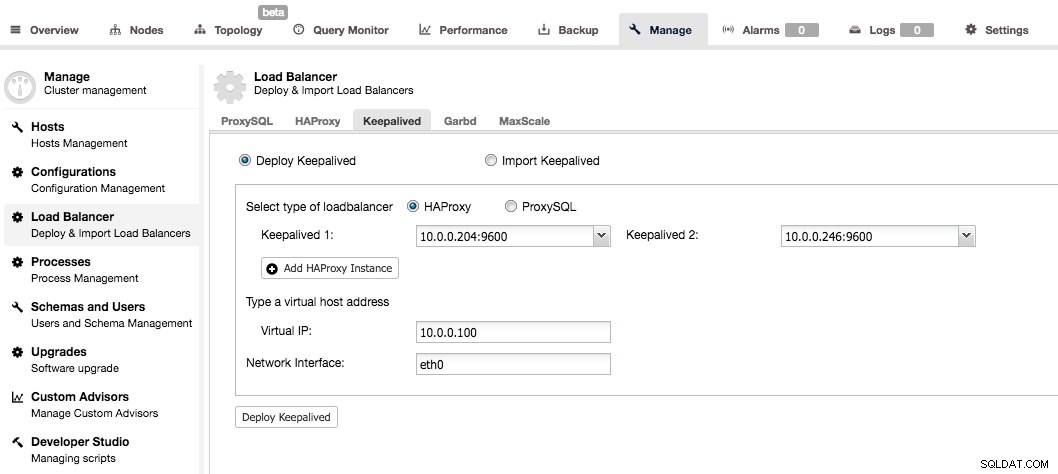
Du måste välja två HAProxy-noder och de kommer att konfigureras som ett aktivt standby-par. En virtuell IP skulle tilldelas den aktiva servern och om den misslyckas kommer den att omtilldelas till standby-proxyn. På så sätt kan du bara ansluta till VIP:n och alla dina frågor kommer att dirigeras till den för närvarande aktiva och fungerande HAProxy-noden.
Du kan hitta mer information om hur internerna är konfigurerade genom att läsa igenom vår HAProxy-handledning.
Distribuera ProxySQL med ClusterControl
Även om HAProxy är en stensäker proxy och mycket populärt val, saknar den databasmedvetenhet, t.ex. läs-skriv-delning. Det enda sättet att göra det i HAProxy är att skapa två backends och lyssna på två portar - en för läsning och en för skrivning. Detta är vanligtvis bra, men det kräver att du implementerar ändringar i din applikation - applikationen måste förstå vad som är en läsning och vad som är en skrivning, och sedan rikta dessa frågor till rätt port. Det skulle vara mycket enklare att bara ansluta till en enda port och låta proxyn bestämma vad som ska göras härnäst - det här är något HAProxy inte kan göra eftersom det den gör bara är att dirigera paket - ingen paketinspektion görs och speciellt har den ingen förståelse för MySQL-protokollet.
ProxySQL löser detta problem - den pratar MySQL-protokoll och den kan (bland annat) utföra en läs-skrivdelning genom sina kraftfulla frågeregler och dirigera den inkommande MySQL-trafiken enligt olika kriterier. Installationen av ProxySQL från ClusterControl är enkel - du vill gå till sektionen Hantera -> Load Balancer och fylla fliken "Deploy ProxySQL" med nödvändiga data.
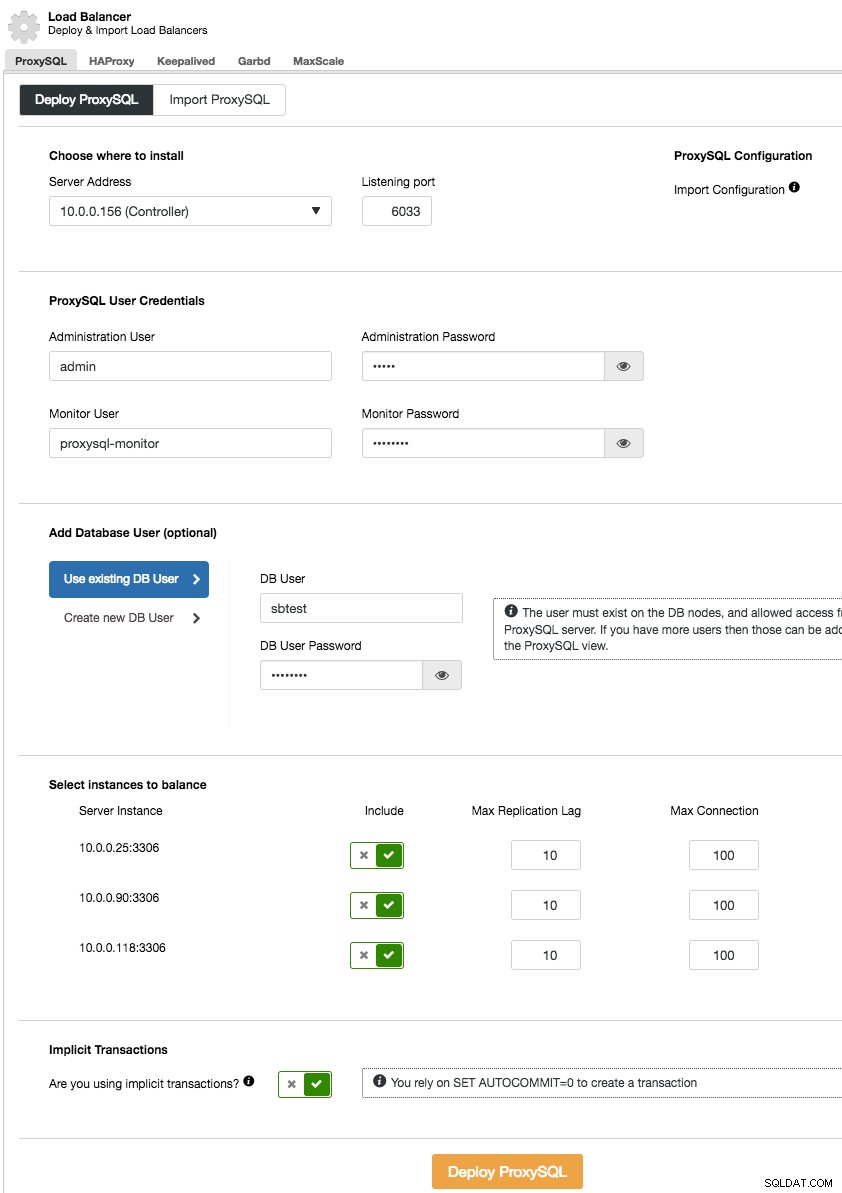
Kort sagt måste vi välja var ProxySQL ska installeras, vilken administratörsanvändare och lösenord den ska ha, vilken övervakningsanvändare den ska använda för att ansluta till MySQL-backends och verifiera deras status och övervakningstillstånd. Från ClusterControl kan du antingen skapa en ny användare som ska användas av applikationen - du kan bestämma dess namn, lösenord, åtkomst till vilka databaser som beviljas och vilka MySQL-privilegier den användaren ska ha. En sådan användare kommer att skapas på både MySQL- och ProxySQL-sidan. Det andra alternativet, mer lämpligt för befintliga infrastrukturer, är att använda befintliga databasanvändare. Du måste skicka användarnamn och lösenord, och en sådan användare skapas endast på ProxySQL.
Slutligen måste du svara på en fråga:använder du implicita transaktioner? Med det förstår vi transaktioner som startas genom att köra SET autocommit=0; Om du använder det kommer ClusterControl att konfigurera ProxySQL för att skicka all trafik till mastern. Detta krävs för att säkerställa att ProxySQL kommer att hantera transaktioner korrekt i ProxySQL 1.3.x och tidigare. Om du inte använder SET autocommit=0 för att skapa en ny transaktion kommer ClusterControl att konfigurera läs/skrivdelning.
ProxySQL, som varje proxy, kan bli en enda felpunkt och den måste göras överflödig för att uppnå hög tillgänglighet. Det finns ett par metoder för att göra det. En av dem är att samlokalisera ProxySQL på webbnoderna. Tanken här är att, för det mesta, kommer ProxySQL-processen att fungera bra och orsaken till dess otillgänglighet är att hela noden gick ner. I sådana fall, om ProxySQL samlokaliseras med webbnoden, har inte mycket skada skett eftersom den specifika webbnoden inte heller kommer att vara tillgänglig.
En annan metod är att använda Keepalved på ett liknande sätt som vi gjorde i fallet med HAProxy.
Du kan hitta mer information om hur internerna är konfigurerade genom att läsa igenom vår ProxySQL-handledning.