MongoDB-zoner
För att förstå MongoDB-zoner måste vi först förstå vad en zon är:en grupp skärvor baserade på en specifik uppsättning taggar.
MongoDB-zoner hjälper till med distributionen av bitar baserat på taggar, över skärvor. Allt arbete (läser och skriver) relaterat till dokument inom en zon görs på skärvor som matchar den zonen.
Det kan finnas olika scenarier där fragmenterade kluster (zonbaserade) kan visa sig vara mycket användbara. Låt oss säga:
- En applikation som är geografiskt distribuerad kan kräva frontend, såväl som datalagret
- En applikation har en n-tier-arkitektur så att vissa poster hämtas från hårdvara med högre nivå (låg latens), medan andra kan hämtas från hårdvara med låg nivå (hög latensframkallande)
Fördelar med att använda MongoDB-zoner
Med hjälp av MongoDB Zones kan DBA:er skapa lagringslösningar som stöder datalivscykeln, med ofta använd data lagrad i minnet, mindre använd data lagrad på servern och vid rätt tidpunkt arkiverad data som tas offline.
Hur man ställer in zoner
I fragmenterade kluster kan du skapa zoner som representerar en grupp shards och associera ett eller flera intervall av shardnyckelvärden till den zonen. MongoDB dirigerar alla läsningar och alla skrivningar som kommer in i ett zonintervall endast till de skärvor som finns inuti zonen. Du kan associera varje zon med en eller flera shards i klustret och en shard kan associeras med valfritt antal zoner.
Några av de vanligaste distributionsmönstren där zoner kan tillämpas är följande:
- Isolera en specifik delmängd av data på en specifik uppsättning skärvor.
- Genom att se till att den mest relevanta informationen finns på skärvor som är geografiskt närmast applikationsservrarna.
- Dirigera data till skärvorna baserat på prestandan hos hårdvaran.
Följande bild illustrerar ett klippt kluster med tre skärvor och två zoner. A-zonen representerar ett område med en nedre gräns på 0 och en övre gräns på 10. B-zonen visar ett område med en nedre gräns på 10 och en övre gräns på 20. Skärvor RÖDA och BLÅA har A-zonen. Shard BLUE har också B-zonen. Shard GREEN har inga zoner associerade med sig. Klustret är i ett stabilt tillstånd och inga bitar bryter mot någon av zonerna
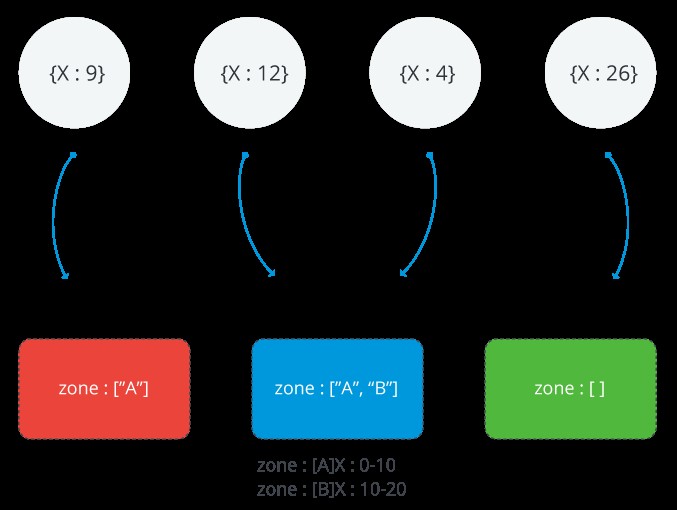
Räckvidd för en MongoDB-zon
Varje zon täcker ett eller flera intervall av shard-nyckelvärden. Varje område som en zon täcker inkluderar alltid dess nedre gräns och exklusive dess övre gräns.
KOM IHÅG: Zoner kan inte dela intervall och de kan inte ha överlappande intervall.
Lägga till skärvor i en zon
sh.addShardTag()-metoden används för att lägga till zoner till en skärva. En enda skärva kan ha flera zoner, och flera skärvor kan också ha samma zon. Följande exempel lägger till zon A till en skärpa.
sh.addShardTag("shard0000", "A")Ta bort skärvor till en zon
För att ta bort en zon från en shard, används metoden sh.removeShardTag(). Följande exempel tar bort zon A från en skärva.
sh.removeShardTag("shard0002", "A")Tips för MongoDB-zoner
Håll dokumenten enkla
MongoDB är en schemafri databas. Det betyder att det inte finns något fördefinierat schema som standard. Vi kan lägga till ett fördefinierat schema i nyare versioner, men det är inte obligatoriskt. Underskatta inte de svårigheter som uppstår när du arbetar med dokument och arrayer, eftersom det kan bli riktigt svårt att analysera dina data i applikationssidan/ETL-processen. Dessutom kan arrayer skada replikeringsprestandan:för varje förändring i arrayen replikeras alla arrayvärden.
Bästa hårdvaran är inte alltid det bästa alternativet
Att använda bra hårdvara hjälper definitivt för en bra prestanda. Men vad kan hända i en miljö när en instans av en stor maskin dör? Svaret är "failover".
Att ha flera små maskiner (istället för en eller två) i en distribuerad miljö kan säkerställa att avbrott kommer att påverka endast ett fåtal delar av skärvan med liten eller ingen uppfattning av applikationen. Men samtidigt innebär fler maskiner en stor sannolikhet att ha ett fel. Tänk på denna avvägning när du designar din miljö. Rätt val påverkar prestandan.
Arbetsuppsättning
Hur stort är arbetssetet? Vanligtvis använder inte en applikation all data. Vissa data uppdateras ofta, medan andra inte gör det. Passar din arbetsdatauppsättning i RAM? Optimal prestanda uppstår när all arbetsdata finns i RAM.