Dataobservabilitet är en viktig del av databasoperationspusslet – Data ger dig insyn i tillståndet och tillståndet för dina kritiska system. Helst bör denna information vara tillgänglig på en enda plats. När du har flera applikationer, som var och en hanterar separata databitar, ställer du in dig på potentiellt allvarliga problem. När problem uppstår måste du snabbt kunna bedöma situationen och avgöra vad som händer istället för att försöka analysera och slå samman rapporter från flera källor.

ClusterControl, bland andra funktioner, ger användarna en enda punkt från vilken de kan spåra hälsan hos sina databaser. I det här blogginlägget kommer vi att visa några av de observerbarhetsfunktioner som finns tillgängliga i ClusterControl.
Fliken Översikt
Översiktsavsnittet är en konsoliderad plats där användare enkelt kan spåra tillståndet för ett kluster, inklusive alla klusternoder och eventuella lastbalanserare.
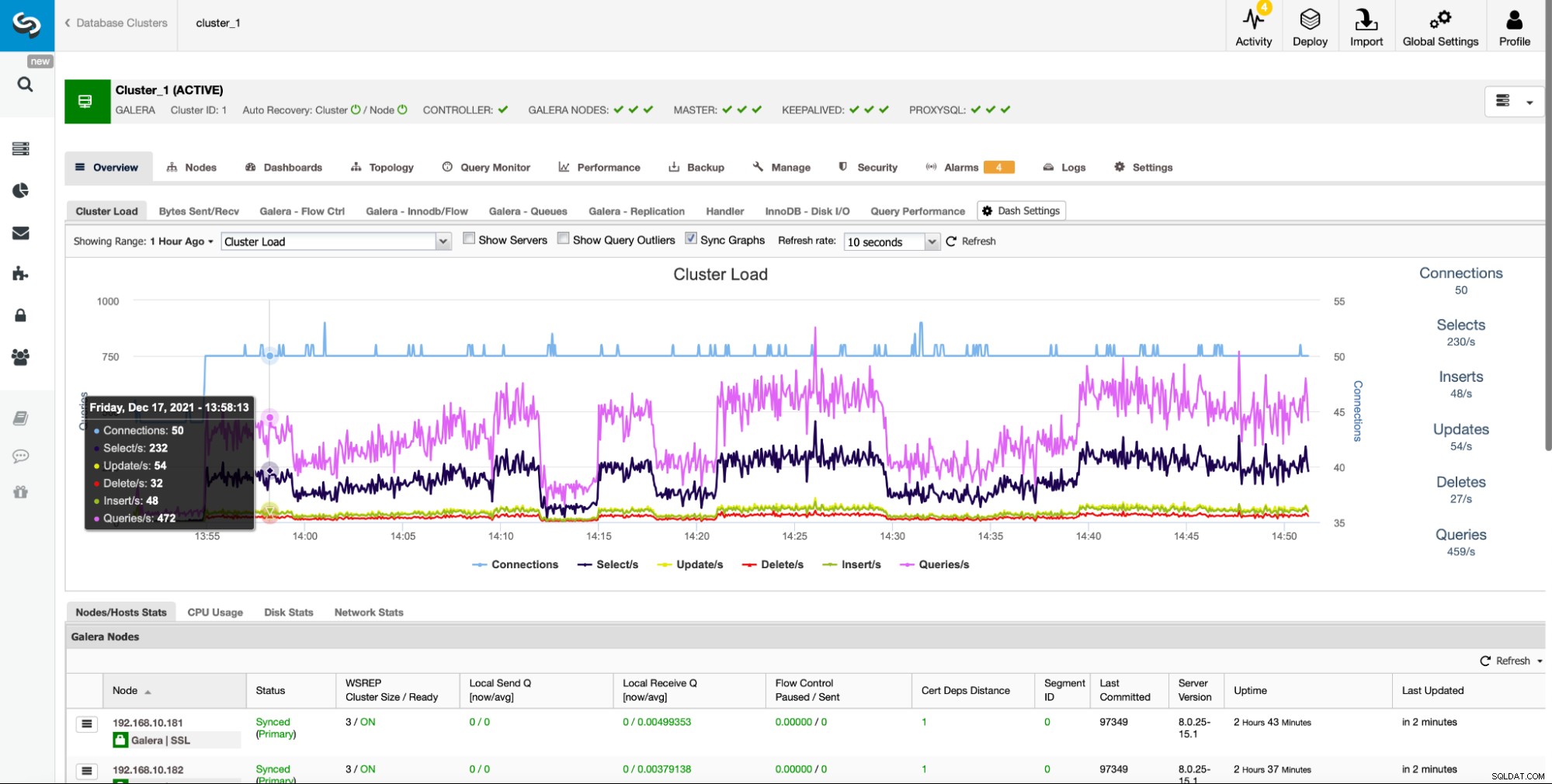
Det ger enkel åtkomst till flera fördefinierade instrumentpaneler som visar de viktigaste information för den givna typen av kluster. ClusterControl stöder olika datalager med öppen källkod, och olika grafer visas baserat på leverantören. ClusterControl erbjuder också ett alternativ för att skapa dina egna anpassade instrumentpaneler:
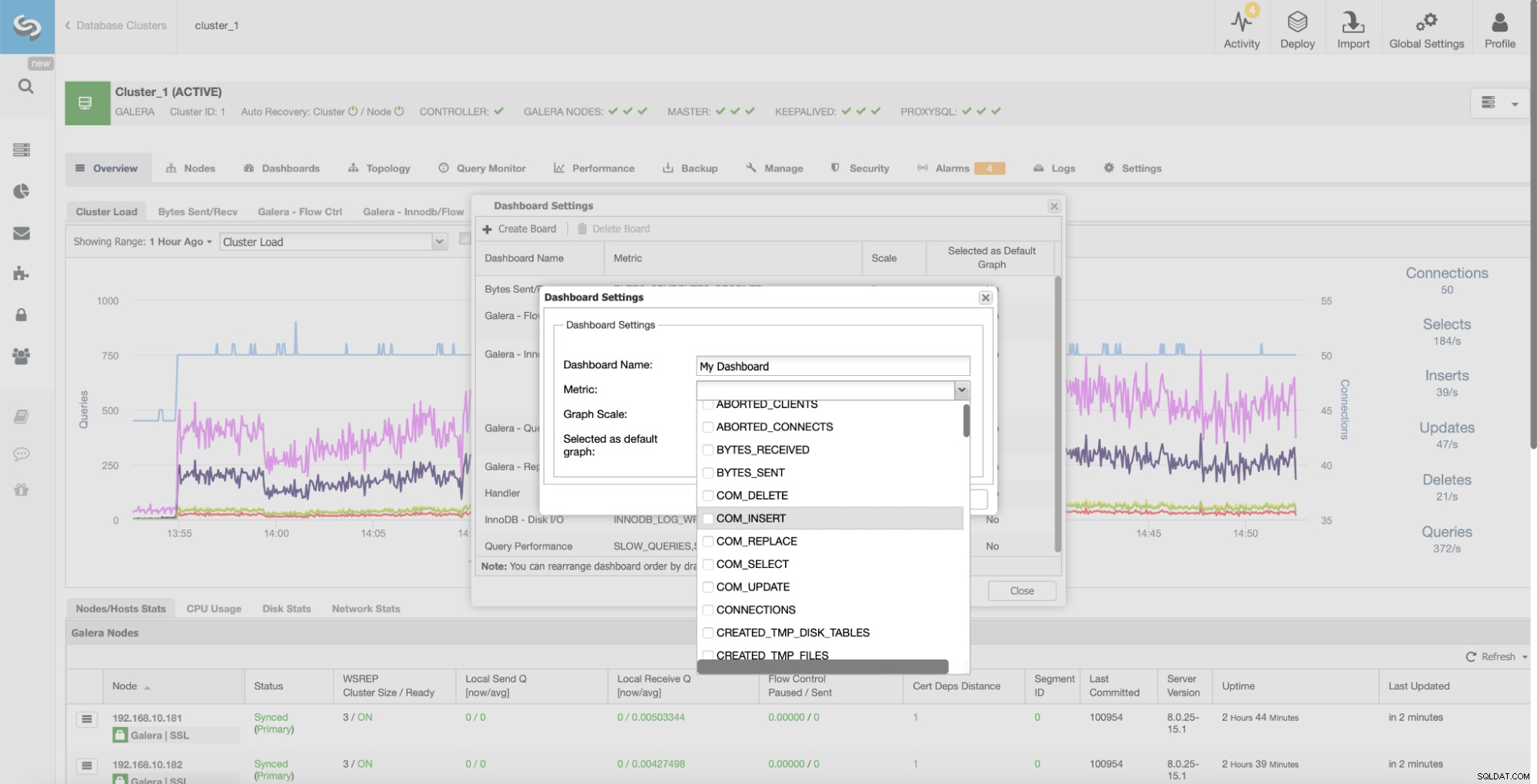
ClusterControl samlar grafer över alla klusternoder. Denna nyckelfunktion gör det lättare att spåra hela klustrets tillstånd. Om du vill kontrollera grafer från varje nod kan du enkelt göra det enligt nedan:
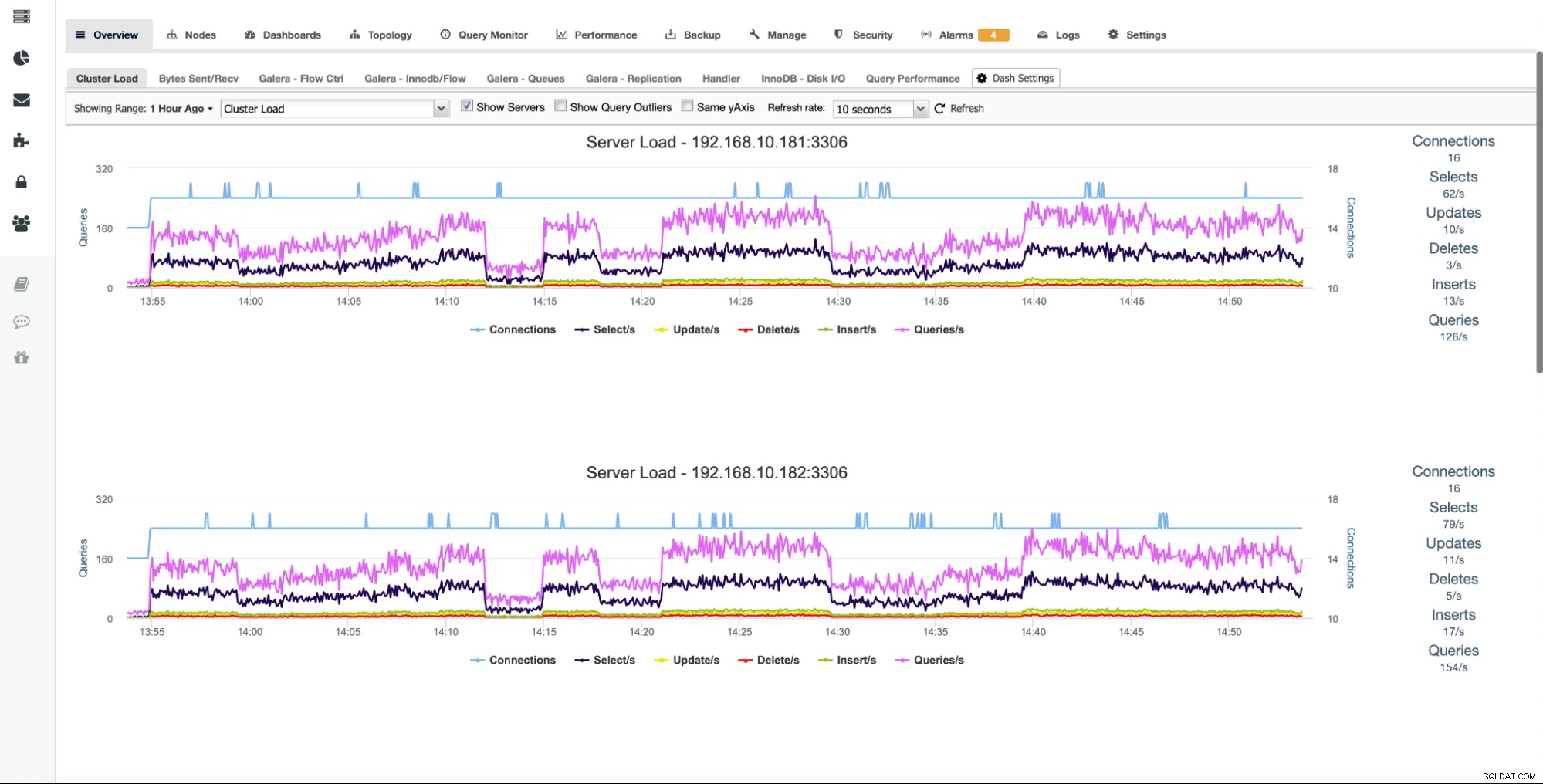
Genom att markera "Visa servrar" kommer alla noder i klustret att visas separat, så att du kan borra ner i var och en.
Fliken Noder
Om du vill kontrollera en viss nod mer i detalj kan du göra det från fliken Noder.
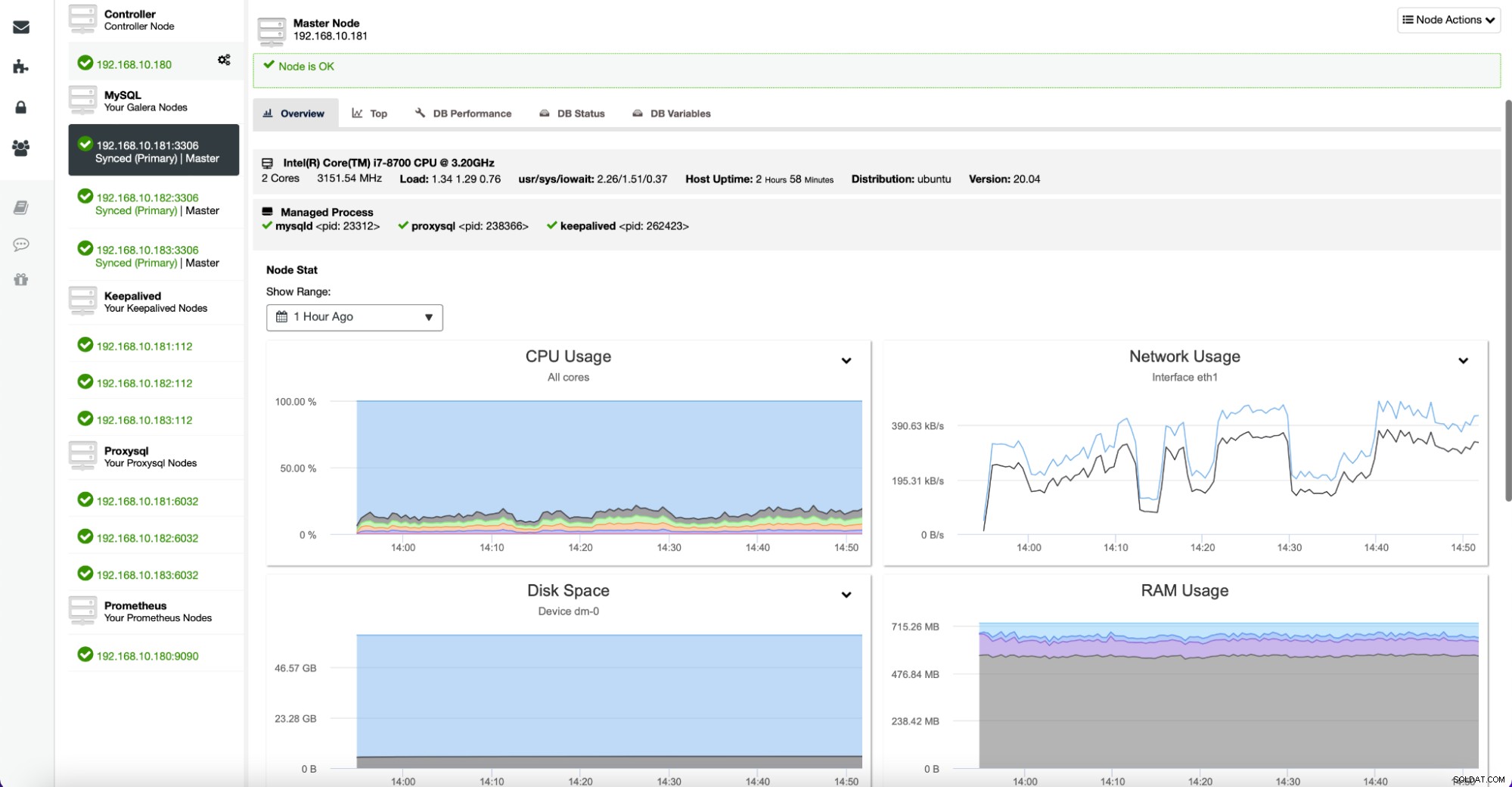
Här kan du hitta statistik för en given värd – CPU, disk, nätverk och minne – alla viktiga databitar som definierar hur en given server beter sig och hur laddad den är.
Fliken Noder ger dig också ett alternativ att kontrollera databasstatistiken för en given nod, som visas nedan:
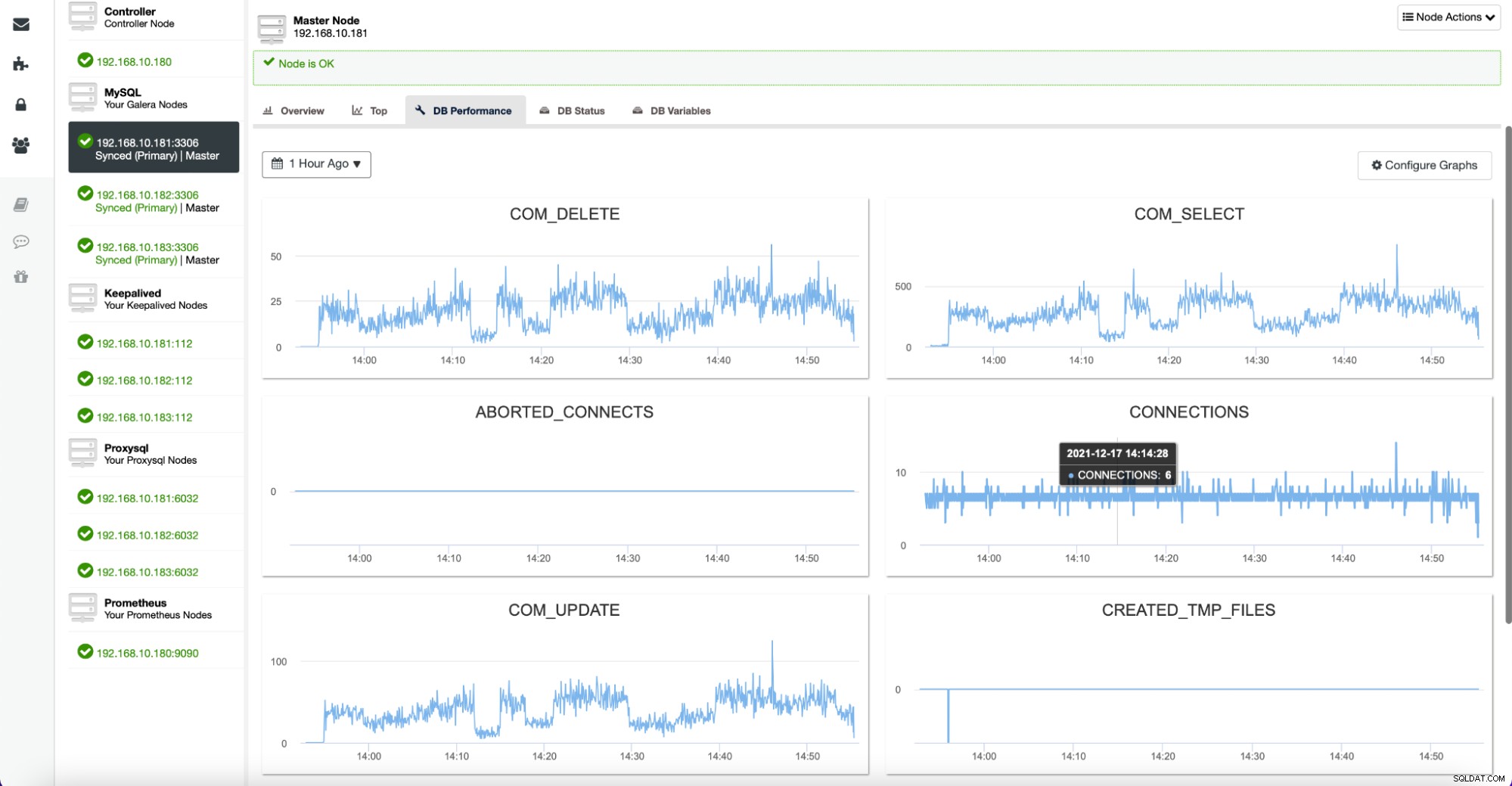
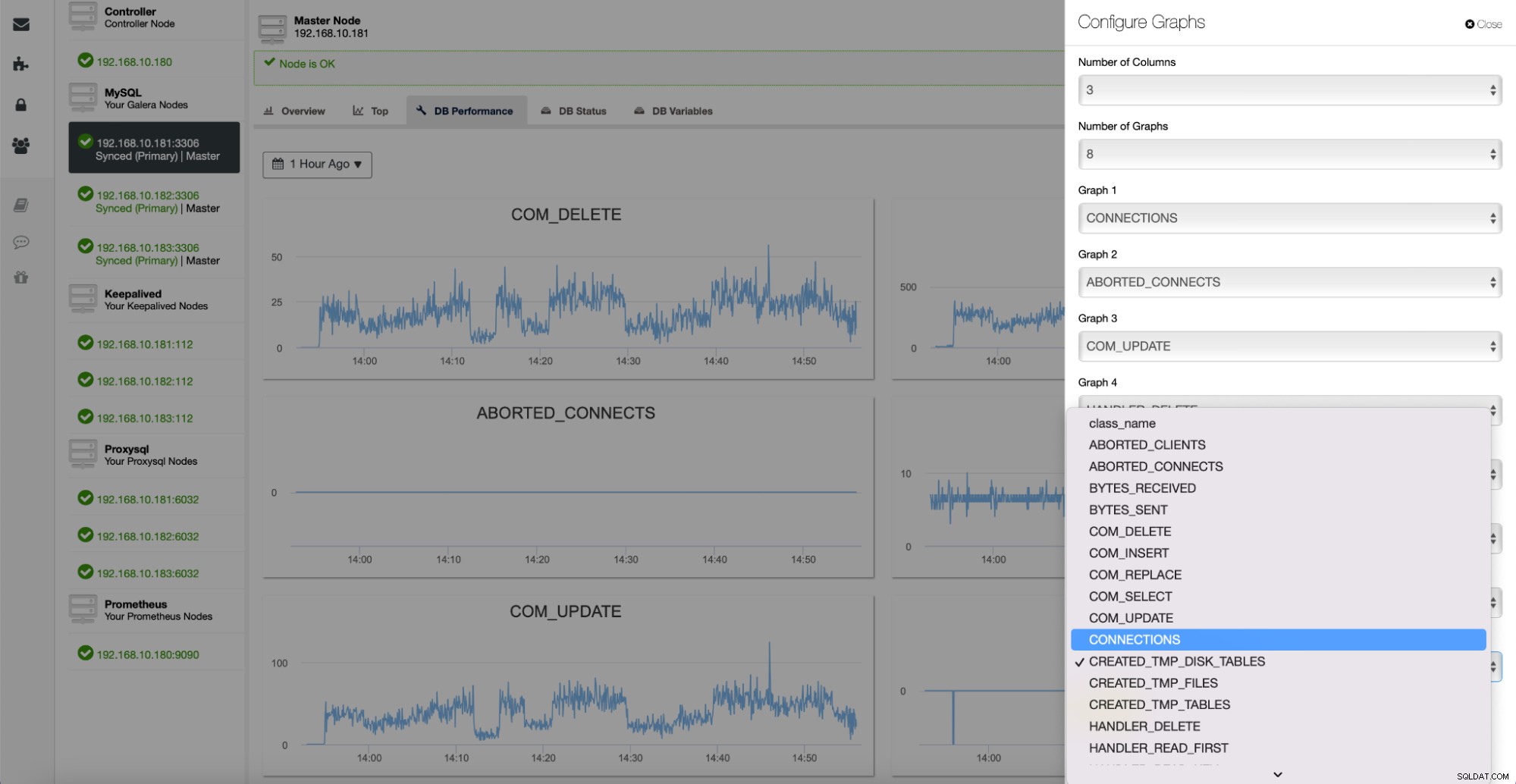
Alla dessa grafer är anpassningsbara och du kan enkelt lägga till fler efter önskemål :
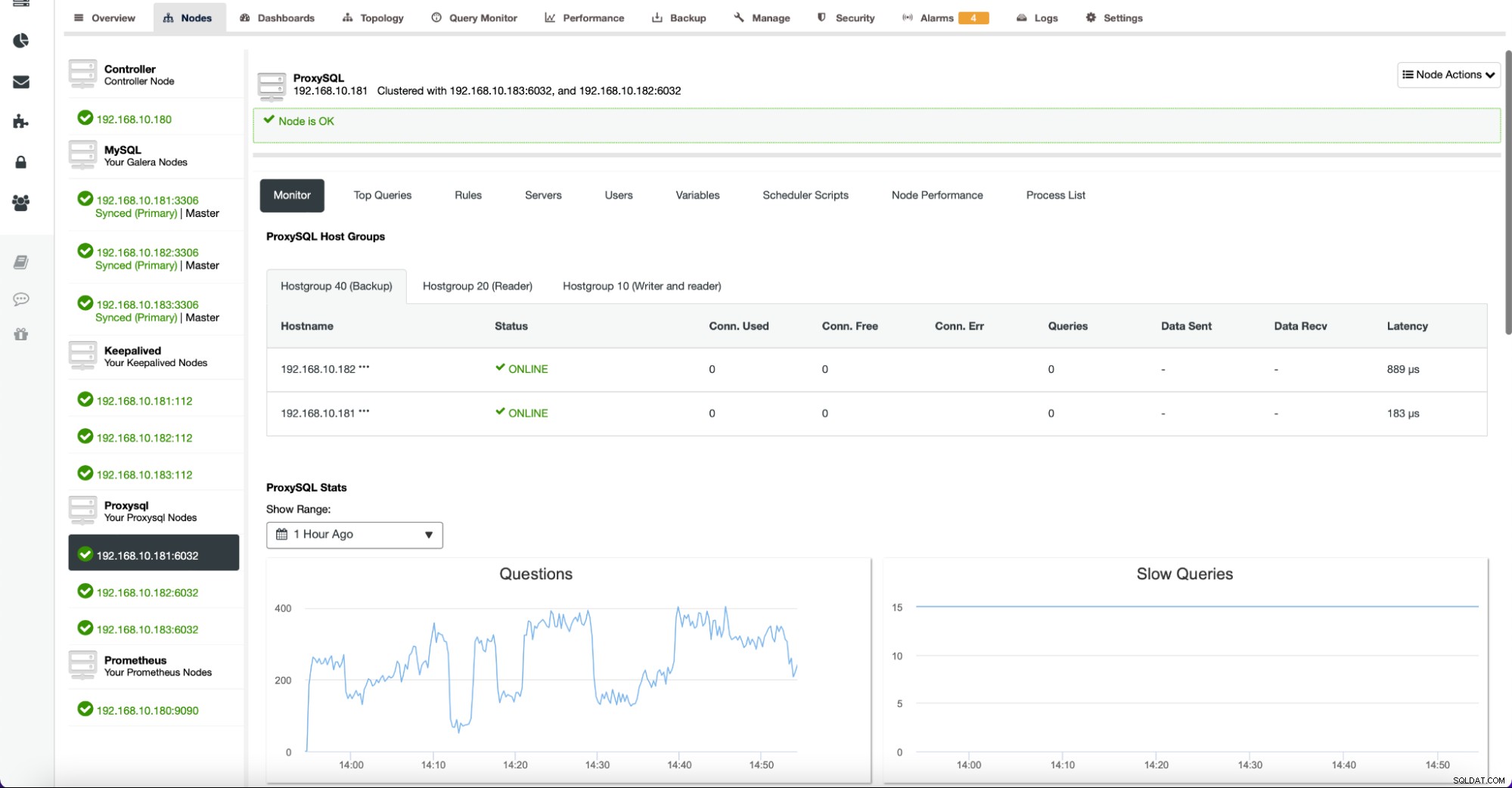
Fliken Noder innehåller även mätvärden relaterade till andra noder än databaser. Till exempel, för ProxySQL, tillhandahåller ClusterControl en omfattande lista med grafer för att spåra tillståndet för de viktigaste mätvärdena.
Instrumentpaneler
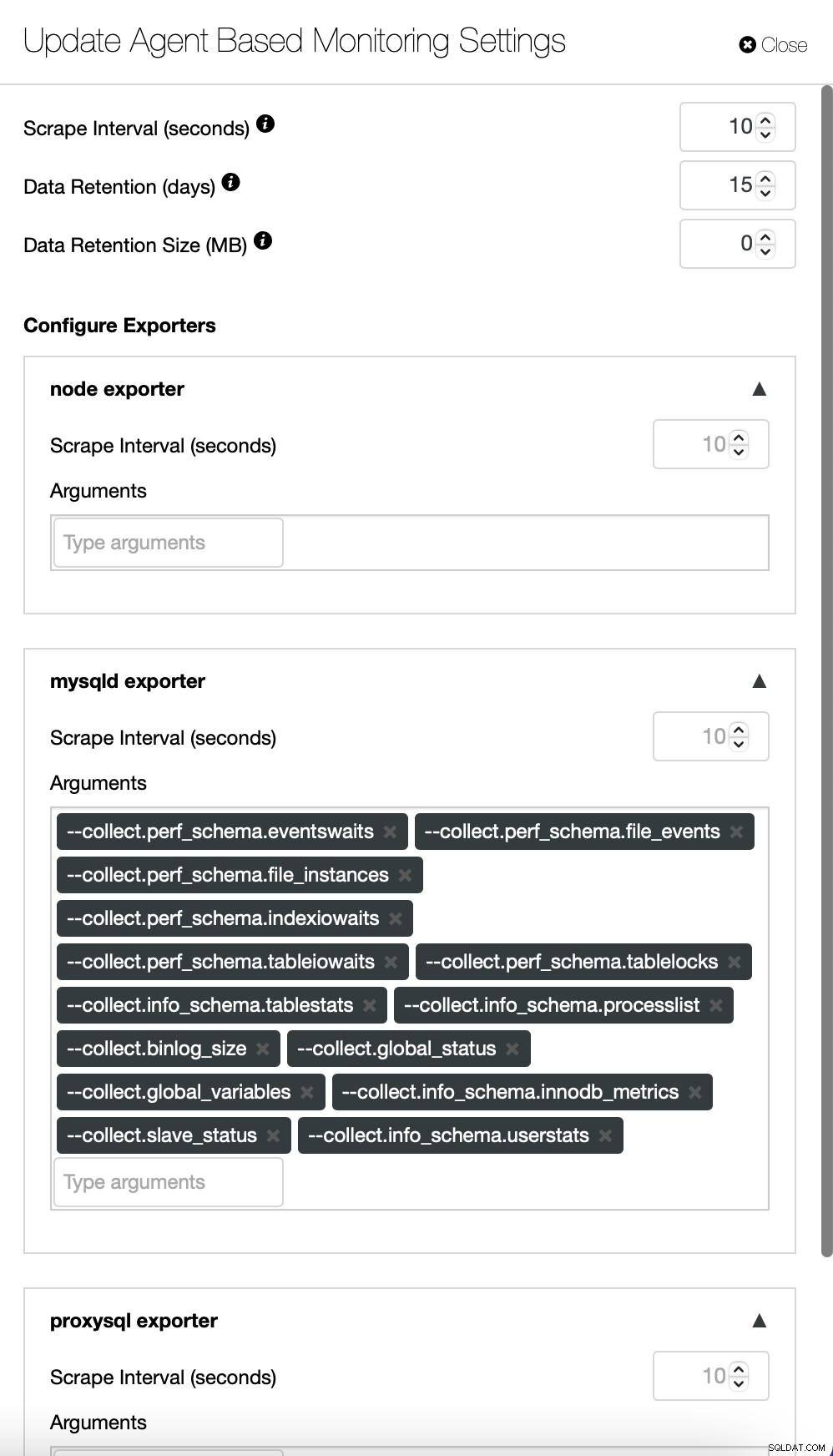
Som standard använder ClusterControl en agentfri metod för övervakning, och all data samlas in direkt från ClusterControl med antingen SSH eller inbyggd anslutning till databasen. Det är dock möjligt att möjliggöra ett agentbaserat tillvägagångssätt. Du kan göra det med bara ett klick.
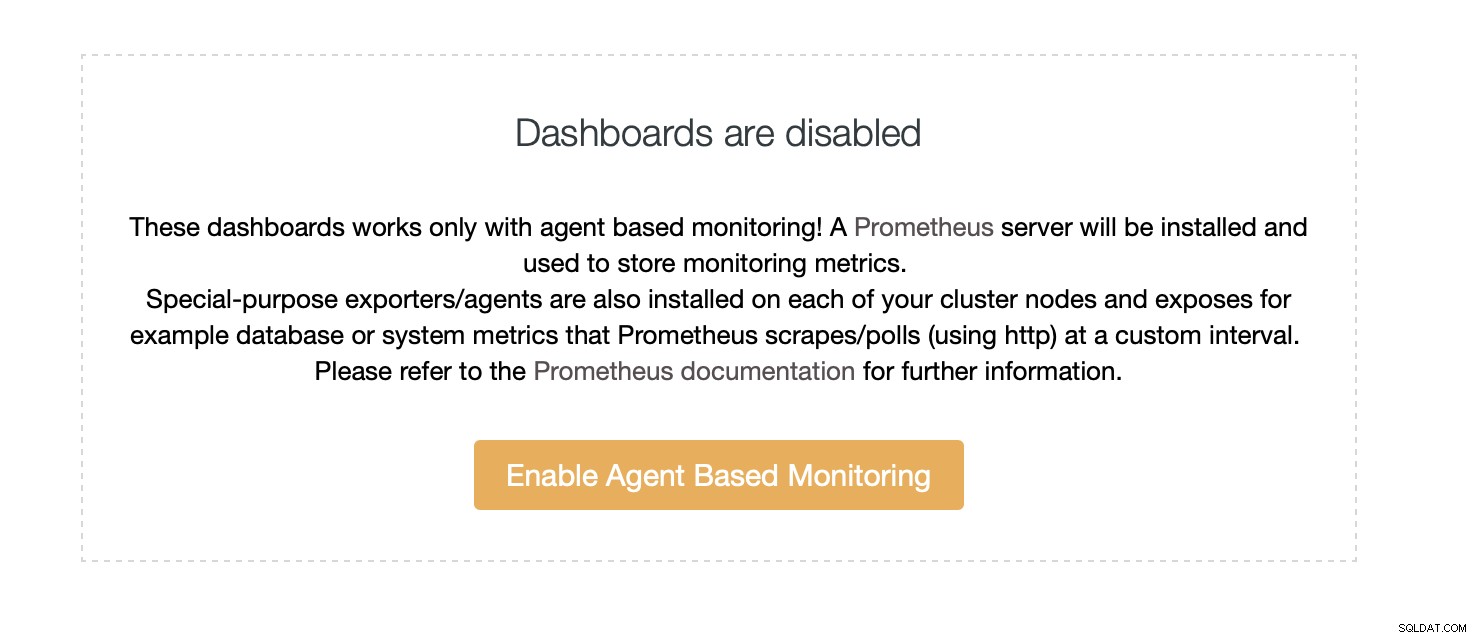
När du aktiverar agentbaserad övervakning startar ett jobb som konfigurerar en Prometheus tidsseriedatabas som kommer att lagra data och olika agenter som samlar in data och skickar den till Prometheus.
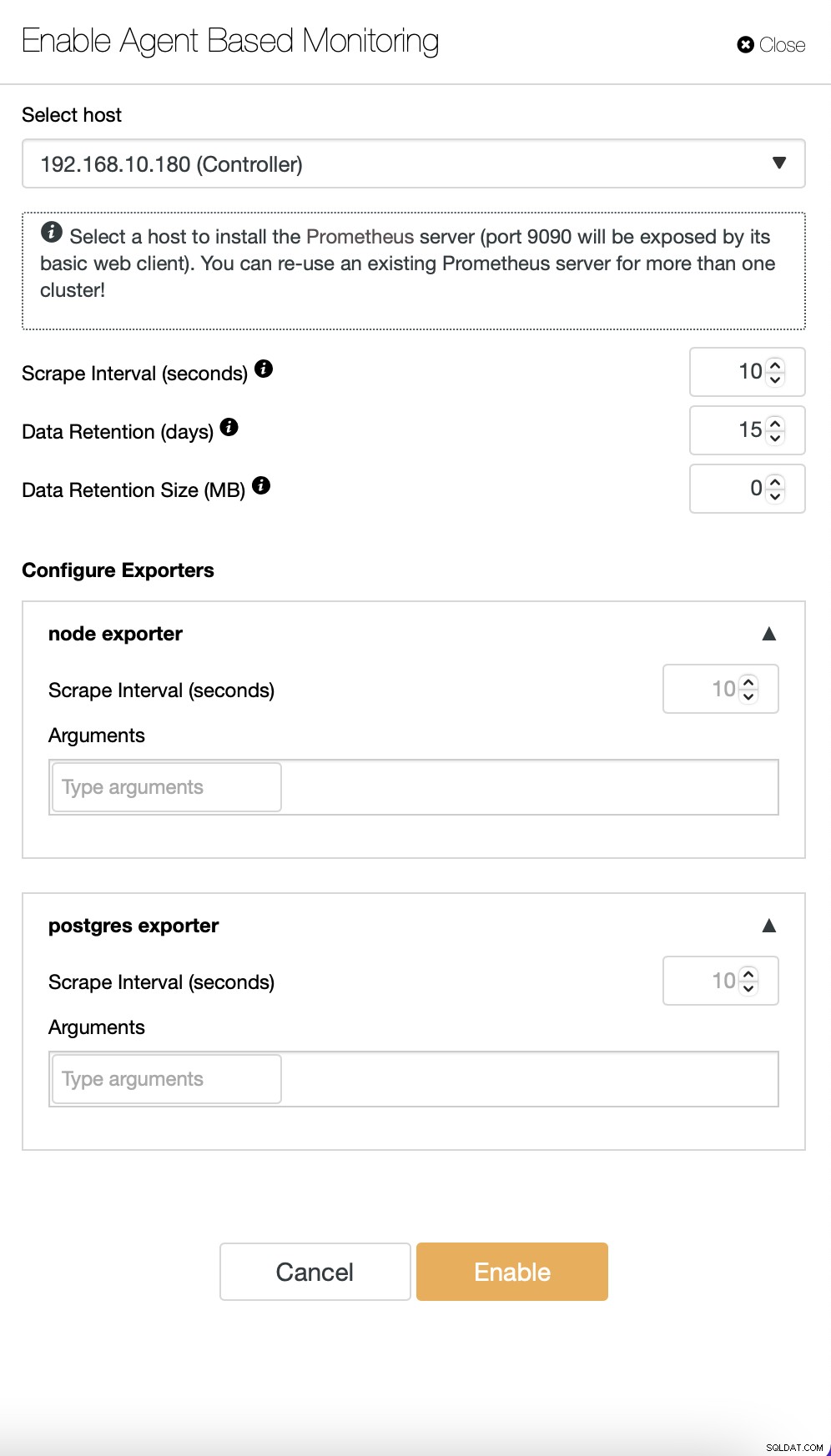
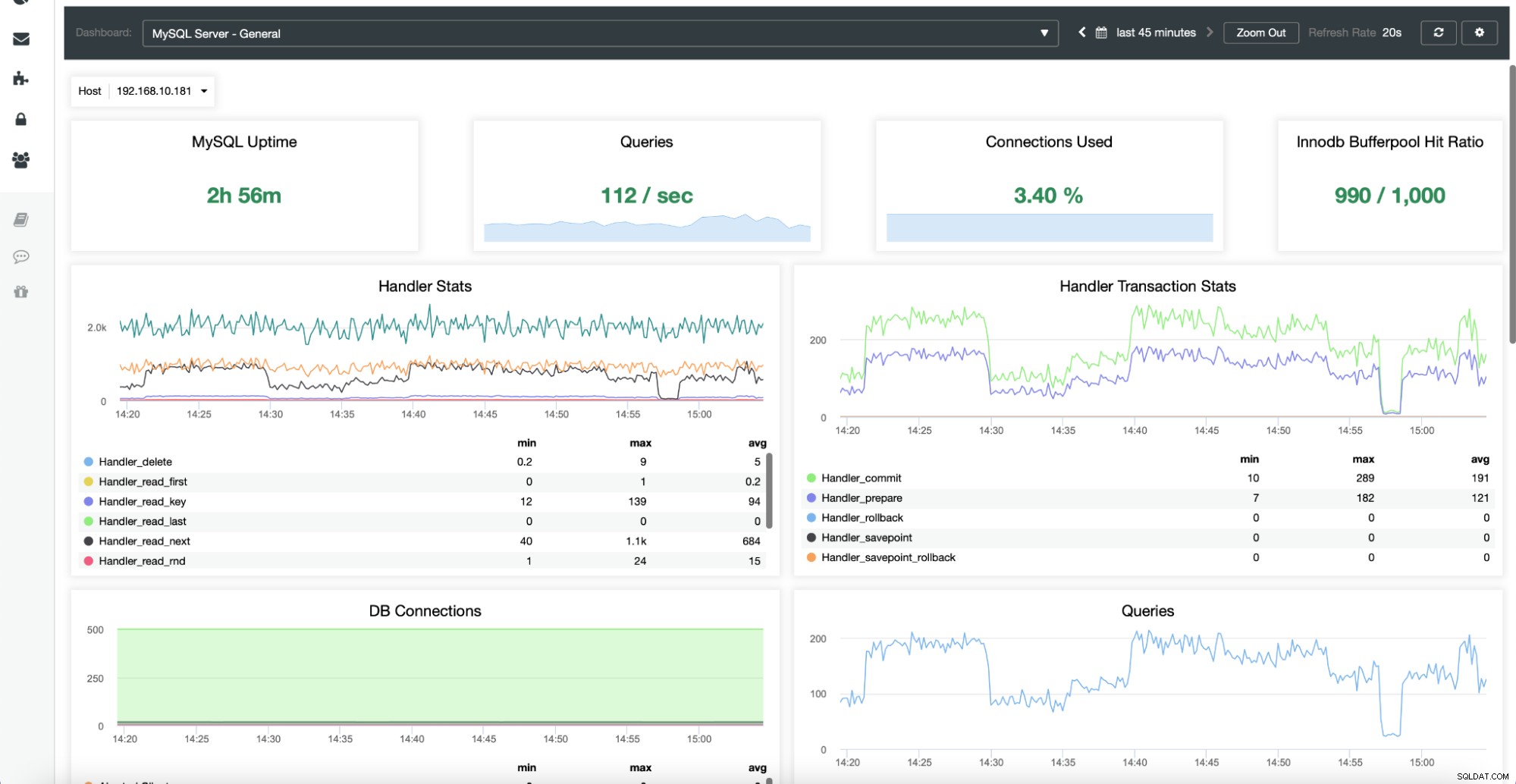
När detta är klart kommer en uppsättning instrumentpaneler att skapas enligt typer av noder tillgängliga i klustret.
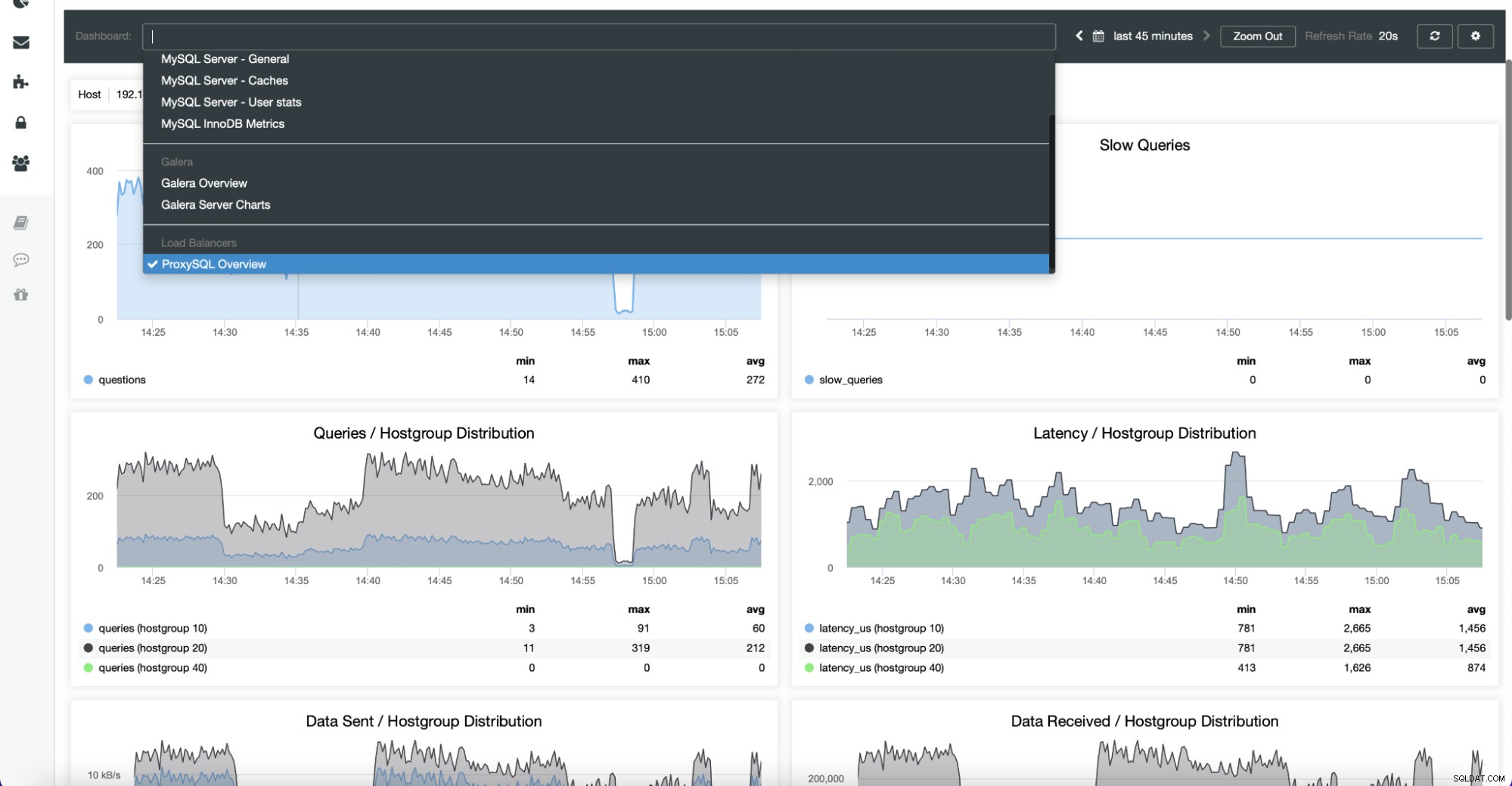
Dashboards inkluderar även lastbalanserare som har distribuerats i klustret. Om det behövs är det möjligt att återaktivera den agentbaserade övervakningen, som inkluderar ominstallation och omkonfigurering av exportörerna:
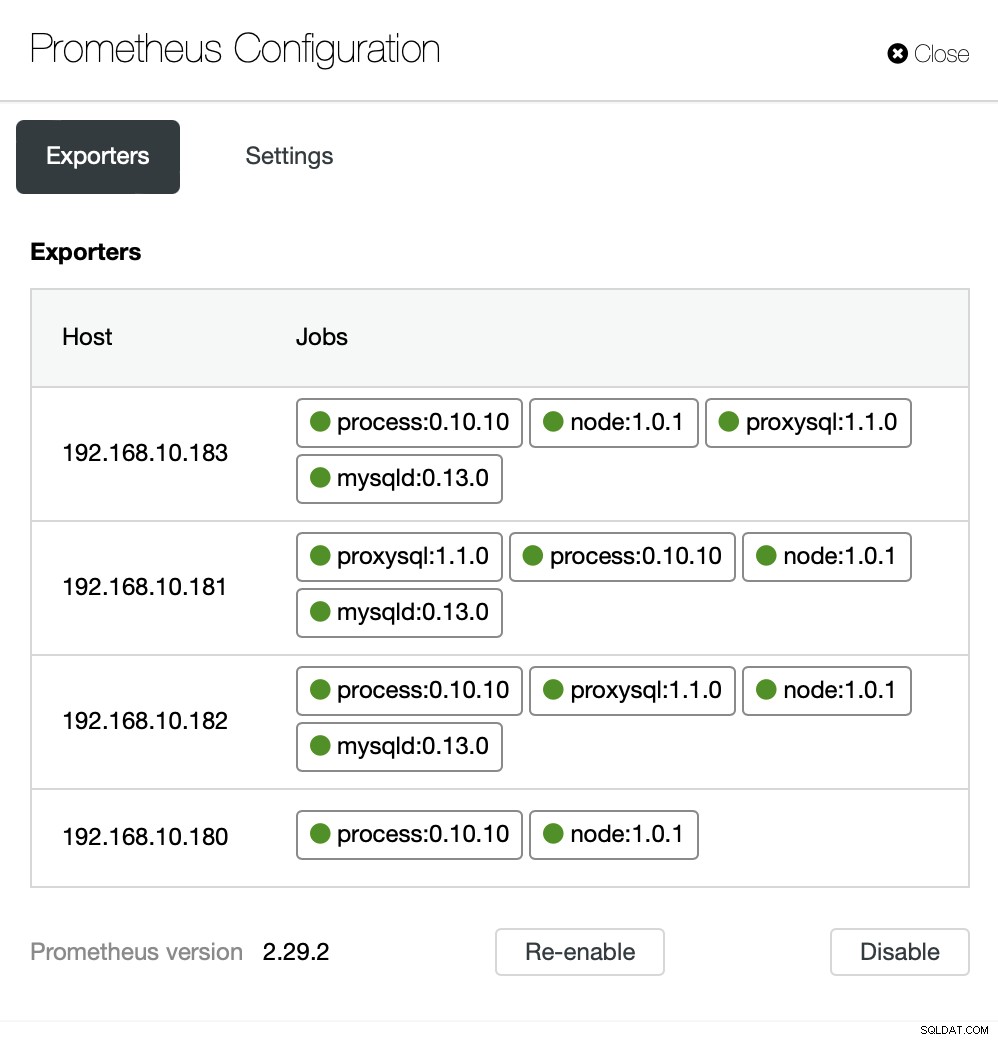
Om du vill kan du också ändra konfigurationen av agenterna och Prometheus :
Rådgivare
Trenddata är inte tillräckligt i sig. Visst, det är bra för obduktionsanalyser eller när du arbetar med kapacitetsplanering; historiska data lagrade i form av grafer kan vara till stor nytta. Men för att ha en fullständig bild av klustret behöver du varningar. Om det uppstår ett problem just nu måste användaren varnas.
ClusterControl tillhandahåller en lista över fördefinierade rådgivare som spårar tillståndet för olika mätvärden och tillståndet för dina databaser. När det behövs skapar ClusterControl en varning.
Som du kan se i skärmdumpen ovan handlar det inte bara om mått. ClusterControl kör också hälsokontroller för viktiga inställningar och ger några förutsägelser. Till exempel när det gäller diskutrymmesutnyttjande försöker ClusterControl att varna användaren om diskutnyttjandet ökar för snabbt. Naturligtvis skickas varningar inte bara genom rådgivare. Händelser som "nod ner" eller "misslyckad säkerhetskopiering" kommer också att resultera i ett meddelande.
Det är värt att notera att rådgivare är skrivna på ett JavaScript-liknande språk och kan redigeras med Developer Studio inom ClusterControl enligt nedan:
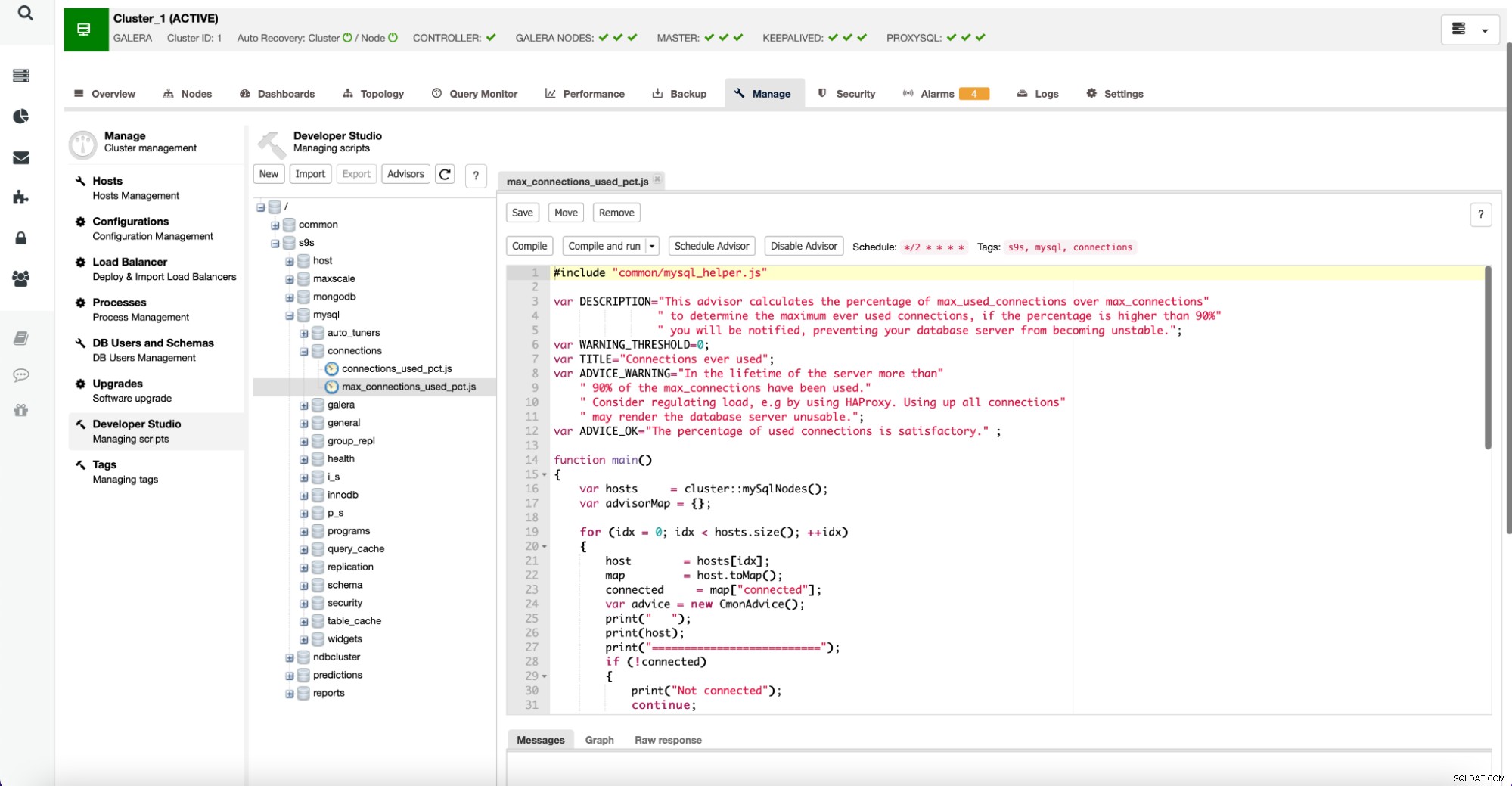
Användare kan också skapa nya rådgivare och schemalägga dem för att köras av ClusterControl.
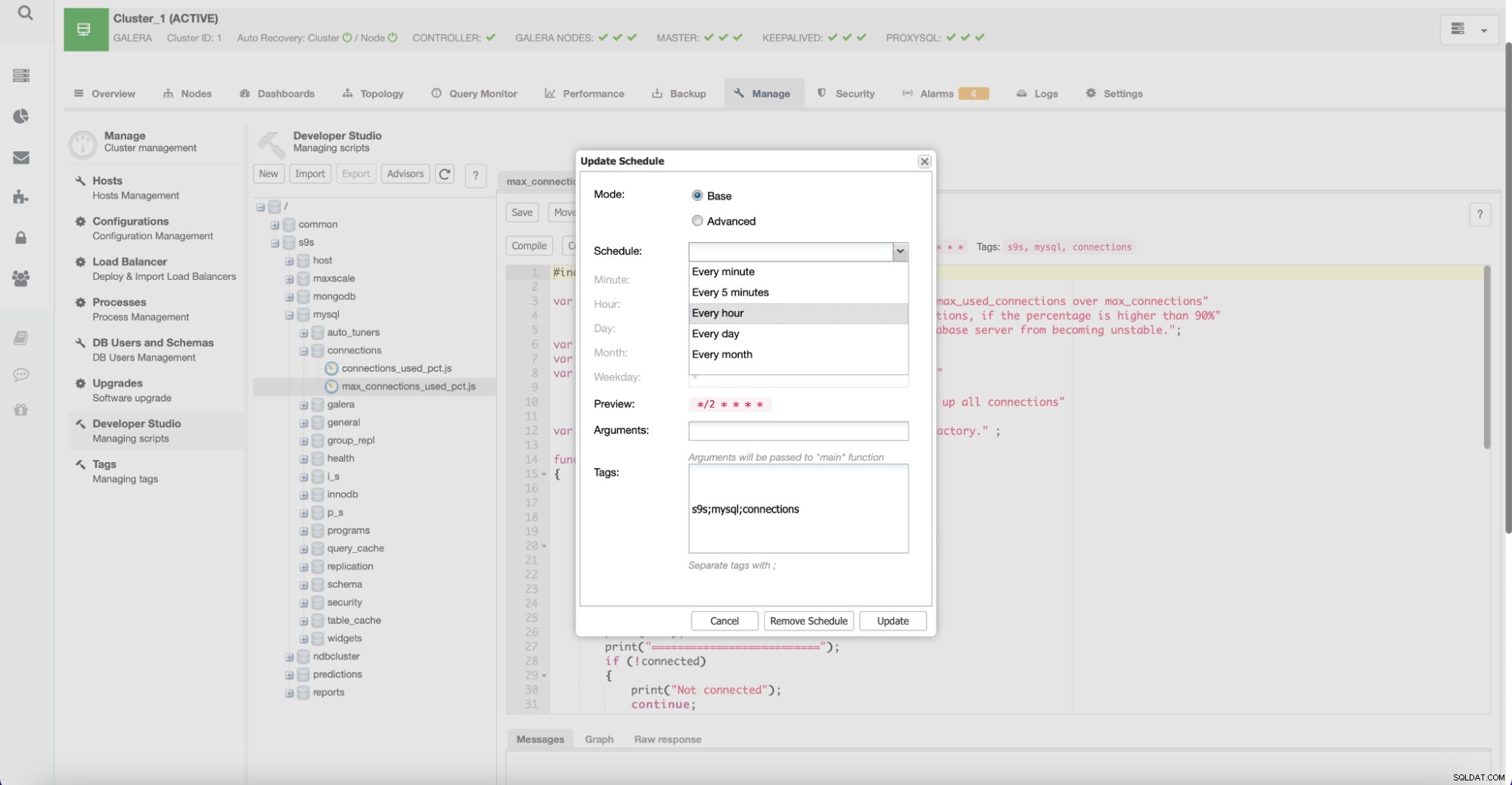
Med denna funktion kan användare utveckla sina egna skript som letar efter viktiga bitar specifikt för miljön. Sådana skript kan också dra nytta av andra ClusterControl-funktioner, till exempel om du vill implementera automatiserad skalning baserat på tillväxten av något mått.
Redo att komma igång med ClusterControl?
Som du kan se gör ClusterControls förmåga att automatisera övervaknings- och varningsuppgifter samtidigt som du får lättförståeliga och anpassningsbara instrumentpaneler det till ett viktigt verktyg för DevOps och systemadministratörer. Faktum är att ClusterControl låter dig snabbt och enkelt automatisera alla databasoperationer från en enda glasruta. Vill du se hur ClusterControl kan hjälpa dig att effektivt övervaka dina databaser? Ladda ner ClusterControl idag för att prova gratis i 30 dagar.