tl;dr:Elasticache tvingar dig att använda en enda instans av redis, vilket är suboptimalt.
Den långa versionen:
Jag inser att detta är ett gammalt inlägg (2 år när detta skrivs) men jag tycker att det är viktigt att notera en punkt som jag inte ser här.
På elasticache hanteras din redis-distribution av Amazon. Det betyder att du har fastnat med hur de väljer att köra din redis.
Redis använder en enda exekveringstråd för att läsa/skriva. Detta säkerställer konsistens utan låsning. Det är en stor tillgång när det gäller prestanda att inte hantera lås och spärrar. Den olyckliga konsekvensen är dock att om din EC2 har mer än 1 vCPU kommer de att gå oanvända. Detta är fallet för alla elasticache-instanser med mer än en vCPU.
Standardstorleken för elasticache-instanser är cache.r3.large , som har två kärnor.
Faktum är att det finns ett antal instansstorlekar med flera vCPU:er. Många möjligheter för detta problem att manifesteras.
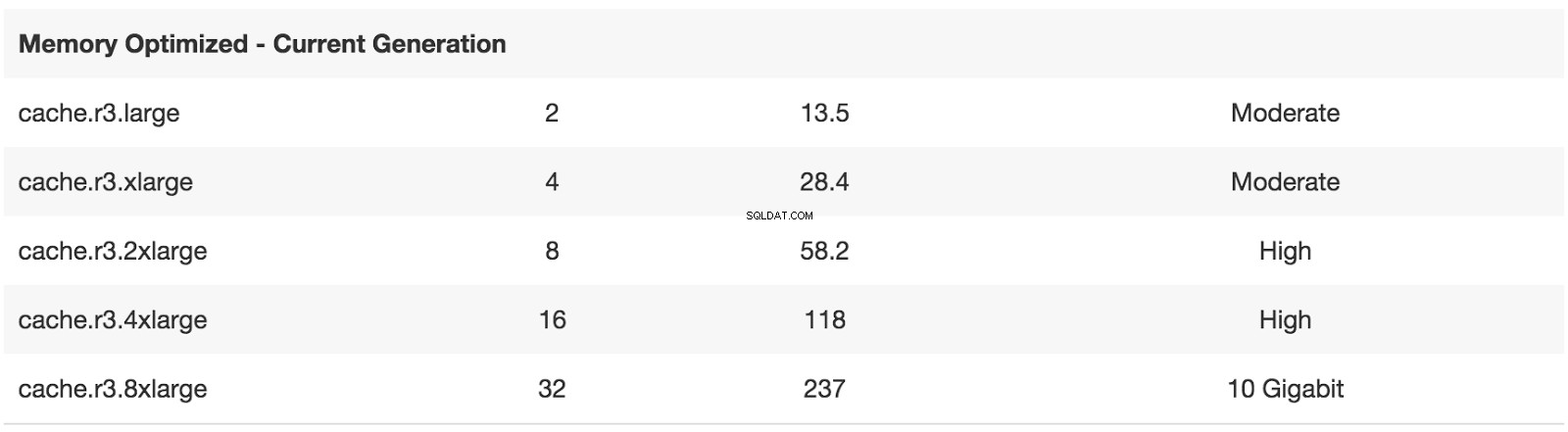
Det verkar som att Amazon redan är medveten om det här problemet, men de verkar lite avvisande mot det.

Den del som gör detta särskilt relevant för den här frågan är att du på din EC2 (eftersom du hanterar din egen distribution) kan implementera multi-tenancy . Detta betyder att du har många instanser av redis-processen som lyssnar på olika portar. Genom att välja vilken port som ska läsas/skrivas till/från i applikationen baserat på en hash av postens nyckel kan du utnyttja alla dina vCPU:er.
Som en sidoanteckning; en redis elasticache-distribution på en flerkärnig maskin bör alltid underprestera jämfört med memcached elasticache-distribution på instansstorleken. Med multi-tenancy tenderar redis att bli vinnaren.
Uppdatering:
Amazon tillhandahåller nu separata mätvärden för din redis-instans CPU, EngineCPUUtilization. Du behöver inte längre beräkna din CPU med den skumma multiplikationen, men multi-tenancy är fortfarande inte implementerad.